Flask- 数据库数据下载成excel
例子:
from flask import Flask, render_template from io import BytesIO import xlsxwriter def create_workbook(): output = BytesIO() # 创建Excel文件,不保存,直接输出 workbook = xlsxwriter.Workbook(output, {'in_memory': True}) # 设置Sheet的名字为download worksheet = workbook.add_worksheet('download') # 列首 title = ["col1","col2","col3"] worksheet.write_row('A1', title) dictList = [{"a":"a1","b":"b1","c":"c1"},{"a":"a2","b":"b2","c":"c2"},{"a":"a3","b":"b3","c":"c3"}] for i in range(len(dictList)): row = [dictList[i]["a"],dictList[i]["b"],dictList[i]["c"]] worksheet.write_row('A' + str(i + 2), row) workbook.close() response = make_response(output.getvalue()) output.close() return response app = Flask(__name__) @app.route('/', methods=['GET']) def index(): return render_template("index.html") from flask import make_response @app.route('/download', methods=['GET']) def download(): response = create_workbook() response.headers['Content-Type'] = "utf-8" response.headers["Cache-Control"] = "no-cache" response.headers["Content-Disposition"] = "attachment; filename=download.xlsx" return response if __name__ == "__main__": app.run(host='127.0.0.1', port=88, debug=True)
运行在浏览器访问 127.0.0.1:88 可以看到新建的页面,在页面访问 127.0.0.1/download 可以下载生成的 excel :
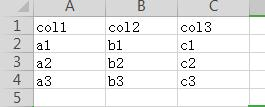
实践中:根据自己项目走的
class StoreGoodsResource(ma.Schema): class Meta: model = goods
分页page:
def paginate(query, page, page_size): if page <= 0: raise AttributeError('page needs to be >= 1') if page_size <= 0: raise AttributeError('page_size needs to be >= 1') items = query.limit(page_size).offset((page - 1) * page_size).all() # We remove the ordering of the query since it doesn't matter for getting a count and # might have performance implications as discussed on this Flask-SqlAlchemy issue # https://github.com/mitsuhiko/flask-sqlalchemy/issues/100 total = query.order_by(None).count() return Page(items, page, page_size, total)
生成下载excel接口代码
from io import BytesIO
def get(self):
#get接口,要求在url上面带着参数,以便分页,
#此目的是经过分页后的数据进行下载
args = request.args page = args.get('page') size = args.get('size') query = goods.query page_result = paginate(query, int(page), int(size)) new_food_material_schemas = StoreGoodsResource( many=True, only=( 'id', 'name', 'goodscode', 'goods_number', 'create_time', 'update_time', 'description', 'firm_id', 'series_id', 'sale_unit', 'min_order_quantity', 'min_order_step', 'goods_category_id', 'store_goods_category_id')) result = new_food_material_schemas.dump(page_result.items) output = BytesIO() # 创建Excel文件,不保存,直接输出 workbook = xlsxwriter.Workbook(output, {'in_memory': True}) # 设置Sheet的名字为download worksheet = workbook.add_worksheet('Download') # 列首 title = ["名称", "商品编码", "创建时间", "修改时间", "商品描述", "生产厂商", "系列", "销售单位", "最小起订数量", "最小起订步长", "包装清单", "商品分类"] worksheet.write_row('A1', title) result_list = result.data for i in range(len(result.data)):
#数据库是时间戳,下面是转换时间戳转换成时间格式
time = pendulum.from_timestamp(result_list[i]["create_time"], tz='Asia/Shanghai') create_time = time.to_date_string() result_list[i]["create_time"] =create_time
#写入数据 row = [result_list[i]["name"], result_list[i]["goods_number"],result_list[i]["create_time"],result_list[i]["update_time"],result_list[i]["description"],result_list[i]["firm_id"], result_list[i]["series_id"],result_list[i]["sale_unit"],result_list[i]["min_order_quantity"],result_list[i]["min_order_step"],result_list[i]["goods_category_id"],result_list[i]["store_goods_category_id"]] worksheet.write_row('A' + str(i + 2), row) workbook.close() response = make_response(output.getvalue()) output.close() #下面是下载 response = response response.headers['Content-Type'] = "utf-8" response.headers["Cache-Control"] = "no-cache" response.headers["Content-Disposition"] = "attachment; filename=GoodsList.xlsx" return response

 浙公网安备 33010602011771号
浙公网安备 33010602011771号