
Redis与epoll
简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。--- From 官网
特性
- key里面会有一个属性--type,描述的是value的类型
- 可以通过type key来查看value的类型,因为value有多种类型,每种类型都有自己对应的方法(和类型绑定)。如果从客服端发出一个非当前类型的方法,只需要检查是否和key中保存的value数据类型匹配,如果不匹配直接报错,不会发生实际操作。
- key还有一个encoding属性,描述的value的encoding(hello的encoding是embstr,99是int,但是这两个值的type都是string)。
- object encoding key:查看value的encoding
- 因为redis还提供了一些计算操作(比如对数值的增减)
- 二进制安全
- 面向流有字节流和字符流。通过socket访问redis时,redis只取出字节流。因为如果redis只存放字节没有按照编码集转换的话,只要双方客户端有统一的编解码,数据就不会被破坏。
Memcached
在memcached中value没有类型的概念,通过json表示复杂的数据结构。看似value的类型没有存在的意义,因为json可以表示很多复杂的数据类型,但是性能会差很多。类型不是很重要,重要的是redis的server中对每种类型都有自己的方法。比如,客户端要取出value中的某一个元素,memcached需要返回value所有的数据到client(网卡I/O,client端需要做转换),redis可以通过自己的方法就可以直接返回所需的元素。本质是解耦,在大数据中可以说,计算向数据移动。
秒级十万操作(1.5M ops/sec)
Redis原理
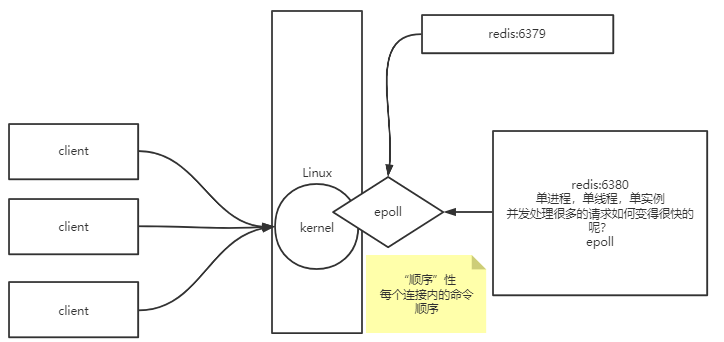
- 单进程,单线程,单实例
- 不完全是为了规避线程切换带来的性能损耗,更重要的是为了保证数据一致性。
- 并发到来时,为什么效率很高?
- 客户端可能带来一个或多个连接,连接先到达内核,redis进程和内核之间使用的是epoll系统调用(非阻塞的多路复用系统调用)。
- 因为redis单进程,所有数据是有“顺序的”。
- 这个顺序是挨个处理数据,按顺序读取就绪描述符的链表。
- 如果想保证事务,对于同一个key的增删改查,要让一个线程(连接)发出请求。
![]()
I/O发展以及epoll
- BIO
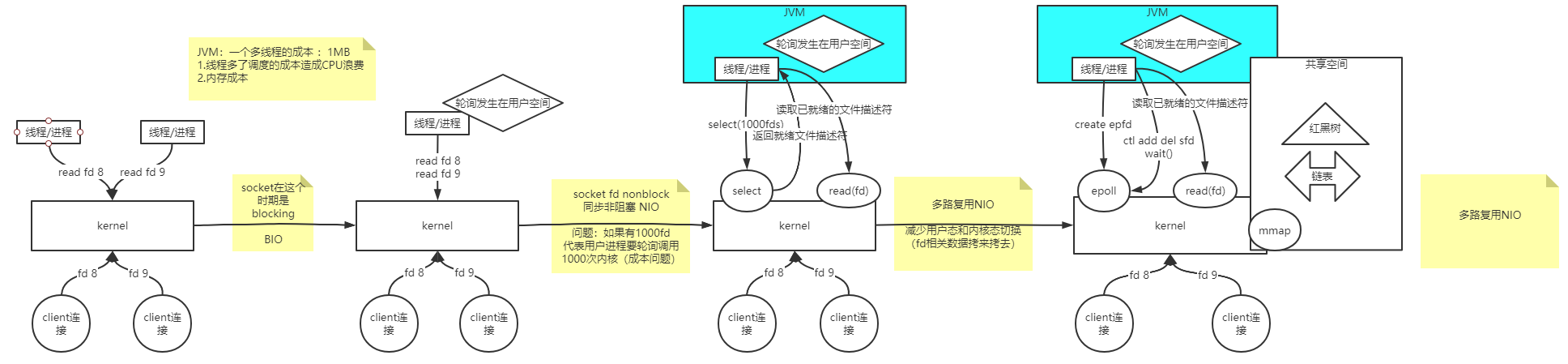
- 早期处理到达内核的连接:通过线程/进程(Java是线程,Linux是进程)read系统调用读取连接的文件描述符。socket在这个时期是blocking(阻塞),所以读取socket产生的文件描述符时,如果数据没到的时候,read命令不能返回,也是阻塞的。此时面对很多连接只能抛出不同的线程/进程处理,所以CPU并没有时刻处理那些数据到达的线程,会产生资源浪费,同时,线程过多的话,切换线程也是有成本的。
- NIO
- 内核发生了变化,socket可以是非阻塞的(nonblock),也就是fd(文件描述符)可以使非阻塞的。
- 可以在Linux中看到(一切皆文件),任何进程在Linux中都有自己I/O对应的文件描述符,查看进程文件描述符使用 cd /proc/进程号/fd)。
