[16] Python 基础语法
1. 基础语法
1.1 注释
在 Python 中,注释分为两类:
(1)单行注释:以 # 开头,# 右边的所有文字当作注释内容,起解释说明代码的作用。
(2)多行注释:三个 " 或 ' 引起来的内容作为对代码的解释说明,这里的注释内容可以更详细。
1.2 关键字和标识符
「关键字」是指在 Python 语言中已经使用的一些词语,且具有特殊意义。特别注意,Python 不允许开发者定义与关键字同名的变量。
可以使用 keyword 库来查看,有哪些 Python 中关键字。
import keyword
print(keyword.kwlist)
「标识符」是指用来标识某个实体的一个符号,在不同的应用环境下有不同的含义。通俗地说,标识符就是开发者在程序中定义的所有名字,比如,即将学习的变量名。
标识符要遵循 5 个命名规范:
- 见名知意
- 由数字、字母、下划线组成,且不能以数字开头
- 区分大小写
- 不能和关键字同名
- 长度没有限制,但是最好不要超过 15 个字符。
在 Python 中,常见命名方法有:
- 小驼峰式命名法: 第一个单词以小写字母开始,第二个单词及之后单词首字母大写。比如:myName、aDog
- 大驼峰式命名法: 所有单词首字母大写,其余字母均小写。比如:FirstBlood、LastName
- 还有一种命名法是用下划线_来连接所有的单词:比如:girl_name,一般地,Python 推荐使用下划线命名。
为了给 Python 标识符新增一些额外要求,常见的有:
- 变量名/函数名/方法名:所有字母均小写,且单词与单词之间使用下划线连接;
- 模块名:所有字母均小写;
- 类名:遵循大驼峰命名法。
1.3 变量与数据类型
在 Python 中,不同类型的变量存放的数据也不同。
常见的数据类型有:
| 类型名 | 表示类型 | 说明 |
|---|---|---|
| int | 整型 | 用于存放整数,例如 -1、10、0、8 等。 |
| float | 浮点型 | 用于存放小数,例如 3.14、6.38、9.99 等。 |
| bool | 布尔型 | 用于表示真或假,这个类型的值只有两种:True、False。 |
| str | 字符串 | 使用引号引起来的内容,都是字符串。 |
可以使用 type(变量名) 的形式来查看数据类型。
1.4 输入与输出
| 函数名 | 说明 | 入参 |
|---|---|---|
| print(args) | 输出信息内容 | 参数 args 可以是一个变量名,或者具体的数据值。 |
| input(x) | 接收从键盘上录入的内容 | 参数 x 是字符串型数据,表示给用户的提示信息。 |
如果想要让 print() 输出更美观些,也可以使用转义字符来处理。转义字符,指的是无法直接表达本身含义,就需要转化含义来显示。若要给一个字符转义,通常要在字符前添加 \。
| 字符 | 名称 | 含义 |
|---|---|---|
\n |
换行符 | 给内容进行换一行显示 |
\t |
水平制表符 | 缩进一个 tab 键的空白位置,也可以当成是缩进 4 个空格。 |
\\ |
反斜杠 | 表示一个反斜杆 |
\" |
单个双引号 | 表示单个双引号 |
在 Python 中,完整的格式化符号要与 % 一同使用:
| 格式化符号 | 转换后表示含义 |
|---|---|
%d |
表示整数 |
%s |
表示通过 str() 字符串转换后的格式化,即字符串。 |
%f |
表示浮点数,即有小数点的数值。 |
(1)让一个符号具有格式化的效果,一般要在前面添加 %;
(2)当使用格式化符号占据位置后,再使用变量去替换;
(3)字符串和变量之间要使用 % 连接。
举例说明:
'''
使用格式: "%d, %s, %f" % (变量1,变量2.....)
'''
# 定义姓名、年限、存款金额这3个变量;
name = '刘源'
year = 3
money = 200000.67
# 通过格式化符号来输出"我的名字是刘源, 工作3年了, 存款有200000.67元!";
print("我的名字是刘源, 工作3年了, 存款有349862.56元!")
print("我的名字是刘源, 工作3年了, 存款有%f元!" % (money))
print("我的名字是%s, 工作3年了, 存款有349862.56元!" % (name))
print("我的名字是刘源, 工作%d年了, 存款有349862.56元!" % (year))
print("我的名字是%s, 工作%d年了, 存款有%20.10f元!" % (name, year, money))
# 我的名字是刘源, 工作3年了, 存款有349862.56元!
# 我的名字是刘源, 工作3年了, 存款有200000.670000元!
# 我的名字是刘源, 工作3年了, 存款有349862.56元!
# 我的名字是刘源, 工作3年了, 存款有349862.56元!
# 我的名字是刘源, 工作3年了, 存款有 200000.6700000000元!
1.5 运算符使用
运算符是用于执行程序代码的操作运算。常见的运算符有:
(1)算术运算符:+、-、*、/、//、% 、**
(2)赋值运算符:=、+=、-=、*=、/=、//=、%=、**=
(3)比较运算符:>、<、>=、<=、``、!=
(4)逻辑运算符:not、and、or
| 算术运算符 | 名称 | 描述 |
|---|---|---|
+ |
加法 | 两个数相加,如 6 + 12=18 |
- |
减法 | 两个数相减,如 25 - 9=16 |
* |
乘法 | 两个数相乘,如 3 * 7=21 |
/ |
除法 | 两个数相除,如 25 / 5=5 |
// |
取整除 | 两个数相除取商的整数部分,如 10.0 // 3.0=3.0 |
% |
求余(取模) | 两个数相除取余数值,如 13 % 4=1 |
** |
次幂(次方) | 表示返回 x 的 y 次幂 |
| 赋值运算符 | 名称 | 描述 |
|---|---|---|
= |
赋值 | c =a+b,将 a+b 的值赋值给c |
+= |
加等于 | m+=n,等同于 m=m+n |
-= |
减等于 | m-=n,等同于 m=m-n |
*= |
乘等于 | m *= n,等同于 m=m * n |
/= |
除等于 | m/=n,等同于 m=m/n |
//= |
取整除等于 | m//=n,等同于 m=m//n |
%= |
取模等于(求余等于) | m%=n,等同于 m=m%n |
**= |
幂等于 | m ** =n,等同于 m=m ** n |
| 关系运算符 | 名称 | 示例 | 结果 |
|---|---|---|---|
== |
等于 | 43 | False |
!= |
不等于 | 4!=3 | True |
< |
小于 | 10<2 | False |
> |
大于 | 10>2 | True |
<= |
小于等于 | 20<=24 | True |
>= |
大于等于 | 20>=24 | False |
| 逻辑运算符 | 名称 | 举例 | 结果 |
|---|---|---|---|
and |
与 | a and b | 若a和b都为True,则结果为True;否则,结果为False。 |
or |
或 | a or b | 若a和b任意一个为True,则结果为True。 |
not |
非 | not m | 若m为False,则结果为True,即取反。 |
2. 流程控制
Python 中有三大基本语句,它们支撑起了程序的业务逻辑处理。
三大基本语句有:顺序语句、分支语句、循环语句
- 顺序语句:让代码按照顺序从上往下、一行一行的执行代码。
- 分支语句:程序在遇到不同条件时,要做判断处理。例如当条件成立,则执行代码 A;当条件不成立,则执行代码 B。
- 循环语句:反复多次执行地执行某操作。也可以设定终止循环的关键字。
(1)if
if 可以用于做条件判断处理。
# 一 if
if 条件: # 条件的结果总是布尔型的
条件成立时,要做的事情 # if语句后记得使用Tab进行强制缩进
# 二 if-else
if 条件:
满足条件时,要做的事情1
满足条件时,要做的事情2
满足条件时,要做的事情3
...(省略)...
else:
不满足条件时,要做的事情1
不满足条件时,要做的事情2
不满足条件时,要做的事情3
...(省略)...
# 三 if-elseif-else
if 条件1:
满足条件1,执行代码1
...
elif 条件2:
满足条件2,执行代码2
...
elif 条件3:
满足条件3,执行代码3
...
# 四 if嵌套
if 条件1:
满足条件1,做的事情1
满足条件1,做的事情2
...
if 条件2: # 当成功满足外层的if条件执行后,才能执行内层的if语句。
满足条件2,做的事情1
满足条件2,做的事情2
...
