
Redis进阶
管道(Pipelining)
- 可以将多次请求一次性发送到服务器。比如超市可以免费喝啤酒,但是必须得回家喝。正常情况的命令就相当于,拿回家一瓶喝完再去超市拿一瓶。管道类似于找了个箱子一次性拿回去很多瓶。和buffer缓存区一样,都是为了减少调用次数,降低通信成本。
- 命令行使用:echo -e "set key value\nincre key" | nc localhost 6379。
- 可以做热加载redis,批量导入数据。
发布订阅
- help @pubsub查看发布订阅命令
- publish channel message:在channel中发布一个message,消费端只能接收到开始监听以后推送的消息。
- subscribe channel:监听一个channel。
使用redis构建实时消息系统
- 读数据
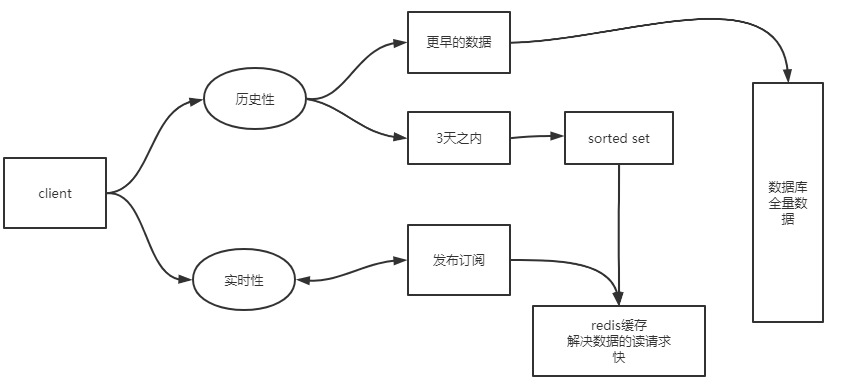
- 历史性:历史消息记录,可分为三天之内以及更早的数据
- 三天之内的数据:zset(sorted set),把时间作为记录的分值,消息作为存的元素。
- 更早的数据可以保存在数据库。
- 实时性:当前发送的消息
- 可以使用redis的发布订阅功能。
- 历史性:历史消息记录,可分为三天之内以及更早的数据
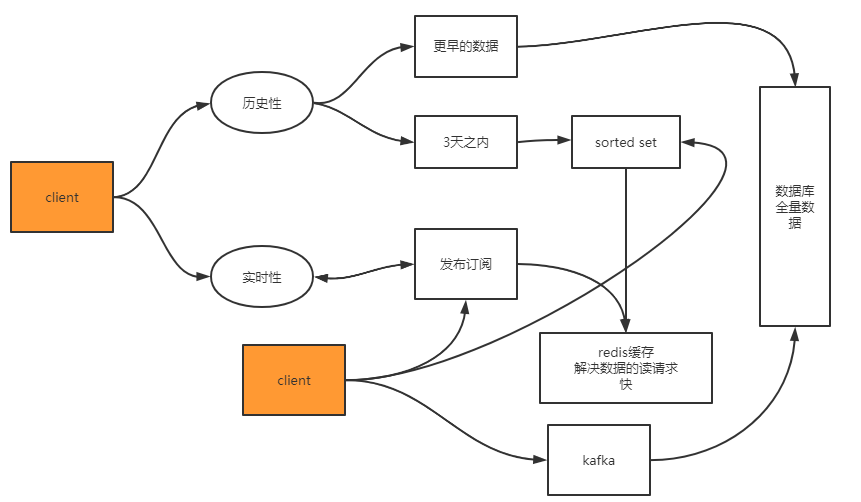
- 写数据
- 客户端推送消息到消息订阅,使用命令将消息发送到zset中,通过kafka将数据保存到数据库。
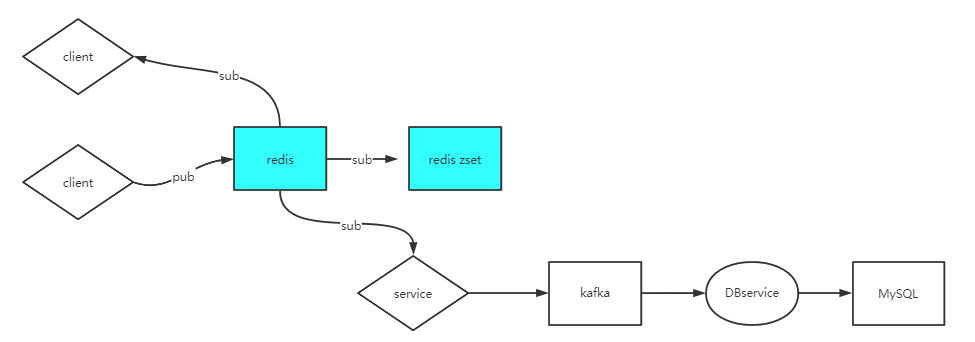
-
- 客户端推送消息到一个redis进程,另一个客户端订阅接收该消息(实时窗口),另一个redis进程订阅接收该消息放到zset中,一个微服务接收该消息通过kafka将该消息放到数据库中。
事务
- redis事务没有回滚操作。
- redis命令只会因为错误语法失败,或者命令用在了错误类型的键上面。也就是说,失败的命令是由编程错误造成的,这些错误应该在开发过程中被发现,不应该出现在生产环境中。
- 因为不需要支持回滚,redis内部可以保持简单且快速。
- 有种观点任务redis处理事务的做法会产生bug,但是需要注意的是,在通常情况下,回滚并不能解决变成错误带来的问题。
- 多个客户端对一个redis进程启动事务时,哪个客户端首先发出了exec命令,先执行哪个客户端的所有命令。
- help @transactions查看所有命令
- multi:开启事务,multi命令之后,exec命令之前的命令都存放在了缓冲队列中。
- exec:执行开启事务后所有的命令。
- watch key [key ...]:监控某个key,如果key的值发生改变,后续命令全部不执行。可以实现乐观锁(CAS)。
module&布隆过滤器
- module是Redis的一种动态库,可以用与Redis内核相似的运行速度和特性来扩展Redis内核的功能。
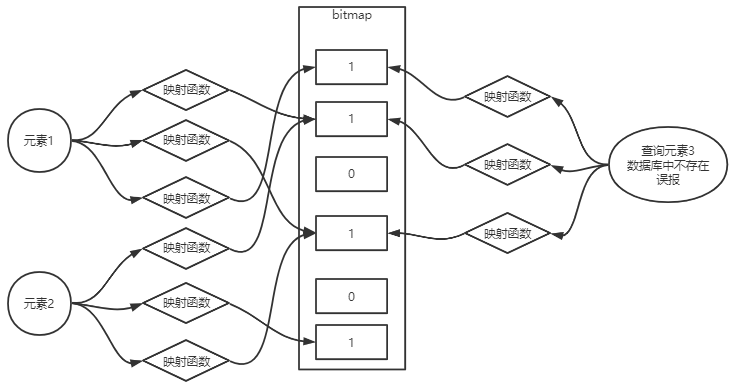
- 布隆过滤器:避免缓存穿透。
- 缓存穿透是指一直查询一些数据库中不存的数据,这时缓存中查询不到会直接去数据库中查找,这时数据库会做很多无用功。
- 布隆过滤器是通过n个散列函数将数据库中存在的值散列到一个很大的bit数组上(bitmap),如果一个值经过散列之后匹配的位有一个值是0,那么这个值在数据库中一定不存在。反之有几率存在。
