
selenium模块(自动化测试工具),安装selenium模块和环境搭建(配置信息),selenium模块查询标签(解析数据,过滤查找,获取标签名等),模拟动作操作(点击,平移,释放等动作),懒加载问题,浏览器窗口编码问题,等待加载问题
简介
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种常见的浏览器
安装selenium模块和环境搭建
安装selenium模块
pip install selenium
安装浏览器驱动(与当前浏览器版本一致),下载好驱动一定要加在项目里,或者配置系统环境变量
https://npm.taobao.org/mirrors/chromedriver/73.0.3683.68/ # 谷歌浏览器淘宝镜像驱动下载地址
# 其他浏览器驱动下载地址 1.chromedriver 下载地址:https://code.google.com/p/chromedriver/downloads/list 2.Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/ 3.IE的驱动IEdriver 下载地址:http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/ 4.火狐:http://ftp.mozilla.org/pub/firefox/releases/
简单使用
from selenium import webdriver # 开始模拟操作浏览器 drive=webdriver.Chrome() # 模拟操作谷歌浏览器 drive=webdriver.Firefox() # 模拟操作火狐浏览器 drive=webdriver.PhantomJS() # 模拟无界面浏览器(无GUI) drive=webdriver.Safari() # Safari浏览器(Mac OS操作系统中的浏览器) drive=webdriver.Edge() # 微软开发的浏览器
drive.get("https://www.baidu.com") # 驱动操作谷歌浏览器,模拟发送get请求
官网:http://selenium-python.readthedocs.io
操作有图形界面的浏览器用法(GUI)
from selenium import webdriver drive = webdriver.Chrome(r'F:\python\practice\爬虫reptile\day03\chromedriver.exe') # 下载好驱动以后将驱动放在项目根路径下,或者添加到系统环境变量中 drive.get("https://www.baidu.com") # 驱动操作谷歌浏览器,模拟发送get请求
Chrome浏览器设置为无GUI模式(无图形界面),配置信息
from selenium import webdriver from selenium.webdriver.chrome.options import Options # 先设置浏览器配置信息 chrome_options = Options() # 开始操作浏览器的配置信息 # 开始设置浏览器的配置信息 chrome_options.add_argument('window-size=1920x3000') # 指定浏览器分辨率 chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面 chrome_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 可以提升速度 chrome_options.add_argument('--headless') # 浏览器不提供可视化页面. linux下如果系统如果无界面不加这条会启动失败(相当于无GUI) chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) # 取消浏览器驱动提示 # 开始操作浏览器 driver=webdriver.Chrome("驱动绝对路径 如果环境变量中有则可以不写",chrome_options=chrome_options) # chrome_options=chrome_options 启动配置信息 driver.get('https://www.baidu.com') # 模拟Chrome浏览器访问百度 text = driver.page_source # 获取页面源代码 可以从中提取数据 print('hao123' in text) driver.close() # 切记关闭浏览器,回收资源