(2)while
当要对代码反复多次执行时,可以使用 while 循环语句解决问题。
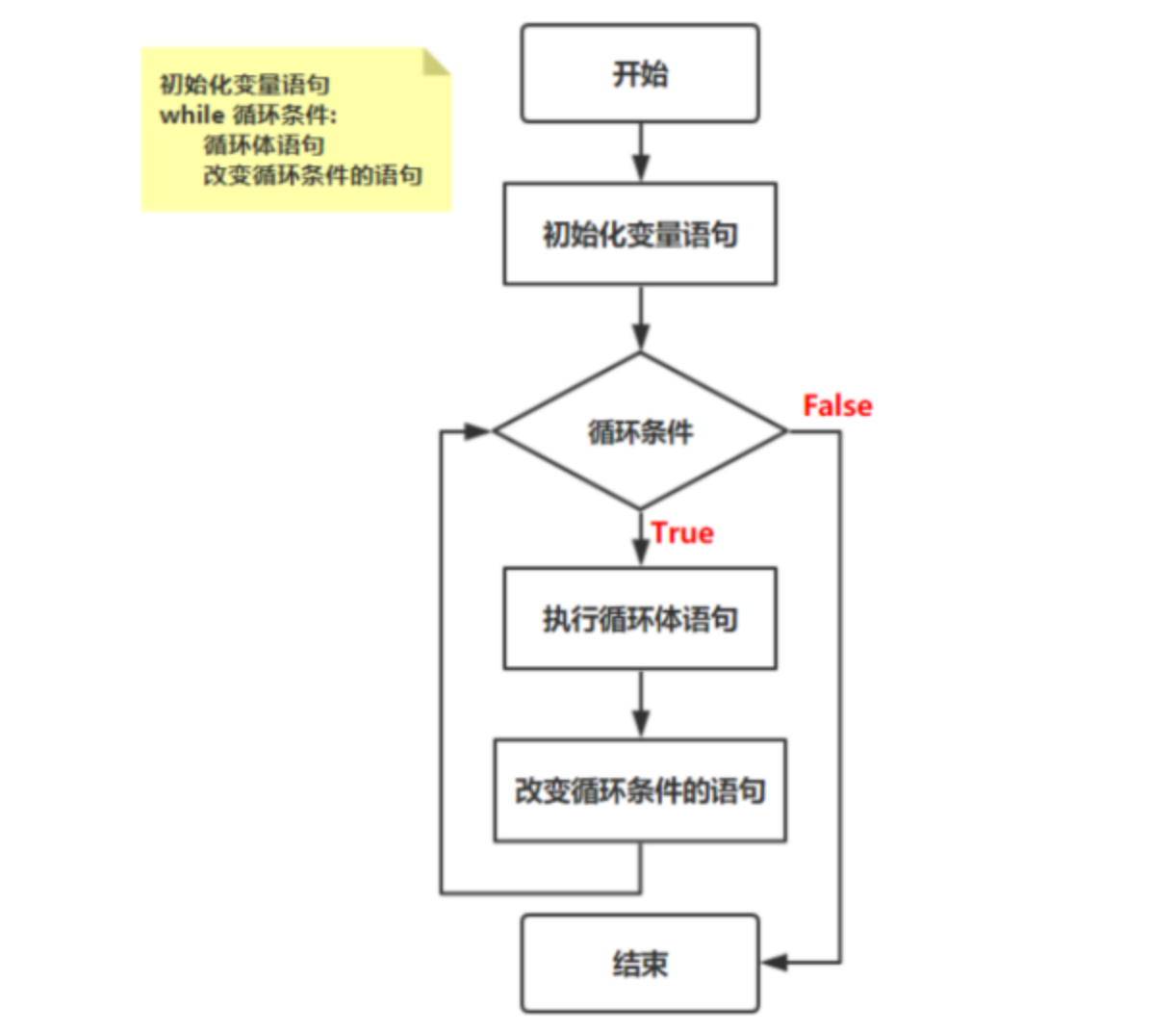
# (1)使用while循环语句来输出10句:Python真简单;
# (2)在程序里,分析while循环的执行流程。
# 定义初始化变量
i = int(input("请输入想输出的次数:"))
# 定义循环条件
while i > 0:
# 改变循环条件的代码
i -= 1
# 要循环执行的代码
print("Python真简单")
死循环,也称为无限循环,指的是程序代码一直执行,不会停止。
产生死循环的情况有:
(1)缺少了改变循环条件的语句;
(2)误写了循环条件;
(3)标准的死循环格式。
在使用 while 循环时,建议先写【改变循环条件的语句】,这样可以避免产生更多错误。
(3)for
与 while 循环功能类似,for 语句也能完成反复多次的执行。
for 语法:
for 临时变量 in 序列:
满足条件时,执行的代码1
满足条件时,执行的代码2
……
[else:
当for循环正常执行结束后,执行代码]
序列指的是能被循环处理的数据类型,比如列表、字符串等。
for 循环里常见的序列 range() 函数:
| 函数名 | 含义 |
|---|---|
| range(x, y) | 一个序列,专门用于给 for 循环使用。 |
range() 中的参数表示从 x 到 y 的取值,即 [x,y),表示能获取到 x 值,但获取不到 y 值。
通俗地说,嵌套循环就是指外层有一个循环,里面再嵌套一个内层循环。
- 可以把内层循环当做一个循环的循环体语句来处理;
- 当外层循环执行一次,内层循环执行所有。
终止/跳过循环:
- break 语句主要是用于终止某个循环语句块的执行。
- continue 语句不常使用,表示用于跳过某个循环语句块的一次执行,然后继续执行下一轮的循环。
补充:在 Python 中要获取随机数值,可以使用生成随机数的 random 模块。
# 导入模块
import random
random 模块生成随机数的函数:
| 函数名 | 含义 |
|---|---|
| randint(a, b) | 生成随机数,用于返回 [a, b] 之间的整数,并能取值 a 和 b。 |
3. 容器
在 Python 中的容器是用来存放数据的。
与此同时,为了操作方便,Python 给我们提供了对容器中数据处理的方法,例如增加、删除、修改、查询等。
请记住这个操作方法的格式:变量名.函数(x),Python 容器有很多操作方法,但都是使用这种形式完成调用。
在 Python 中,常见容器有:
- 字符串:str 不可变数据类型,使用 " " 引起来的内容;
- 列表:list 可变数据类型,使用 [ ] 表示的内容;
- 元组:tuple 不可变数据类型,使用 ( ) 表示的内容;
- 字典:dict 可变数据类型,使用 { } 表示,内部元素是键值对。
【案例】分别定义字符串、列表、元组、字典变量;使用 type(变量名) 查看变量的类型。
s = "tee6x7"
print(type(s)) # <class 'str'>
print(s.upper().islower())
l = ['tee6x7', 'tree', 'bigdata', 1]
print(type(l)) # <class 'list'>
print(len(l))
t = ('tee6x7', 'tree', 'bigdata', 2)
print(type(t)) # <class 'tuple'>
d = {'tee6x7': s, 'tree': t, 'bigdata': s}
print(type(d)) # <class 'dict'>
3.1 字符串
字符串表示文本内容,例如中文文字、学生姓名、一段英文等。字符串就是使用双引号引起来的内容。
创建字符串语法:变量名 = "内容"
说明:字符串可以使用双引号或单引号表示,较常见的是双引号表示。
# (1)使用双引号表示一个公司名称;
# (2)使用单引号表示公司名称;
# (3)分别输出变量的类型结果;
# (4)思考1:使用字符串与一个数值拼接,会怎样?
# (5)思考2:一段使用引号表示的字符串中,还有引号,该怎么处理?
company1 = "aaa"
company2 = 'bbb'
print(type(company1))
print(type(company2))
# 字符串与字符串拼接
print(company1 + company2)
# 字符串与数值拼接,会报错不能拼接
print(company1 + company2 + 1) # <= TypeError: can only concatenate str (not "int") to str
# 字符串中有引号时:
# —— 单引号中可以有双引号
# —— 双引号中可以有单引号
print('aaa"bbb') # aaa"bbb
# 如果有重复的引号加转义字符
print('aaa\'bbb') # aaa'bbb
索引
索引有时也称为下标、编号。
Python 字符串的索引,就与储物柜编号类似。比如有个字符串变量:name = 'abcdef',存放效果:

获取字符串元素语法:变量名[索引值]。
说明:索引值是从 0 开始计算的。
字符串长度的表示方式:
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量 s 的长度或元素个数(长度值是从 1 开始计算的) |
案例:
# (1)定义一个存有HelloWorld的字符串变量
s = "HelloWorld"
# (2)获取变量中的H和W
print(s[0])
print(s[5])
# (3)获取变量的总长度
print(len(s))
# (4)思考:如何获取变量的最后一个元素d
# 索引与长度的关系可表示为:最大索引值 = 长度 - 1
print(s[len(s)-1])
切片
切片指的是截取字符串中的一部分内容。
切片语法:
[起始:结束]
当需要每隔几个字符来截取内容时,可以加入步长,语法:
[起始:结束:步长]
说明:切片语法选取的范围是左闭右开型,即 [起始, 结束),包含起始位,但不包含结束位。
# (1)定义一个字符串变量,内容为:HelloITHEIMA;
s = "HelloITHEIMA"
# (2)截取索引值1到5之间的内容;
print(s[1:5])
# 截取第1到第5个之间的内容
print(s[0:5])
# (3)截取索引值2到结尾的内容;
print(s[2:])
# (4)截取索引值2到倒数第2个的内容;
print(s[2:11])
print(s[2:-1])
# (5)截取起始处到索引值为3的内容;
print(s[0:3])
print(s[:3])
# (6)截取索引1到8且每隔2个字母截取一下内容;
print(s[1:8:2])
# (7)截取索引2到10且每隔3个截取一下内容。
print(s[2:10:3])
# 可以从后往前数,可以使用负数表示,对字符串反转
print(s[::-1])
# 结束索引值如果大于实际边界,可以正常执行,但是只能取最后的索引位置
print(s[0:100])
# 如果直接获取索引值大于实际边界时,会报错超出索引边界
print(s[100])
遍历
(1)使用 for 遍历字符串
# (1)定义一个字符串变量,内容为:ABCDEF;
s = "ABCDEF"
# (2)使用for循环来遍历元素;
for temp in s:
print(temp)
else:
print("字符串中的所有元素已遍历结束")
# 通过下标循环遍历字符串中的元素
# 当需要获取元下标时使用的方式
for i in range(0, len(s)):
print(f"{s[i]}这是字符串的第{i + 1}个元素")
(2)使用 while 遍历字符串
# (1)定义一个字符串变量,内容为:ABCDEF;
s = "ABCDEF"
# (2)使用while循环遍历字符串
i = 0
while i < len(s):
print(s[i])
i += 1
操作
字符串的查找方法指的是查找元素(或子串)在字符串内容的索引位置。
| 函数名 | 含义 |
|---|---|
| find(sub) | 检测 sub 是否包含在字符串中,如果是,则返回 sub 所在开始的索引,否则返回 -1 |
| index(sub) | 与 find() 类似,只不过当 sub 在字符串中不存在时,会报错误 |
| rfind(sub) | 从右往左找子串在字符串的某个索引 |
| count(sub) | 计算 sub 在字符串中出现的总次数 |
字符串的修改方法,指的是修改字符串中的数据。
| 函数名 | 含义 |
|---|---|
| replace(old, new) | 用于将字符串中的 old 内容替换成 new 内容 |
| split(sep) | 使用指定内容 sep 来对字符串进行切割 |
| strip() | 用于去掉字符串前后的空白内容 |
3.2 列表
列表类型为 list,是 Python 中的一种常见类型。
列表可以存放各种数据类型的数据,且列表的长度会随着添加数据的变化而变化。
列表语法:
变量名 = [元素1,元素2,元素3,...]
说明:列表的多个元素之间使用 , 逗号分隔。
# (1)定义一个列表变量1,用于存放几个知名大学名称;
list1 = ["清华大学", "南开大学", "南昌大学", "东南大学", 35]
print(list1)
# (2)定义一个列表变量2,用于存放某学生的姓名、年龄、存款、是否男生等信息;
list2 = ['张三', 38, 0, True]
print(list2)
# (3)思考:要把字符串Python转换为列表list类型的值,该怎么做?
str1 = "Python"
print(list(str1)) # ['P', 'y', 't', 'h', 'o', 'n']
基础操作:
获取列表的元素和长度的方式与字符串一样。
(1)获取列表元素语法:
变量名[索引值]
说明:索引值是从 0 开始计算的。
(2)列表长度的表示方式:
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量 s 的长度或元素个数(长度值是从 1 开始计算的) |
索引与长度的关系可表示为:最大索引值 = 长度 - 1
# (1)获取知名大学名称列表变量的元素总个数;
list1 = ["a大学", "b大学", "c大学", "d大学", 35]
list_len = len(list1)
# (2)获取列表变量的第1个和最后一个位置对应的元素值;
print(list1[0])
print(list1[list_len - 1])
# (3)思考:若直接访问不存在的第100个元素值,会怎样?
# IndexError: list index out of range
# 索引不能超出列表的长度-1
print(list1[100])
(3)遍历列表
# (1)定义一个列表变量,用于存放水果信息,内容为:苹果、香蕉、西瓜、菠萝等;
list1 = ['苹果', '向日葵', '香蕉', '菠萝']
# (2)使用for循环来遍历元素;
for element in list1:
print(element)
# (3)使用while循环来遍历元素
index = 0
while index < len(list1):
print(list1[index])
index += 1
常见操作:
| 函数名 | 含义 |
|---|---|
| append(x) | 用于在列表结尾处,添加数据内容 x。 |
| insert(index, x) | 用于在列表索引 index 处,新增一个元素 x。 |
| extend(x) | 用于给列表添加另一个列表的所有元素内容,并形成一个完整列表。 |
| remove(x) | 删除列表元素值 x。 |
| del 变量名[索引] | 根据索引值,删除列表的某个元素。 |
| 变量名[索引] = 值 | 根据索引值,来修改列表中的某个元素值。 |
| len(s) | 返回 s 的长度或元素个数。 |
| in | 判断指定数据是否在某个列表序列中。如果在就返回 True,否则返回 False。 |
| reverse() | 将列表进行倒序,即输入顺序与输出顺序相互倒过来。 |
| sort([reverse=False]) | 对列表进行从小到大排序。当设置 reverse=True 可改为由大到小排序。 |
3.3 元组
定义元组时,需要使用 () 小括号,用,逗号隔开各个元素,并且元组的元素可以是不同类型的数据。
虽然元组从表面上看与列表类似,比如:
列表: [1, 2, 3, 4]
元组: (1, 2, 3, 4)
特别注意,元组的元素只能用来查询,且元素不可以修改、不可以删除、也不可以添加。
元组语法:
变量名 = (元素1,元素2,元素3,...)
