【大数据】通过 docker-compose 快速部署 Presto(Trino)保姆级教程

一、概述
Presto是一个快速的分布式查询引擎,最初由Facebook开发,目前归属于 Presto Software Foundation(由 Facebook、Teradata 和其他公司共同支持)。Presto的核心特点是支持远程数据访问,可以查询包括Hadoop、Cassandra、Relational databases、NoSQL databases在内的多个数据源。Presto支持标准的SQL语法,同时提供了一些扩展功能,如分布式查询、动态分区、自定义聚合和分析函数等。
但是Presto目前有两大分支:
PrestoDB(背靠Facebook)和PrestoSQL现在改名为Trino(Presto的创始团队),虽然PrestoDB背靠Facebook,但是社区活跃度和使用群体还是远不如Trino。所以这里以Trino为主展开讲解。
关于更多的Presto介绍可以参考我这篇文章:大数据Hadoop之——基于内存型SQL查询引擎Presto(Presto-Trino环境部署)
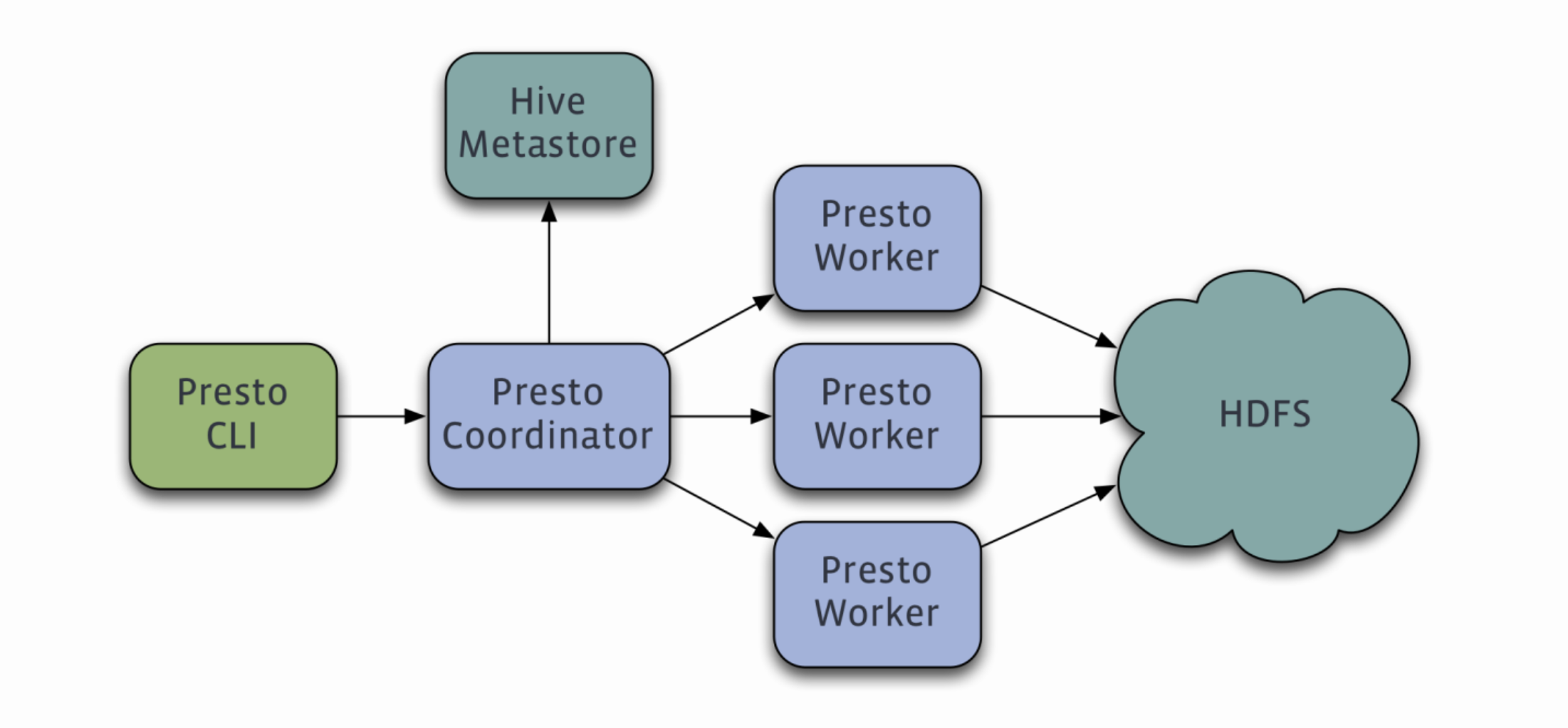
二、前期准备
1)部署 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
2)部署 docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
三、创建网络
# 创建,注意不能使用hadoop_network,要不然启动hs2服务的时候会有问题!!!
docker network create hadoop-network
# 查看
docker network ls
四、Trino 编排部署
1)下载 trino
官方下载地址:https://trino.io/download.html
# trino server
wget https://repo1.maven.org/maven2/io/trino/trino-server/416/trino-server-416.tar.gz
# trino Command line client
wget https://repo1.maven.org/maven2/io/trino/trino-cli/416/trino-cli-416-executable.jar
# jdk
wget https://cdn.azul.com/zulu/bin/zulu20.30.11-ca-jdk20.0.1-linux_x64.tar.gz
2)配置
首先创建etc和data目录,后面配置文件需要用到
mkdir -p etc/{coordinator,worker} etc/catalog/ images
1、coordinator 配置
node.properties
cat << EOF > etc/coordinator/node.properties
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=test
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的。
node.id=trino-coordinator
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/apache/trino/data
EOF
jvm.config
cat << EOF > etc/coordinator/jvm.config
-server
-Xmx2G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
