
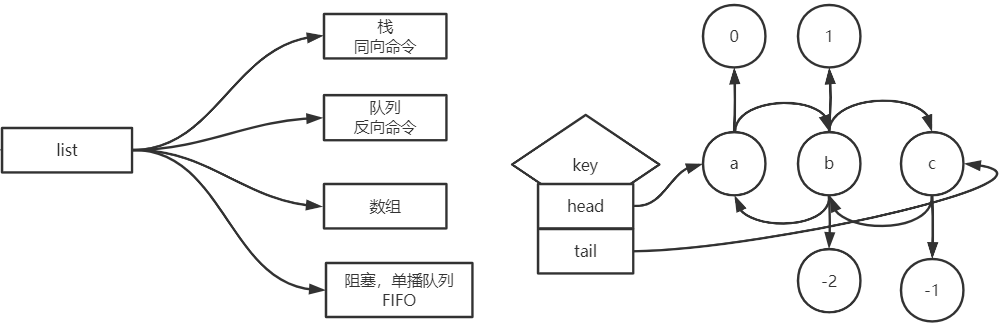
list
![]()
- 双向链表,key中有head和tail指向list的第一个以及最后一个元素。
- 可重复的,有序的,插入的顺序。
- 对list的操作
- 使用help @list查看所有操作
- 在对list的操作中,以L开头的操作,部分代表list的左边,以R开头的操作代表list的右边。维护了正负索引
- lpush key value [value]:从list的左边添加元素。(后push的在左边)
- rpush key value [value]:从list的右边添加元素。(后push的在右边)
- lpop key:从list的左边弹出元素。
- rpop key:从list的右边弹出元素。
- lrange key start stop:取value从start到stop的元素。
- lindex key index:取出value位于index的元素。
- lset key index value:将index处设为value。
- lpush + lpop / rpush + rpop(同向命令):先进后出,模拟栈
- lpush + rpop / rpush + lpop(反向命令):先进先出,模拟队列
- list对index进行操作模拟数组 。
- linset key before|after pivot value:在链表中的pivot元素前|后插入值为value的元素(左起第一个pivot元素)。
- lrem key count value:移除值为value的count个元素(list不去重),count分为正数,负数,0。
- 正数:从左移除count个value。
- 负数:从右移除count个value。
- 0:不移除
- blpop key [key...] timeout(b开头为阻塞命令):阻塞的弹出list中的左起第一个元素,timeout为阻塞时间,0是一直阻塞。
- 阻塞的单播队列:list中的元素会先被第一个阻塞调用的进程取。
- ltrim key start stop:保留start到stop之间的元素(start以及stop位置的元素也被保留),两端的被删除。
hash
![]()
- 类似于hashmap。
- 应用于点赞、评论、收藏数以及商品详情等。
- 对hash的操作
- help @hash查看所有操作
- hset key field value:在value里面放了一个键值对。
- hmset key field value [field value]:在value放多个键值对。
- hget key field:取出value里面field对应的值。
- hmget key field [field...]:取出多个。
- hkeys key:取出value里面所有的key(键值对中的)。
- hvalues key:取出key对应值里面所有的value。
- hgetall key:取出所有的键值对。
- hincrbyfloat key field increment:对field对应的值增加increment(对数值的操作)。
- hincrby key field increment:对field对应的值增加increment(整型)。
set
![]()
- 去重,无序
- 对set的操作
- help @set
- sadd key member [member...]:添加元素。
- smembers key:取出所有的值(很少使用,数据量大的情况下会消耗redis在主机的吞吐量)。
- srem key member [member...]:移除元素。
- sinter key [key...]:得出key之间的交集并返回。
- sinterstore destination key [key...]:将交集赋值到destination(这个命令的出现是为了将交集存放到redis中的情况,省去了客户端拿到交集再回写到redis的过程)。
- sunion key [key...]:得出key之间的并集并返回(也有sunionstore命令)。
- sdiff key [key...]:得出key的差集(也有sdiffstore命令)。
- k1: 1 2 3 4 5;k2: 4 5 6 7 8
- sdiff k1 k2:1 2 3
- sdiff k2 k1:6 7 8
- srandmember key [count]:取出count个数据。
- 正数(小于元素个数):在已有集合中返回count个去重的结果。
- 正数(大于元素个数):返回所有数据。
- 负数:取出一个有重复数据的结果集,一定会满足需要的数量。
- 0:不返回。
- spop key:随机弹出一个值并返回该值。
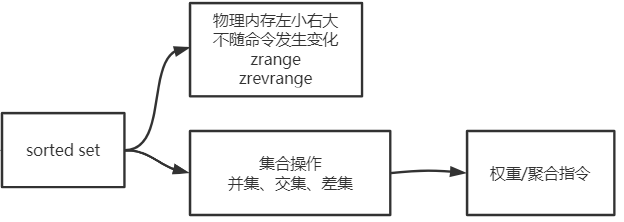
sorted set
![]()
- 去重,有序
- 排序是根据存入的排序依据(score)进行的,如果分值相同,按照value的字典序进行排序
- 有正负向索引
- 对sorted_set的操作(对元素、分值以及排名的操作)
- help @sorted_set查看所有操作
- zadd key score member [score member...]:存入数据及其分值。
- zrange key start stop [WITHSCORES]:取出从start到stop(索引是按照分数来排序的)的元素[将分值也打印出来]。
- zrangebyscore key min max [WITHSCORES]:取出分值在min到max之间的元素[将分值也打印出来]。
- zrevrange key start stop:由高到低取出start到stop之间的数据(由高到低取数据只能使用zrevrange)。
- zscore key member:取出member的分值。
- zrank key member:取出member的排名。
- zincrby key increment member:对member的分值增加increment。
- zunionstore destination numkeys key [key...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
- numkeys--key的个数:不加其他参数的时候会把两个key中重复出现的元素的分值相加,此时WEIGHTS默认为1,AGGREGATE默认为sum。
- WEIGHTS--权重:此时的分数=key1*weight1 + key2*weight2。此时AGGREGATE默认为sum
- AGGREGATE--聚合参数:max:去重复元素分值的最大值。
posted @
2021-02-28 19:17
January01
阅读(
145)
评论()
收藏
举报



 浙公网安备 33010602011771号
浙公网安备 33010602011771号