遍历元组:
# (1)定义一个元组变量
phone_tuple = ('a', 'b', 'c', 'd', 'e', 'f')
print(phone_tuple)
# (2)for
for element in phone_tuple:
print(element)
# (3)while
index = len(phone_tuple) - 1
while index < len(phone_tuple):
print(phone_tuple[index])
index -= 1
常见操作:
| 函数名 | 含义 |
|---|---|
| 元组变量名[索引] | 按索引值查找数据。 |
| index(x) | 查找某个数据,当数据不存在时会报错,语法和列表、字符串的 index() 方法相同。 |
| len(x) | 表示元组中元素的总个数。 |
| in | 用于判断元素是否出现在元组中。e.g. if "Hello" in x: |
3.4 字典
Python 字典需要使用 {} 引起来,且元素形式为键值对。键值对,可以理解为一一对应的关系,即可以通过键找到值。
字典语法:
变量名 = {键1:值1, 键2:值2, ...}
使用 Python 中的字典定义一本书:
book1 = {"name":"新华字典", "page":568, "price":46.5}
- 键、值组合在一起,形成了字典的元素;
- 字典元素的键是唯一的;字典元素的值可以重复;
常见操作:
(1)查找元素
变量名[键]
当访问不存在的键时,提升稳定性,可使用如下方式:
| 函数名 | 含义 |
|---|---|
| get(key[, default]) | 返回指定键 key 对应的值,若值不在字典中,则返回默认值。 |
(2)添加元素
添加元素指的是:给字典添加新元素内容。
变量名[键] = 值
说明:当要添加多个元素时,则执行多次添加元素的操作。
(3)删除元素
删除元素指的是:删除字典的某元素,或者清空字典的所有数据。
| 函数名 | 含义 |
|---|---|
| del 变量名[键] | 删除指定元素 |
| clear() | 清空字典的所有元素内容 |
(4)修改元素
修改元素指的是:对已有元素进行修改,当成功修改后,则会用最新修改的值替换原有值。
变量名[键] = 值
(5)字典遍历方法
当要遍历字典的元素内容,即获取字典的键、值。
常用方法:
| 函数名 | 含义 |
|---|---|
| keys() | 以列表的形式,返回一个字典所有的键。 |
| values() | 以列表的形式,返回一个字典所有的值。 |
| items() | 返回由键值组成的序列,主要应用于遍历字典。 |
举例:
# (1)定义一个字典变量,存放一个学生的信息:姓名、住址、年龄等;
stu_dict = {
"name" : "刘源",
"age" : 27,
"address" : "NanJing"
}
# (2)获取字典变量中的所有键,并输出【键 -> 值】形式结果;
key_list = stu_dict.keys()
print(key_list)
for key in key_list:
print(f"{key} -> {stu_dict[key]}")
# (3)获取字典变量中的所有值并输出;
value_list = stu_dict.values()
print(value_list)
for value in value_list:
print(value)
# (4)获取字典变量中的所有键、值序列;
items = stu_dict.items()
print(items)
for kv in items:
# print(kv)
key = kv[0]
value = kv[1]
print(f"{key} --> {value}")
3.5 补充
(1)可以运用于 Python 容器的运算符
| 运算符 | 描述 | 支持的容器类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典 |
举例:
# (1)定义字符串变量,并完成+、*的运算操作
# 对字符串操作
str1 = "Hello"
str2 = str1 + " World"
print(str2)
print("-" * 40)
# 对列表操作
list1 = [1, 2, 3, 4, 5]
# TypeError: can only concatenate list (not "int") to list,列表不能与数字相加
# list2 = list1 + 3
# 列表加列表,对列表进行追加操作
list2 = list1 + list1
print(list2)
print("-" * 40)
# 列表可以与数字相乘,相当于复制
list3 = list1 * 2
# TypeError: can't multiply sequence by non-int of type 'list',列表不能与非数值进行相乘操作
# list3 = list1 * list1
print(list3)
print("-" * 40)
# 对元组进行操作
tuple1 = (1, 2, 3, 4, 5)
tuple2 = tuple1 + tuple1
print(tuple2)
print("-" * 40)
tuple3 = tuple1 * 2
print(tuple3)
print("-" * 40)
# (2)定义列表变量,并完成in、not in的运算操作
list4 = [1, 2, 3, 4, [5, 6, 7]]
print([5, 6, 7] in list4)
# print(5 not in list4)
(2)适用于 Python 容器的一些通用方法
| 方法 | 描述 |
|---|---|
| len(s) | 计算容器中的元素总个数 |
| del | 删除 |
| max() | 返回容器中元素最大值 |
| min() | 返回容器中元素最小值 |
4. 函数
4.1 基本概念
在 Python 函数中,有几个重要概念:
(1)函数名
(2)参数
(3)返回值
函数语法:
def 函数名([参数, ..]):
代码1
代码2
...
[return 具体的值]
函数的定义与调用
Python 函数需要使用 def 关键字来定义。使用方式有两步:
(1)定义函数
def 函数名():
代码1
代码2
...
(2)调用函数
函数名()
函数的参数
当在定义函数时,设定了参数,则可称该函数为:有参函数。反之,没有参数的函数,称为:无参函数。
定义有参数的函数,语法:
def 函数名(参数1,参数2,...): # 形参
...
调用函数,语法:
函数名(参数值1,参数值2,...) # 实参
- 形参是指形式参数,表示在定义函数时的参数;
- 实参是指实际参数,表示在调用函数时传递的参数值,具有实际意义。
函数的返回值
当函数完成一件事情后,最后要返回给函数的结果。
返回值语法:
def 函数名([参数1, 参数2, ...]):
代码1
代码2
...
return 值
- 若要给函数返回结果,需要使用 return 关键字;
- return 关键字的作用:把结果返回给函数,结束函数;
- 当函数没有返回值时,默认返回 None。
4.2 函数嵌套
函数的嵌套调用指的是:在一个函数中,调用了另一个函数。
def 函数1():
...
def 函数2():
...
函数1() # 调用函数1
...
使用函数的嵌套调用,我们可以把复杂问题分解成:多个简单问题,这样便于解决问题。
比如,要求多个数的平均值。此时,我们就可以拆分为两个函数:
- 函数A:用于求解多个数之和;
- 函数B:调用函数 A,获取多个数之和,接着,再使用和除以总个数,就能求解出平均值。
4.3 变量作用域
作用域指的是:内容生效的具体范围。当根据作用域的不同,可以给变量分为两类:
(1)局部变量
(2)全局变量
局部变量指的是:定义在函数内部的变量或参数,且只在函数中生效。
def 函数名(参数1,参数2,...):
...
变量名 = 值 # 局部变量只作用在函数中
...
全局变量指的是:在函数体内、外都能生效的变量。与模块中定义的函数,处于同一级别的变量,就是全局变量。
变量名 = 值 # 全局变量是指与函数处于同一级别的变量
def 函数名(...):
...
# 变量名 = 值
注意:当函数中的局部变量与全局变量同名时,在函数中使用的是局部变量的值。
需要注意的是,当要修改全局变量的值时,记得提前使用 global 进行声明。
# 声明
global 变量名
# 修改值
变量名 = 修改后的值
举例:
number = 18
def func1(a):
number = a # Warning: Shadows name 'number' from outer scope
def func2(a):
global number
number += a
func1(10)
print(number) # 18
func2(10)
print(number) # 28
4.4 函数多种参数
a. 位置参数
位置参数指的是:调用函数时,根据函数定义的参数位置来传递数值。
def 函数名(参数1,参数2,...):
...
函数名(值1,值2,...)
案例:
# (1)定义一个使用格式化符号替换数据,且显示姓名、年龄的函数;
def show_info(name, age):
print("*" * 50)
print("姓名:%s" % (name))
print("年龄:%s" % (age))
print("*" * 50)
# (2)调用函数,展示形成【个人名片】的样式。
show_info("张三", '18')
在给位置参数传递值时,要注意参数的个数、类型和顺序。
b. 关键字参数
关键字参数指的是:调用函数时,可以通过【键 = 值】的形式指定参数。
使用关键字参数后,可以让函数更加清晰、容易使用,同时也简化了传递参数的要求,比如不需要关注参数的个数、类型和顺序。
def 函数名(参数1,参数2,...):
...
函数名(参数1=值, 参数2=值,...)
说明:调用函数时,参数名必须要与定义函数时的名称保持一致。
案例:
# (1)定义一个使用格式化符号替换数据,且显示姓名、年龄的函数;
def show_info(name, age):
print("*" * 50)
print("姓名:%s" % (name))
print("年龄:%s" % (age))
print("*" * 50)
# (2)调用函数,展示形成【个人名片】的样式。
show_info('18', "张三")
# 使用关键字参数方式调用
show_info(age=18, name='李四')
c. 缺省参数
有时候,缺省参数也叫默认参数。
缺省参数是指:在定义函数时,就为参数提供默认值。在调用函数时,就可以不用传递默认参数的值。如果给缺省参数传递了数值,则以传递的值为准。
缺省参数语法:
# 缺省参数需要定义在最末尾!
def 函数名(参数1,参数2,...,参数n=值):
...
# 若给函数定义了缺省参数,则在调用函数时可以省略该参数值的传递
函数名(值1,值2,...[值n])
举例:
# (1)定义一个显示姓名、年龄、性别的函数,且默认性别为男;
def show_info(name, age, sex='男'):
print("*" * 50)
print(f"姓名为:{name}")
print(f"年龄为:{age}")
print(f"性别为:{sex}")
print("*" * 50)
# (2)调用函数,观察程序执行结果;
show_info('张三', 18)
show_info('张三', 18, '女')
show_info(name='张三', age=28)
show_info(name='张三', age=28, sex='女')
# (3)思考1:可以定义多个缺省参数吗?
def show_info2(name='张三', age=99, sex='男'):
print("*" * 50)
print(f"姓名为:{name}")
print(f"年龄为:{age}")
print(f"性别为:{sex}")
print("*" * 50)
show_info2('李四')
show_info2()
# (4)思考2:能否把缺省参数放在前面呢?
# non-default parameter follows default parameter
# 默认参数后不能有非默认参数
# def show_info3(name='张三', age=99, sex):
# print("*" * 50)
# print(f"姓名为:{name}")
# print(f"年龄为:{age}")
# print(f"性别为:{sex}")
# print("*" * 50)
d. 不定长参数
不定长参数也叫可变参数。
通常情况下,不定长参数用于在不确定调用函数时,要传递多少个参数的场景,当然也可以不传递参数。
而当要调用函数时,可以给 *args 传递位置参数,给 **kwargs 传递关键字参数,这样显得更加方便。
不定长参数语法:
def 函数名(参数1, ..., *args, **kwargs):
...
函数名(值1, 值2, 值3, ..., 参数1=值, 参数2=值,...)