# Disable Preventive GC for performance reasons (JDK-8293861)
-XX:-G1UsePreventiveGC
EOF
config.properties
cat << EOF > etc/coordinator/config.properties
# 设置该节点为coordinator节点
coordinator=true
# 允许在协调器上调度工作,也就是coordinator节点又充当worker节点用
node-scheduler.include-coordinator=false
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8080
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=1GB
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=1GB
# hadoop-node1也可以是IP
discovery.uri=http://localhost:8080
EOF
log.properties
cat << EOF > etc/coordinator/log.properties
# 设置日志级别,有四个级别:DEBUG, INFO, WARN and ERROR
io.trino=INFO
EOF
2、worker 配置
node.properties
cat << EOF > etc/worker/node.properties
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=test
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的。
# node.id=trino-worker
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/apache/trino/data
EOF
jvm.config
cat << EOF > etc/worker/jvm.config
-server
-Xmx2G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
# Disable Preventive GC for performance reasons (JDK-8293861)
-XX:-G1UsePreventiveGC
EOF
config.properties
cat << EOF > etc/worker/config.properties
# 设置该节点为worker节点
coordinator=false
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8080
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=1GB
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=1GB
# hadoop-node1也可以是IP
discovery.uri=http://trino-coordinator:8080
EOF
log.properties
cat << EOF > etc/worker/log.properties
# 设置日志级别,有四个级别:DEBUG, INFO, WARN and ERROR
io.trino=INFO
EOF
3)启动脚本 bootstrap.sh
#!/usr/bin/env sh
wait_for() {
echo Waiting for $1 to listen on $2...