操作PhantomJS浏览器用法(无GUI,无图形界面),目前phantomJS已经停止了更新维护
地址:http://phantomjs.org/download.html
from selenium import webdriver
driver=webdriver.PhantomJS() # 开始操作无界面浏览器 driver.get('https://www.baidu.com') # 模拟PhantomJS浏览器访问百度 text = driver.page_source # 获取页面源代码 可以从中提取数据 ... time.sleep(10) # 隔十秒自动关闭浏览器 driver.close() # 关闭浏览器,回收资源
selenium模块查询标签
基本用法
try: from selenium import webdriver driver = webdriver.Chrome(r"D:\jerry\spiderDay3\selenium模块\chromedriver.exe") # 指定想相应的浏览器驱动 driver.get("https://www.baidu.com") # 操纵浏览器访问百度 # 过滤标签 input_tag=driver.find_element_by_id('kw') # 过滤id属性,操作input框 # 也可以改写成 input_tag=driver.find_element(By.ID,'kw') # 过滤出id为kw的第一个标签出来 input_tag=driver.find_elements(By.ID,'kw') # 过滤出id为kw的所有标签出来
# 开始驱动操作标签 input_tag.send_keys('美女') # 输入要输入的文字,python2中输入中文错误,字符串前加个u input_tag.send_keys(Keys.ENTER) # 输入按下回车键 # 解析数据 text = driver.page_source # 获取页面源代码 可以从中提取数据 driver.current_url # 获取当前连接地址 driver.get_cookies() # 获取当前的cookie值 finally: driver.close()
获取某一标签的标签名,id,其他属性,文本,位置,大小(了解)
from selenium import webdriver drive=webdriver.Chrome() # 操作浏览器 drive.get('https://www.amazon.cn/') # 模拟浏览器发请求 # 获取标签属性, tag.get_attribute('src') # 获取标签的src属性值 # 获取标签ID,名称,文本,位置,大小(了解) tag.id # 获取标签的id属性值 tag.tag_name # 获取标签的名字 tag.text # 获取标签的文本 tag.location # 获取标签的位置 {'x': 383, 'y': 67} tag.size # 获取标签的大小 {'height': 129, 'width': 270} drive.close() # 关闭浏览器
过滤查找(标签)
# 不带s表示过滤出第一个标签,带s表示过滤出所有标签 tag = driver.find_element_by_class_name("xx") # 过滤出第一个类名为xx的标签 tag = driver.find_elements_by_class_name("xx") # 过滤出所有类名为xx的标签们 # 标签名过滤 tag = driver.find_element_by_tag_name("body") # 标签名称等于body # 类名过滤 tag = driver.find_element_by_class_name("index-logo-src") # 通过类名来查找 # 过滤name属性 tag = driver.find_element_by_name("tj_trhao123") # name属性等于tj_trhao123 # id属性过滤 input_tag=driver.find_element_by_id('kw') # 过滤id属性值为kw的标签 # 选择器过滤 tag = driver.find_element_by_css_selector(".index-logo-src") # 通过选择器来查找 # 通过文本查找点击按键 tag = driver.find_element_by_link_text("学术") # 文本完全匹配过滤出来 tag = driver.find_element_by_partial_link_text("术") # 文本部分匹配过滤出来 tag.click() # 模拟点击 # 嵌套过滤 tag = driver.find_element_by_name("tj_trhao123") # name属性等于tj_trhao123的标签 tag2 = tag.find_element_by_tag_name("a") # name属性等于tj_trhao123的标签里的 a 标签
find_element_by_xpath # 利用xpath模块过滤
等待页面加载某一元素
隐士等待
# 隐士等待,不管什么标签,等待10秒,还没找到就报错 from selenium import webdriver drive=webdriver.Chrome() # 操作浏览器 # 隐士等待,发请求之后马上设置等待时间,为隐士等待
drive.get('https://www.amazon.cn/') # 模拟浏览器发请求
driver.implicitly_wait(10) # 当要查找的某个元素不存在时 会过一会儿在查找一次(轮询),直到超过10秒就报错
显示等待
# 显示等待,明确知道某一标签等待满足某些条件 from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 方法1:
key_input = driver.find_element(By.ID,"kw")
# 方法2:
key_input = driver.find_element_by_id("kw") # 当我们要查找的id为kw的标签,超过10秒没找到就报错
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,"content_left"))) # 等待id="content_left"的标签,10秒内没找到,报错
模拟动作操作,一定要执行此动作
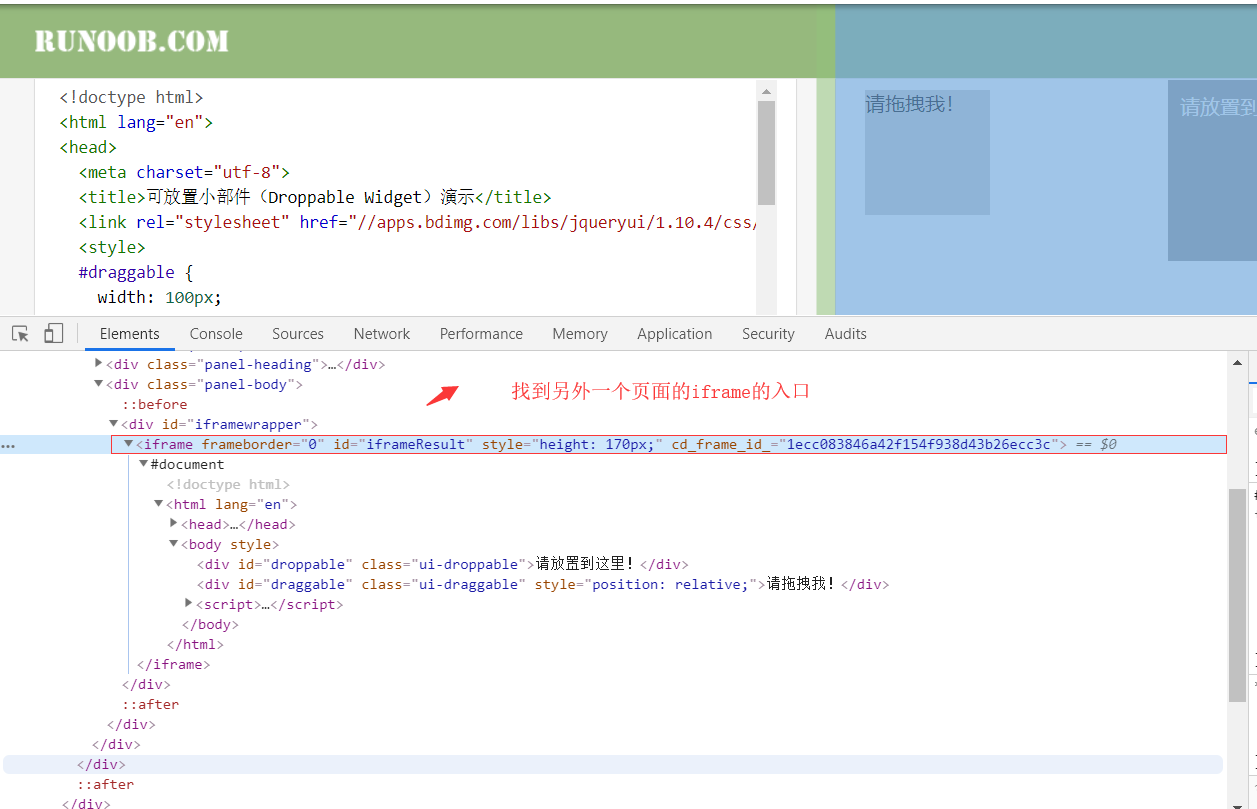
切换fream,相当于是页面里又加载了另外一个页面
driver.switch_to.frame("iframeResult1") # 从主框架往子框架切 driver.switch_to.frame("iframeResult2") # 一层一层往下切 driver.switch_to.parent_frame() # 不需要参数,从子框架往父框架切 driver.switch_to.parent_frame() # 一层一层往上切,如果是主框架则无任何效果
模拟键盘按键动作
from selenium.webdriver.common.keys import Keys key_input.send_keys("基佬") # 找到输入框,模拟输入文字 key_input.send_keys(Keys.ENTER) # 模拟回车键 key_input.clear() # 清空输入框,每次操作输入框前先清空input框
# 模拟点击动作
# 确定点击的标签
tag = driver.find_element_by_link_text("登陆") # 文本完全匹配过滤出来 tag = driver.find_element_by_partial_link_text("登") # 文本部分匹配过滤出来
# 执行点击
tag.click() # 模拟点击
瞬间平移动作