举例:
#(1)定义函数1,使用不定长参数*args求多个数之和;
def get_sum1(*args):
print(args)
# 定义结果的和
sum1 = 0
# 求和
for i in args:
sum1 += i
print(sum1)
# 不定长参数可以传入不同数据类型的实参,但处理时需要有对应的数据类型
# get_sum1(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, '15')
#(2)定义函数2,使用不定长参数**kwargs求多个数之和;
def get_sum2(**kwargs):
print(kwargs)
# 定义结果的和
sum1 = 0
for v in kwargs.values():
sum1 += v
print(sum1)
get_sum2(a=1, b=2, c=1, d=2, e=3, f=4, g=5, h=6)
# (3)综合两个函数,合并在一起完成求多个数之和;
def get_sum3(*args, **kwargs):
sum1 = 0
sum2 = 0
for num in args:
sum1 += num
for num in kwargs.values():
sum2 += num
return sum1 + sum2
print(get_sum3(10, 20, 30, 90, 100, a=20, b=30, c=9))
4.5 拆包
把组合形成的元组形式的数据,拆分出单个元素内容。
变量名1,变量名2,... = 结果
举例:
# (1)在一个函数中,使用return返回求解两个数的和、差;
def get_sum_sub(num1, num2):
sum = num1 + num2
sub = num1 - num2
return sum, sub
result1 = get_sum_sub(1, 2)
print(result1[0])
print(result1[1])
a, b = get_sum_sub(1, 2)
print(a)
print(b)
# (2)使用items()方式遍历处理字典中存储的学生信息各个键与值;
stu_dict = {"name": "刘源", "age": 28, "gender": '男'}
for item in stu_dict.items():
print(item[0], item[1])
# 遍历字典时进行拆包遍历
for key, value in stu_dict.items():
print(f'{key}: {value}')
(1)当要把一个组合的结果快速获取元素数据时,可以使用拆包来完成;
(2)对列表、元组数据结果,都可以使用拆包方式。
交换变量值:
a = 100
b = 200
b, a = (a, b)
print(a, b)
4.6 引用传递
引用可以通俗的称为内存地址值。在 Python 中,引用有两种表现形式:
(1)十进制数 5040624
(2)十六进制数 0x45AC6
在 Python 中,变量值是通过引用来传递的。
查看引用语法:id(变量名),我们可以把 id() 值理解为变量所在内存的地址值。
is 用于比较两个对象的身份(即它们是否是同一个对象)。如果两个对象是同一个对象,is 将返回 True;否则返回 False。这与比较两个对象的值是否相等的 == 操作符不同。
举例:
# 定义一个变量x,查看变量的引用值;
x = 100
print(id(x)) # 4317195632
def get_sum(a, b):
return a + b
# 函数带括号,表示调用的是函数返回值
print(get_sum(1, 2)) # 3
# 函数不带括号,表示是函数本身就是函数的引用
print(get_sum) # <function get_sum at 0x1008fe8b0>
print(id(get_sum)) # 4304398512
print(id(get_sum(1, 2))) # 4317192528
# 思考:有两个列表变量[1, 2],分别使用==和is去比较,结果如何?
list1 = [1, 2, 3, 4, 5]
list2 = [1, 2, 3, 4, 5]
# == 比较的是两个容器中的值
# is 比较的是两个容器的地址值
print(list1 == list2) # true
print(list1 is list2) # False
# print(1 is 1) # "is" with a literal. Did you mean "=="?
print(id(list1)) # 4339921344
print(id(list2)) # 4339921280
print(id(128)) # 4343738608
print(id(128)) # 4343738608
a = 1
b = 1
print(a == b) # True
print(a is b) # True
# 字符串中内容相同时,地址引用一样
str1 = 'abc'
str2 = 'abc'
print(str1 == str2) # True
print(str1 is str2) # True
print(id(str1)) # 4330560688
print(id(str2)) # 4330560688
当定义函数时设定了参数,则在调用函数时也需要传递参数值。当给函数传递参数时,其本质就是:把引用当做参数进行传递。
4.7 匿名函数
定义匿名函数需要使用 Lambda 关键字,可以创建小型匿名函数。匿名函数表示没有名字的函数,这种函数得名于省略了用 def 关键字声明函数的标准步骤。
定义匿名函数语法:
lambda 参数列表 : 表达式
调用匿名函数语法:
函数名([参数列表])
在实际应用中,为便于简化函数传递处理,我们可以使用 Lambda 表达式作为参数进行传递,但要注意:传递的是一个引用。
def func1(a, b):
return a - b
def func2(a, b):
return a + b
def func3(a, b):
return a * b * 100
def func4(a, b):
return a * b
# (1)把lambda表达式当作参数传递给函数;
def get_sum(func):
print("*" * 50)
a = 100
b = 200
print(func(a, b))
# get_sum(func1)
# (2)求解两个数之和,注意:在函数中定义变量并传递。
get_sum(lambda a, b: a * b - 10000 + 20)
# 当一个函数比较简单且仅使用一次时,建议使用lambda
5. 文件/异常/模块
5.1 文件操作
说明:
(1)目录就是可以用于存放多个文件、目录的集合;[os模块]
(2)文件是用于记录数据内容的,通常是有后缀名的。[file对象]
文件可以用来存储数据。若根据文件内容的不同来给文件分类,可分为:
- 文本类型:存放文字类数据,读写时使用 r、w;
- 二进制原始数据类型:存放二进制 bytes 数据,比如图片、音频、视频等,读写时使用 rb、wb;
访问模式 r 表示 read,即读;访问模式 w 表示 write,即写。
在现实生活中,怎么记录电子笔记?
(1)新建一个doc文件,使用办公软件打开;
(2)写入一些笔记,笔记写完了,然后保存信息;
(3)关闭办公软件。
类似地,在 Python 中操作文件记录信息的步骤:
(1)打开文件,或新建一个文件 open()
(2)读取或写入数据内容 read() / write()
(3)关闭文件 close()
说明:无论操作文件的过程多么复杂,这个步骤基本是一致的。
(1)打开文件
在操作一个文件前,需要先打开文件。
| 函数名 | 含义 |
|---|---|
| open(name, mode) | 创建一个新文件或打开一个已经存在的文件,name 指的是文件名,mode 指的是访问模式。 |
常见的 mode 访问模式有:
| 模式 | 描述 |
|---|---|
| r | 以读数据的方式打开文件,这是默认模式,可以省略。 |
| rb | 以读二进制原始数据的方式打开文件。 |
| w | 以写数据的方式打开文件。如果文件已存在,则打开文件写入数据是会覆盖原有内容。如果文件不存在,则创建新文件。 |
| wb | 以写二进制原始数据的方式打开文件。 |
| a | 使用追加内容形式,打开一个文件。通常用于写数据,此时会把新内容写入到已有内容后。 |
(2)读数据
在读取文件数据前,该文件必须已存在。
| 函数名 | 含义 |
|---|---|
| read() | 从某文件中,一次性读完整的数据。 |
| readlines() | 按行的方式把文件中的完整内容进行一次性读取,并返回一个列表。 |
| readline() | 一行一行读文件中的数据内容。 |
说明:当访问模式有 r 时,可以读数据。
(3)写数据
在写文件数据前,文件若不存在,则创建一个新文件。
| 函数名 | 含义 |
|---|---|
| write(seq) | 给某文件写数据。 |
说明:当访问模式有 w 时,可以写数据;当使用访问模式 a 时,用于追加数据内容,也可以写入数据。
(4)关闭文件
当每次打开文件及使用完毕后,都需要进行关闭文件,用于释放系统内存资源。
| 函数名 | 含义 |
|---|---|
| close() | 关闭文件。 |
总结:
(1)读数据时使用 r 模式,写数据时使用 w 模式;
(2)不管一个文件有多么复杂,操作步骤都是:打开文件、读/写数据、关闭文件。
【例一】向文件写数据
# (1)给test.txt文件分别写入数据:Hello World、123456;
# 打开文件
# FileNotFoundError: [Errno 2] No such file or directory: './data/test.txt'
# 写文件时,文件不存在时会自动创建,但是目录不存在会报错
file = open("./data/test.txt", "w")
# 操作文件
file.write('Hello world\n')
file.write('123456')
# (2)思考1:如果要给文件写入内容:程序员,会怎样?
# 写入中文后,查看时需要使用GBK字符集
file.write('程序员')
# print("已成功写入数据!")
# (3)思考2:如果要在文件原有内容基础上,再追加内容:123123,该怎么做呢?
file = open('./data/test.txt', 'a')
file.write("\n123123")
file.close()
【例二】从文件读数据
| 函数名 | 含义 |
|---|---|
| read() | 从某文件中,一次性读完整的数据(读取文件数据之前,要保证文件已经存在) |
为了简化读写数据的操作,也可以使用语法:
with open(xxx, xx) as 变量名:
变量名.read()
# 变量名.write(xxx)
# (1)读取test.txt文件的数据内容,并输出;
# 打开文件
file = open("./data/test.txt", "r", encoding="UTF-8")
# 读取文件
print(file.read())
# 关闭文件
file.close()
# (2)简化写法,省略关闭文件步骤
with open("./data/test.txt", "r", encoding="UTF-8") as file:
texts = file.read()
print(texts)
print(texts)
其他方式读取:
| 函数名 | 含义 |
|---|---|
| readlines() | 按行的方式把文件中的完整内容进行一次性读取,并返回一个列表。 |
| readline() | 一行一行读文件中的数据内容。 |
# (1)读取test.txt文件的数据内容,并输出;
file = open('./data/test.txt', 'r')
# (2)分别使用readlines()、readline()方式来完成。
# 操作文件
# 使用readlines()读取文件
# lines = file.readlines()
# for line in lines:
# print(line, end="")
# 使用readline读取一行数据时,会创建一个指针就是偏移量,每调用一次readline()指针自动向下移动
# print(file.readline())
# print(file.readline())
# 如果想使用readline读取全部,需要使用循环
while True:
line = file.readline()
# if not line:
# break
if len(line) == 0:
break
print(line)
# 关闭文件
file.close()
5.2 os 模块
Python 中的 os 模块包含有操作系统所具备的功能,如查看路径、创建目录、显示文件列表等。
os 模块是 Python 标准库,可直接导入使用:
# 导入os模块
import os
在 Python 中,os 模块的常用函数分为两类:
(a)通过 os.path 调用的函数
(b)通过 os 直接调用的函数
在 Python 的 os 模块中,通过 os.path 常用函数:
| 函数名 | 含义 |
|---|---|
| exists(pathname) | 用来检验给出的路径是否存在。 |
| isfile(pathname) | 用来检验给出的路径是否是一个文件。 |
| isdir(pathname) | 用来检验给出的路径是否是一个目录。 |
| abspath(pathname) | 获得绝对路径。 |
| join(pathname,name) | 连接目录与文件名或目录。 |
| basename(pathname) | 返回单独的文件名。 |
| dirname(pathname) | 返回文件路径。 |
说明:上述常用函数需要使用 os.path 来进行调用。
在 Python 的 os 模块中,可直接通过 os 调用的常用函数:
| 函数名 | 含义 |
|---|---|
| getcwd() | 获得当前工作目录,即当前 Python 脚本工作的目录路径。 |
| system(name) | 运行 shell 命令。 |
| listdir(path) | 返回指定目录下的所有文件和目录名,即获取文件或目录列表。 |
| mkdir(path) | 创建单个目录。 |
| makedirs(path) | 创建多级目录。 |
| remove(path) | 删除一个文件。 |
| rmdir(path) | 删除一个目录。 |
| rename(old, new) | 重命名文件。 |
举例:
import os
# (1)获取当前工作目录;
work_path = os.getcwd()
print(work_path)
# (2)获取day05/date下的文件或目录列表信息;
dir_list = os.listdir(work_path)
print(dir_list)
# (3)思考:若要在data下新建hello/world/python目录,该怎么做呢?
new_path_name = 'data/hello/world/pyth0n'
if not os.path.exists(new_path_name):
# FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: './data/hello/world/pyth0n'
os.makedirs(new_path_name)
print("已创建成功!")
else:
print("目录或者文件已存在,不要重复创建!")
