Kernel File Handle 详解
1. NFS 用什么代表文件?
NFS 的客户端和服务端交互时,怎么告诉服务端操作哪个文件?网络文件系统在传输中用什么代表文件?可以使用文件路径代表文件,但有两个小问题:
- NFS 导出的本地目录可能被本地文件系统修改。如果本地文件系统修改了文件名,NFS 客户端回传的文件路径就无法正确找到文件。而在传统文件系统中,通过 open() 打开文件后,即使文件被重命名,也可以正确找到并写入文件。另外,如果本地文件系统删除文件之后再创建了新的同名文件,回传的文件路径会解析到新文件,导致读写对象错误。
- Linux 中定义最大文件路径 PATH_MAX 为 4096,传输的文件路径可能很长,很浪费资源。
为了解决这些问题,NFS 引入了 file handle 这个概念。file handle (fh) 也叫 file identifier (fid)。file handle 默认包含 inode number (ino) 和 inode generation (igeneration)。
inode number 在创建 inode 时生成,在同一个文件系统中唯一但可以重复利用;而 inode generation 是创建 inode 时生成的一串随机数。如果 inode number 相同但 inode gernation 不同,说明这个 inode 已经不是原来的 inode 了。
这样就做到了 file handle 与文件一一对应。同时,inode number 与 inode generation 的大小都是固定的,非常易于传输。
2. file handle 怎么生成?
inode number 和 inode generation 存储在本地文件系统中,file handle 的生成与解析离不开本地文件系统的支持。另外,有些文件系统会定制自己的 file handle,添加一些其他的信息。比如,btrfs 可以生成带 root ino 的 file handle。
本地文件系统通过实现 export_operations 支持 file handle 的生成和解析。下节中会详细说明 export_operations 中和 file handle 相关的接口。
如果要使用 file handle,fs/exportfs/exp.c 里提供了一些简单易用的 API。它们包装了 export_operations ,后文会详细剖析 exportfs API 的具体实现。
3. export_operations 提供了什么能力?
为了支持 NFS daemon 的访问,本地文件系统需要实现自己的 export_operations。下面看看 export_operations 中与 file handle 相关的接口。
3.1 encode_fh
int (*encode_fh)(struct inode *inode, __u32 *fh,
int *max_len, struct inode *parent);
encode_fh 把 inode 和 parent 的信息保存在 fid 中,返回用于描述 fid 编码类型的 fid_type。fid_type 在 decode 时和 fid 配合使用。
文件系统可以自定义 encode_fh 函数,也可以直接使用 exportfs 提供的 helper 函数 export_encode_fh()。export_encode_fh 把 inode 和 parent 的 inode number 和 inode generation 保存在 fid 中,并返回 fid_type FILEID_INO32_GEN_PARENT(意为保存了 32 位的 inode number 和 inode generation,且包含 parent 信息)。如果调用者不提供 parent 指针,则 fid_type 为 FILEID_INO32_GEN (在前面的基础上去掉了 parent 信息)。
每一种不同的编码类型都需要声明在 enum fid_type 里。比如 btrfs 自定义了 FILEID_BTRFS_WITH_PARENT_ROOT 类型 :
enum fid_type {
...
/*
* 64 bit object ID, 64 bit root object ID,
* 32 bit generation number,
* 64 bit parent object ID, 32 bit parent generation,
* 64 bit parent root object ID.
*/
FILEID_BTRFS_WITH_PARENT_ROOT = 0x4f,
...
}
3.2 fh_to_dentry/fh_to_parent
struct dentry *
(*fh_to_dentry)(struct super_block *sb, struct fid *fid,
int fh_len, int fh_type);
struct dentry *
(*fh_to_parent)(struct super_block *sb, struct fid *fid,
int fh_len, int fh_type);
与 encode_fh 不同的是,decode_fh 不由文件系统直接提供,文件系统只需要提供 fh_to_dentry/fh_to_parent 和下面一小节的 get_name/get_parent,接下来的工作由 exportfs api 完成。
fh_to_dentry() 利用 super block 和 fid type 把 fid 解析为 dentry。由于可能挂载多个同类型文件系统,super block 被用来确认具体要找哪个挂载点下的文件。
fh_to_parent() 同理,解析保存在 fid 中的 parent 信息。
3.3 get_name/get_parent
int (*get_name)(struct dentry *parent,
char *name, struct dentry *child);
struct dentry * (*get_parent)(struct dentry *child);
get_name() 在 parent dentry 中,根据 child dentry 检索 child file name 并填到 name 参数里。
文件系统不提供 get_name() 时,exportfs 会使用默认的 get_name。它遍历 parent 目录,通过 child inode number 找到 child file 的记录,然后把 file name 拷贝到 @name 中。(作者疑问:为什么不直接使用 child->d_name?)
