scrapy框架爬虫的Spider类
Scrapy工作流程参考网址: https://docs.scrapy.org/en/latest/topics/architecture.html
快速入门: https://docs.scrapy.org/en/latest/intro/tutorial.html
为什么使用Scrapy框架:它是异步非阻塞的,可以理解为多线程的框架,因此爬虫速度快
Scrapy框架中分两类爬虫,Spider类和CrawlSpider类。
本章讲的是Spider类
下面我们主要介绍两种爬虫模板,第一种是通过命令行创建的模板,比较简单
第二种是在上面快速入门网址中复制来的
Scrapy框架是一个第三方包 需要 pip insatll Scrapy
注意:如果 pip insatll Scrapy 后出现下图错误

是因为缺少一个包,安装步骤如下:
在 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 这个官网上查找 twisted 显示如下图

python安装包是32位的则下载32位后缀的。如果pthon是64位的下载64位后缀的
下载结果如下:

再pip install Scrapy
安装好Scrapy 包后,我们开始按照快速入门的步骤来
第一步:创建项目 在桌面命令行 输入
scrapy startproject tutorial # 这里 tutorial 是要创建的项目名

这时,在桌面上就有了一个 名叫 tutorial 的文件夹。用pycharm打开该文件夹
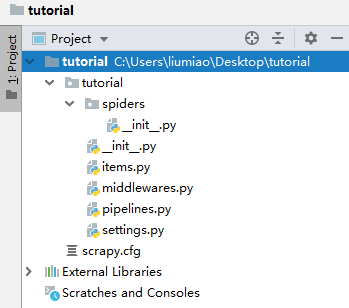
1)spiders 文件夹是放各种爬虫文件的
2) pipelines.py 作为管道是用来存储数据的,比如存储到 csv 或 mysql 数据库中
3)items.py 是选取哪些数据作为字段进行存取
我们按照命令行的步骤来,先cd 到项目的根目录下,准备进行爬虫文件的创建,这里我们通过scrapy genspider 的命令创建,注意我们要指定模板。
我们先来看看有哪些模板,使用scrapy genspider -l 查看有哪些模板 ,注意当不指定使用模板时,默认使用的是basic 这个模板
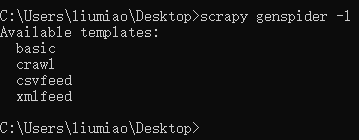
当想要使用某个模板时:(不指定模板时,去掉 -t crawl即可)
scrapy genspider QuotesCrawl (-t crawl) quotes.toscrape.com #QuotesCrawl代表的是爬虫的文件名,
quotes.toscrape.com 代表的是要爬虫网站的域名,比如boss直聘的域名为 zhipin.com
