c语言部分笔记(笔记为简记)
第一天、计算机基础知识
1、计算机五部分组成:运算器、控制器、存储器(内存、外存)、输入设备、输出设备
CPU只和内存打交道 外存的数据掉电不丢失
内存的数据掉电会丢失
(1)、提出计算机由五部分组成
2、计算机之父:冯诺依曼——> (2)、计算机的数据采用二进制存储
(3)、计算机中程序按照顺序执行
3、第一台电子计算机:1946年 艾伦图灵
4、C语言的标准由美国ANSI组织(美国国家标准协会)发布,所以最初也被成为ANSI C,
后面由ISO组织(国际标准化组织)制定和发布,目前一共有5套标准(C89,C99,C11,C17,C23)
5、美国标准国家协会ASCI设计出来一套编码规则 ASCII码,收录了128个字符,为了兼容其他国家,扩展到了256个字符
6、中国国家标准总局设计了中文简体字符集:GB2312字符集,后面推出了GBK编码,UTF-8收录了各个国家的字符.
7、常用的字符ASCII码:换行符 10, 回车符 13,字符0 48, 大写字母A 65,小写字母a 96
8、为了能存储ASCII码表中的任意字符,所以需要存储器中的8个电容。 电容:电子元件,具有充电放电的特性,容纳电荷
9、动态随机存储器(DRAM):常见设备 内存条
9、计算机处理数据的最小单位:bit 计算机处理数据的基本单位byte(字节)
10、存储器一般以一组电容(8bit)作为存储单元
第二天、程序框架分析
1、函数:可以重复使用的代码段
2、main函数需要有返回值必须是int整型,可以没有参数,返回值会最为exit函数的参数,程序总是从main函数开始运行
int main(viod){}
int main(int argc,char *argv[]){}
argc->的值是非负整数
*argv[]-> (1)、数组中的每一个元素都是一个指向字符串的指针
(2)、字符串应该由主机环境递给main函数,主机环境指的是Linux命令行终端
(3)、数组中第一个元素的字符串指的是程序的名字
(4)、数组中第二个元素到最后一个元素是传递给程序的参数
3、exit函数可以导致程序终止,只能调用一次。参数是0表示程序正常终止,如果是非0表示程序异常终止,exit的参数会提供给当前 程序的父进程
4、头文件的两种包含形式: < > " "
< >:直接从系统路径下进行查找,如果未找到,则编辑器提示错误
" ":先从当前路径下查找,如果没有则在系统路径下进行查找,如果未找到,则编辑器提示错误
第三天、C语言基本元素
1、C语言标准中常用关键字32个,并且全都是小写
2、计算机的存储器分为两种:RAM(随机存储器) ROM(只读存储器)
掉电数据丢失 掉电数据不丢失
3、32位系统/64位系统 指的是计算机的地址总线的位数,指的是计算机的寻址范围是32位,也就是4GB
4、常量:在程序循行期间值不会发生改变的量 ->一般情况下用宏定义的方式来实现常量的设计 #define
变量:在程序运行期间值可能发生变化的量 ->用户可以根据实际情况向kernel(内核)申请一块存储单元0
5、C语言不支持二进制输入,但是支持八进制、十进制、十六进制
6、在二进制数前面增加一个符号位 0:表示正数 1:表示负数
7、用二进制表示负数:原码->反码->补码 注:负数原码求反的过程中符号位是不变的
8、设计程序时,定义的变量如果是由符号的,则尽量避免写入超过变量范围的数值
9、浮点数的两种形式 十进制形式(3.14)和指数形式(3.14E2) 注:C语言标准中规定字符e/E的后面必须是整数,另外字符e/E的前面必 须有数字
第四天、输入,输出
1、'#'可以把对应进制的前导符进行输出 #o可以把八进制的前导符输出 #x可以把十六进制的前导符输出->0x
2、'-'可以用于数据对齐 '-'表示左对齐 (默认是右对齐),一般结合字段宽度使用
3、字段宽度:采用十进制,指的是待输出的字符串需要占用多少列
4、'.'表示精度,后面跟着一个可选的十进制数
5、hh指的是把整形转为字符型,h指的是把整形转为短整型,只针对输出而言,数据本身没有收到影响
6、大端存储:低地址存储高字节(ARM架构) 小端存储:低地址存储低字节(x86架构)
5、函数的四个步骤:头文件、函数原型、函数参数以及返回值
7、stdout 指的是标准输出 显示器
stdin 指的是标准输入 键盘
8、printf 把格式化字符串输出到显示器 返回值是传输的字符数量 如果失败发送,返回值是负整数
9、'%P'可以把存储单元的编号以十六进制的形式输出
10、fflush刷新缓冲区 fflush(stdout)刷新输出缓冲区