get_parent() 通过 child dentry 寻找 parent dentry。文件系统需要提供的 get_parent(),而且必须查找 parent 路径对应的 dentry,而不是仅仅是调用 ->lookup("..")。
在下节的 decode 过程中,我们需要一层一层地向上解析,拿到每个路径分量对应的 dentry。比如假设有 dentry /A/B/C,我们需要 /A/B、/A 和 /,但通过 ->lookup("..") 只能解析出 /A/B/C/.. 、/A/B/C/../.. 、/A/B/C/../.. 。
3.4 other
其他 operations 比如 commit_metadata、get_uuid 等和 file handle 的生成解析无关,此处暂不分析。
4. exportfs API 剖析
fs/exportfs/expfs.c 中使用 export_operations 包装了一些简单易用的 encode/decode API,下面来看看这些 API 的原理和用法。
4.1 encode 部分
extern int
exportfs_encode_inode_fh(struct inode *inode, struct fid *fid,
int *max_len, struct inode *parent);
extern int
exportfs_encode_fh(struct dentry *dentry, struct fid *fid,
int *max_len, int connectable);
exportfs_encode_inode_fh 把 inode 和 parent 信息用 ->encode_fh 或默认的 export_encode_fh 编码到 fid 中。
exportfs_encode_fh 不含 parent 参数,但 dentry 结构中可以保存 parent 信息。在特定需求中,可以把 connectable 参数设置为非 0,将 dentry 的 parent 信息写到 fid 中。 目前 NFS subtree checking 使用了该特性,参考 exports(5) 中的 no_subtree_check。
4.2 decode 部分
extern struct dentry *
exportfs_decode_fh_raw(struct vfsmount *mnt, struct fid *fid, int fh_len,
int fileid_type,
int (*acceptable)(void *, struct dentry *),
void *context);
extern struct dentry *
exportfs_decode_fh(struct vfsmount *mnt, struct fid *fid, int fh_len,
int fileid_type,
int (*acceptable)(void *, struct dentry *),
void *context);
exportfs_decode_fh 与 exportfs_decode_fh_raw 几乎一样,它额外把除 NOMEM 之外的返回值换成 STALE(dentry 无效)。因为大多数时候调用者并不关心实际发生了什么错误,它只要拿到正确的 dentry 或知道 dentry 无效就可以了。
如果需要具体的错误,可以使用 exportfs_decode_fh_raw。首先明确几个概念:
4.2.1 概念:disconnected dentry
dentry 一般是通过文件名一级一级查找创建的,子 dentry 的 parent 成员被设置为父 dentry。无论经过多少次访问,生成的 dentry 都会连接到 root dentry 树上。也就是说,正常文件系统访问文件不会生成游离于 root 之外的 dentry;但 get_dentry 生成的 dentry 不是通过文件路径访问被创建的,无法附加到 root 树上。这些 dentry 被称为 disconnected dentry。
disconnected dentry 会在 refcount 清零时立即回收,其 inode 也可能随之回收。所以对于 decode_fh 来说,如果想要在 decode 后仍然使用 inode 或者 dentry,就需要把 dentry 连接到 parent 上,再对 parent 逐次向上连接,直到 root。
为统一接口, dcache 提供了两个 helper,d_obtain_alias 和 d_splice_alias。他们现在已经成为所有 lookup 的最终调用函数。
4.2.2 概念:dentry alias
文件可以有硬链接,目录不可以有硬链接(因为防止递归)。硬链接可以通过不同的路径访问到同一个 inode,所以一个 inode 可以有多个 dentry,这些 dentry 通过 d_alias 字段链在 inode 的 i_dentry 链表中。
下面解析 exportfs_decode_fh 及其关键函数 reconnect_path 和 reconnect_one:
4.2.3 函数:exportfs_decode_fh
/*
* exportfs_decode_fh_raw: decode @fid,并使用 @acceptable 函数检测是否符合条件。
* @mnt: 挂载点
* @fid, @fh_len, @fileid_type: 需要 decode 的 fid 及其长度、类型(在 encode 时的返回值)
* @acceptable: 调用者可能对 dentry 有特殊要求,通过此回调确认是否接受 decode 出的 dentry。
void * 是下面的 context 参数,struct dentry * 是 decode 出的 dentry
@context: 传给 acceptable
*/
struct dentry *
exportfs_decode_fh_raw(struct vfsmount *mnt, struct fid *fid, int fh_len,
int fileid_type,
int (*acceptable)(void *, struct dentry *),
void *context)
{
const struct export_operations *nop = mnt->mnt_sb->s_export_op;
struct dentry *result, *alias;
char nbuf[NAME_MAX+1];
int err;
/*
* Try to get any dentry for the given file handle from the filesystem.
*/
if (!nop || !nop->fh_to_dentry)
return ERR_PTR(-ESTALE);
// 1.1 获取 fid 对应的 dentry,一般是 disconnected dentry(by d_obtain_alias)。
result = nop->fh_to_dentry(mnt->mnt_sb, fid, fh_len, fileid_type);
if (IS_ERR_OR_NULL(result))
return result;
/*
* If no acceptance criteria was specified by caller, a disconnected
* dentry is also accepatable. Callers may use this mode to query if
* file handle is stale or to get a reference to an inode without
* risking the high overhead caused by directory reconnect.
*/
// 1.2 如果没有 acceptable 的话,caller 可能只是来检查 fid 是否过期的。
// 或者是在非高并发 reconnect 情况下(因为 reconnect 会调用 d_move,
// 导致 dentry 失效)。所以不需要将 dentry 连接到 root 树上。
if (!acceptable)
return result;
if (d_is_dir(result)) {
/*
* This request is for a directory.
*
* On the positive side there is only one dentry for each
* directory inode. On the negative side this implies that we
* need to ensure our dentry is connected all the way up to the
* filesystem root.
*/
// 2.1 如果 fid 代表目录,因为目录没有硬链接,不可能有 alias,所以必须
// 连接到 root 树上。
// 2.1.1 连接到文件系统 root
if (result->d_flags & DCACHE_DISCONNECTED) {
err = reconnect_path(mnt, result, nbuf);
if (err)
goto err_result;
}
// 2.1.2 检查是否接受
if (!acceptable(context, result)) {
err = -EACCES;
goto err_result;
}
// 2.1.3 如接受,返回 dentry
return result;
} else {
/*
* It's not a directory. Life is a little more complicated.
*/
// 2.2 fid 代表的不是目录
struct dentry *target_dir, *nresult;
/*
* See if either the dentry we just got from the filesystem
* or any alias for it is acceptable. This is always true
* if this filesystem is exported without the subtreecheck
* option. If the filesystem is exported with the subtree
* check option there's a fair chance we need to look at
* the parent directory in the file handle and make sure
* it's connected to the filesystem root.
*/
// 2.2.1 首先检查有没有可用的 alias,如果有,直接返回 alias 就可以。
// find_acceptable_alias 结构类似 dcache helper 中的
// d_find_any_alias,只是在循环中检查 dentry 是否被 acceptable。
alias = find_acceptable_alias(result, acceptable, context);
if (alias)
return alias;
/*
* Try to extract a dentry for the parent directory from the
* file handle. If this fails we'll have to give up.
*/
// 2.2.2 先找到 parent dentry,手法类似 2.1。
// 完成之后,fid 的 parent 就在 root 树里了。
err = -ESTALE;
if (!nop->fh_to_parent)
goto err_result;
target_dir = nop->fh_to_parent(mnt->mnt_sb, fid,
fh_len, fileid_type);
if (!target_dir)
goto err_result;
err = PTR_ERR(target_dir);
if (IS_ERR(target_dir))
goto err_result;
/*
* And as usual we need to make sure the parent directory is
* connected to the filesystem root. The VFS really doesn't
* like disconnected directories..
