python网络编程05 /TCP阻塞机制
python网络编程05 /TCP阻塞机制
1.什么是拥塞控制
- 拥塞控制就是防止过多的数据注入网络中,这样可以使网络中的路由器或链路不致过载。
2.拥塞控制要考虑的因素
- 拥塞控制所作的都有一个前提,就是网络能够承受现有的网络负荷。
- 拥塞控制是一个全局性的过程,涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
- TCP连接的端点只要迟迟不能收到对方的确认信息,就猜想在当前网络中的某处可能发生了拥塞,但这时却无法知道拥塞到底发生在网络的何处,也无法知道发生拥塞的具体原因。
3.拥塞控制的方法:
前提:1.数据是单方向传送的,对方只传送确认报文。
2.接收方总是有足够大的缓存空间,因而发送窗口的大小由网络的拥塞程度来决定
1、慢开始和拥塞避免
-
前提:
a.下面讨论的拥塞控制也叫做基于窗口的拥塞控制。 b.发送方维持一个叫做拥塞窗口cwnd(Congestion window)的状态变量。 c.拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。 d.发送方让自己的发送窗口等于拥塞窗口。 -
发送方控制拥塞窗口的原则
1.只要网络没有出现拥塞,拥塞窗口就可以再增大一些,以便把更多的分组发送出去,这样就可以提高网络的利用率。 2.但只要网络出现拥塞或有可能出现拥塞,就必须把拥塞窗口减小一些,以减少注入到网络中的分组数,以便缓解网络出现的拥塞。 -
慢开始算法的思路
1.当主机开始发送数据时,由于并不清楚网络的负荷情况,所以如果立即把大量数据字节注入到网络,那么就有可能引起网络发生拥塞。 2.经验证表明,较好的办法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口的数值。 -
新的RFC 5681把初始拥塞窗口cwnd设置规定
1.若SMSS>2190 字节,则设置初始拥塞窗口 cwnd = 2 * SMSS字节,且不得超过2个报文段。 2.若SMSS>1095 且SMSS<2190字节,则设置初始拥塞窗口cwnd=3*SMSS字节,且不得超过3个报文段。 3.若SMSS<=1095字节,则设置初始拥塞窗口cwnd=4* SMSS 字节,且不得超过4个报文段。 4.慢开始规定,在每收到一个新的报文段的确认后,可以把拥塞窗口增加最多一个SMSS的数值。 5.拥塞窗口cwnd每次的增加量=min(N, SMSS) -
慢开始流程:
1.在一开始发送方先设置cwnd = 1,发送第一个报文段M1,接收方收到后确认M1 2.发送方收到对M1的确认后,把cwnd从1增大到2,于是发送方接着发送M2和M3两个报文段,接收方收到后发回对M2和M3的确认 3.发送方每收到一个对新报文段的确认(重传的不算在内)就使发送方的拥塞窗口加1,因此发送方在收到两个确认后,cwnd就从2增大到4,并可发送M4~M7共4个报文段 4.使用慢开始算法后,每经过一个传输轮次,拥塞窗口cwnd就加倍。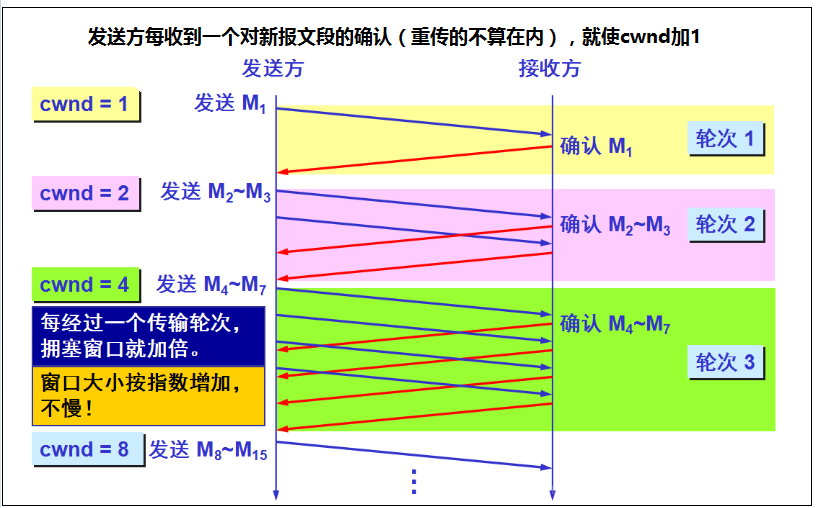
-
RTT:一个传输轮次所经历的时间
1.一个传输轮次所经历的时间其实就是往返时间RTT(RTT并非恒定的数值) 2.使用“传输轮次”是更加强调:把拥塞窗口所允许发生的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认 3.例如,拥塞窗口cwnd的大小是4个报文段,那么这时的往返时间RTT就是发送方连续发送4个报文段,并收到这4个报文段的确认,总共经历的时间。 4.在TCP的实际运行中,发送方只要收到一个对新报文段的确认,其拥塞窗口cwnd就立即加1,并可以立即发送新的报文段,而不需要等这个轮次中所有的确认都收到后再发送新的报文段。 -
ssthresh状态变量:慢开始的门限
为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量 1.当cwnd < ssthresh时,使用上述的慢开始算法 2.当cwnd > ssthresh时,停止使用慢开始算法而改用拥塞避免算法 3.当cwnd = ssthresh时,即可以使用慢开始算法,也可以使用拥塞避免算法。 -
拥塞避免算法的思路
拥塞避免算法的思路是让拥塞避免窗口cwnd缓慢的增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1。 1.假定cwnd等于10个MSS的长度,而MSS是1460字节,发送方可一连发送14600字节(即10个报文段)。 2.假定接收方每收到一个报文段就发回一个确认。 3.于是发送方每到一个新的确认,就把拥塞窗口稍微增大一些,即增大0.1 MSS = 146字节。 4.经过一个往返时间RTT(或一个传输轮次)后,发送方共收到10个新的确认,拥塞窗口就增大了1460字节,正好是一个MSS的大小。) 5.不是像慢开始阶段那样加倍增长。因此在拥塞避免阶段就有“加法增大”AI的特点。 6.这表明在拥塞避免阶段,拥塞窗口cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
2、快重传和快恢复
-
快重传以及优势
1.采用快重传算法可以让发送方尽早知道发生了个别报文段的丢失。 2.快重传算法首先要求接收方不要等待自己发送数据时才进行捎带确认,而是要立即发送确认,即使收到了失序的报文段也要立即发出对已收到的报文段的重复确认。 -
快重传的流程