注意:一个项目中可以创建多个爬虫文件,不同爬虫文件可以爬取不同的网站,但每个爬虫文件的name值是唯一的。
开始进行爬虫之前,要对settings.py文件进行一些设置:
1) ROBOTSTXT_OBEY = True 这时robot君子协议,我们爬虫之前要注释掉此行
2) LOG_LEVEL = 'INFO' 设置日志等级(日志等级可修改为合适的)
3) 在项目的根目录下新建main.py文件,将下面两个粘贴到此文件中,之后我们就可以在bebug模式下运行,可以设置断点了
from scrapy import cmdline cmdline.execute("scrapy crawl boss.split()) # 红色为爬虫文件中爬虫的名字,每个爬虫文件的名字都是唯一的
我们还不能查看返回来的数据,因为还未解决反爬问题,下面是解决反爬的方法:
第一种方法和第二种方法的爬虫文件
import scrapy class GuaziSpider(scrapy.Spider): name = 'guazi' # 爬虫的名字 allowed_domains = ['guazi.com'] # 这个爬虫允许爬取的域 # start_url的编写形式 # 第一种编写形式 # start_urls = ['https://www.guazi.com/bj/buick/o1/#bread', # 'https://www.guazi.com/bj/buick/o2/#bread'] # 起始url地址 # 第二种编写形式 start_urls = [] for i in range(1,5): url = 'https://www.guazi.com/bj/buick/o{}/#bread'.format(i) start_urls.append(url) def parse(self, response): # 这个函数名是固定不变的 """ 回调函数 :param response: 发起网络请求后,相应回来的数据 :return: """ pass
第一种方法(添加加请求头UA):在settings中将USER_AGENT取消注释,并将要爬虫的网站的USER_AGENT写到这里。

当只加请求头解决不了时
第二种方法:在settings.py文件中将COOKIES_ENABLED = False这一行和DEFAULT_REQUEST_HEADERS取消注释,在此花括号中写USER_AGENT和cookie值
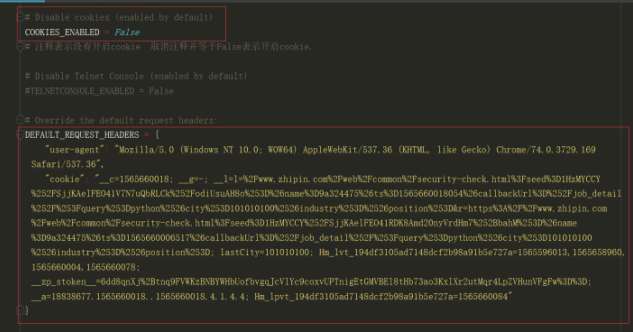
这个方法是有缺点的,在该项目中只使用了一种cookie,因此只能对一个网站实现爬虫,当其他网站也需要设置cookie才能爬时,需要修改这里的cookie
第三种方法(在scrapy框架中解决反爬):这时我们就不能用 命令行 创建爬虫文件的方法,而是根据下面的地址
