
node爬虫使用cheerio爬取网站图片简单实现
一.前言
爬虫爬取网站img图片的基本流程:
发送请求->获取网页->解析页面->获取图片->存储图片(爬去其他资源也是类似的)
cheerio没办法爬取背景图片,因为css并不会解析.
网上有很多网页爬取图片的工具哦
二.实现
cheerio模块和jquery一样,用于操作dom.可以把抓去的页面解析成可操作的dom格式
request模块,用于数据请求
fs模块,用于图片下载(内置模块,无需下载)
bagpipe模块,用于nodejs中控制并发执行
npm i cheerio -S npm i request -S npm i bagpipe -S
2.1发送请求
我在做这里的时候,爬取的网站html页面如下,这种页面是没办法获得我们想要的数据的,解决方法就是手动拷贝代码到本地,用服务器开启爬去
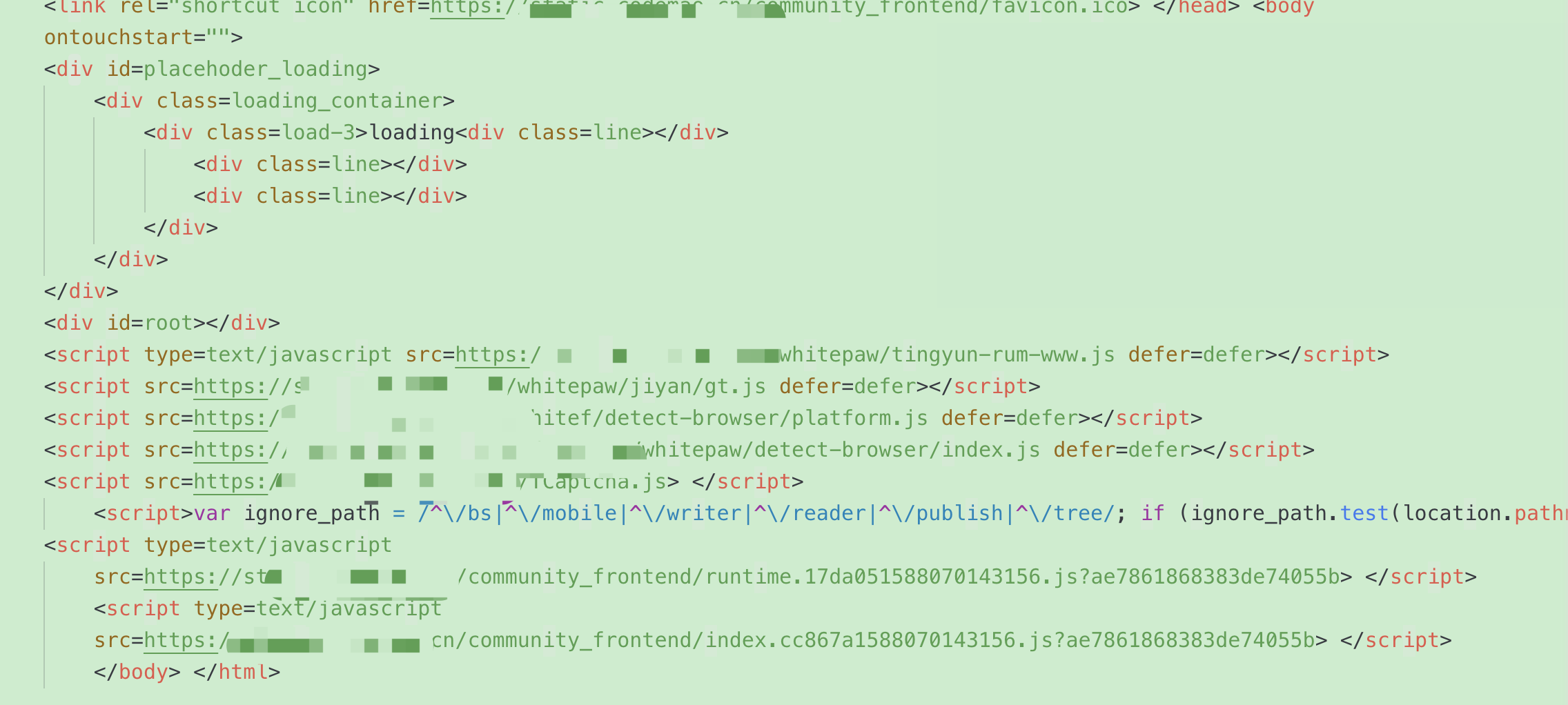
手动获取页面代码,拷贝在了index.html上,通过启动本地服务器(live server),以服务的形式启动index.html页面.然后在nodejs中请求地址设置为本地页面
选择edit 然后复制html内容
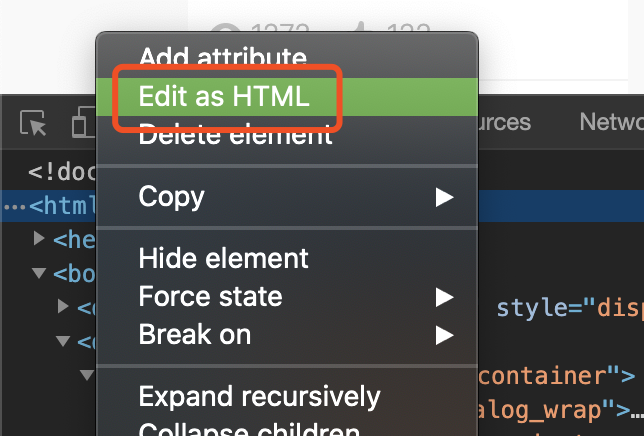
nodejs中请求页面
const request=require('request');
//http://127.0.0.1:5500是我要爬取的网址
request('http://127.0.0.1:5500',function(err,res,data){
if(!err && res.statusCode === 200){
console.log(data)//data就是我们整个html文档代码
}
});
2.2解析页面
nodejs中处理请求的页面,把获取的html文档代码,转化为可操作的节点;然后
const cheerio=require('cheerio');
const fs=require('fs')
const Bagpipe=require('bagpipe');
const request=require('request');
request('http://127.0.0.1:5500',function(err,res,data){
if(!err && res.statusCode === 200){
//把获取的html文档代码,转化为可操作的节点
const $=cheerio.load(data);
}); } });
2.3获取图片
使用cheerio按照jquery api一样操作取获取img地址
const cheerio=require('cheerio');
const fs=require('fs')
const Bagpipe=require('bagpipe');
const request=require('request');