1.接收方收到了M1和M2后都分别及时发出了确认。 2.现假定接收方没有收到M3的但收到了M4,本来接收方可以什么都不做。 3.但按照快重传算法,接收方必须立即发送对M2的重复确认,以便让发送方及早知道接收方没有收到报文段M3。 4.发送方接着发送M5和M6,接收方收到后也仍要再次分别发出对M2的重复确认。 5.这样,发送方共收到了接收方的4个对M2的确认,其中后3个都是重复确认。 6.快重传算法规定,发送方只要一收到3个重复确认,就知道接受方确实没有收到报文段M3,因而应当立即进行重传(即“快重传”),这样就不会出现超时,发送方也不就会认为出现了网络拥塞。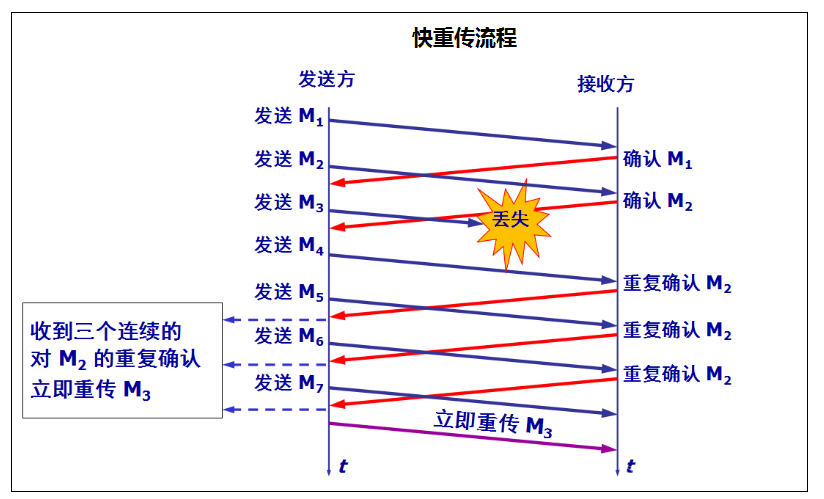
-
快恢复的两个特点
1)当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把慢开始门限减半,这是为了预防网络发生拥塞。 2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,而是把cwnd值设置为慢开始门限减半后的值,然后开始执行拥塞避免算法,是拥塞窗口的线性增大。 -
快恢复和慢开始的区别:
慢开始算法只是在TCP建立时才使用,快恢复是在遇到网络拥塞接收不到数据时触发,常常伴随着快重传算法。
4.慢开始、拥塞避免算法实例流程
-
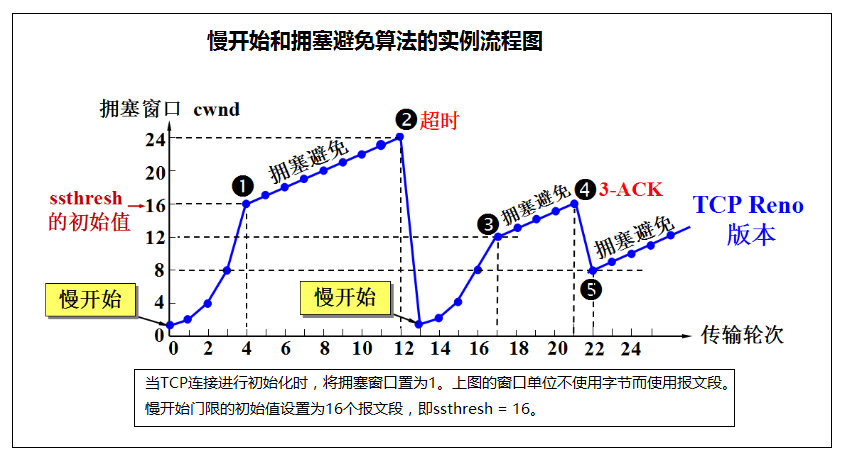
流程描述:
1、当TCP连接进行初始化时,把拥塞窗口cwnd置为1。 2、慢开始门限的初始值置为16个报文段,即ssthresh = 16。 3、在执行慢开始算法时,发送方每收到一个对新报文段的确认ACK,就把拥塞窗口值加1,然后开始下一轮的传输(图中的横坐标是传输轮次,不是时间)。 4、因此拥塞窗口cwnd随着传输轮次按指数规律增长。 5、当拥塞窗口cwnd增长到慢开始门限值ssthresh时(图中点(1),此时拥塞窗口cwnd=16)。 6、改为执行拥塞避免算法,拥塞窗口按线性规律增长。 7、“拥塞避免”并非完全能够避免拥塞,“拥塞避免”是说把拥塞窗口控制为线性规律增长,使网络比较不容易出现拥塞。 8、当拥塞窗口cwnd=24时,网络出现了超时(图中点(2)),发送方判断为网络拥塞,于是调整门限值ssthresh=cwnd/2=12,同时设置拥塞窗口cwnd=1,进入慢开始阶段。 9、按照慢开始算法,发送方每收到一个对新报文段的确认ACK,就把拥塞窗口值加1。 10、当拥塞窗口cwnd=ssthresh = 12时(图中点(3),则是新的ssthresh值),改为执行拥塞避免算法,拥塞窗口按线性规律增大。 11、当拥塞窗口cwnd=16时(图中点(4)),出现了一个新的情况,就是发送方一连收到3个对同一个报文段的重复确认(图中记为3-ACK)。