while ! nc -z $1 $2; do echo waiting...; sleep 1s; done
}
start_trino() {
node_type=$1
if [ "$node_type" = "worker" ];then
wait_for trino-coordinator 8080
fi
${TRINO_HOME}/bin/launcher run --verbose
}
case $1 in
trino-coordinator)
start_trino coordinator
;;
trino-worker)
start_trino worker
;;
*)
echo "请输入正确的服务启动命令~"
;;
esac
4)构建镜像 Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
RUN export LANG=zh_CN.UTF-8
# 创建用户和用户组,跟yaml编排里的user: 10000:10000
RUN groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop -m
# 安装sudo
RUN yum -y install sudo ; chmod 640 /etc/sudoers
# 给hadoop添加sudo权限
RUN echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
RUN yum -y install install net-tools telnet wget nc
RUN mkdir /opt/apache/
# 添加配置 JDK
ADD zulu20.30.11-ca-jdk20.0.1-linux_x64.tar.gz /opt/apache/
ENV JAVA_HOME /opt/apache/zulu20.30.11-ca-jdk20.0.1-linux_x64
ENV PATH $JAVA_HOME/bin:$PATH
# 添加配置 trino server
ENV TRINO_VERSION 416
ADD trino-server-${TRINO_VERSION}.tar.gz /opt/apache/
ENV TRINO_HOME /opt/apache/trino
RUN ln -s /opt/apache/trino-server-${TRINO_VERSION} $TRINO_HOME
# 创建配置目录和数据源catalog目录
RUN mkdir -p ${TRINO_HOME}/etc/catalog
# 添加配置 trino cli
COPY trino-cli-416-executable.jar $TRINO_HOME/bin/trino-cli