11、刷新缓冲区的情况:(1)、缓冲区满了 (2)、遇到'\n'时 (3)、手动释放 调用fflush
12、匹配字符 [] 例:scanf("%d",&buf); //用户通过键盘把字符输入到对应的数组中,如果程序只打算接收0-9,如果用户输入其他字符 则结束
13、C语言的单目运算符和三目运算符都是遵循右结合,还有双目运算符中的赋值运算符‘=’,其他的运算符都是左结合性
14、sizeof运算符的操作对象如果是一个表达式,则表达式不会参与运算
15、类型转换 :强制类型转换和自动类型转换 注:两个都是为了本次运算而进行的临时性转换,转换的结果也会保存到临时的内存 空间(栈空间),不会改变数据本来的类型或者值
第五天、操作符
1、位操作运算符:~ & ^ | << >> ~属于单目运算符 其他的是双目运算符
~:按位取反 对于二进制而言 0变1 1变0 例:~1101_1110 = 0010_0001
&:按位与 对于二进制而言 当两个bit同时为1,结果为1 当bit存在0,结果为0
|:按位或 对于二进制而言 当两个bit同时为0,结果为0 当bit存在1,结果为1
^:按位异或 对于二进制而言 当两个bit相同,则结果为0 两个bit不同,结果为1
<<:左移运算符,对于二进制而言 原则:高位舍弃,低位补零 0111_1010 << 3 -->1101_0000
>>:右移运算符,对于二进制而言 原则:底位舍弃,高位补零 0111_1010 >> 3 -->0000_0111
2、给定一个整形变量a,第一个设置a的bit 3,第二个清除a的bit 3。在以上两个操作中,要其他位不变
置位 bit=1 复位bit=0
a = (1 << 3) | 1; ---> a |=(1<<?);
a = (~(1<<3))& a; ---> a &=~(1<<?);
3、逗号运算符 运算规则:逗号运算符中的最后一个表达式的结果最为最终结果
第六天、语句
1、语句:是为了指定动作,如果没有特殊说明,语句是顺序执行。 块是语句和声明的集合,每个代码块都是独立的语法单元
语句的种类: 标签语句 case default
复合语句 {}
表达式语句 ;
选择语句 if() if()else() switch()
迭代语句 while() do while() for( ; ; )
跳转语句 goto语句 countinue语句 break语句 return语句
第七天、数组
1、Array 数组 :用户向内核申请一块地址连续的内存空间 空间大小:数据类型的大小数据数量(数组长度)
2、数组名称就是指向数组对象的指针,数组名表示数组第一个存储单元的地址
3、(E1 + E2)== E1[E2] 如果E1是数组名 E2是整形常量 则:E1[E2]等价于 E2[E1]
4、int buf[5]; (buf+1)指的是数组地址向后偏移一个元素对应的单元大小,也就是偏移了4字节 (&buf+1)偏移了(5*sizeof(int))个 字节
5、清空数组操作:bzero(数组名,数组长度) memset(数组名,填充数,数组长度)-->更灵活
6、数组初始化只能在数组定义的时候进行
第八天、字符数组和多维数组
1、如果数组的容量刚好和字符串中的有效字符的数量一致时,就会数组越界,因为字符串末尾有一个转义字符‘\0’,也需要占用一个 字节的存储单元
2、不管是几维数组,数组的定义规则:数组名 [元素数量] + 元素类型
3、buf[1][1] --> *( ( *(buf+1) ) +1)
第九天、指针
1、int *P=NULL; //对指针变量进行初始化,目的是防止野指针出现,为了避免段错误的
2、从下到上 : 保留区->代码段->数据段->堆空间->栈空间->内核空间(1G)
3、对指针变量的偏移,地址加一不表示存储单元向后偏移一个字节,而是向后偏移一个数据类型的字节长度
4、指针数组:数据类型 *数组名[元素个数];
5、二级指针:一个指针变量中存储的地址是另一个变量变量的地址 例:int data; int *P1 = &data; int **P2 = &P1;
第十天、函数
1、函数的返回类型可以是void挥着是一个对象类型,而不是数组类型
2、注意:如果函数有返回值类型,则函数内部的需要返回的数据的类型必须要和 函数的返回值类型一致,则需要在函数内部调用return语句实现。
3、C语言中函数都是独立的个体,不允许在一个函数内部定义新的函数,但是允许 在一个函数内部调用其他的函数!设计函数应该做到*低耦合,高内聚*!