https://docs.scrapy.org/en/latest/intro/tutorial.html
在项目中直接新建一个py爬虫文件,将网址中的代码粘贴到py文件中
import scrapy class QuotesSpider(scrapy.Spider): name = "gua" def start_requests(self): # 只有这个函数名是固定的 urls = [ 'https://www.guazi.com/bj/buick/o1/#bread', 'https://www.guazi.com/bj/buick/o2/#bread', ] for url in urls:
# 下面是对url发起访问请求 yield scrapy.Request(url=url, callback=self.parse) # 光标红字处+ctrl 查看底层 def parse(self, response): # 这个函数名是根据上面绿字处确定的 print("end")
查看底层结果
注意:上图中dont_filter=False 的作用就是去重,可以理解为调度器处的去重,当改为True时,将不在有去重功能
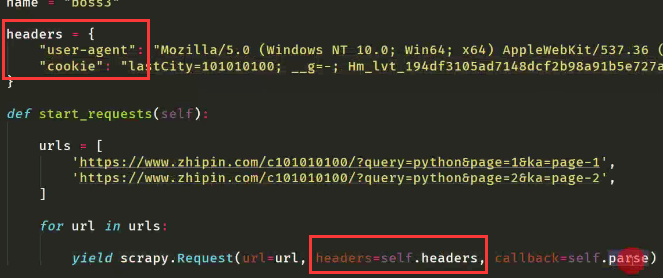
注意上述方法settings文件中COOKIES_ENABLED = False要取消注释
第四种方法:我们发现之前查看Request底层文件时,有一个单独的cookie参数,我们将cookie从第三种方法headers中单独提取出来,在它的下方写cookie={} ,这时我们可以在浏览器的Application中的cookie中复制name和value值,然而这样写比较麻烦。这时我们要将COOKIES_ENABLED = False注释掉。
总结:我们可以总结如果你的cookie是放在请求头中时(不管是第二种方法的在settings中DEFAULT_REQUEST_HEADERS中cookie还是第二种方法的在爬虫文件中的请求头)都需要将settings文件中的COOKIES_ENABLED = False取消注释。
当cookie没有放在请求头中而是单独写了一个cookie参数,那settings文件中的COOKIES_ENABLED = False要注释掉。
将setttings中的这些取消注释,并将值都写小一点(以下的值都是默认值)
# Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 32 # 将由Scrapy下载程序执行的并发(即同时)请求的最大数量 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # 下载延迟,每发起一次网络请求后延迟3秒 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 对单个域执行的并发(即同时)请求的最大数量 CONCURRENT_REQUESTS_PER_IP = 16 # 同一个时间点,一个ip发送16次请求