# copy bootstrap.sh
COPY bootstrap.sh /opt/apache/
RUN chmod +x /opt/apache/bootstrap.sh ${TRINO_HOME}/bin/trino-cli
RUN chown -R hadoop:hadoop /opt/apache
WORKDIR $TRINO_HOME
开始构建镜像
docker build -t registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/trino:416 . --no-cache
# 为了方便小伙伴下载即可使用,我这里将镜像文件推送到阿里云的镜像仓库
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/trino:416
### 参数解释
# -t:指定镜像名称
# . :当前目录Dockerfile
# -f:指定Dockerfile路径
# --no-cache:不缓存
5)编排 docker-compose.yaml
version: '3'
services:
trino-coordinator:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/trino:416
user: "hadoop:hadoop"
container_name: trino-coordinator
hostname: trino-coordinator
restart: always
privileged: true
env_file:
- .env
volumes:
- ./etc/coordinator/config.properties:${TRINO_HOME}/etc/config.properties
- ./etc/coordinator/jvm.config:${TRINO_HOME}/etc/jvm.config
- ./etc/coordinator/log.properties:${TRINO_HOME}/etc/log.properties
- ./etc/coordinator/node.properties:${TRINO_HOME}/etc/node.properties
- ./etc/catalog/:${TRINO_HOME}/etc/catalog/
ports:
- "30080:${TRINO_SERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh trino-coordinator"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${TRINO_SERVER_PORT}/v1/info || exit 1"]