*/
err = reconnect_path(mnt, target_dir, nbuf);
if (err) {
dput(target_dir);
goto err_result;
}
/*
* Now that we've got both a well-connected parent and a
* dentry for the inode we're after, make sure that our
* inode is actually connected to the parent.
*/
// 2.2.3 开始构建 fid dentry。
// 通过 get_name 获取 filename,再通过 lookup 生成 dentry。
// 通过 lookup 生成的 dentry 是在 root 树里的。
err = exportfs_get_name(mnt, target_dir, nbuf, result);
if (err) {
dput(target_dir);
goto err_result;
}
inode_lock(target_dir->d_inode);
nresult = lookup_one_len(nbuf, target_dir, strlen(nbuf));
if (!IS_ERR(nresult)) {
if (unlikely(nresult->d_inode != result->d_inode)) {
dput(nresult);
nresult = ERR_PTR(-ESTALE);
}
}
inode_unlock(target_dir->d_inode);
/*
* At this point we are done with the parent, but it's pinned
* by the child dentry anyway.
*/
dput(target_dir);
if (IS_ERR(nresult)) {
err = PTR_ERR(nresult);
goto err_result;
}
dput(result);
result = nresult;
/*
* And finally make sure the dentry is actually acceptable
* to NFSD.
*/
// 2.2.4 一番操作后,应该有 alias 了,找出来并返回。
alias = find_acceptable_alias(result, acceptable, context);
if (!alias) {
err = -EACCES;
goto err_result;
}
return alias;
}
err_result:
dput(result);
return ERR_PTR(err);
}
EXPORT_SYMBOL_GPL(exportfs_decode_fh_raw);
4.2.4 函数:reconnect_path
/*
* Make sure target_dir is fully connected to the dentry tree.
*
* On successful return, DCACHE_DISCONNECTED will be cleared on
* target_dir, and target_dir->d_parent->...->d_parent will reach the
* root of the filesystem.
*/
// 如注释所述,把 target_dir 连接到 root 树上。
// 实际实现是先连接到 parent,再把 parent 向上连接,循环,直到连接到 root 树。
static int
reconnect_path(struct vfsmount *mnt, struct dentry *target_dir, char *nbuf)
{
struct dentry *dentry, *parent;
dentry = dget(target_dir);
while (dentry->d_flags & DCACHE_DISCONNECTED) {
BUG_ON(dentry == mnt->mnt_sb->s_root);
// 这里解释一下, IS_ROOT 是 dentry->parent == dentry。
// 对于 disconnected dentry,一个表现是有 DCACHE_DISCONNECTED flag。
// 另一个是 dentry->parent == dentry。
if (IS_ROOT(dentry))
parent = reconnect_one(mnt, dentry, nbuf);
else
parent = dget_parent(dentry);
if (!parent)
break;
dput(dentry);
if (IS_ERR(parent))
return PTR_ERR(parent);
dentry = parent;
}
dput(dentry);
clear_disconnected(target_dir);
return 0;
}
4.2.5 函数:reconnect_one
/*
* Reconnect a directory dentry with its parent.
*/
static struct dentry *reconnect_one(struct vfsmount *mnt,
struct dentry *dentry, char *nbuf)
{
struct dentry *parent;
struct dentry *tmp;
int err;
parent = ERR_PTR(-EACCES);
inode_lock(dentry->d_inode);
// 1. 获取 parent dentry
if (mnt->mnt_sb->s_export_op->get_parent)
parent = mnt->mnt_sb->s_export_op->get_parent(dentry);
inode_unlock(dentry->d_inode);
if (IS_ERR(parent)) {
dprintk("%s: get_parent of %ld failed, err %d\n",
__func__, dentry->d_inode->i_ino, PTR_ERR(parent));
return parent;
}
dprintk("%s: find name of %lu in %lu\n", __func__,
dentry->d_inode->i_ino, parent->d_inode->i_ino);
// 2. 找到 parent 下和 dentry 有相同 ino 的条目,把 filename 填入 nbuf
err = exportfs_get_name(mnt, parent, nbuf, dentry);
if (err == -ENOENT)
goto out_reconnected;
if (err)
goto out_err;
dprintk("%s: found name: %s\n", __func__, nbuf);
// 3. 在 parent 下查找 filename,获取 dentry。
// 注意通过 lookup 生成的 dentry 是在 root 树里的,这样就达到了 connect。
tmp = lookup_one_len_unlocked(nbuf, parent, strlen(nbuf));
if (IS_ERR(tmp)) {
dprintk("%s: lookup failed: %d\n", __func__, PTR_ERR(tmp));
err = PTR_ERR(tmp);
goto out_err;
}
// 4. 异常情况处理
if (tmp != dentry) {
/*
* Somebody has renamed it since exportfs_get_name();
* great, since it could've only been renamed if it
* got looked up and thus connected, and it would
* remain connected afterwards. We are done.
*/
dput(tmp);
goto out_reconnected;
}
dput(tmp);
if (IS_ROOT(dentry)) {
err = -ESTALE;
goto out_err;
}
// 5.1 正常情况,返回 parent dentry
return parent;
out_err:
dput(parent);
return ERR_PTR(err);
out_reconnected:
dput(parent);
/*
* Someone must have renamed our entry into another parent, in
* which case it has been reconnected by the rename.
*
* Or someone removed it entirely, in which case filehandle
* lookup will succeed but the directory is now IS_DEAD and
* subsequent operations on it will fail.