好了该配置的都已经配置好了,我们现在开始提取数据。
在scrapy框架中回调函数的response可以直接调用xpath,不用etree

注意:要再加上.extract() 才能获取要抓取的数据,结果是一个列表数据,因此再在.extract()后面补充比如 [0]
这是我们要对上面抓去的job_href发起网络请求,照搬之前发起的请求,但url参数和callback参数要改,例下图:
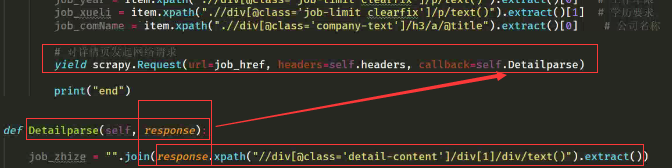
好了现在我们已经获取到数据,现在要保存数据
items.py文件就是定义将提取的数据存储到哪些字段上,这样才能传输给管道进行入库操作。
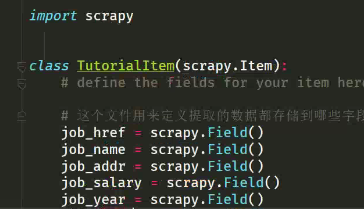
这就定义好了。这个类名可以自己改。
当此项目中存在其他爬虫文件时,在这里复制上图的类,改类名,改要保存的字段名
定义好之后,我们在爬虫文件中以导包的形式导入这个类。
from tutorial.items import TutorialItem
然后我们通过这个类创建对象,创建多少个对象?一条数据创建一个实例对象。因此要将创建对象的过程写到提取数据的for循环中
给实例对象的属性进行赋值,在Scrapy框架中实例对象的属性的赋值是通过字典的形式
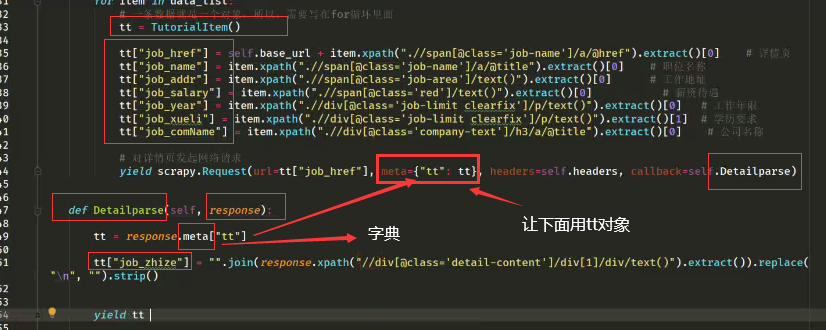
上面 yield tt 就是将数据传输给管道 >> pipelines.py 文件
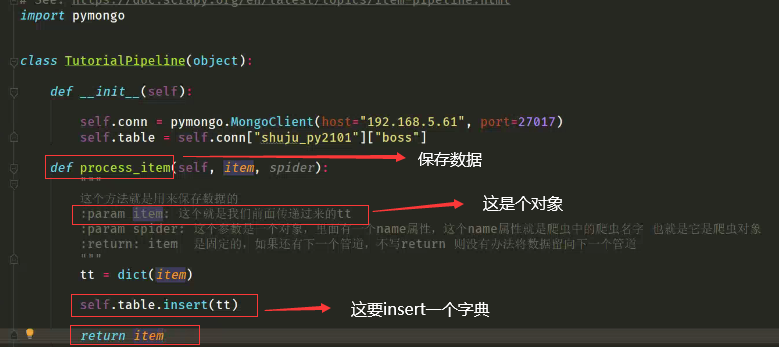
在管道文件中保存数据
当存在其他爬虫文件需要保存数据时,
我们直接复制下面的类,改类名,改保存到mongodb中表名(下图的["boss"]),在settings文件中添加这个管道
你会发现这样弄有点麻烦。我们可以根据spider的name属性来判断走的哪个爬虫文件 具体步骤在后面写
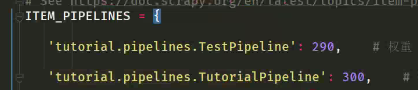
现在我们要在settings中开启管道(按照下面的写法在花括号中写即可)
ITEM_PIPELINES = { 红色字体为在管道文件中的类名 'tutorial.pipelines.TutorialPipeline': 300, # 这个300是权重,具体下面详细说 } 当此处有多个管道时,不能都开,都开时
run 运行main文件。
步骤流程总结:
1)先在spiders下新建一个py文件,将网址上的代码复制到该py为文件中。在name下面写请求头headers
