

【MySQL学习笔记】InnoDB引擎-数据存储结构
1. InnoDB 存储引擎
InnoDB 存储引擎是MySQL的默认存储引擎,是事务安全的MySQL存储引擎。该存储引擎是第一个完整ACID事务的MySQL存储引擎,其特点是行锁设计、支持MVCC、支持外键、提供一致性非锁定读,同时被设计用来最有效地利用以及使用内存和 CPU
2. InnoDB体系架构
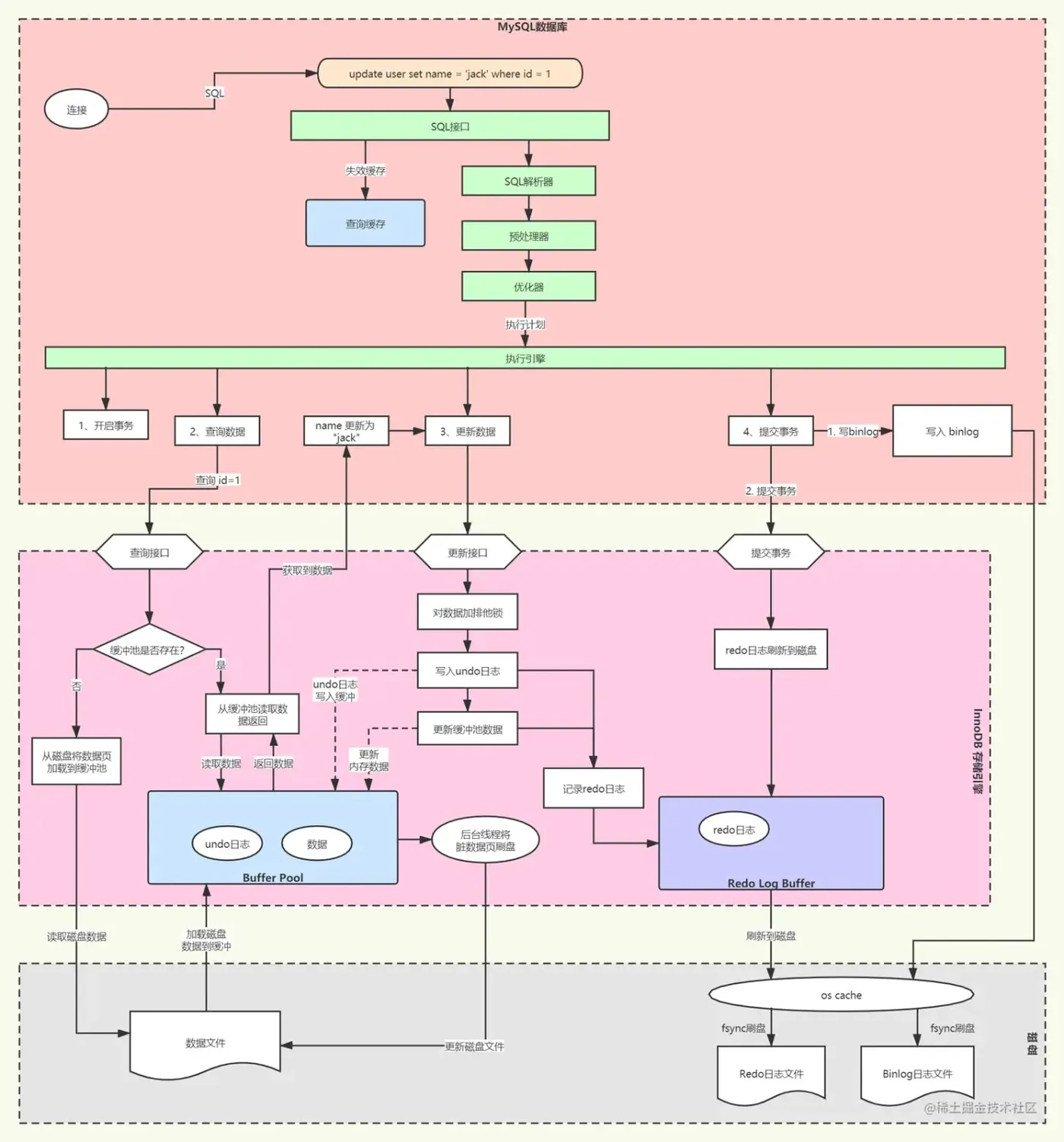
- 客户端连接到MySQL服务器,将SQL更新语句发送到服务器;MySQL服务器连接池中会有一个连接和客户端建立连接,然后后台线程会从连接中获取到要执行的SQL语句,并发送给SQL接口去调度执行。
- 增、删、改 时,会将查询缓存中 user 表相关的缓存都清空。
- SQL语句经过SQL解析器解析、优化器优化,得到一个执行路径,前面这些和执行查询其实都是类似的。
- 接着由执行引擎去调用底层的存储引擎接口,根据执行计划完成SQL语句的执行。
- 首先查询出要更新的数据,这一步会先判断缓冲池(Buffer Pool)中是否已经存在这条数据,如果已经存在了,则直接从缓存池获取数据返回。否则从磁盘数据文件中加载这条数据到缓冲池中,再返回数据。
- 获取到数据后,执行引擎会根据SQL更新数据,然后调用存储引擎更新数据。这一步会对数据加排它锁,避免并发更新问题。之后先写 undolog 到缓冲池,undolog 主要用于事务回滚、MVCC等;同时,undolog 也会产生 redolog 日志。
- 之后更新缓冲池中的数据,同时记录 redolog 到 RedoLog缓冲池,redolog 主要用于保证数据的持久性,宕机恢复数据等。
- 最后提交事务,虽然没有手动 commit 提交事务,update 语句执行完成后也会有隐式的事务提交的。事务提交时,会先在MySQL服务器层面会写入 binlog,binlog是数据持久性的保证。最后将redolog刷入磁盘,完成事务提交。
- 最底层的一部分就是磁盘上的数据文件、日志文件等,可以看到,InnoDB 设计了缓冲池来缓冲数据、undolog、redolog 等,这些内存中的数据最终都是要刷新到磁盘中才能保证数据不丢失的。
![]()
3.系统数据库
- mysql
这个数据库的核心,它存储了MySQL的用户账户和权限信息,一些存储过程、事件的定义信息,一些运行过程中产生的日志信息,一些帮助信息以及时区信息等。
- information_schema
这个数据库保存着MySQL服务器所有其他数据库的信息,比如表、视图、触发器、列、索引、锁、事务等等。这些信息并不是真实的用户数据,而是一些描述性信息,也称之为元数据。
- performance_schema
这个数据库主要保存MySQL服务器运行过程中的一些状态信息,包括统计最近执行了哪些语句,在执行过程的每个阶段都花费了多长时间,内存的使用情况等等信息。