这是因为:有时,个别报文段会在网络中丢失,但实际上网络并未发生拥塞。如果发送方迟迟收不到确认,就会产生超时,就会误认为网络发生了拥塞。这就导致发送方错误地启动慢开始,把拥塞窗口cwnd又设置为1,因而降低了传输效率。 12、图中的点(4),发送方知道现在只是丢失了个别的报文段,于是不启动慢开始,而是执行快恢复算法。 13、这时,发送方调整门限值ssthresh = cwnd/2 = 8,同时设置拥塞窗口cwnd=ssthresh = 8(上上图中点(5)),并开始执行拥塞避免算法。 14、请注意,也有的快恢复实现是把快恢复开始时的拥塞窗口cwnd值再增大一些(增大3个报文段的长度),即等于新的ssthresh+3* MSS。这样做的理由是:既然发送方收到了3个重复的确认,就表明有3个分组已经离开了网络。这三个分组不再消耗网络的资源而是停留在接收方的缓存中(接收方发送出3个重复的确认就证明了这个事实)。可见现在网络中并不是堆积了分组而是减少了3个分组。因此可以适当把拥塞窗口扩大些。 -
AIMD算法
在拥塞避免阶段,拥塞窗口时按照线性规律增大的,这常称为加法增大AI(Additive Increase)。而一旦出现超时或3个重复的确认,就要把门限值设置为当前拥塞窗口值的一半,并大大减小拥塞窗口的数值。这称为“乘法减小”MD(Multiplicative Decrease)。二者合在一起就是所谓的AIMD算法 -
流程图解
5.总结
-
TCP拥塞控制实际流程和上文理论的区别
1.我们刚开始就假定了接收方总是有足够大的缓存空间,因而发送窗口的大小由网络的拥塞程度来决定。 2.实际上接收方的缓存空间总是有限的。 3.接收方根据自己的接收能力设定了接收方窗口rwnd,并把这个窗口值写入TCP首部中的窗口字段,传送给发送方。 4.从接收方对发送方的流量控制的角度考虑,发送方的发送窗口一定不能超过对方给出的接收方窗口值rwnd。 5.把这里所讨论的拥塞控制和接收方对发送方的流量控制一起考虑,那么很显然,发送方的窗口的上限值应当取为 接收方窗口rwnd和拥塞窗口cwnd这两个变量中较小的一个。 6.发送方窗口的上限值 = Min[ rwnd, cwnd ] 7.当rwnd < cwnd 时,是接收方的接收能力限制发送方窗口的最大值。 8.反之,当cwnd < rwnd 时,则是网络的拥塞程度限制发送方窗口的最大值。 9.也就是说,rwnd和cwnd中数值较小的一个,控制了发送方发送数据的速率。 -
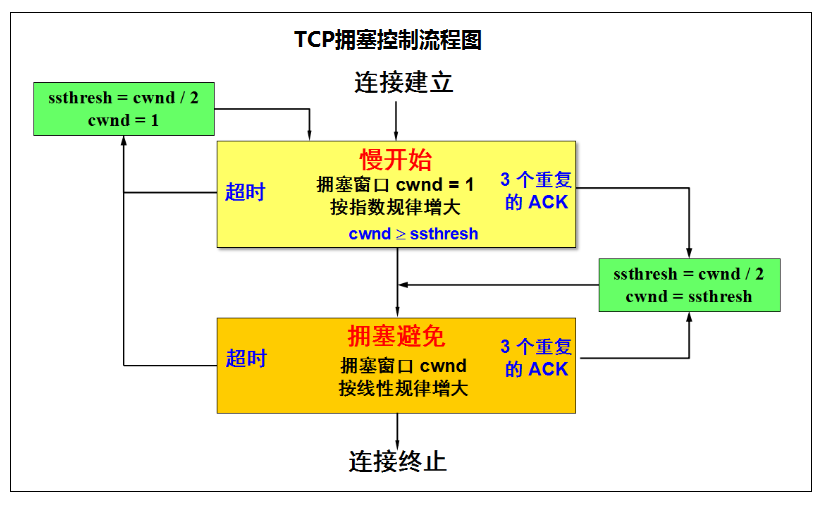
TCP拥塞控制流程图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号