5.3 异常
异常指的是 Python 程序发生的不正常事件。有时候,异常可称为错误。
当检测到一个错误时,Python 解释器就无法继续执行,反而出现了一些错误的提示,这就是异常,也就是我们常说的 BUG。
举例:
# (1)定义一个列表变量;
list1 = [1, 2, 3, 4, 5]
# (2)获取一个远超列表索引值的元素,报错:IndexError。
# IndexError: list index out of range
print(list1[10])
当程序中遇到了异常时,通常程序会出现崩溃情况。为了不让程序崩溃,就可以使用异常来快速处理。
(1)异常处理语法
try:
可能发生异常的代码
except:
如果出现异常时, 执行的代码
(2)捕获多个异常
捕获异常是处理异常的标准形式。通常情况下,捕获异常分为三类:
-
捕获一个指定异常
try: 可能发生异常的代码 except 异常类型名: 当捕获到该异常类型时,执行的代码 -
捕获多个异常
try: 可能发生异常的代码 except (异常类型1,类型2,...): 如果捕获到该异常类型时,执行的代码 -
捕获所有异常
try: 可能发生异常的代码 except Exception[ as 变量]: 当捕获到该异常类型时,执行的代码
(3)异常的其他关键字
在捕获异常过程中,有两个关键字 else、finally 需要注意:
- else:表示如果没有异常时,要执行的代码;
- finally:表示的是无论是否有异常,都要执行的代码。
当把 else、finally 都放入到捕获异常中:
try:
可能发生异常的代码
except 异常类型:
当捕获到该异常类型时,执行的代码
else:
没有异常信息时,执行的代码
finally:
无论如何,都会执行的代码
当使用 finally 部分代码时,可以用于完成一些必须完成的操作,例如关闭文件、关闭系统资源等。
(4)异常具有传递性
当一段可能发生异常的代码,发生了异常时,若不处理,则会传递给调用处。
def func1():
try:
data = [1,2,3,4,5]
print(data[10])
except IndexError:
print('IndexError')
def test():
func1()
test()
5.4 模块
模块指的是:以 .py 结尾的 Python 文件。
注意:模块名属于标识符。
在模块中,能定义函数、变量和类等,也能包含其他一些可执行的代码。
a. 导入模块
使用模块前,要先导入模块。
导入模块有 3 种方式:
# 1
import 模块名
import 模块名1[, 模块名2, ...] # 不推荐
# 2
from 模块名 import 功能1[, 功能2, 功能3...]
# 3
from 模块名 import *
【方式一】import 关键字导入模块语法:
import 模块名1
import 模块名2
......
此外,也可以使用:
import 模块名1[, 模块名2, ...] # 不推荐
调用模块中的函数语法
模块名.函数名([值1, 值2, ...])
为便于操作导入模块。来看看 math。模块的函数:
| 函数名 | 含义 |
|---|---|
| pow(x, y) | 返回 x^y(x 的 y 次方)的值 |
| sqrt(x) | 返回数值 x 的平方根 |
举例:
# (1)使用import导入math模块;
import math
# (2)求解2^10^ = 1024的值;
print(math.pow(2,64))
# (3)求解9的平方根为多少?
print(math.sqrt(9))
【方式二】from xx import xx 导入模块功能语法:
from 模块名 import 功能1[, 功能2, 功能3...]
此外,也可以使用:
from 模块名 import 功能1 # 不推荐
from 模块名 import 功能2
......
调用模块中的功能语法:
功能1()
功能2()
为便于操作导入模块。来看看 math 模块的函数:
| 函数名 | 含义 |
|---|---|
| ceil(x) | 返回数值 x 的上入整数,如 math.ceil(6.3) |
| floor(x) | 返回数值 x 的下舍整数 |
举例:
# (1)使用from - import导入math模块的几个功能;
from math import ceil, floor
# (2)求解3.14的上入整数;
print(ceil(3.14))
# (3)求解3.14的下舍整数。
print(floor(3.14))
【方式三】from xx import * 导入模块语法:
from 模块名 import *
说明:表示导入所有功能。
举例:
# (1)使用from - import *导入模块;
from math import *
# (2)求解8的平方根、10^3^的值;
print(sqrt(8))
print(pow(10, 3))
# (3)思考:若要使用π,可以怎么做?
print(pi)
print(e)
- 在 Python 中,* 通常表示所有;
- 不推荐使用该方式导入模块,因为导入模块中所有功能时,加载缓慢。
【取别名】导入模块时,也可以给模块或功能取别名:
import 模块名 as 别名
from 模块名 import 功能 as 别名
举例:
import math as m
from math import sqrt as sq
print(m.pow(2, 10))
print(sq(9))
b. 制作模块
(1)定义与调用模块
有时候,模块也称为库,当一个模块具有强大功能时,也可称为框架。在 Python 中,模块分为三类:
- 自定义模块:定义后,直接使用;
- 标准库:直接导入使用;
- 扩展库(第三方库):需要先安装库,然后再使用。
每个 Python 文件都可以作为一个自定义模块而存在。
注意:
- 给模块名取名时,建议所有字母均小写;
- 当一些功能比较通用且频繁使用时,可以采用自定义的形式把功能进行封装在自定义模块中;
- 自定义模块名不要与 Python 已有库名相同,否则会出错。
(2)__name__ 变量
[Q] 为了提升程序的稳定性。当编写完一个自定义模块的功能后,需要在模块中添加一些测试代码。而当在另一个模块中调用自定义模块时,会发现:刚刚添加的测试代码也会一并执行。该怎么解决呢?
[A] 每个模块中都有的 __name__ 变量(前后是双下划线),且 __name__ 在当前模块下测试输出结果为 __main__,当在另外的模块里调用输出时,结果是当前模块名。
通常地,在测试代码时,需要添加判断 __name__ 变量的语法:
if __name__ "__main__":
...
举例:
##### mytool.py #####
def add(a, b):
return a + b
def sub(a, b):
return a - b
if __name__ == '__main__':
print(add(100, 200))
print("程序运行正常")
print(f"这是mytool中的:{__name__}")
##### test.py #####
import mytool
if __name__ == '__main__':
print(mytool.add(4, 3))
print(mytool.sub(5, 3))
print(f"这是主代码中的:{__name__}")
(3)__all__ 变量
当一个模块文件中有 __all__ 变量,当使用 from xxx import * 导入时,只能导入这个列表中的元素。
__all__ = ["函数名1", "函数名2", xxx]
可以使用 __all__ 变量来限定 * 的范围。
举例:
# 限定 * 的导入范围
__all__ = ['add', 'mul']
# 求和
def add(a, b):
return a + b
# 求差
def sub(a, b):
return a - b
# 求积
def mul(a, b):
return a * b
# 求商
def div(a, b):
return a / b
from myutil import *
print(add(2,3))
# print(sub(2,3))
print(mul(2,3))
# print(div(2,3))
6. 面向对象
面向对象思想就不多说了,dddd~
6.1 类与对象
要掌握 Python 面向对象的特性,首先需要了解两个重要概念:类、对象。
- 类是抽象的概念,指的是:对某些事物的描述。
- 对象是具体的概念,指的是:实实在在存在的个体。
(1)类的定义
类是抽象的概念,指的是:对某些事物的描述。简单地说,类就是一个模板。
定义 Python 类语法:
class 类名:
def 方法名(self):
...
# 其他方法...
举例:
class Car:
def run(self):
print("汽车飞速行驶!")
类是抽象的,仅定义了类并执行,没有执行效果。
(2)对象的使用
对象是具体的概念,指的是:实实在在存在的个体。简单的说,对象就是通过类创建出来的实体。
创建对象语法:
对象名 = 类名()
调用方法语法:
对象名.方法名()
说明:不用给 self 参数传递参数值
举例:
class Car:
def run(self):
print("汽车飞速行驶!")
# (1)用对象模拟制造出一台小轿车
car = Car()
# (2)小轿车能跑起来
car.run()
(3)self 关键字
self 是一个 Python 关键字,在面向对象中 self 指向了对象本身。比如,创建了一个学生对象。
# 定义类
class Student:
pass
# 创建对象
student = Student()
举例:
# (1)定义一个学生类,且学生在努力学习;
# (2)创建一个对象,同时输出对象名、self,了解self的含义;
# (3)再到学生类中,定义一个学生睡觉的行为,并分别通过对象名、self调用方法;
# (4)执行程序,观察self的效果。
class Student:
def study(self):
print("=" * 30)
print("正在努力学习!!!")
print("=" * 30)
def sleep(self):
self.study()
print(self) # <__main__.Student object at 0x0000026F6E636A60>
Student.study(self)
if __name__ == '__main__':
stu1 = Student()
print(stu1) # <__main__.Student object at 0x000001CD9B226A60>
stu1.sleep()
stu2 = Student()
print(stu2)
stu2.sleep()
# Student.study() # 类不能直接调用属性方法,因为没有self参数
6.2 对象属性
仔细观察后会发现,属性可以简单理解为与生俱来的特征,比如一个人的姓名、年龄、身高、体重等都是属性。而属性在 Python 面向对象中,直接使用变量来表示。需要注意的是,一个对象通常包含两部分:方法、属性。
- 在类外面访问属性,分为:
- 添加属性语法:
对象名.属性名 = 值 - 获取属性语法:
对象名.属性名
- 添加属性语法:
- 类内部获取属性:
self.属性// 可以简单的把 self 理解为对象本身
案例:
# (1)在类外部添加2个属性:车颜色、车品牌;
# (2)在类内部定义一个show()方法来获取属性值信息。
class Car:
def run(self):
print("开车上路!滴滴滴~")
def show(self):
# 在类内部获取属性可以使用【self.属性名】方式
print(f"颜色为:{self.color},品牌为:{self.brand}")
if __name__ == '__main__':
# 通过类实例一个对象
car1 = Car()
# 添加属性
car1.color = "红色"
car1.brand = "bwm"
# 获取属性
# print(f"颜色为:{car.color},品牌为:{car.brand}")
car1.show()
# car2 = Car()
# car2.show()
小结:
- 在类内部获取属性和实例方法,通过 self 获取;
- 在类外部获取属性和实例方法,通过 对象名 获取;
- 一个类的多个对象的属性是各自保存的,都有各自独立的地址;但是实例方法是所有对象共享的,只占用一份内存空间,类会通过 self 来判断是哪个对象调用了实例方法。
6.3 魔法方法
魔法方法指的是:可以给 Python 类增加魔力的特殊方法。
有两个特点:
- 总是被双下划线所包围;
- 在特殊时刻会被自动调用,不需要开发者手动去调用。
语法:__魔法方法名__()
在 Python 中,常用的魔法方法有:
| 魔法方法名 | 描述信息 |
|---|---|
__init__(self [, ...]) |
构造器,当一个对象被初始化创建时,会被自动调用。 |
__str__(self) |
输出对象名时,若不想直接输出内存地址值,可重写 str() 方法。 |
__del__(self) |
当一个对象被删除或销毁时,会被自动调用。 |
(1)__init__() 方法
在 Python 中,当新创建一个对象时,则会自动触发 __init__() 魔法方法。
| 魔法方法名 | 描述信息 |
|---|---|
__init__(self [, ...]) |
构造器,当一个对象被初始化创建时,会被自动调用。 |
根据是否给 __init__() 魔法方法传递参数值,可分为:
- 无参
__init__()方法 - 有参
__init__()方法
无参 __init__() 方法语法:
class 类名:
def __init__(self):
...
说明:当仅需在类内部使用与初始化属性时,可以使用该方法。
# (1)给小轿车这个对象默认设置颜色和轮胎数为:黑色、3个轮胎;
# (2)创建对象后,直接获取属性结果。
class Car:
def __init__(self):
"""
构造函数
在类的内部添加对象属性
"""
self.color = '黑色'
self.number = 3
# 类名()本质上就是调用这个类的__init__()方法
car1 = Car()
car2 = Car()
# 可以在类的外部修改对象的属性
car1.color = '大红色'
# 在类的外部获取对象的属性
print(car1.color)
print(car1.number)
# 不同对象的属性没有关系
print(car2.color)
当想要在创建对象时,就设定属性值时,可以使用有参 __init__() 方法。语法:
class 类名:
def __init__(self, 参数1, 参数2,...):
...