from selenium.webdriver import ActionChains # 创建一个动作对象 asc = ActionChains(driver) # 点击并按住动作,click_and_hold asc.click_and_hold(tag).perform() # 点击并按住,perform()表示执行这个动作 # 瞬移动作 move_to_element asc.move_to_element(tag2).perform() # 瞬间移动标签到tag2的位置 # 松手动作 release asc.release().perform() # 松手动作
线性移动动作
from selenium.webdriver import ActionChains while tag.location["x"] < tag2.location["x"]: # 当移动的标签坐标小于目标标签的坐标 ActionChains(driver).move_by_offset(1,0).perform() # 则每次移动1距离坐标 asc.release().perform()
模拟执行js
driver = Chrome(r"F:\python\practice\爬虫reptile\day03\chromedriver.exe") driver.get("https://www.baidu.com") driver.execute_script("alert('你是杀马特码?')") driver.execute_script("window.open()") # 相当于打开一个窗口
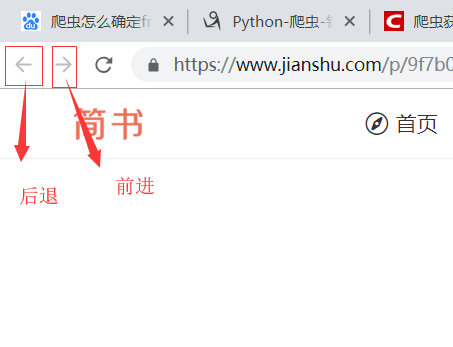
模拟操作导航条
driver.back() # 后退,相当于返回上一次的浏览地址 driver.forward() # 前进
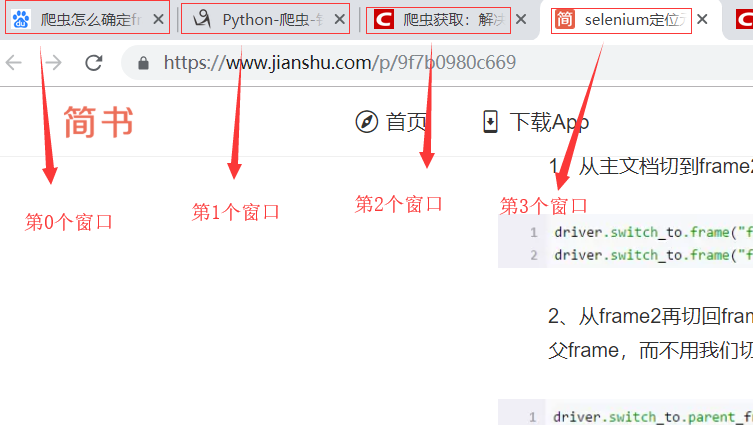
模拟操作窗口
driver.execute_script("window.open()") # 模拟打开一个新窗口 print(driver.window_handles) # 获取所有windows对象 driver.switch_to.window(driver.window_handles[1]) # 切换到第1个窗口
懒加载问题,浏览器窗口编码问题,等待加载问题
from selenium.webdriver import Chrome from urllib.parse import urlencode import time
# 处理窗口编码问题 kw = "黄金" par = {"enc": "utf-8", "keyword": kw, "wq":kw} # 处理浏览器编码问题 kw = urlencode(par) # 处理浏览器编码问题
print(kw) # enc=utf-8 & keyword=%E9%BB%84%E9%87%91 & wq=%E9%BB%84%E9%87%91
# 驱动浏览器发请求
url = 'https://search.jd.com/Search?' + kw # 已经编好码的连接
drive = Chrome(r'F:\python\practice\爬虫reptile\day05\chromedriver.exe')
drive.get(url) # 驱动浏览器发请求
# 隐士等待加载问题
drive.implicitly_wait(10) # 隐士等待加载
# 处理懒加载问题(模拟滑动)
height = drive.execute_script("return document.body.clientHeight") # 测出页面总高度
dis = 0 # 已经滑动的距离
while dis < height:
drive.execute_script("""
window.scrollTo({
top: %s, behavior: "smooth"
});""" % dis)
dis += 200 # 每次滑动200
time.sleep(0.2)
drive.implicitly_wait(5)
# 开始过滤查找标签 tag = drive.find_elements_by_class_name('gl-warp') # 开始过滤查找 for i in tag: print(i.find_element_by_class_name("p-img").get_attribute('href'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号