interval: 10s
timeout: 20s
retries: 3
trino-worker:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/trino:416
user: "hadoop:hadoop"
restart: always
privileged: true
deploy:
replicas: 3
env_file:
- .env
volumes:
- ./etc/worker/config.properties:${TRINO_HOME}/etc/config.properties
- ./etc/worker/jvm.config:${TRINO_HOME}/etc/jvm.config
- ./etc/worker/log.properties:${TRINO_HOME}/etc/log.properties
- ./etc/worker/node.properties:${TRINO_HOME}/etc/node.properties
- ./etc/catalog/:${TRINO_HOME}/etc/catalog/
expose:
- "${TRINO_SERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh trino-worker"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${TRINO_SERVER_PORT}/v1/info || exit 1"]
interval: 10s
timeout: 10s
retries: 3
# 连接外部网络
networks:
hadoop-network:
external: true
.env 文件内容如下:
cat << EOF > .env
TRINO_SERVER_PORT=8080
HADOOP_HDFS_DN_PORT=/opt/apache/trino
EOF
6)开始部署
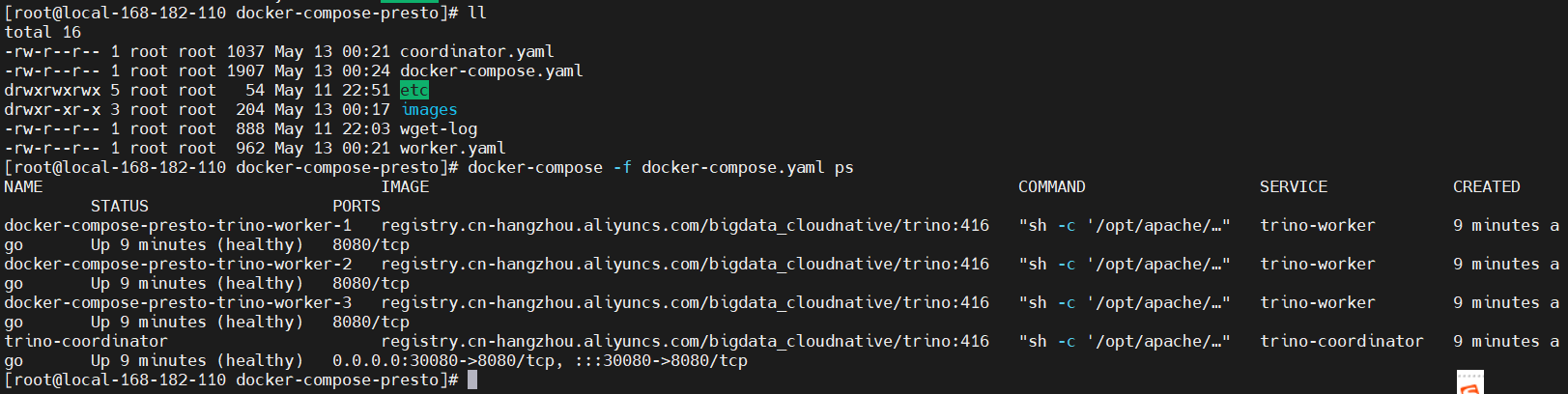
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
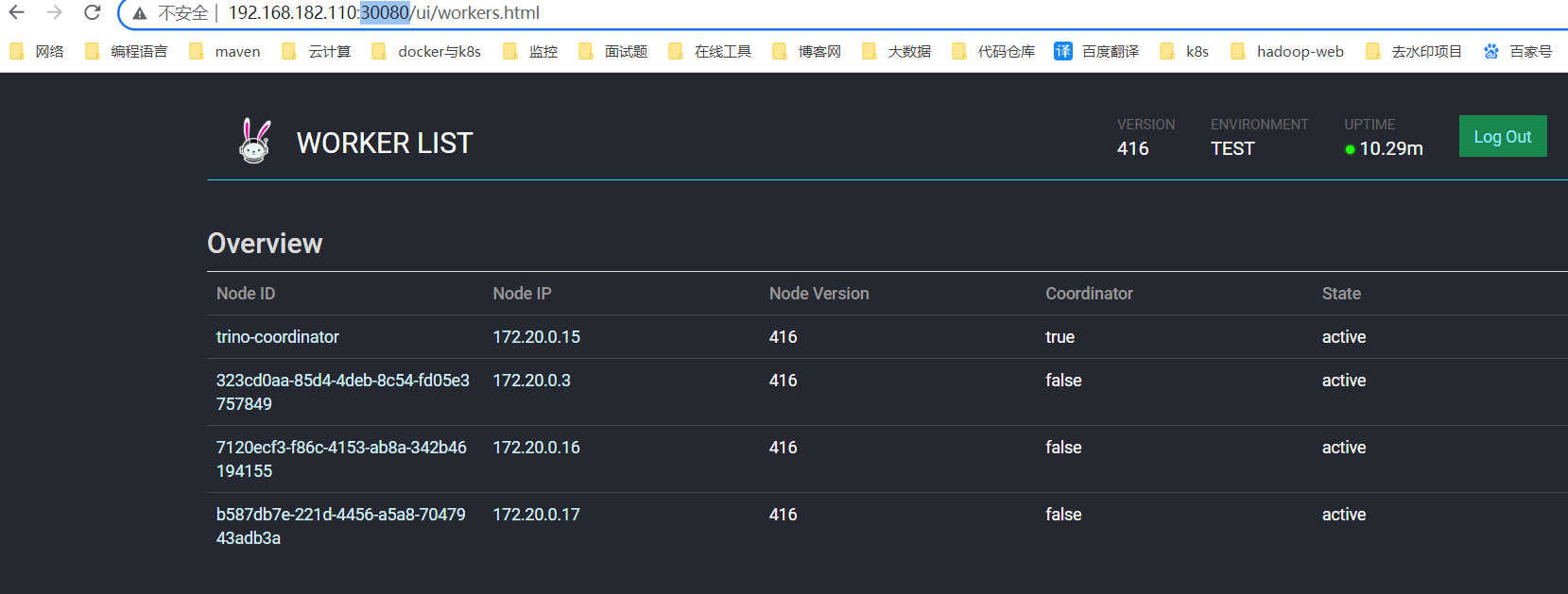
web 地址:http://ip:30080
五、简单测试验证
hive和mysql快熟部署文档可参考我这篇文章:通过 docker-compose 快速部署 Hive 详细教程