2) 发送请求
3)xpath提取数据
4)把数据放到在爬虫文件中创建的对象中(该对象从items.py文件中创建的类生成的)
5)在最后yield返回给管道,在管道中做真正的保存,而管道要想起作用要在settings文件中开启。
6)在main.py文件中run这个爬虫文件。
下图为Scrapy流程框架(五大核心组件)
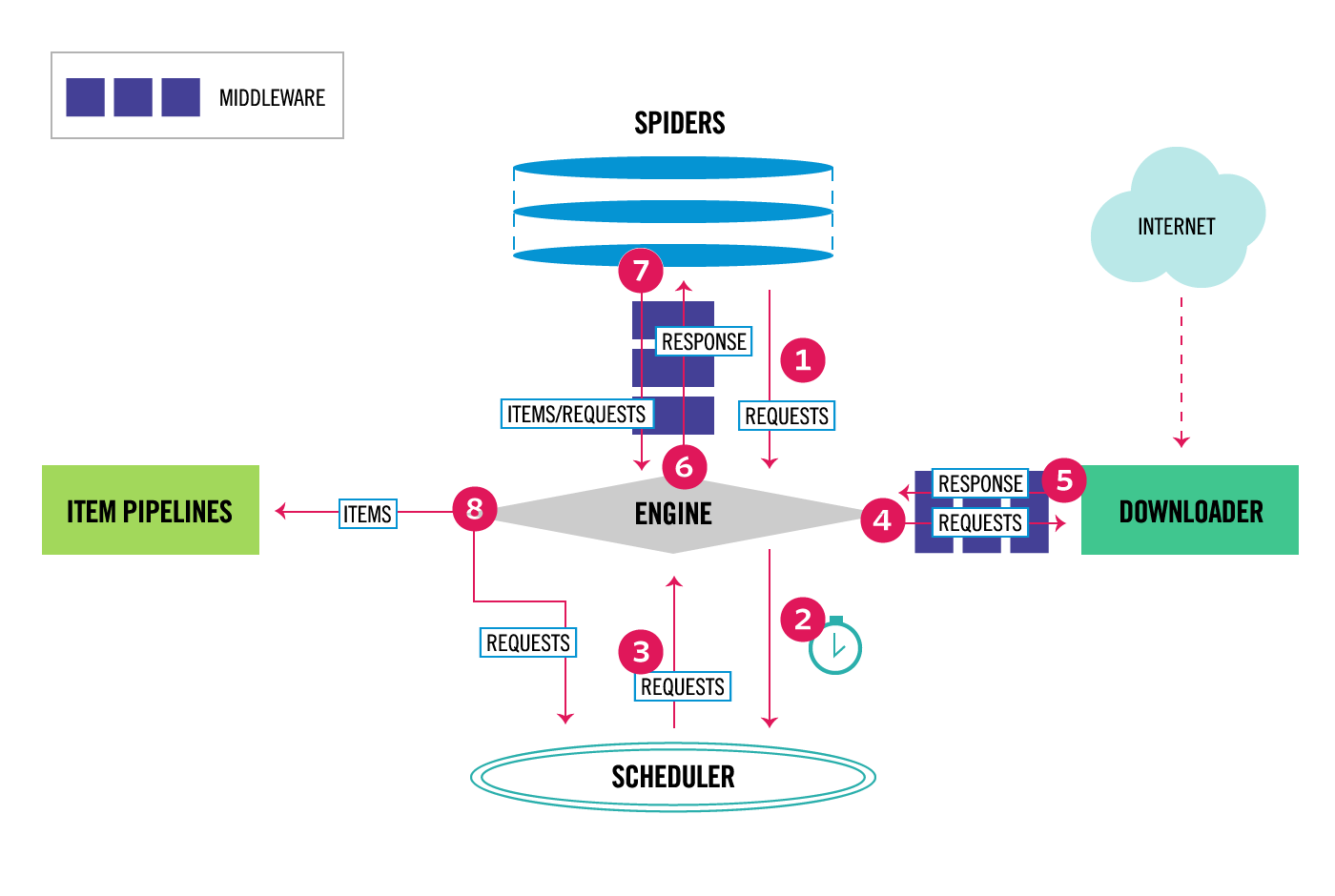
1)spider将请求对象给了引擎。
2) 引擎将请求对象转发给了调度器。(调度器的作用就是对请求对象去重,将去重后的请求对象放到队列中,调度器再将请求对象逐一发给引擎)
3)好了,这里的第三步就是经过调度器后发给引擎的单个请求对象
4)引擎将请求对象发送给下载器DOWNLOADER,同过下载中间件下载网络数据。(下载器拿到请求对象开始对网站发起请求)
5)如图你会发现第4步发送过去的是requests,第5步的传送出来的是response,下载器接收到网站返回的response发送给引擎
6)引擎再将response发送给爬虫spider做页面数据提取xpath工作。
7)spider将xpath解析后的数据发送给引擎
8)引擎再将数据发送给管道,在管道进行真正的储存(这里还涉及的items[ 确定储存到哪个字段上 ]是为储存到管道做准备)
然后再从调度器发送请求对象,开始循环
当存在多个爬虫文件时,可以在管道文件处做下面的优化
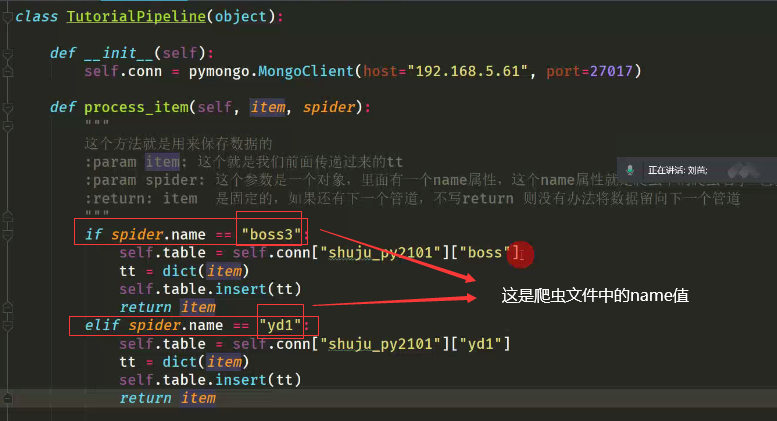
我们也可以根据管道文件中的参数 item 就是爬虫文件中的 创建的根据items文件中类的实例对象
先导入items文件的类
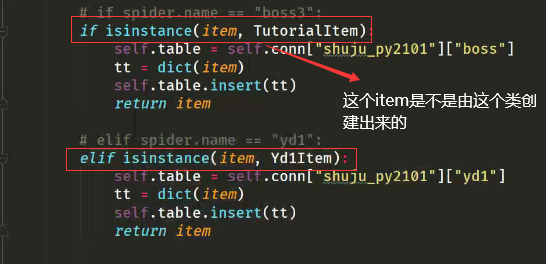
这时,我们在settings处就不用再开启新的管道了。
我们无法在items文件处做优化,因为每个爬出文件提取的数据不一样。
settings中开启管道时权重值大小的作用:下图所示(添加了一个给实例对象添加动态属性的类)
注意我们需要将TestPipline中定义的两个值,放到items文件中,注意要放到执行的items类中,比如上面走的是YdqItem类,则在items的这个类中定义字段名,而不是新建一个TestPipline类
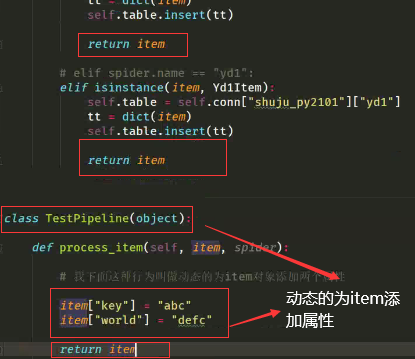
注意必须加return 才能流入到下一个管道
在settings文件中(先跑权重小的,再跑权重大的)验证一下
结果为:上图应先添加俩属性,再保存的数据库中,因此数据库中存在这两个属性
当反过来时,先将爬虫文件的数据保存的数据库中,再给对象添加属性,因此数据库中将不存在这两个属性
用途:额外的添加东西

 浙公网安备 33010602011771号
浙公网安备 33010602011771号