*
* Alternatively, maybe there was no race at all, and the
* filesystem is just corrupt and gave us a parent that doesn't
* actually contain any entry pointing to this inode. So,
* double check that this worked and return -ESTALE if not:
*/
// 5.2 没有连接成功,dentry 过期。
if (!dentry_connected(dentry))
return ERR_PTR(-ESTALE);
// 5.3 连接成功,但是 parent 已经失效了,可能是由于 rename 或 remove。也算成功。
return NULL;
}
5. file handle 的其他使用场景
file handle 最开始被用于网络文件系统传递 dentry。后面因为其能把 dentry 持久化,又衍生出了其他的应用。
5.1 overlayfs
overlayfs 是一种 union file system,它将底层文件系统中不同目录进行合并,然后呈现给用户。主要特性有:
- 上下层同名目录合并
- 上下层同名文件覆盖
- lower layer 只读,其中的文件写时拷贝(copy up)到 upper layer 中
在 overlayfs 中,file handle 主要用来关联上下层文件以及解决 hardlink break 问题。因为 overlayfs 可能有多个 layer,在生成 file handle 时,也会记录文件系统的 uuid。
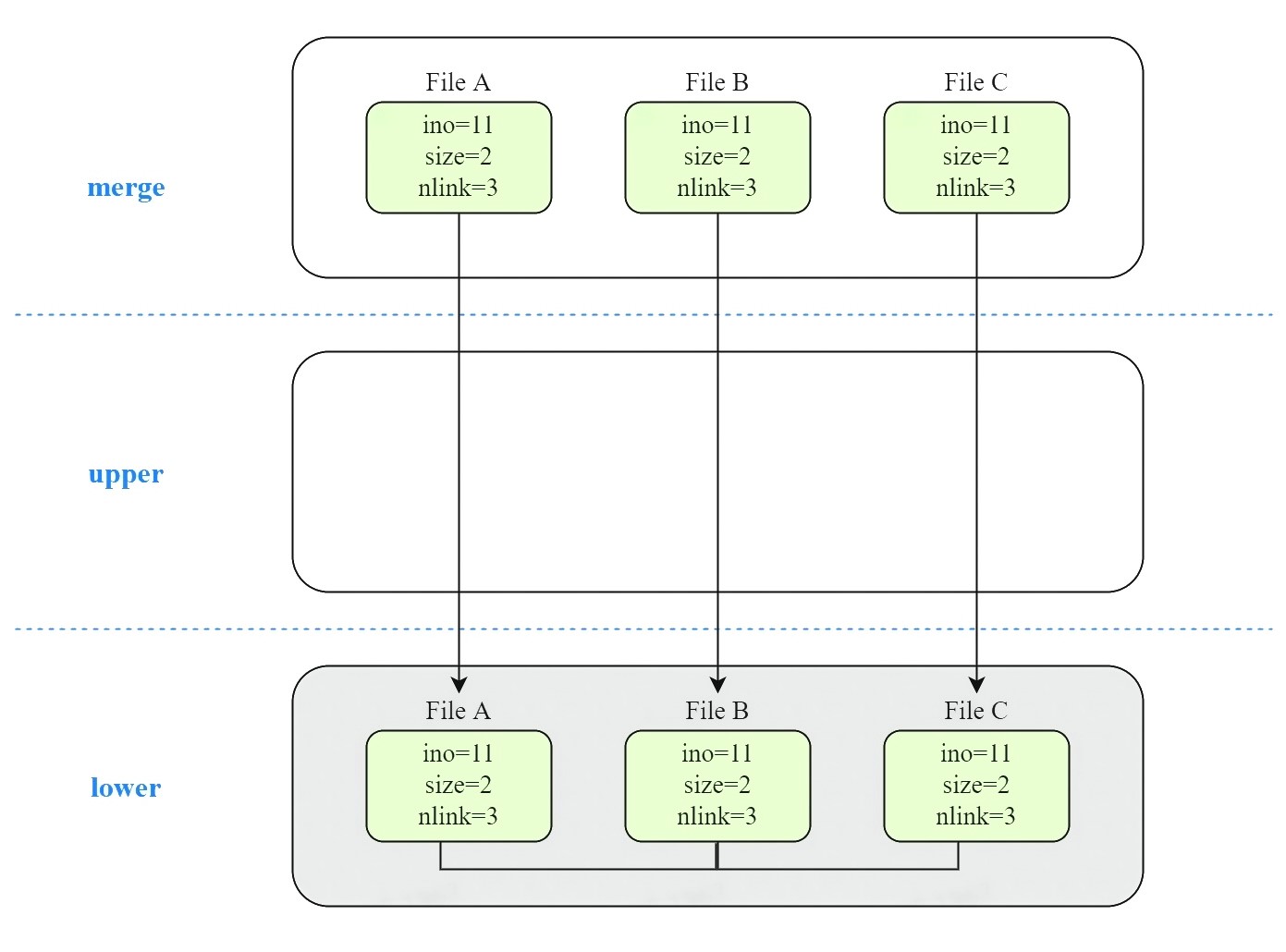
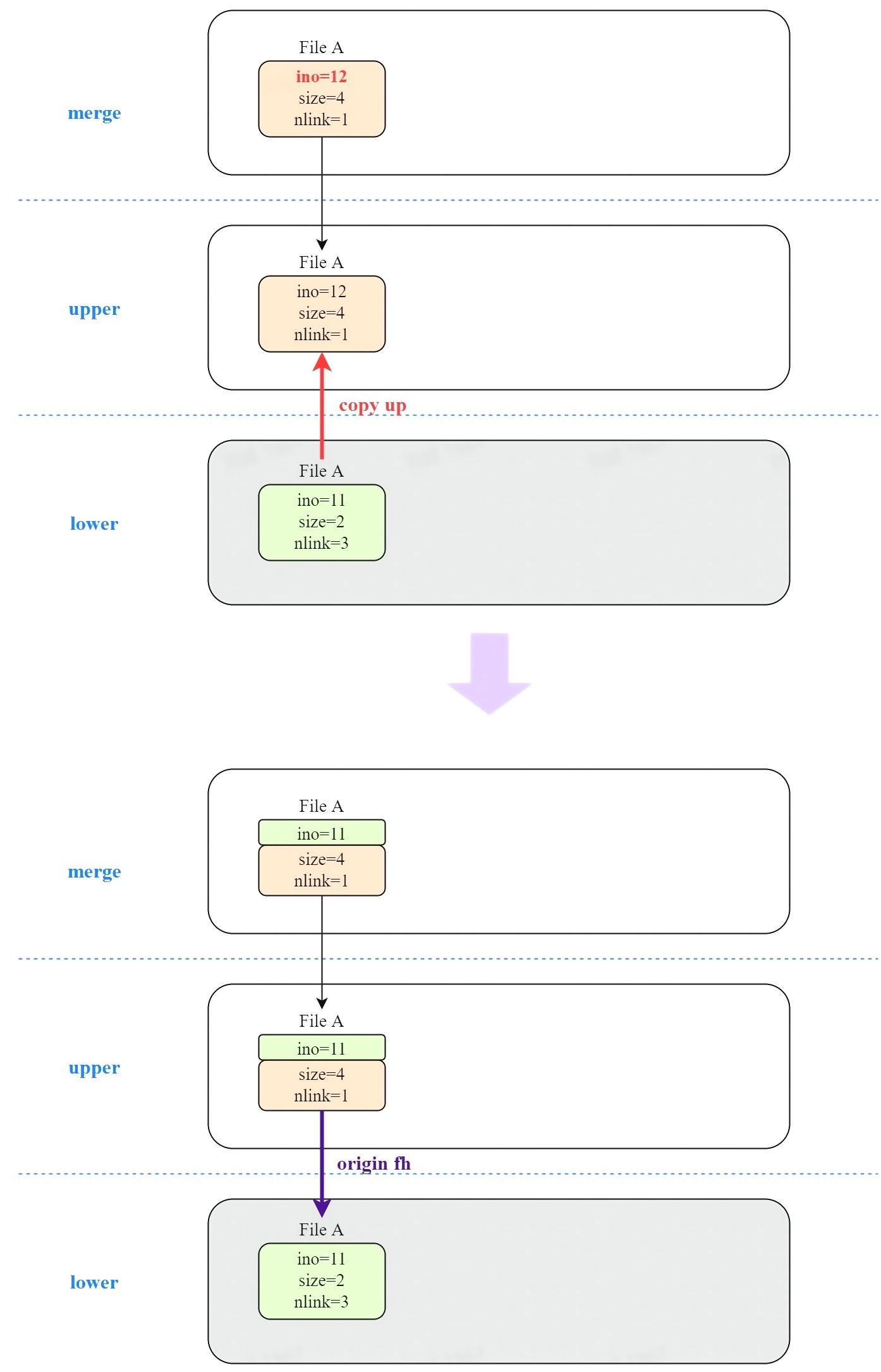
