
HashMap源码分析
一 HashMap使用的数据结构
HashMap时基于map接口的key,value实现的。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。HashMap继承了AbstractMap(提供Map),Cloneable接口、Serializable。
数据结构:HashMap的数据结构为数组+链表/红黑树
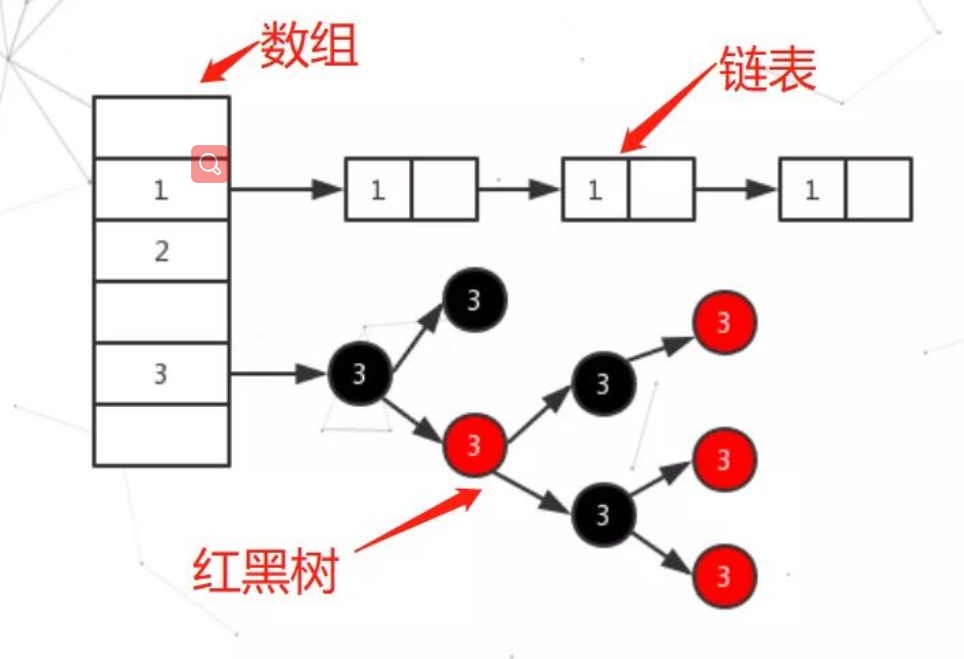
图片来源:https://www.sohu.com/a/327165642_753508
hashmap中存储的是Entry对象。源码如下:当获取key:value时,根据hashcode得到存储位置,然后比较key是否相等,如果相等,则返回对象。这里重点是数据结构中存储的是Entry,不单单是key,或者value。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }
二 为什么JDK1.8之后要将存储链表转换为红黑树结构,为什么值大于等于8之后变换?
使用红黑树查找时间复杂度为logn,在线性表链表中查找时间复杂度为n。为什么一开始不用红黑树呢?因为树型节点需要占用更多的存储空间,所以在节点较少时,使用链表存储,可以较好的节省存储空间。
把值设为8的原因是,源码上说,为了配合使用分布良好的hashCode,树节点很少使用。并且在理想状态下,链表中节点数是8的概率已经非常小,而且此时链表的性能已经很差了。所以在这种比较罕见和极端的情况下,才会把链表转变为红黑树。因为链表转换为红黑树也是需要消耗性能的,特殊情况特殊处理,为了挽回性能,权衡之下,才使用红黑树,提高性能。也就是大部分情况下,hashmap还是使用的链表,如果是理想的均匀分布,节点数不到8,hashmap就自动扩容了。

但是也不是直接扩容,而是数组容量大于当前 最小树形化容量阈值>=MIN_TREEIFY_CAPACITY 时,树化阈值>=TREEIFY_THRESHOLD时,再进行树形化。
参考文章:https://blog.csdn.net/baidu_37147070/article/details/98785367
三 重要属性
初始化容量:必须是2的次幂

集合容量必须是2的次幂。负载因子为0.75,当超过负载因子*容量时,数组会发生扩容,扩容之后容量为之前的两倍。当树型结构节点数小于6时,会转变为链表结构。默认初始容量为16。
四 重要方法
构造方法:HashMap
空的构造方法,使用默认的负载因子

构造一个带有初始容量的HashMap

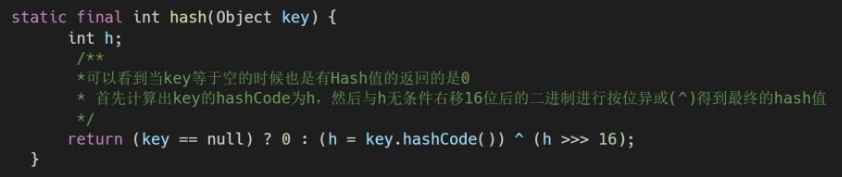
hash计算方法(数组长度为2的幂次方,主要是为了保证计算hash的速率)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号