机器学习-无监督学习
1 无监督学习
有标签的是监督学习,无标签的是非监督,当然还有中半监督
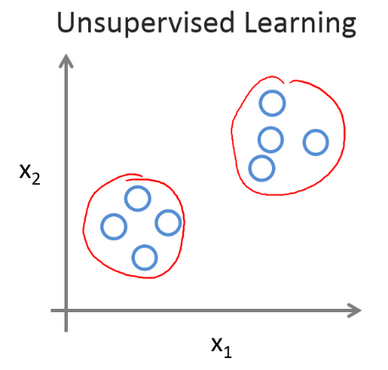
无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法
无监督学习会自动将数据分类
给它一堆水果 它可以分类出哪些是香蕉哪些是苹果榴莲 自动分类
2 应用
其中就有基因学的理解应用。一个DNA微观数据的例子。基本思想是输入一组不同个体,对其中的每个个体,你要分析出它们是否有一个特定的基因。技术上,你要分析多少特定基因已经表达。所以这些颜色,红,绿,灰等等颜色,这些颜色展示了相应的程度,即不同的个体是否有着一个特定的基因。你能做的就是运行一个聚类算法,把个体聚类到不同的类或不同类型的组(人)……
所以这个就是无监督学习,因为我们没有提前告知算法一些信息,比如,这是第一类的人,那些是第二类的人,还有第三类,等等。我们只是说,是的,这是有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型。我甚至不知道人们有哪些不同的类型,这些类型又是什么。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些。因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习
无监督学习或聚集有着大量的应用。它用于组织大型计算机集群。我有些朋友在大数据中心工作,那里有大型的计算机集群,他们想解决什么样的机器易于协同地工作,如果你能够让那些机器协同工作,你就能让你的数据中心工作得更高效。第二种应用就是社交网络的分析。所以已知你朋友的信息,比如你经常发email的,或是你Facebook的朋友、谷歌+圈子的朋友,我们能否自动地给出朋友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人?还有市场分割。许多公司有大型的数据库,存储消费者信息。所以,你能检索这些顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中,你才能自动并更有效地销售或不同的细分市场一起进行销售。这也是无监督学习,因为我们拥有所有的顾客数据,但我们没有提前知道是什么的细分市场,以及分别有哪些我们数据集中的顾客。我们不知道谁是在一号细分市场,谁在二号市场,等等。那我们就必须让算法从数据中发现这一切。最后,无监督学习也可用于天文数据分析,这些聚类算法给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。这些都是聚类的例子,聚类只是无监督学习中的一种
我现在告诉你们另一种。我先来介绍鸡尾酒宴问题。嗯,你参加过鸡尾酒宴吧?你可以想像下,有个宴会房间里满是人,全部坐着,都在聊天,这么多人同时在聊天,声音彼此重叠,因为每个人都在说话,同一时间都在说话,你几乎听不到你面前那人的声音。所以,可能在一个这样的鸡尾酒宴中的两个人,他俩同时都在说话,假设现在是在个有些小的鸡尾酒宴中。我们放两个麦克风在房间中,因为这些麦克风在两个地方,离说话人的距离不同每个麦克风记录下不同的声音,虽然是同样的两个说话人。听起来像是两份录音被叠加到一起,或是被归结到一起,产生了我们现在的这些录音。另外,这个算法还会区分出两个音频资源,这两个可以合成或合并成之前的录音,实际上,鸡尾酒算法的第一个输出结果是:
1,2,3,4,5,6,7,8,9,10,
所以,已经把英语的声音从录音中分离出来了。
第二个输出是这样:
1,2,3,4,5,6,7,8,9,10。
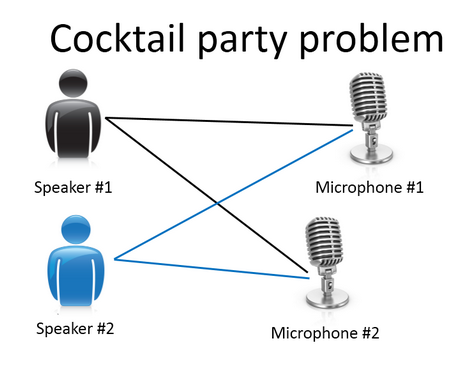
看看这个无监督学习算法,实现这个得要多么的复杂,是吧?它似乎是这样,为了构建这个应用,完成这个音频处理似乎需要你去写大量的代码或链接到一堆的合成器JAVA库,处理音频的库,看上去绝对是个复杂的程序,去完成这个从音频中分离出音频。事实上,这个算法对应你刚才知道的那个问题的算法可以就用一行代码来完成。
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
作者:8亩田
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.
本文如对您有帮助,还请多帮 【推荐】 下此文。
如果喜欢我的文章,请关注我的公众号
如果有疑问,请下面留言

 浙公网安备 33010602011771号
浙公网安备 33010602011771号