- sys
这个数据库主要是通过视图的形式把 information_schema 和 performance_schema 结合起来,让程序员可以更方便的了解MySQL服务器的一些性能信息。
4.InnoDB逻辑存储结构
InnoDB将所有数据都存放在表空间中,表空间又由段(segment)、区(extent)、页(page)组成。InnoDB存储引擎的逻辑存储结构大致如下图。
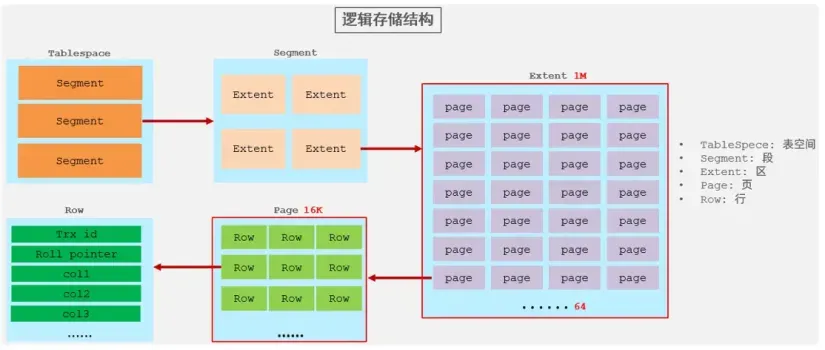
4.1. 表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。在默认情况下InnoDB存储引擎有一个共享表空间ibdata1,所有数据都存放在这个表空间内。
如果启用了参数innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。需要注意的是,这些单独的表空间文件仅存储该表的数据、索引和插入缓冲Bitmap等信息,其余信息还是存放在共享表空间中,例如 undo日志、插入缓冲索引页、系统事务信息、二次写缓冲等。
因此即使在启用了参数innodb_file_per_table之后,共享表空间的大小还是会不断地增加,例如事务中写入了undo日志,就算回滚了,共享表空间的大小也不会缩小。但是会判断这些undo信息是否还需要,不需要的话,就会将这些空间标记为可用空间,供下次重复使用。
4.2. 段
从前面B+树的结构知道,B+树分为叶子节点和非叶子节点,最底层的叶子节点才存储了数据,非叶子节点是索引目录。如果将叶子节点页和非叶子节点页混合在一起存储,那在检索数据的时候同样也会有大量的随机I/O。
所以 InnoDB 又提出了段的概念,常见的段有数据段、索引段、回滚段等。段是一个逻辑上的概念,并不对应表空间中某一个连续的物理区域,它由若干个完整的区组成(还会包含一些碎片页),不同的段不能使用同一个区。
存放叶子节点的区的集合就是数据段,存放非叶子节点的区的集合就是索引段。也就是说一个索引会生成2个段,一个叶子节点段(数据段),一个非叶子节点段(索引段)。
4.3. 区
在默认情况下,InnoDB存储引擎页的大小为16KB,表空间中的页就太多了。为了更好的管理这些页,InnoDB 将物理位置上连续的64个页划为一个区,任何情况下,每个区的大小都为1MB。
B+树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,本来链表中相邻的两个页之间的物理位置就可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机I/O是非常慢的。所以应该尽量让链表中相邻的页的物理位置也相邻,这样可以消除很多的随机I/O,使用顺序I/O,尤其是在进行范围查询的时候。