- 概率解决问题,不是完全避免到数据库查询不存在的数据。
- 如果数据穿透到数据库但是实际不存在,服务器可以将该key放到缓存中,value为null或者提示。
- 数据库如果增加了元素,需要在过滤器中添加该元素。
- Redis承载bitmap以及布隆过滤器module(支持删除---cf命令)的好处在于使得客户端更加的轻量,可以专注于业务的处理。
- 安装过程
- 访问redis.io
- modules
- 访问RedisBloom的GitHub:https://github.com/RedisBloom/RedisBloom
- Linux中wget *.zip
- yum install unzip
- unzip *.zip
- make
- cp bloom.so /opt/liu-feng/redis5/
- redis-server --loadmodule /opt/liu-feng/redis5/redisbloom.so
- redis -cli
- 1.bf.add xxx abc, 2.bf.exits abc, 3.bf.exits adsf
Redis--缓存
- 缓存不是全量数据,应该随着访问变化。加缓存的目的是减轻后台的访问压力,所以应该将要请求的数据放到缓存,即热数据。
- Redis里的数据怎么能随着业务变化,只保留热数据?(内存大小有限,这是Redis的瓶颈)
- vi /etc/redis/6379.conf:查看redis基本信息,可看到内存大小(最好是1G-10G)。
-
key的有效期
- 由业务逻辑决定。
- set key value EX seconds:该key在seconds秒后过期。
- ttl key:查看key的过期时间,没有过期时间的key会返回-1,过期的key会返回-2。
- Expire key seconds:设置key的过期时间。
- 还可设置定时过期。
- 时间有效期不会随着访问时间延长。
- 对设置了过期时间的key重新赋值(set),会修改有效期(如果不加有效期,则一直有效,如果加了即为最新设置的时间)。
-
淘汰冷数据
-
随着业务运转,内存是有限的,随着访问的变化,应该淘汰掉冷数据(内存慢了之后)。
- 淘汰策略配置项:maxmemory-policy + 策略。
- noeviction; allkeys-lru; allkeys-lfu; volatile-lru; volatile-lfu; allkeys-random; volatile-random; volatile-ttl。
- noeviction:调用某些指令时返回错误,不淘汰key。Redis作为数据库时可用,作缓存不使用。
- allkeys:所有key中。
- volatile:过期集合的key。
- LRU:淘汰最长时间没有使用的key(时间)。
- LFU:淘汰最少使用次数的key(次数)。
- volatile-ttl:优先回收存活时间短的key,即将要过期的key,成本较高。
-
-
Redis如何淘汰过期的keys
- 被动方式:当访问keys时,过期的key会被发现并主动的过期。
- 主动方式:有的key不会再被访问,所以定时随机测试keys的过期时间,每秒10次(如果全量测试会影响性能)。
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步骤1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号