- yuminstall man man-pages
- man ls、man 2 read、man 2 socket
- 因为文件描述符是非阻塞,可以在一颗CPU上只使用一个线程去读取文件描述符,如果有数据就进行处理,如果没有数据,去轮询别的文件描述符(轮询发生在用户线程)。减少了线程切换带来的成本。
- 此时是同步非阻塞(同步,所有东西都是我来处理,异步,交给别人处理。)
- 问题:如果有大量的fd(1000个) ,代表用户进程轮询调用1000次内核,带来了很大的成本问题。
- 为解决轮询的成本问题,内核再次发展,出现select系统调用,线程/进程通过select告知内核需要哪些文件描述符,待文件描述符就绪时,内核通过select返回给线程/进程。线程/进程通过read系统调用去读取文件描述符。减少了内核态和用户态的切换。
- 多路复用NIO。
- 问题:线程/进程每次要传很多文件描述符给内核,内核再返回给线程/进程可用描述符,线程/进程在执行系统调用去读取,还是有些复杂。
- epoll(man epoll)是通过内核态和用户态的共享空间(共享内存中有红黑树和链表两个数据结构)实现的(epoll是一个整体,不是一个系统调用)。线程/进程使用epoll_create获取一个epoll文件描述符,内核会准备一个共享空间来。如果有1000个文件描述符,会注册到共享空间中的红黑树中(内核来完成),内核会把红黑树中就绪的文件描述符放到链表中。用户直接从共享空间中读取就绪的文件描述符,然后调用read系统调用读取数据。
- 用户空间有两个系统调用
- epoll_ctl add/del sfd:添加或删除要监听的文件描述符。
- epoll_wait:当链表中有就绪的文件描述符时,会返回给线程/进程(从阻塞变为不阻塞)。
- 共享空间其实也是自己空间的一部分,用户态和内核态可以直接访问。有了共享空间之后,用户态不需要在自己再维护存放文件描述符的空间,直接放入(只需要调用系统调用,没有拷贝的过程)到共享内存中。
- 用户空间有两个系统调用
- 内核发生了变化,socket可以是非阻塞的(nonblock),也就是fd(文件描述符)可以使非阻塞的。
![]()
- 扩展:零拷贝
![]()
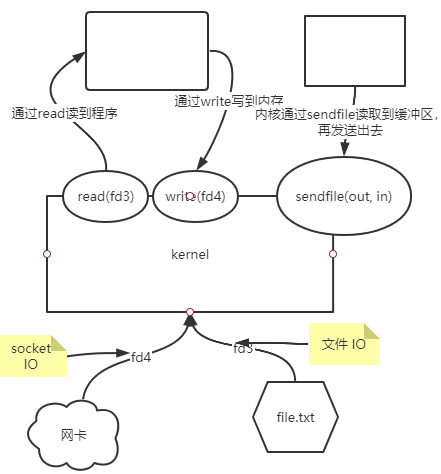
- 使用sendfile(out, in)实现。
- 在sendfile之前有read(fd)和write(fd)两个系统调用,内核使用read系统调用读取file.txt(文件 IO)到用户空间(文件数据先到buffer缓冲区,由read拷贝到用户空间),再通过write系统调用写到网卡(socket IO)中(通过write拷贝到buffer缓冲区,发送到网卡)。
- 使用sendfile后(用户空间调用),内核把文件数据放到buffer缓冲区,再直接发送到网卡,省略了来回拷贝的过程。
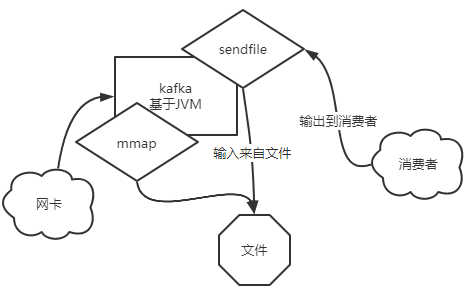
- kafka:sendfile+mmap
- kafka基于JVM
- 从网卡读取到的数据可以通过mma挂载到文件
- 消费者读取数据时,使用了sendfile系统调用(直接在内核完成输入输出。输入来自file,输出来自消费者)
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号