4、函数遵循一个“先定义,后使用”原则,由于C语言中程序都是以函数为单位,并 且程序的入口是主函数main(),所以应该把用户自定义的函数定义在main()函 数之前,然后在main()函数中进行调用。
5、单向传递:只是把实参的值传递给函数作为参数,在函数内部对数值进行修改 是不会影响外部实参的!
6、双向传递:如果不打算调用return语句,则可以选择把实参的地址作为参数传递 给函数内部,这样函数内部对地址中的数据进行修改,则函数外部的实参地址 下的值也会变化,只不过此时函数参数类型应该是指针才可以。
第十一天、函数声明周期以及内存分布
1、对于生命周期是指变量的生命周期,也就是变量从得到内存到释放内存的时间 就是变量的生命周期,程序中变量如果按照存储单元的属性分类,可以分为变 量和常量,也可以按照生命周期进行划分,可以分为全局变量和局部变量。
2、(1) 局部变量:在函数内部定义的变量或者在某个复合语句中定义的变量都称为 局部变量!
(2) 全局变量:在所有的函数外部(在所有复合语句外部)定义的变量就被称 为全局变量!
3、对于局部变量而言,作用域只针对当前局部变量的复合语句有效。
4、当全局变量的名称和局部变量名称相同时,则应该遵循*“就近原则”*,也就是应 该优先使用同一个作用域内的变量,如果该作用域中没有该变量,则可以扩大作用域。
5、由于C语言不支持函数的返回值类型是一个数组,但是可以选择把数组的地址作 为返回值,此时函数的返回值类型就应该是指针才对。
6、把函数内部的局部变量的生命周期延长,此时需要使用C语言中的存储 类修饰符,就是C语言关键字之一的static关键字,static具有静态的含义,可 以把局部变量的生命周期进行延长。
7、从内存角度分析:如果在函数内部定义一个局部变量,则系统会从内存分区中 的*栈空间*中分配一块内存给局部变量,栈空间是由系统自动管理,所以当函 数调用结束时系统会自动释放该局部变量的内存。
8、如果函数中定义的局部变量使用static关键字进行修饰,则系统会从*全局数 据区*分配内存空间给该局部变量,全局数据区的生命周期是跟随程序的, 不会因为函数结束而释放。
9、static除了可以修饰局部变量外,也可以用于修饰函数,如果一个函数在定义的 时候使用static关键字进行修饰,则可以限制函数的作用域为文件内部有效。
10、内存分布
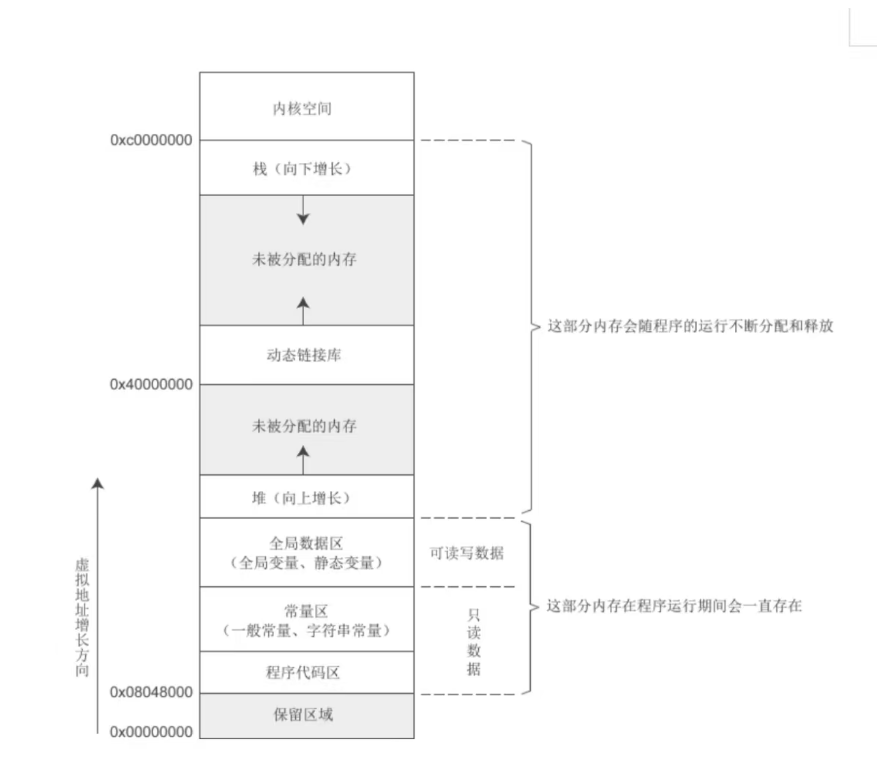