- 不需要给 self 传递参数值
- 传递参数个数的计算公式为:传递参数个数 = 定义方法后的参数总个数 - 1
举例:
# (1)直接在创建车对象时,初始化设定颜色、轮胎数值;
# (2)在类外部直接获取对象属性值。
class Car:
def __init__(self, color, number):
"""
有参构造函数
:param color: 初始化时传入的color
:param number: 初始化时传入的number
"""
self.color = color
self.number = number
# 实例化Car对象
# 类名()本质上就是调用了__init__()方法
car1 = Car('red', 3)
car2 = Car('blue', 4)
# car1.color = 'red'
car2.color = 'green'
# 获取对象属性
print(car1.color)
print(car1.number)
print(car2.color)
(2)__str__() 方法
内存地址值,也称为引用。表现形式有两种:
(1)十进制数 5040624
(2)十六进制数 0x45AC6
说明:当直接输出对象名时,默认输出的是对象的内存地址值。
当在类中定义了 __str__ 方法,则获取的是该方法返回的数据结果。
| 魔法方法名 | 描述信息 |
|---|---|
__str__(self) |
输出对象名时,若不想直接输出内存地址值(默认),可重写 str() 方法。 |
__str__ 方法语法:
class 类名:
def __str__(self):
...
return 字符串型的结果
举例:
class Car:
def __init__(self, color, price):
self.color = color
self.price = price
def show(self):
"""
用来显示对象的相关属性
:return:
"""
print(f"汽车的颜色为:{self.color},汽车的价格为:{self.price}")
def __str__(self):
"""
如果在自定义类中重写了__str__()方法,就会用重写的返回值覆盖原来的地址值
:return: 必须返回字符串类型
"""
return f"汽车的颜色为:{self.color},汽车的价格为:{self.price}"
if __name__ == '__main__':
car1 = Car('red', 100)
car2 = Car('blue', 200)
# print(car1) # <__main__.Car object at 0x0000018797EA6A60>
# print(car2) # <__main__.Car object at 0x0000018797EEB040>
# car1.show()
# car2.show()
print(car1)
print(car2)
(3)__del__() 方法
当删除对象时,会自动调用 __del__() 方法。
| 魔法方法名 | 描述信息 |
|---|---|
__del__(self) |
当一个对象被删除或销毁时,会被自动调用。 |
__del__() 方法语法:
class 类名:
def __del__(self):
...
举例:
class Car:
def __init__(self, brand):
"""
构造函数
:param brand: 品牌
"""
self.brand = brand
def __del__(self):
"""
当前销毁对象时会自动调用这个方法
:return:
"""
print(f"{self.brand}会销毁了!!!")
if __name__ == '__main__':
car1 = Car('benz')
# 通过对象调用__del__方法并不会销毁对象
car1.__del__()
# del 对象是手动销毁对象,会自动调用一次__del__方法
del car1
print(car1.brand)
当使用 del 对象名 时,会自动调用 __del__() 方法。当程序执行结束时,Python 垃圾回收器会自动销毁内存垃圾,此时会自动调用 __del__() 方法。
6.4 类的继承
a. 继承基础
我们知道,可以使用 class 关键字定义类。
在类的使用中,定义方式有三种:
- 类名
- 类名()
- 类名(object)
说明:区别在于类名后面是否加其他内容。
方式 1 语法:
class 类名:
...
方式 2 语法:
class 类名():
...
方式 3 语法:
class 类名(object): # 推荐
...
说明:方式 3 是定义类最常见的语法
在面向对象中,当子类继承父类后,则:子类拥有了父类的属性和方法。
class 父类名(object):
...
class 子类名(父类名):
...
建议在定义父类时,都采用 类名(object) 语法;当子类拥有了父类的属性和方法后,能提升代码的复用性。
(1)单继承
单继承指的是:一个子类继承一个父类。
class 子类名(父类名):
...
举例:
class Master(object):
def __init__(self):
self.pei_fang = "【独创古法配方】"
def make_cake(self):
print("老师傅使用古法配方制作煎饼果子!!!")
# 定义徒弟类
class TuDi(Master):
pass # pass 使得代码在语法上合法,但不会执行任何操作,它通常用在你暂时不打算实现某部分代码的情况。
if __name__ == '__main__':
xiaoming = TuDi()
# 当子类继承了父类后,子类可以拥有父类的属性和方法。
xiaoming.make_cake()
print(xiaoming.pei_fang)
【补充】在 Python 中,pass 是一个占位符语句,它的作用是让代码块保持语法上的完整性,但实际上什么也不做。通常,pass 用于以下几种情况:
- 占位符:在你定义一个类、函数或条件语句时,可能暂时不打算实现它的内容,
pass就用来占据位置,避免语法错误。 - 空方法或类:有时你希望子类继承父类的方法或类,但暂时不实现具体的功能,可以在方法或类体中使用
pass。
(2)多继承
多继承指的是:一个类同时继承了多个父类。
class 子类名(父类名1, 父类名2, ...):
...
举例:
# (1)徒弟是个爱学习的好孩子,想学习更多的摊煎饼技术;
# (2)于是,在百度搜索到暗黑学校[School],报班来培训学习如何摊煎饼;
# (3)使用多继承形式模拟程序。
# 定义师傅类,有配方的属性和摊煎饼的方法
class Master(object):
def __init__(self):
self.pei_fang = "【独创古法配方】"
def make_cake(self):
print("老师傅使用古法配方制作煎饼果子!!!")
def jueji(self):
print("心灵鸡汤!!!")
# 学校类,有配方的属性和摊煎饼的方法
class School(object):
def __init__(self):
self.pei_fang = "【科技与狠活之3d打印黑暗配方】"
def make_cake(self):
print("采用黑暗配方制作煎饼果子!!!")
# 定义徒弟子类,继承多个父类
class TuDi(School, Master):
pass
if __name__ == '__main__':
xiaoming = TuDi()
xiaoming.make_cake()
print(xiaoming.pei_fang)
# 查看当前子类同名方法的调用顺序
# [<class '__main__.TuDi'>, <class '__main__.Master'>, <class '__main__.School'>, <class 'object'>]
print(TuDi.mro())
xiaoming.jueji()
在 Python 面向对象中,继承包含:单继承、多继承、多层继承。
【补充】当子类同时继承多个父类,并调用多个父类同名方法的顺序,查看时使用:
类名.__mro__
类名.mro()
b. 方法重写
(1)方法重写
当父类的同名方法达不到子类的要求,则可以在子类中对方法进行重写。
class 父类名(object):
def 方法A(self):
...
class 子类名(父类名):
def 方法A(self):
...
举例:
# (1)徒弟非常认真学习,终于掌握了老师傅的技术;
# (2)接着,自己潜心钻研出类独门配方的全新摊煎饼技术;
# (3)使用方法重写对摊煎饼方法进行处理。
class Master(object):
def __init__(self):
self.pei_fang = "【独创古法配方】"
def make_cake(self):
print("老师傅使用古法配方制作煎饼果子!!!")
# 定义徒弟类
class TuDi(Master):
def make_cake(self):
print("潜心学习,钻研了新的配方制作煎饼果子!!!")
if __name__ == "__main__":
tudi = TuDi()
tudi.make_cake()
print(tudi.pei_fang)
print(TuDi.mro())
- 当子类中出现与父类中同名方法且参数内容保持一致时,称为方法重写;
- 当子类重写了父类方法后,子类对象优先调用执行子类方法,可以通过
子类名.mro()查看执行顺序。
(2)调用父类方法
当子类要在父类同名方法的基础上,再新增功能且要求在子类中调用同名方法时,就可以使用 super()。
super().方法名([参数1, 参数2, ...])
举例:
# (1)徒弟在培训学校学习努力,不仅掌握了学校的煎饼配方、还创办了自己煎饼果子的品牌;[配方、品牌]
# (2)配合着一起摊煎饼,做出了更加美味的煎饼果子;
# (3)使用调用父类方法在`__init__()`和摊煎饼方法中处理。
class School(object):
def __init__(self):
self.pei_fang = "学校配方"
def make_cake(self):
print("学校配方制作了美味的煎饼果子!!!")
class TuDi(School):
def __init__(self, pei_fang, brand):
self.pei_fang = pei_fang
self.brand = brand
def make_cake(self):
super().make_cake() # 调用父类的方法
print(f"子类,制作煎饼果子使用{self.pei_fang}")
if __name__ == '__main__':
tudi = TuDi("个人原创", "新品牌")
tudi.make_cake()
(3)多层继承
多层继承指的是:多级继承的关系,比如:子类继承父类 C、继续继承父类 B、继续继承父类 A 等;即一个类可能会有多级父类。
举例:
# (1)N年后,当初的徒弟也老了;
# (2)因此,徒弟想要把"有自己品牌,也有学校配方的煎饼果子"的所有技术传授给自己的小徒弟;
# (3)请试着使用多层继承的方式完成案例。
class School(object):
def make_cake(self):
print("学校制作的煎饼果子!!!")
class TuDi(School):
def make_cake(self):
super().make_cake()
print("通过学校配方改良之后煎饼果子!!!")
class TuSun(TuDi):
pass
if __name__ == '__main__':
tusun = TuSun()
tusun.make_cake()
c. 私有权限
(1)私有属性
为了更好的限制属性的访问和包含隐私,可以给属性设置私有权限。当把属性设置为私有属性后,则该属性只能被本类直接访问。
定义私有属性语法:self.__属性名
如果要从外部访问私有属性值,建议要在类中定义 set/get 方法。设置和获取私有属性值语法:
class 类名(xxx):
# 设置私有属性值[set]
def set_私有属性名(self,参数):
self.私有属性 = 参数
# 获取私有属性值[get]
def get_私有属性名(self):
return self.私有属性
(2)私有方法
当把方法设置为私有方法后,则该方法只能被本类直接访问。
定义私有方法语法:
def __方法名(self):
...
当把方法设定为私有权限后,则该方法不会被继承给子类;当子类继承了父类后,子类只会拥有父类的非私有属性和非私有方法。
6.5 类属性/方法
(1)对象属性
对象属性,有时也称为实例属性、普通属性、公有属性,或者直接叫做属性。
- 在类内部,访问对象属性语法:
self.对象属性名 - 在类外部,访问对象属性语法:
对象名.对象属性名
(2)类属性
类属性指的是:类所拥有的属性,在整个类中都可以直接使用。
定义类属性语法:
class 类名(object):
类属性名 = 值
调用类属性语法:
类名.类属性名
实际上,可以通过对象名和类名来调用类属性,但优先考虑使用【类名.类属性名】形式。
(3)类方法
类方法指的是:类所拥有的方法。要形成类方法,需满足:
- 使用装饰器
@classmethod来修饰方法; - 把方法的第 1 个参数设置为 cls。
定义类方法,语法:
class 类名(object):
@classmethod
def 类方法名(cls):
...
调用类方法语法:
类名.类方法名()
类方法一般会和类属性配合使用,尤其是私有类属性。
(4)静态方法
静态方法需要通过装饰器 @staticmethod 来修饰方法,且静态方法不需要定义任何参数。
定义静态方法,语法:
class 类名(object):
@staticmethod
def 静态方法名():
...
