


力扣180(MySQL)-连续出现的数字(中等)
题目:
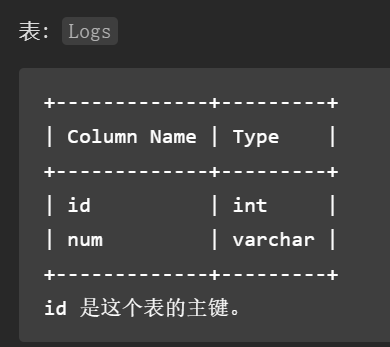
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
返回的结果表中的数据可以按 任意顺序 排列。
查询结果格式如下面的例子所示:
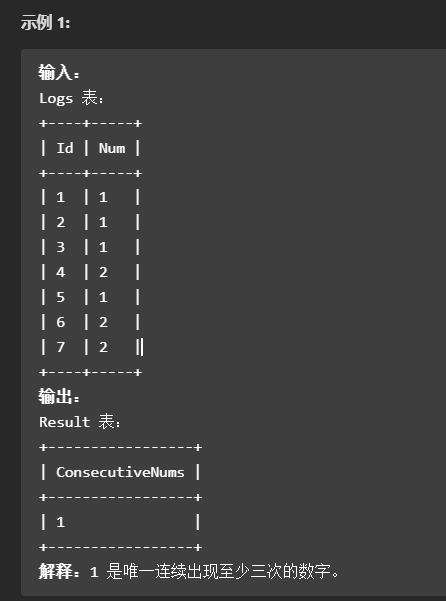
解题思路:
原表数据:

方法一:
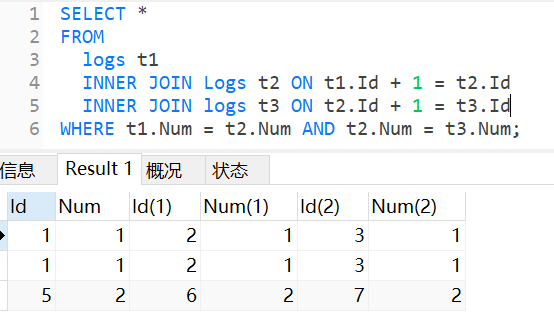
使用内连接(inner join)来解决,将三个表进行连接,在连接时,只有存在于连接标准相匹配的数据才会被保留下来。通过id+1的方式查找下一次出现的数字,通过id+2的方式查找下下次出现的数字,如果下次和下下次出现的数字相同,就满足条件。
①将下次和下下次出现的数字,放在同一个表中。
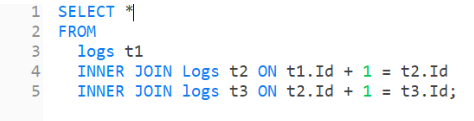
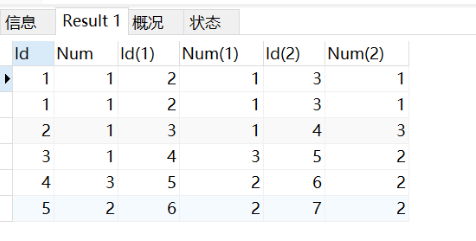
②加上筛选条件,三个表中的数字相等
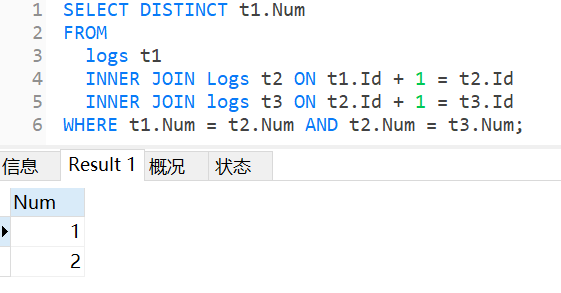
③修改Select后面输出的字段,只用输出Num。
方法二:
参考猴子老师的题解:(点一下跳转)
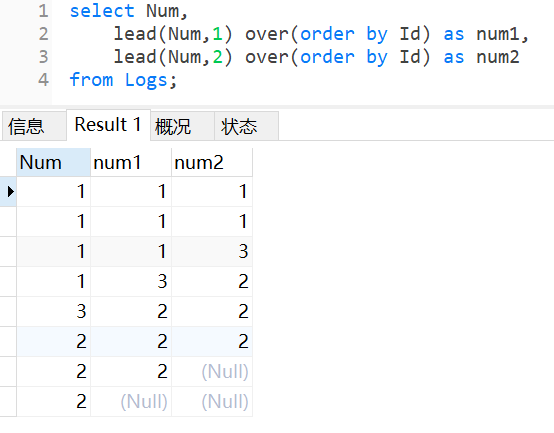
①先使用窗口函数lead()查找当id按升序排列时的num值。
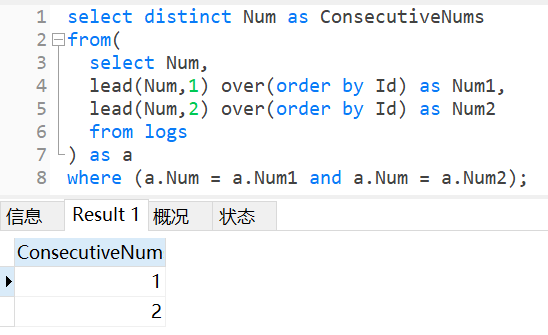
②再使用where查找出三个值都相同的行
小知识:
①窗口函数lead()和lag():
向上窗口函数lead:取出字段名所在的列,向上N行的数据,作为独立的列
lead(字段名,N,默认值) over(partion by …order by …)
向下窗口函数lag:取出字段名所在的列,向下N行的数据,作为独立的列
lag(字段名,N,默认值) over(partion by …order by …)
默认值是指,当向上N行或者向下N行值时,如果已经超出了表行和列的范围时,会将这个默认值作为函数的返回值,若没有指定默认值,则返回Null。

②(本题没有用)count(1) 和 count(*) 在 SQL 中都可用来计算表中的行数。但是它们有一些细微的差别:
count(1)是统计非 NULL 值的行数。count(*)是统计所有行的行数, 包括 NULL 值。
在大多数情况下,count(1) 和 count(*) 的结果是一样的。但是如果表中有很多 NULL 值,那么两个函数的结果就会不同。 建议使用 count(1) 更加贴近需求且效率较高,而 count(*) 更加保险。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号