(1)、保留区的地址范围是0x0000_0000 ~ 0x0804_8000,所以保留区的大 小是128M,用户没有访问权限,NULL指向的就是保留区0x0000_0000
(2)、代码段分为:.text段用于存储用户程序生成的指令
.init段用户存储系统初始化的指令
(这两部分的属性都是只读的)
(3)、数据段(根据数据类型以及是否被初始化)把数据存储在三个位置:
.rodata段:被称为只读常量区,程序中的常量(整型常量、字符串 常量)都是存储在该区域,对于该区域的属性是只读的,当程 序结束后该区域的内存会被释放。
.data段:用于存储程序中的已经被初始化的全局变量和已经被初始 化的静态局部变量,另外注意初始化的值不能为0!
.bss段:用于存储程序中未被初始化的全局变量以及未被初始化的 静态局部变量以及初始化为0的全局变量和初始化为0的静态局 部变量。
(4)、堆内存:
堆空间属于用户可以随意支配的内存,用户想要支配堆空间的内存 的前提是需要向内核申请,可以通过库函数malloc()、calloc()申请堆 内存,注意堆空间需要用户手动申请以及手动进行释放,通过库函 数free()释放堆内存。堆内存属于匿名内存,只能通过指针访问!!!
malloc():只需要一个参数,该参数指的是需要申请的堆内存的大小,以字 节为单位。申请的堆内存是未被初始化的,用户应该进行初始化
calloc():可以申请堆内存,有两个参数,第一个参数是要申请的 内存块的数量,第二个参数是内存块的大小,所以申请的内存的总 大小 = 内存块数量 * 内存块大小,相当于是数组结构。申请的堆是初始 化的
(5)、栈空间:
栈空间主要用于存储程序的命令行参数、局部变量、函数的参数值、函数 的返回地址,当函数被调用期间,内核会分配对应大小的栈空间给函数使 用,当函数调用完成则栈空间就会内核释放。
栈空间的地址分配是*向下递增*,所以栈空间使用的越多,则分配的内存 地址越低,栈空间的数据遵循“*先进后出*”原则,一般内核都会提供两个 指针,一个指针指向栈顶,一个指针指向栈底,数据进入栈空间的动作就 叫做入栈/压栈(PUSH),数据从栈空间出去的动作就叫做出栈/弹栈 (POP)。栈空间的大小默认是8M
第十二天笔记、const关键字
1、const是C语言的关键字之一,其实是英文constant的缩写,具有常量的含 义,const关键字在C语言标准中是类型限定符,一般用于修饰变量的, 可以用于降低变量的访问权限,相当于把变量的属性变为只读,变量的存 储单元只能读,不能写。
2、思考:C语言中明明支持定义常量,为什么还需要定义一个变量,再把变 量的权限变为只读?