假设 lower layer 中存在文件 A 和 A 的硬链接 B、C,upper layer 为空。挂载 overlayfs 后,merge dir 中的文件及其属性如图所示:
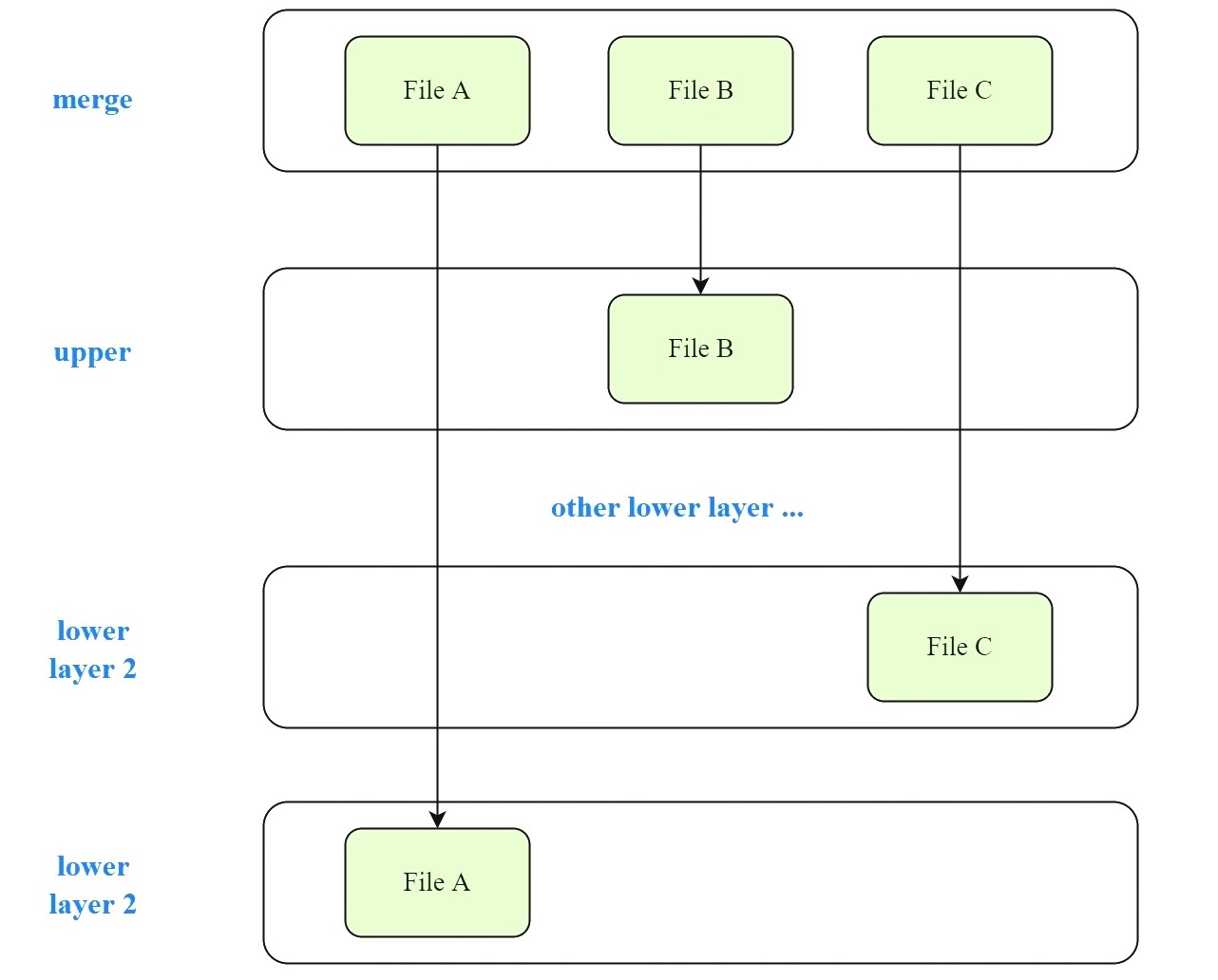
此时追加两个字节到文件 A,此时 merge dir 中预期结果为文件 A、B、C size 同时变为 4,ino 不变,nlink 不变。
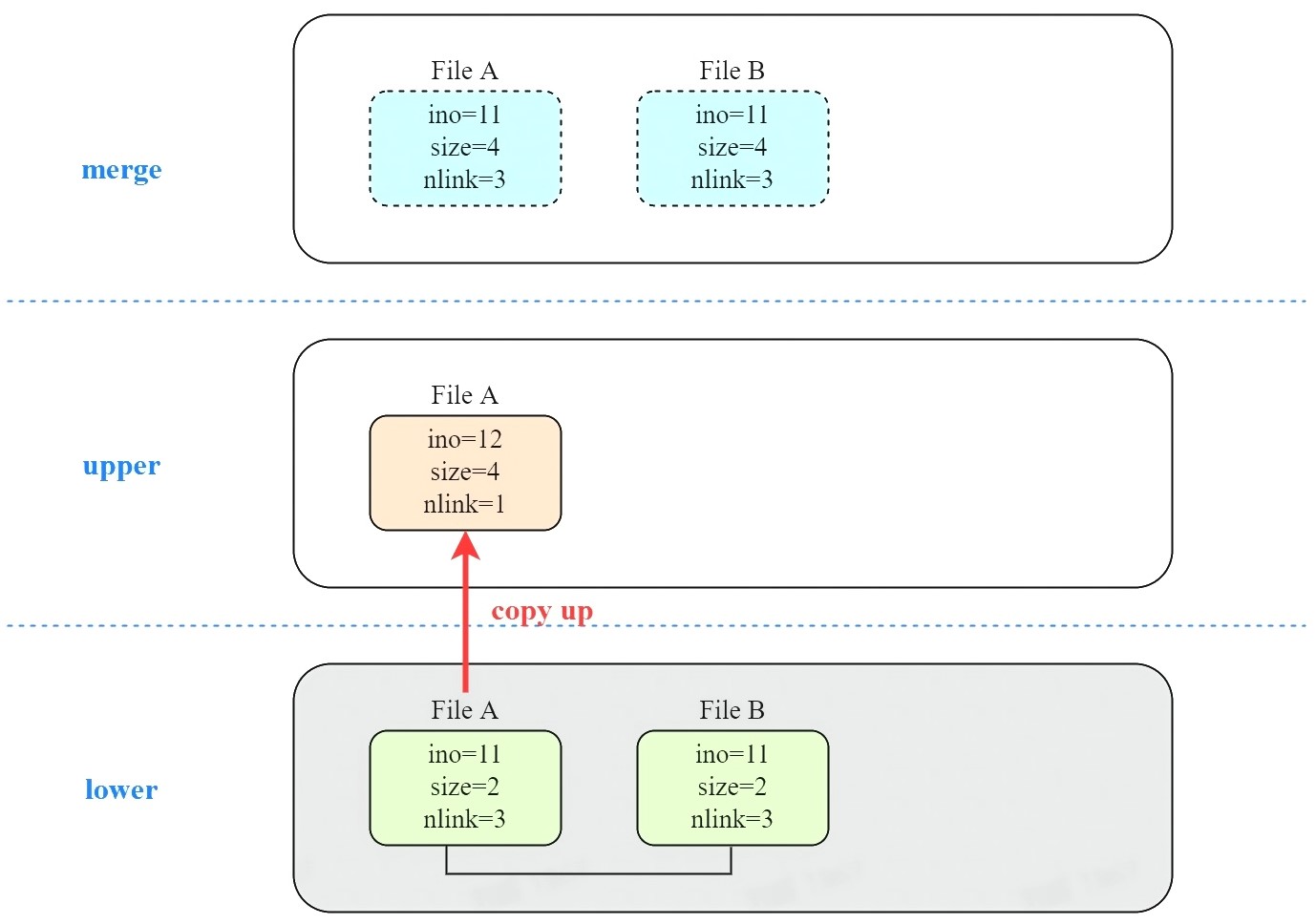
但对于 overlayfs,lower layer 只读,因此需要将文件 A copy up 到 upper layer 再进行写入。copy up 产生了新 inode,因此 ino 和 nlink 都发生了变化。
另外,因为没有在 upper layer 中创建硬链接 B、C,导致 merge dir 中看到的 B、C 文件 size 仍为 2。