调用静态方法,语法:
类名.静态方法名()
(5)总结
- 实例方法:如果一个方法需要访问到对象的实例属性,可以把这个方法封装成一个对象方法;
- 类方法:如果一个方法不需要访问对象的实例属性,但是需要访问到类的类属性,可以把方法封装成一个类方法;
- 静态方法:如果一个方法不需要访问对象的实例属性,也不需要访问类的类属性时,可以把方法封装成一个静态方法。
6.6 深拷贝和浅拷贝
在 Python 中,浅拷贝和深拷贝是用于复制对象的两种方式,它们的区别在于对嵌套对象(例如列表中的列表或字典中的字典)如何处理。
(1)浅拷贝
浅拷贝指的是创建一个新的对象(如新的列表或字典),但对象中的元素(如列表的元素或字典的值)是对原始对象中元素的引用(即它们仍然指向原始对象中的相同位置)。也就是说,浅拷贝复制了外层对象,但不会复制内部嵌套的对象,它们仍然指向相同的内存地址。
| 函数名 | 含义 |
|---|---|
| copy(t) | 使用浅拷贝来拷贝信息。 |
示例:
import copy
# 创建一个包含嵌套列表的原始列表
original = [[1, 2, 3], [4, 5, 6]]
# 创建一个浅拷贝
shallow_copy = copy.copy(original)
# 修改原始列表的内部元素
original[0][0] = 999
# 打印原始列表和浅拷贝
print("Original:", original) # 输出: Original: [[999, 2, 3], [4, 5, 6]]
print("Shallow Copy:", shallow_copy) # 输出: Shallow Copy: [[999, 2, 3], [4, 5, 6]]
(2)深拷贝
深拷贝是指创建一个新的对象,并递归地复制原始对象及其所有嵌套对象。也就是说,深拷贝不仅复制了外层对象,还会复制其中所有的嵌套对象,确保它们是完全独立的,彼此之间没有任何引用关系。
| 函数名 | 含义 |
|---|---|
| deepcopy(t) | 使用深拷贝来拷贝信息。 |
示例:
import copy
# 创建一个包含嵌套列表的原始列表
original = [[1, 2, 3], [4, 5, 6]]
# 创建一个深拷贝
deep_copy = copy.deepcopy(original)
# 修改原始列表的内部元素
original[0][0] = 999
# 打印原始列表和深拷贝
print("Original:", original) # 输出: Original: [[999, 2, 3], [4, 5, 6]]
print("Deep Copy:", deep_copy) # 输出: Deep Copy: [[1, 2, 3], [4, 5, 6]]
# ----- 拷贝类对象 -----
class MyClass:
def __init__(self, name, values):
self.name = name
self.values = values
# 创建原始对象
original_obj = MyClass("Object1", [1, 2, 3])
# 使用浅拷贝创建新对象
shallow_copy_obj = copy.copy(original_obj)
deep_copy_obj = copy.deepcopy(original_obj)
# Original Obj: 4331808128 4340963904
print("Original Obj:", id(original_obj), id(original_obj.values))
# Shallow Copy Obj: 4332877616 4340963904
print("Shallow Copy Obj:", id(shallow_copy_obj), id(shallow_copy_obj.values))
# Deep Copy Obj: 4333517840 4340964480
print("Deep Copy Obj:", id(deep_copy_obj), id(deep_copy_obj.values))
# 修改对象简单属性
original_obj.name = 'other'
# other Object1 Object1
print(original_obj.name, shallow_copy_obj.name, deep_copy_obj.name)
# 修改对象复杂属性
shallow_copy_obj.values[0] = '111'
# ['111', 2, 3] ['111', 2, 3] [1, 2, 3]
print(original_obj.values, shallow_copy_obj.values, deep_copy_obj.values)
- 浅拷贝:只复制外部对象,内部的嵌套对象仍然是引用,修改内部对象会影响到拷贝。
- 深拷贝:复制整个对象,包括嵌套对象,确保拷贝对象和原始对象完全独立,修改其中一个不影响另一个。
(3)自定义拷贝行为
如果类的对象有复杂的结构或者你希望控制浅拷贝和深拷贝的行为,可以通过定义 __copy__ 和 __deepcopy__ 方法来实现自定义拷贝逻辑。
自定义浅拷贝 (__copy__)
import copy
class MyClass:
def __init__(self, name, values):
self.name = name
self.values = values
def __copy__(self):
# 创建一个新对象,但自己处理拷贝逻辑
new_obj = type(self)(self.name, self.values)
return new_obj
original = MyClass("Object1", [1, 2, 3])
shallow_copy = copy.copy(original)
自定义深拷贝 (__deepcopy__)
import copy
class MyClass:
def __init__(self, name, values):
self.name = name
self.values = values
def __deepcopy__(self, memo):
# 自定义深拷贝逻辑
new_obj = type(self)(self.name, copy.deepcopy(self.values, memo))
return new_obj
original = MyClass("Object1", [1, 2, 3])
deep_copy = copy.deepcopy(original)
(4)小结
- 浅拷贝类对象:创建新对象,但属性是引用的,如果属性是可变对象(例如列表、字典等),则修改原始对象的属性会影响拷贝对象。
- 深拷贝类对象:不仅创建新对象,而且所有的嵌套对象都会被完全拷贝,原始对象与拷贝对象完全独立,修改一个不会影响另一个。
- 你可以通过自定义
__copy__和__deepcopy__方法来控制拷贝的行为,特别是在对象包含复杂的数据结构时。
6.7 闭包
什么是闭包?
闭包是指一个函数(通常是嵌套函数),它引用了其外部函数的变量,并且能够记住这些变量,即使外部函数已经返回。
在 Python 中,当一个函数定义在另一个函数内部,并且内部函数引用了外部函数的变量,且外部函数返回了内部函数时,这个内部函数就形成了闭包。
闭包的特征:
- 闭包函数可以访问外部函数的变量。
- 外部函数的作用域(即局部变量)在闭包函数执行时仍然可用。
- 闭包需要满足函数嵌套和引用外部变量两个条件。
闭包的例子:
def outer_function(x):
# 外部函数的局部变量
def inner_function(y):
# 内部函数引用外部函数的变量 x
return x + y
return inner_function
# 调用外部函数,返回闭包函数
closure = outer_function(10)
# 闭包函数,x=10,y=5
print(closure(5)) # 输出 15
outer_function 返回了 inner_function,而 inner_function 可以访问 outer_function 中的变量 x。即使 outer_function 已经执行完并返回,inner_function 依然能够访问 x。
闭包的实际应用:
- 数据封装和隐藏:闭包可以帮助你封装数据并隐藏实现细节,比如在实际开发中经常用闭包来创建私有变量。
- 记住历史状态:闭包可以保存外部函数的状态,用于实现一些具有状态保持功能的操作,比如计数器、缓存等。
nonlocal 关键字
在闭包的使用过程中,当要在内部函数中修改外部函数的变量,需要使用 nonlocal 提前声明。nonlocal 关键字语法:
nonlocal 变量名
案例:
(1)编写一个闭包,并让内部函数去修改外部函数内的变量 a = 100;
(2)记得使用 nonlocal 变量名 提前声明,并观察效果。
# 定义闭包
def outer():
a = 100
def inner():
print("*" * 50)
# 修改外部函数中的变量
nonlocal a
a += 1
print(f"修改后的结果:{a}")
print("*" * 50)
return inner
# 调用闭包
# result = outer()
# print(result)
# result()
outer()()
6.8 装饰器
什么是装饰器?
装饰器是一个函数,它接受一个函数作为参数并返回一个新的函数。装饰器用于修改或扩展原有函数的功能,而不直接修改原函数的代码。装饰器通常用来给函数增加一些额外的功能,比如日志记录、权限检查、缓存等。
装饰器的基本原理:
- 装饰器的本质是一个闭包。
- 装饰器函数接受一个函数作为输入,并返回一个新的函数,这个新函数通常在执行时会调用原函数并进行某些额外操作。
装饰器的例子:
def decorator(func):
def wrapper():
print("Before function call") # 执行装饰器的额外操作
func() # 调用原函数
print("After function call") # 执行装饰器的额外操作
return wrapper
# 使用装饰器
@decorator
def say_hello():
print("Hello, World!")
# 调用装饰过的函数
say_hello()
# ------ 输出 ------
# Before function call
# Hello, World!
# After function call
@decorator是 Python 中的一种语法糖,它的作用是将say_hello函数作为参数传递给decorator函数,然后用返回的wrapper函数来替代原始的say_hello函数。- 通过装饰器,我们可以在不修改原函数的代码情况下,增加一些额外的功能,比如在调用原函数前后添加日志、权限检查等操作。
多个装饰器的使用:
Python 支持多个装饰器同时应用于一个函数。这些装饰器会从内到外依次应用。
def decorator_1(func):
def wrapper():
print("Decorator 1")
func()
return wrapper
def decorator_2(func):
def wrapper():
print("Decorator 2")
func()
return wrapper
@decorator_1
@decorator_2
def say_hello():
print("Hello, World!")
say_hello()
# ------ 输出 ------
# Decorator 1
# Decorator 2
# Hello, World!
@decorator_2 先应用,然后是 @decorator_1,这样就形成了一个“链式”调用。
带参数的装饰器:
装饰器也可以处理带参数的函数。为了实现这一点,装饰器内部的 wrapper 函数需要接受任意数量的参数。
def decorator(func):
def wrapper(*args, **kwargs):
print("Before function call")
result = func(*args, **kwargs)
print("After function call")
return result
return wrapper
@decorator
def add(a, b):
return a + b
print(add(3, 5))
# ------ 输出 ------
# Before function call
# After function call
# 8
当被装饰的原有函数有参有返回值时,定义的装饰器类型应该在内部函数中要有参数,也要有返回值。
7. 连接 MySQL
7.1 pymysql 模块
当要使用 Python 和 MySQL 数据库进行交互,需要借助一个第三方模块:pymysql。
在使用 pymysql 模块前,先进行安装:直接在 cmd 窗口中安装就可以了。
pip install pymysql
有时使用 pip install xxx 命令安装时较慢,若要提升 pip 下载的速度,可采用命令:
pip install 模块名 [-i 镜像源地址]
比如,在国内的镜像源中,有很多可供使用的源地址:
当成功安装 pymysql 模块后,可直接导入使用:
# 导入模块
import pymysql
7.2 操作基本步骤
(1)在 Python 中,使用 pymysql 模块来操作 MySQL 数据的基本步骤:
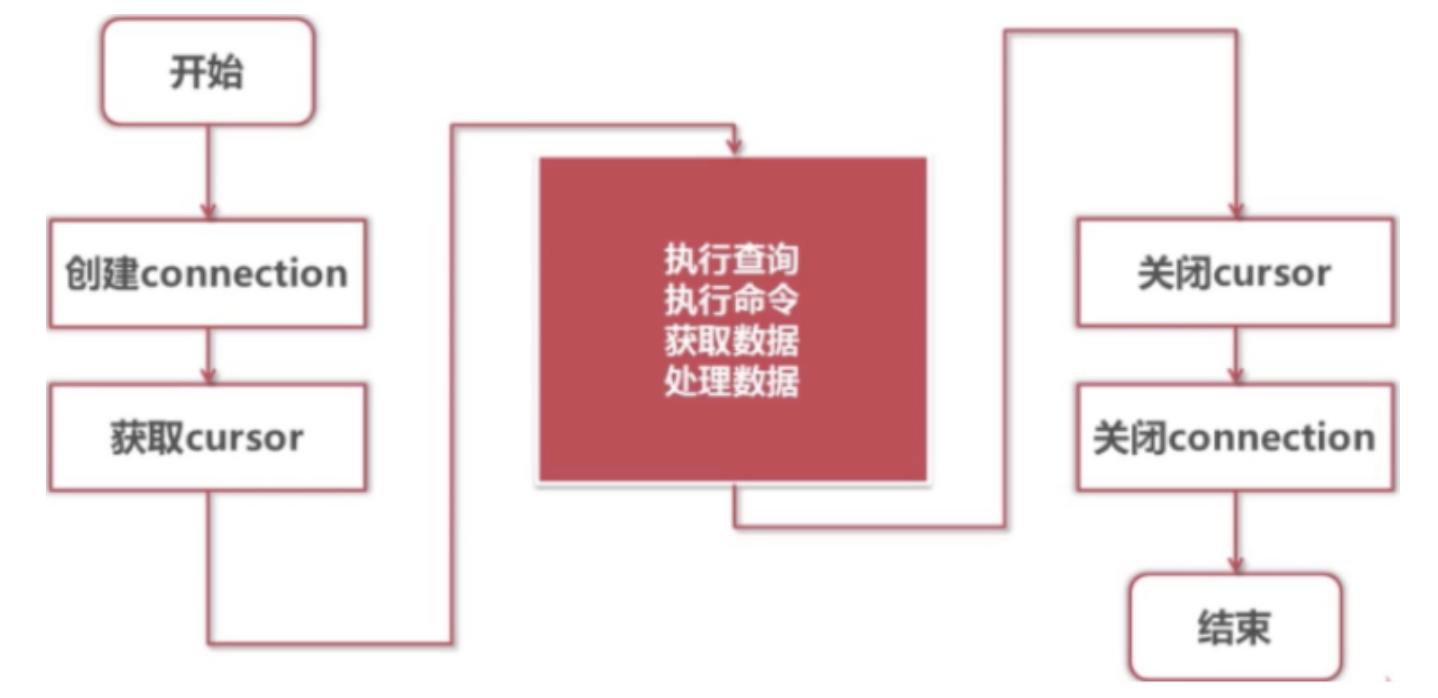
对于图解,操作步骤说明:
#1. 导入模块(导入模块前,必须安装pymysql模块:pip install pymysql)
import pymysql
# 2. 创建连接对象
db_conn = pymysql.connect()
# 用户名 root
# 密码 123456
# IP地址 192.168.88.80
# 端口号 3306
# 数据库名 test
# 编码格式 utf8
# 3. 创建游标对象
db_cursor = db_conn.cursor()
# 4. 使用游标对象执行SQL并进行增删改查
db_cursor.execute(sql)