回答:程序的中的常量都是存储在只读常量区(.rodata段),但是由于这个段 的属性是只读的,并且没有办法通过名称来访问常量,所以就可以定义变 量,通过变量名称来间接访问在程序运行期间不需要修改的常量的值!
3、注意: 如果需要利用变量来存储一个常量,则需要在定义变量的时候利用 const关键字修饰,并且一定要完成初始化!
第十三天笔记、C语言结构体,联合体,枚举
1、C语言标准中提供了一个叫做struct的关键字,是英文structure的缩写,具 有结构的含义,一般在C语言中利用该关键字设计的类型被称为结构体。
2、定义格式:
struct 结构体名称
{
数据类型 成员名称;
数据类型 成员名称;
数据类型 成员名称;
....
}; //注意:复合语句后的分号不可以省略
3、注意:构造的结构体类型是不占内存的,只有使用该类型创建的变量才会 得到内存空间!!!
4、算自定义数据类型宽度的时候,要考虑CPU的运行效率,一般嵌入式系统 都采用32bit系统,所以CPU的地址总线是32bit,所以为了提高CPU的工 作效率,所以寻址都是4字节为主,也就是当数据宽度不够4字节,则系 统默认提供4字节内存方便CPU寻址,所以这种方式被称为*字节对齐*。
5、C语言标准的一个预处理指令 #pragma ,C语言标准中的预处理#pragma pack(n)可以用于进行字节对齐以及取消字节对齐。
6、 typedef 数据类型 别名; 如果打算把某个数据类型起一个新的别名,在 使用typedef的时候,新的别名应该在命名的时候末尾添加 _t
7、C语言标准中提供了一个叫做union的关键字,用于构造联合体类型,联合 体也被称为共用体,指的是联合体中的各个成员是共用一块内存空间,所 以联合体的内存空间就是以成员中数据宽度最大的那个成员为主。
8、定义格式:
union联合体名称
{
数据类型 成员名称;
数据类型 成员名称;
数据类型 成员名称;
....
}; //注意:复合语句后的分号不可以省略
9、联合体变量中的成员由于是共用一块内存,所以每个成员的起始地址都是 相同的,只要修改联合体中任何一个成员的值,都会影响其他成员的值, 另外,也不应该同时对联合体中的多个成员进行赋值。
10、注意:联合体也是遵循字节对齐
11、用联合体判断大端、小端问题:
12、C语言中规定,枚举类型也属于用户自定义类型,用户通过关键字enum 可以实现枚举类型的设计,枚举就是把一些没有意义的数字(整数)起一 个有意义的名称,利用该名称就相当使用该整数常量,是为了提高程序可 读性!!