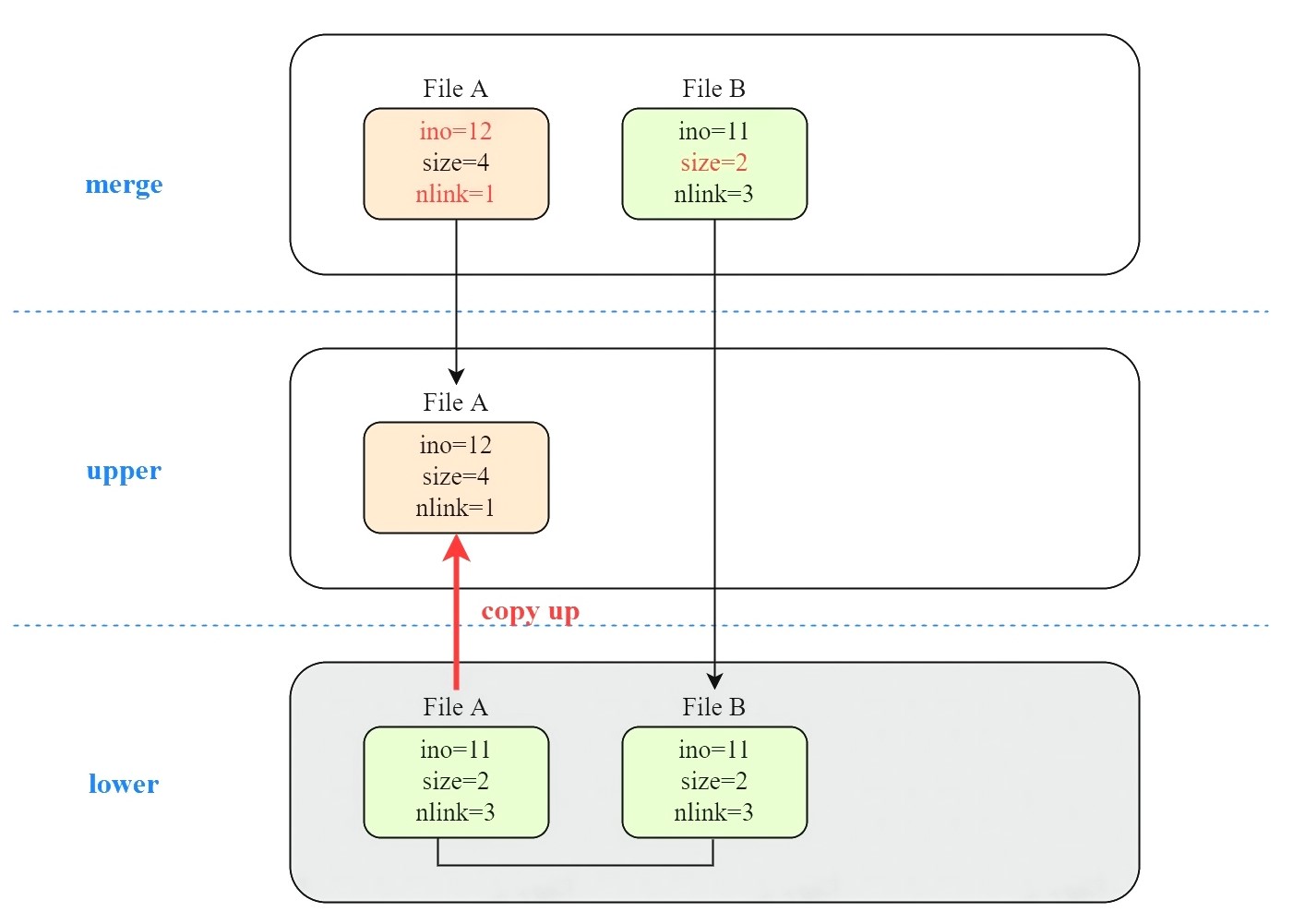
这里有三个待解问题:
- 文件 A 的 ino 预期为 11,实际为 12。
- 文件 B、C size 预期为 4,实际为 2。(后面仅分析文件 B,文件 C 同理)
- 文件 A 的 nlink 预期为 3,实际为 1。
5.1.1 inode number 不一致问题
ino 的不一致可以通过在 upper file 中保存 lower layer 对应文件的 file handle 解决。在 lookup file A 时,检测到其保存了 origin file handle,就以 origin file 的 ino 为准。
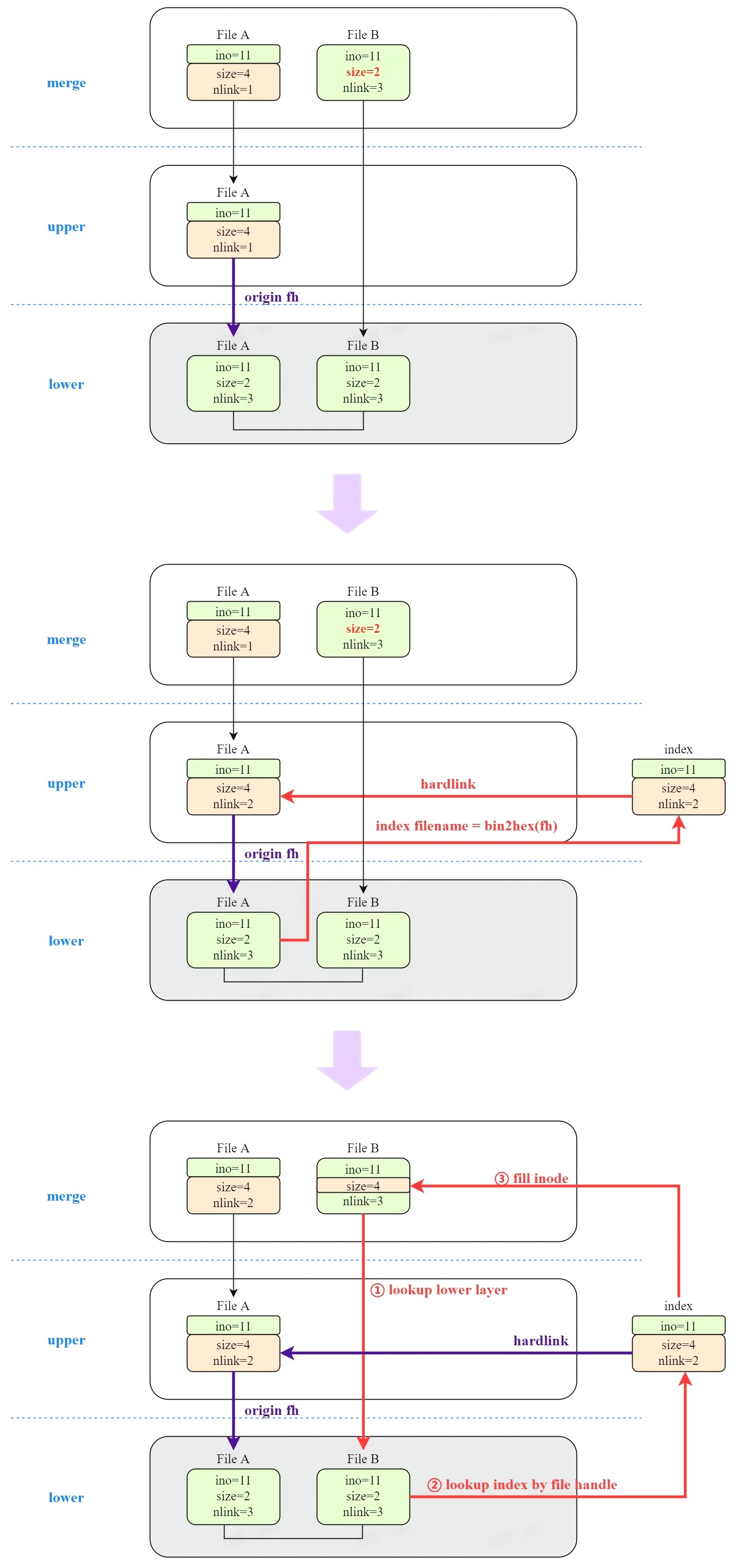
5.1.2 size 不一致问题
如何让文件 B 获取到文件 A 的新 size?