request('http://127.0.0.1:5500',function(err,res,data){
if(!err && res.statusCode === 200){
//把获取的html文档代码,转化为可操作的节点
const $=cheerio.load(data);
let imgSrc=[];
$('img').each(function(index,item){
//获取img页面的src属性值
imgSrc.push($(item).attr('src'))
console.log($(item).attr('src'))
}); } });
运行node 文件名,查看imgSrc内容

2.4下载图片
使用bagpipe去批量下载图片,使用bagpipe的目的是防止图片量过大时出现问题
const cheerio=require('cheerio');
const fs=require('fs')
const Bagpipe=require('bagpipe');
const request=require('request');
//下载图片
function downloadImg(src,name,callback){
request(src).pipe(fs.createWriteStream(name)).on('close',function(){
callback()
})
}
request('http://127.0.0.1:5500',function(err,res,data){
if(!err && res.statusCode === 200){
const $=cheerio.load(data);
let imgSrc=[];
$('img').each(function(index,item){
imgSrc.push($(item).attr('src'))
});
let len=imgSrc.length;
//批量下载
const bagpipe=new Bagpipe(len); for(let i=0;i<len;i++){
let filename=imgSrc[i].slice(imgSrc[i].lastIndexOf('/')+1);
bagpipe.push(downloadImg,imgSrc[i],'./public/'+filename,function(err,data){
if(err){
console.log(err);
}
})
}
}
});
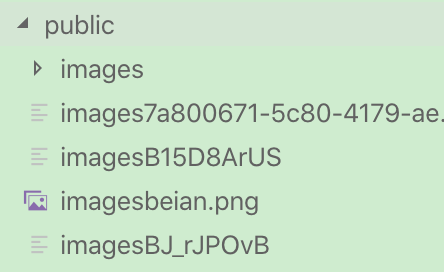
三.执行结果
如下在public文件夹下的图片就是我们爬取网站的图片
开源中国博客地址:https://my.oschina.net/u/2998098/blog/1540520

 浙公网安备 33010602011771号
浙公网安备 33010602011771号