13、枚举 :第一个元素未被初始化,该元素的值默认为0,对当前元素的值 = 上一个元素的值+1
第十四天笔记、宏定义
1、#define预处理指令,define是C语言关键字之一,中文具有定义的含义,所以利 用#define预处理指令可以对某些表达式、某些常量、某些函数进行定义,其 实就是给这些内容起一个可读性较高的名称。
2、宏替换其实就是简单的文本替换,宏名称就是一个用户命名的特定的标识符, 一*般实际开发中宏名称都采用大写*(潜规则)。 macro 宏
3、定义格式: #define 宏名称(大写) 替换列表
4、用户在源文件中某个位置使用了宏,不管使用了多少次,在程序编译之前,预 处理器都会把宏用替换列表进行替换,*当然要注意,宏替换就是单纯的文 本替换*,预处理器并不会做任何检查,比如替换之后是否符合语法,语法的 检查是由编译器在编译阶段进行的。
5、 (1)、无参数的宏定义:除了用户自定义的宏之外,系统中也存在一些已 经定义好的宏,比如常用的NULL就是一个宏,
(2)、带参数的宏定义:C语言标准中支持定义带参数的宏,带参数的宏的 使用在语法上类似于函数调用,宏的参数由括号()进行包含,括号中如果 有多个参数则需要通过逗号来分隔,另外,带参数的宏在定义的时候宏名 称和参数列表之间不能空格
(3)、 无替换列表的宏:C语言中也允许只定义一个宏,这个宏可以没有替 换列表,一般实际开发中都是对程序进行*条件编译*的情况下来使用。条 件编译指的是可以选择性的编译程序中的某段代码,也就是预处理器可以 根据具体的条件来保留或者删除某段源程序。可以理解为是类似于C语言 的判断语句,只不过是使用C语言中的预处理指令来判断宏的有效性,有 效性指的是宏是否为真以及宏是否存在,C语言中提供了多种预处理指令 来实现条件编译。
A. #if 用于判断常量表达式是否成立,遵循“非0即真”原则,#if预处 理指令作为条件编译,一般#if和#endif是结合一起使用的,经 常用于程序中的调试,可以选择保留或注释代码块!
B. #ifdef 用于判断宏是否被定义,如果宏是提前定义好的,则该预 处理指令是有效的,也需要和#endif一起使用
C. #if和#elif和#else和#endif 用于条件编译,可以通过常量表达式的 多种状态来选择保留或者删除某些代码块
D、*#ifndef和#endif* 用于判断宏是否未定义,如果宏定义,则该 代码块会被删除,如果宏未被定义,则该代码块可以保留
6、思考:宏定义一般定义在源文件的开头,所以作用域是针对整个文件,但是有 的时候如果只打算让某个宏只对某个函数有效,请问应该如何实现?
回答:可以实现,可以利用C语言标准中提供的预处理指令#undef,可以提前 终止某个宏的作用域。
7、程序的编译过程:
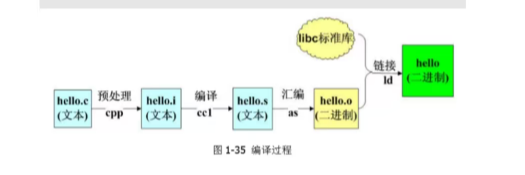
1、预处理:
对源码进简单的加工,GCC编译器会调用预处理器cpp对程序进行预处理,其 实就是解释源程序中所有的预处理指令,如#include(文件包含)、#define (宏定义)、#if(条件编译)等以#号开头的预处理语句。这些处理指令将会 在预处理阶段被解释掉,如会把被包含的文件拷贝进来,覆盖掉原来的 #include语句,把所有的宏定义展开,所有的条件编译语句被执行,GCC还会 把所有的注释删掉,添加必要的调试信息。
预处理指令: gcc -E xxx.c -o xxx.i 会生成预处理文件 xxx.i
2、编译:
就是对经过预处理之后的.i文件进行进一步翻译,也就是对语法、词法的分 析,最终生成对应硬件平台的汇编文件,具体生成什么平台的汇编文件取决于 编译器,比如X86平台使用gcc编译器,而ARM平台使用交叉编译工具arm-li nux-gcc。
编译指令 : gcc -S xxx.i -o xxx.s 会生成汇编文件 xxx.s
3、汇编:
GCC编译器会调用汇编器as将汇编文件翻译成可重定位文件,其实就是把.s文 件的汇编代码翻译为相应的指令。
编译指令 : gcc -c xxx.s -o xxx.o 会生成目标文件 xxx.o
4、链接:
经过汇编步骤后生成的.o文件其实是ELF格式的可重定位文件,虽然已经生成 了指令流,但是需要重定位函数地址等,所以需要链接系统提供的标准C库和 其他的gcc基本库文件等,并且还要把其他的.o文件一起进行链接。-lc -lgcc 是默认的,可以省略
编译指令:gcc hello.o -o hello -lc -lgcc 会生成可执行文件 xxx // l是lib的 缩写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号