

阿里云服务故障复现演示
昨天,发完《阿里云的垃圾云主机》,就收到私信,质疑我的发贴动机。拜托,我和阿里云往日无怨,近日无仇,都是纯粹的技术问题,没必要做它的黑公关。清者自清,浊者自浊!因为你不信,现在我就把完整的对比测试公示出来,用事实说话。如果你还不信,可以自己去下载Laxcus大数据操作系统,然后部署到阿里云上试试。
对比测试很简单,只有两个命令:
PARALLEL MULTI SWARM 1M 10K 10K 1MS TO HUB 2 ITERATE 3
PARALLEL MULTI SWARM 1M 10K 10K 100MS TO HUB 2 ITERATE 3
先解释一下“PARALLEL MUTLI SWARM”命令的含义,这是Laxcus大数据操作系统里面一个流量测试命令,提供Laxcus的帮助图。

图上解释很清楚了,我就不必多说。我的测试情况是:Laxcus大数据操作系统部署在阿里云服务器上,Front客户端在我公司,通过远程登录连上阿里云的Laxcus大数据操作系统,然后向阿里云发送数据流量测试包,等待它的反馈结果。
先测第一个命令:“PARALLEL MULTI SWARM 1M 10K 10K 1MS TO HUB 2 ITERATE 3”,这个命令的意思是:同时有3个线程发送1兆的数据包,1兆数据切割成单个10K的小包,每个包发送间隔时间是1毫秒,连续发送2次1M数据包,这样总共只有6兆的数据。这个流量其实已经非常小了,我们上网看视频,QQ发送文件,都远比这个大得多,但是在阿里上什么表现呢,请看下面的图。

测试结果显示是失败,登录阿里云查看,这个流量测试直接到导致Gate节点的Java虚拟机崩溃。我也是真无语了。

重新启动接受测试的Gate节点,测试参数变成:“PARALLEL MULTI SWARM 1M 10K 10K 100MS TO HUB 2 ITERATE 3”再试,测试显示成功,请看下图。
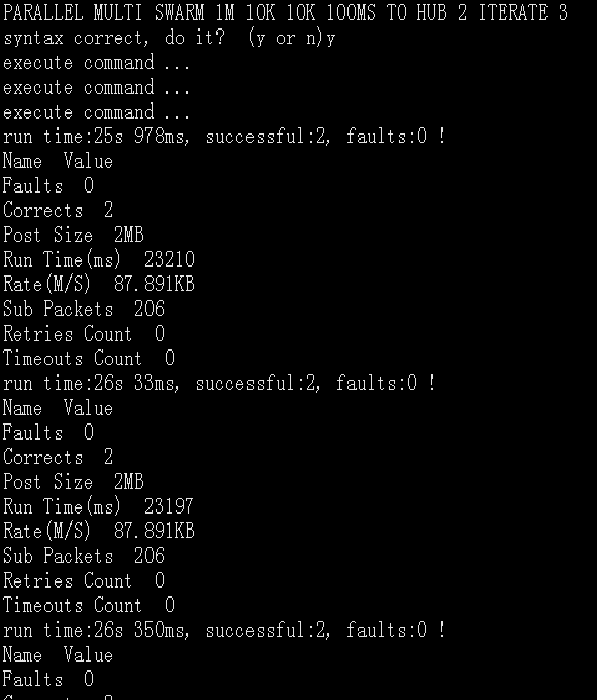
评测对比,两次测试的参数,唯一改变的就是把1毫秒的发送间隔改成100毫秒(1ms -> 100ms),后面的测试成功,前面的测试失败,连Java虚拟机都崩溃!这说明什么问题了?结合看Laxcus大数据操作系统的源代码,我的分析体会:Gate服务器收到客户端的数据包后,要分配本地内存,把数据保存起来,进行数据包正确性校验,然后向客户端发出确认/重发反馈。在分配内存这个阶段,因为1毫秒的时间间隔,造成Gate服务器频繁通过JVM向阿里云申请内存,阿里云无法承受这种密度的频繁请求,直接把JVM挂掉。改成100毫秒后,增加了时间延迟,阿里云有了反应时间,可以给应用分配内存,使得流量测试成功,也保留JVM和GATE服务器仍然存活。
但是这不是重点,重点是:100毫秒的发送间隔放到应用场景毫无意义,大数据应用场景的数据流量都是GB、TB计量。按照这个规模大家可以算一下,到时GB/TB容量的数据传输要消耗多少时间呢?
我不知道阿里云上的虚拟化服务是不是都是这样,但是阿里云如果不把这个核心问题解决,迟早彻底失去用户信任!!!
posted on 2018-12-16 15:11 liudongyang 阅读(352) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号