所以在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区为单位分配,甚至在表中的数据非常多的时候,可以一次性分配多个连续的区。
不论是系统表空间还是独立表空间,都可以看成是由若干个区组成的,每个区64个页,然后每256个区又被划分成一组。
第一个组最开始的3个页面的类型是固定的,也就是第一个区(extent0)最开始的三个页。分别是:
-
- FSP_HDR:用来登记整个表空间的一些整体属性以及本组所有区的属性,整个表空间只有一个 FSP_HDR 类型的页面。
- IBUF_BITMAP:存储本组所有区的所有页面关于 INSERT BUFFER 的信息。
- INODE:索引节点信息。
其余各组则是最开始的2个页面的类型是固定的,分别是:
-
- XDES:用来登记本组256个区的属性。
- IBUF_BITMAP:存储本组所有的区的所有页面关于 INSERT BUFFER 的信息。
从这里也可以看出,索引数据并不时连续存储在区中,因为其中有些页面被用来存储额外的一些管理信息了。
4.4. 页
页(Page)是 InnoDB 磁盘管理的最小单位,默认每个页的大小为16KB,也就是最多能保证16KB的连续存储空间。
InnoDB 将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,也就是一次最少从磁盘中读取一页16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
4.5. 行
InnoDB的数据是按行进行存放的,每个页存放的行记录最多允许存放16KB / 2 -200行的记录,即7992行记录。
每行记录根据不同的行格式、不同的数据类型,会有不同的存储方式。每行除了记录我们保存的数据之外,还可能会记录事务ID(DB_TRX_ID),回滚指针(DB_ROLL_PTR)等。
4.6. 索引组织表
在InnoDB中,行数据都是根据主键顺序存放的,这种存储方式的表称为索引组织表。在InnoDB表中,每张表都有个主键,如果在创建表时没有显式地定义主键,则InnoDB会按如下方式选择或创建主键:
-
- 首先判断表中是否有非空的唯一索引,如果有,则该列即为主键。
- 当表中有多个非空唯一索引时,将选择建表时第一个定义的非空唯一索引为主键。
- 如果不符合上述条件,InnoDB会自动创建一个名为row_id的6字节的隐藏列作为主键。
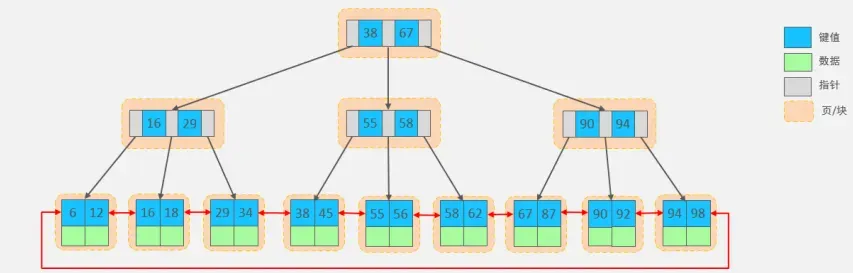
为了能快速的从磁盘中检索出数据,InnoDB采用 B+树 结构来组织数据,通过 B+树 组织起来的结构大概就像下图这个样子。InnoDB存储引擎表是索引组织的,数据即索引,索引即数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号