1)mysql 数据源
添加 mysql 数据源,在宿主机上配置即可,因已经挂载了
cat << EOF > ./etc/catalog/mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://mysql:3306
connection-user=root
connection-password=123456
EOF
重启 trino
docker-compose -f docker-compose.yaml restart
测试验证
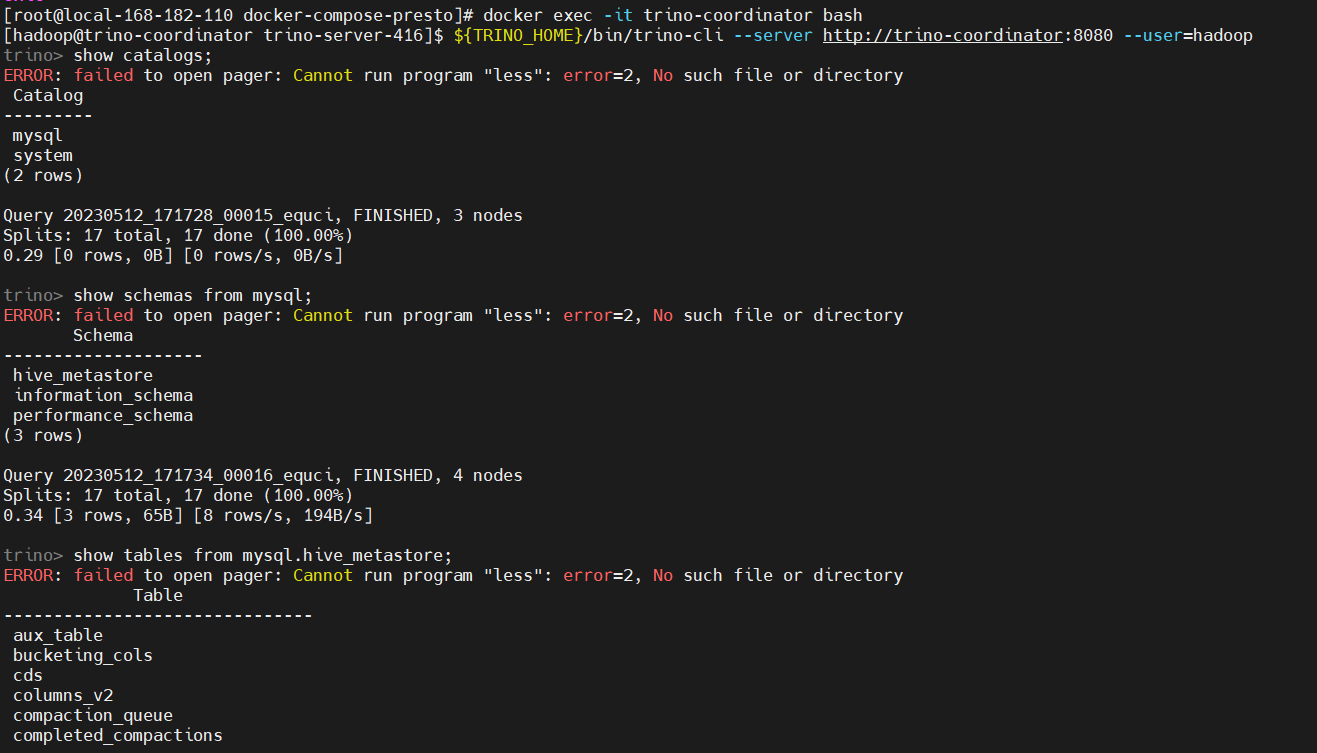
# 登录容器
docker exec -it trino-coordinator bash
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
# 查看数据源
show catalogs;
# 查看mysql库
show schemas from mysql;
# 查看表
show tables from mysql.hive_metastore;
# 查看表数据
select * from mysql.hive_metastore.version;
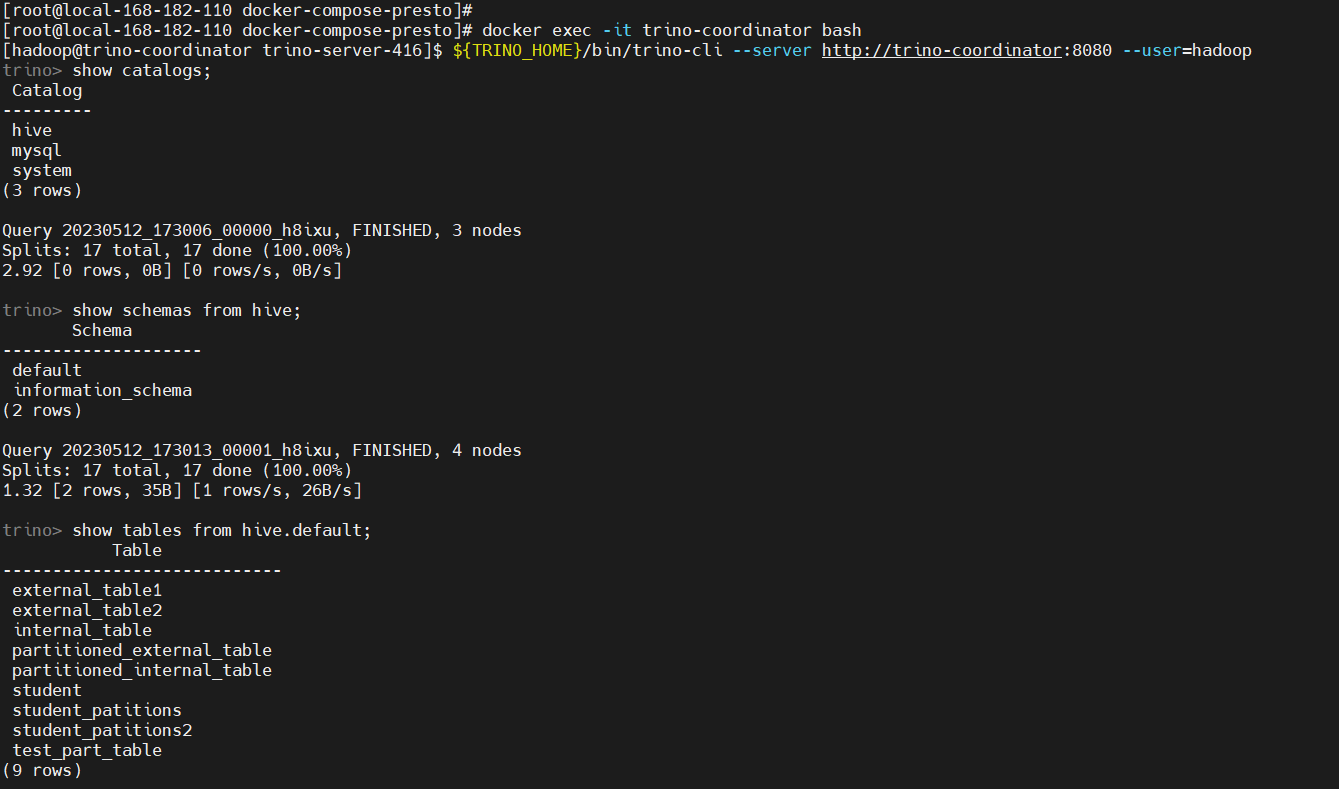
2)hive 数据源
添加 hive 数据源,在宿主机上配置即可,因已经挂载了
cat << EOF > etc/catalog/hive.properties
connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
EOF
重启 trino
docker-compose -f docker-compose.yaml restart
测试验证
# 登录容器
docker exec -it trino-coordinator bash
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
# 查看数据源
show catalogs;
# 查看mysql库
show schemas from hive;
# 查看表
show tables from hive.default;
# 查看表数据
select * from hive.default.student;
docker-compose 快速部署 Presto(Trino)保姆级教程就先到这里了,有任何疑问可关注我的公众号【大数据与云原生技术分享】加群交流或私信咨询问题,如这篇文章对你有所帮助,麻烦帮忙一键三连(点赞、转发、加关注)哦~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号