注意到在 lower layer 中,文件 B 与文件 A 指向相同的 inode,其 file handle 相同。如果 upper layer 中存在由文件 A copy up 的文件,那么就可以通过这个文件确定文件 B 的实际 size。
但是,遍历 upper layer 中所有文件太过耗时。overlayfs 使用挂载时指定的额外的 work 目录,把所有 file handle 以文件名的形式保存在 workdir/index 目录中,这样就可以通过 lookup work 目录,快速知道是否存在 file handle。
另外,overlayfs 会在 copy up 后将 index file 硬链接到文件 A(实际过程是先创建 index file 再硬链接到文件 A),这样就能很方便地获取到文件 A 的 size。所以,在 overlayfs 中,查找文件 B 的过程是这样的:
- lookup upper layer,没有找到
- lookup lower layer,找到文件 B
- 计算文件 B 的 file handle,转化为 16 进制字符串。检查到 workdir 中存在对应的 index file
- 生成文件 B 的 inode,并修正其 i_size 等属性
5.1.3 nlink 不一致
在生成 index file 后,文件 A 的 nlink 已经变成 2。解决 nlink 不一致问题只需要在文件 A 中保存与原始文件的 nlink 差,再生成 inode 时补上对应值即可。
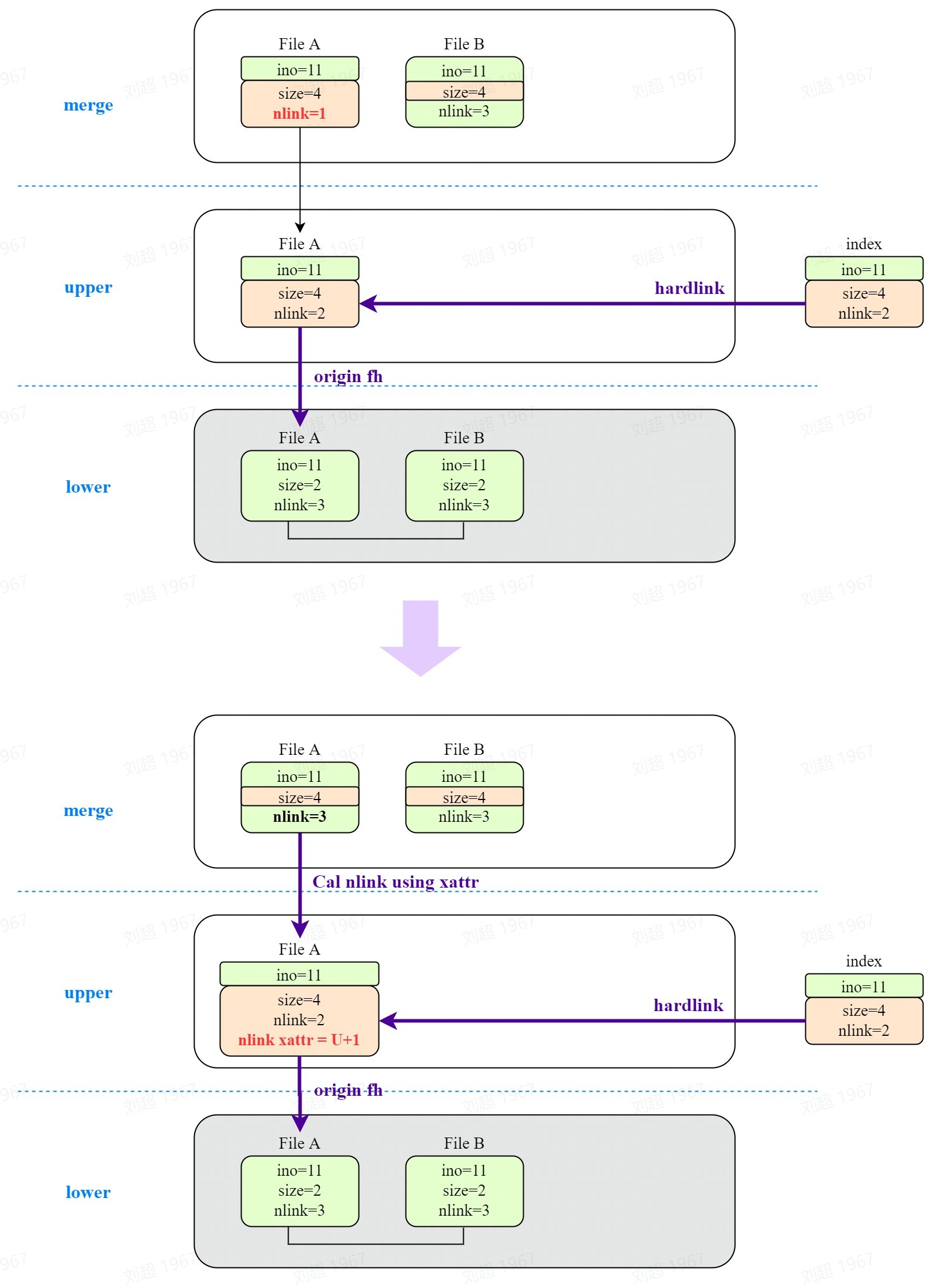
注意下次创建或删除硬链接时,都会更新保存的差值。
5.2 syscalls & ioctl
fs/fhandle.c 使用 exportfs API 包装了提供了两个系统调用:name_to_handle_at 和 open_by_handle_at。它们拆分了 openat 的功能。name_to_handle_at 返回 fid,open_by_handle_at 使用 fid 打开对应的文件,并返回 fd。
为什么需要两个步骤打开文件,而不是直接调用 open?
主要还是考虑在用户级远程文件系统中存在延时打开文件的场景。用户文件系统服务器可以使用 name_to_handle_at 生成 fid 并传递给客户端。当客户端需要时,将 fid 回传并打开文件。
XFS 使用此思想扩展了许多 API,主要用于备份和恢复操作以及分层存储管理系统。
- XFS_IOC_FD_TO_HANDLE_32
- XFS_IOC_PATH_TO_HANDLE_32
- XFS_IOC_PATH_TO_FSHANDLE_32
- XFS_IOC_OPEN_BY_HANDLE_32
- XFS_IOC_READLINK_BY_HANDLE_32
- XFS_IOC_ATTRLIST_BY_HANDLE_32
- XFS_IOC_ATTRMULTI_BY_HANDLE_32
6. 参考文档
- Making Filesystems Exportable — The Linux Kernel documentation
- Linux source code (v5.17.8) - Bootlin
- The Directory Cache
- filesystem - Why are hard links not allowed for directories? - Ask Ubuntu
- 目录项高速缓存 - Space Patrol Delta-(S.P.D)
- VFS数据结构之(dentry)_指向NULL的博客-CSDN博客_dentry数据结构
- 深入理解overlayfs(一):初识_luckyapple1028的博客-CSDN博客_linux overlayfs
- 深入理解overlayfs(二):使用与原理分析_luckyapple1028的博客-CSDN博客_mount overlay
- open_by_handle_at(2) - Linux manual page
- Open by handle [LWN.net]
- exports(5): NFS server export table - Linux man page

 浙公网安备 33010602011771号
浙公网安备 33010602011771号