# 增 insert into 表名[(字段1, 字段2.....)] values(值1, 值2.......)[(值1, 值2.......)(值1, 值2.......)]
# 删 delete from 表名 [where 条件]
# 改 update 表名 set 字段1=值1[,字段2=值2.......]
# 查 select * from 表名
# 5. 关闭游标对象
db_cursor.close()
# 6. 关闭连接对象
db_conn.close()
(2)我们都知道,在使用 MySQL 数据库前,首先需要登录并进行连接。
类似地,在使用 pymysql 模块时,也需要登录并进行连接,且此时需要使用 connection 对象。connection 是用于建立与数据库的连接,需要使用 pymysql 模块来调用:
| 函数 | 含义 |
|---|---|
| connect(host=None, port=0, user=None, password="", database=None, charset='',...) |
用于创建Connection连接对象。 ①host:表示连接MySQL的IP地址。若为本机,则可表示成'localhost'或'127.0.0.1';若为其他计算机,则表示为具体IP地址; ②port:表示连接的MySQL的端口号,默认是3306; ③user:表示连接的用户名,默认是root; ④password:表示连接的密码; ⑤database:表示数据库的名称; ⑥charset:表示采用的编码方式,设定为'utf8'即可。 |
当成功通过 connect() 获取并得到连接对象后,常用函数:
| 函数 | 含义 |
|---|---|
| commit() | 用于事务提交,在进行数据操作时需要进行事务提交后才会生效。 |
| close() | 用于关闭连接。 |
| cursor() | 用于返回 cursor 对象,可使用该对象来执行 SQL 语句并获取结果。 |
- 使用 pymysql 模块时,已默认开启了事务,因此要让数据操作生效,则必须要进行事务提交;
- 为了节约系统内存资源,通常在使用完 Connection 连接对象后,要进行 close() 关闭连接。
(3)若要执行 SQL 语句时,则需要使用 cursor 对象,可通过 connection 对象的 cursor() 方法进行创建。
| 函数 | 含义 |
|---|---|
| cursor() | 用于返回 cursor 对象,可使用该对象来执行 SQL 语句并获取结果。 |
当有了 cursor 对象后,常用函数:
| 函数 | 含义 |
|---|---|
| execute(operate [, param]) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operate 为字符串类型,表示SQL语句; 参数 parameters 为列表类型,表示 SQL 语句中的参数。 |
| fetchone() | 在执行查询语句时,获取查询结果集的第一行数据,返回一个元组,即 (v1, v2,...)。 |
| fetchall() | 在执行查询时,获取结果集的所有行,返回一个元组,即 ((v11, v12,...), (v21, v22,...),...)。 |
| close() | 关闭 cursor 对象。 |
- 使用 execute() 执行 SQL 语句时,SQL 语句应写成字符串型;
- 当关闭 connection 和 cursor 对象时,记得先关闭 cursor 游标,后关闭 connection 连接。
7.3 数据记录操作
通常情况下,在使用 pymysql 模块前,会先创建好数据库和数据表字段信息。
使用 MySQL 命令完成:
- 创建一个班级 db_students 数据库,并设定为 utf8 编码;
- 在库中新建一个数据表,包含编号 id、姓名 name、性别 gender、年龄 age 等字段;
- 其中,字段编号 id 为整型、主键且自动增长;
- 操作完成后,查看表结构,并查看表内是否有数据内容。
# 创建库
create database if not exists sz38db_students charset utf8;
# 使用库
use sz38db_students;
# 查看表信息
show tables;
# 创建表
create table if not exists student(
id int primary key auto_increment,
name varchar(20),
gender varchar(10),
age int
) engine = InnoDB default charset utf8;
# 查看表字段
desc student;
# 查看表数据
select * from student;
(1)插入数据
使用 pymysql 来给表内添加数据。使用函数:
| 函数 | 含义 |
|---|---|
| execute(operate [, param]) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operate 为字符串类型,表示 SQL 语句; 参数 parameters 为列表类型,表示 SQL 语句中的参数[可选项]。 |
# (1)使用execute()向学生表中插入1条学生数据;
# (2)使用DataGrip查看添加成功后的数据结果;
# (3)思考:如果要插入两条数据,该怎么做呢?
# 1-导入模块
import pymysql
# 2-创建连接
conn = pymysql.connect(
host='192.168.88.161',
port=3306,
user='root',
passwd='123456',
db='db_students',
charset='utf8'
)
# 3-创建游标
cur = conn.cursor()
# 4-执行SQL
sql = "insert into student(name, gender, age) values ('张三', '男', 28),('李四', '女', 38)"
cur.execute(sql)
# 5-提交事务
conn.commit()
# 6-关闭游标
cur.close()
# 7-关闭连接
conn.close()
(2)修改数据
当数据显示有误时,就需要来修改数据内容。使用函数:
| 函数 | 含义 |
|---|---|
| execute(operate [, param]) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operate 为字符串类型,表示 SQL 语句; 参数 param 为列表类型,表示 SQL 语句中的参数。 |
# 1-导入模块
import pymysql
# 2-创建连接
conn = pymysql.connect(
host='192.168.88.161',
port=3306,
user='root',
passwd='123456',
db='db_students',
charset='utf8'
)
# 3-创建游标
cur = conn.cursor()
# 4-执行SQL
# sql = "update student set age=19, name = '王军' where id=2"
sql = "update student set gender='Male' where gender='男';"
res = cur.execute(sql)
print(res)
# 5-提交事务
conn.commit()
# 6-关闭游标
cur.close()
# 7-关闭连接
conn.close()
(3)删除数据
当数据内容已失效时,就需要来删除数据内容。使用函数:
| 函数 | 含义 |
|---|---|
| execute(operate [, param]) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operate 为字符串类型,表示 SQL 语句; 参数 param 为列表类型,表示 SQL 语句中的参数。 |
# 1-导入模块
import pymysql
# 2-创建连接
conn = pymysql.connect(
host='192.168.88.161',
port=3306,
user='root',
passwd='123456',
db='db_students',
charset='utf8'
)
# 3-创建游标
cur = conn.cursor()
# 4-执行SQL
# 硬编码方式:1-不够灵活 2-SQL注入
sql = "delete from student where id=2"
res = cur.execute(sql)
print(res)
# 5-提交事务
conn.commit()
# 6-关闭游标
cur.close()
# 7-关闭连接
conn.close()
(4)查询数据
查询数据,要使用 cursor 对象的函数:
| 函数 | 含义 |
|---|---|
| execute(operate [, param]) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operation 为字符串类型,表示具体的 SQL 语句,注意,若在 SQL 语句中要向外传入参数值,则该参数均使用 %s 表示; 参数 param 为列表类型,表示 SQL 语句中的参数。 |
| fetchone() | 在执行查询语句时,获取查询结果集的第一行数据,返回一个元组,即 (v1, v2,...)。 |
| fetchall() | 在执行查询时,获取结果集的所有行,返回一个元组,即 ((v11, v12,...), (v21, v22,...),...)。 |
说明:查询的数据结果是元组类型。
# (1)使用fetchone来查询一条某xx姓名的数据信息;
# (2)使用fetchall()查询出所有数据信息,并遍历出详细信息。
# 1-导入模块
import pymysql
# 2-创建连接
conn = pymysql.connect(
host='192.168.88.161',
port=3306,
user='root',
passwd='123456',
db='db_students',
charset='utf8'
)
# 3-创建游标
cur = conn.cursor()
# 4-执行SQL
# 硬编码方式:1-不够灵活 2-SQL注入
name = input("请输入您要查询的姓名:")
params = [name]
sql = "select * from student where name = %s"
cur.execute(sql, params)
# result = cur.fetchone()
# print(result)
result_all = cur.fetchall()
# print(result_all)
for row in result_all:
print(row)
for id, name, gender, age in result_all:
print(id, name, gender, age)
# 5-提交事务
conn.commit()
# 6-关闭游标
cur.close()
# 7-关闭连接
conn.close()
(5)SQL 注入问题
SQL 注入指的是:恶意篡改或注入 SQL 条件。当开发者的数据条件若被恶意篡改,那就达不到预期的查询效果。
比如在条件结尾处,添加 or 1=1,并查询结果。
如果要解决 SQL 注入的问题,在 pymysql 模块中,可采用语句参数化来解决。
语句参数化是指以 %s 表示值,然后再传入具体的参数值进行替换。
为了更好理解语句参数化,可以把 SQL 语句的参数化、值,简要地理解为 print() 函数中的格式化符号输出:
print("xxx%s, xxx%d"%(name, age))
要使用 cursor 对象的函数:
| 函数 | 含义 |
|---|---|
| execute(operate, param) | 用于执行 SQL 语句,返回受影响的行数。 其中,参数 operation 为字符串类型,表示具体的 SQL 语句,注意,若在 SQL 语句中要向外传入参数值,则该参数均使用 %s 表示; 参数 param 为列表类型,表示 SQL 语句中的参数。 |
# 1-导入模块
import pymysql
# 2-创建连接
conn = pymysql.connect(
host='192.168.88.161',
port=3306,
user='root',
passwd='123456',
db='db_students',
charset='utf8'
)
# 3-创建游标
cur = conn.cursor()
# 4-执行SQL
# 硬编码方式:1-不够灵活 2-SQL注入
name = input("请输入姓名:")
gender = input("请输入性别:")
age = int(input("请输入年龄:"))
params = [name, gender, age]
sql = "insert into student(name,gender,age) values(%s,%s,%s)"
res = cur.execute(sql, params)
print(res)
# 5-提交事务
conn.commit()
# 6-关闭游标
cur.close()
# 7-关闭连接
conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号