
HashMap部分源码解析(JDK1.8)
JDK1.8版本的HashMap源码
HashMap<K,V>继承自AbstractMap<K,V>,并实现了Map<K,V>, Cloneable, Serializable三个接口。

一些默认的静态常量
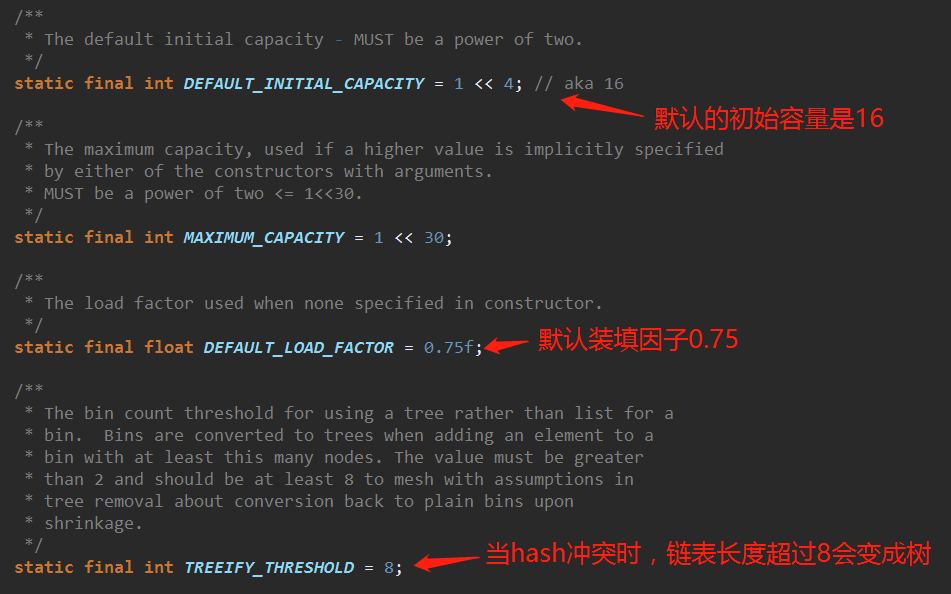
静态内部类Node的定义。Node实现了Map.Entry接口。可以看到Node就是链表的节点。
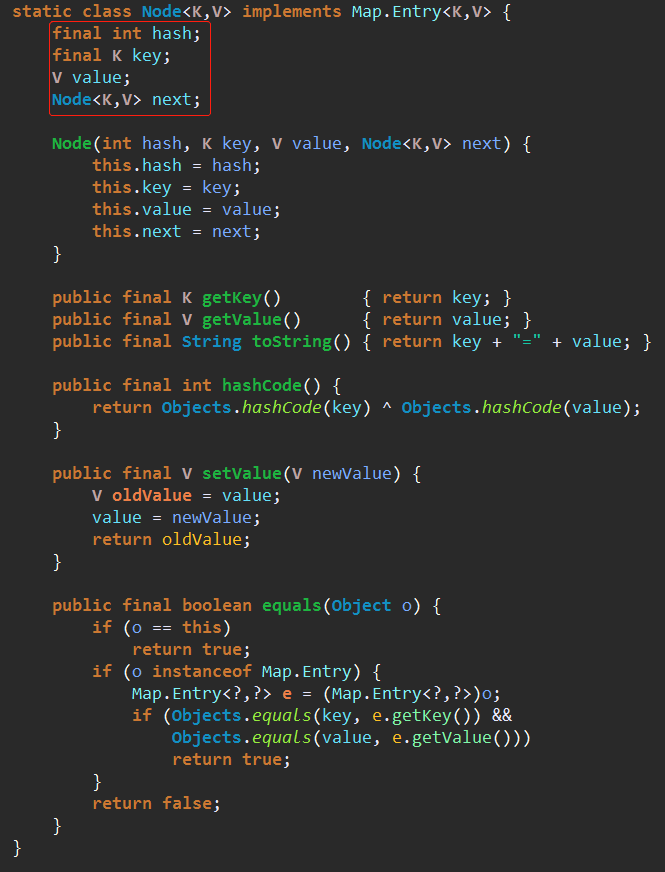
HashMap的域中定义了一个链表数组
HashMap自己的hash计算方法,可以看到当key==null的时候hashcode是0。

HashMap一共有4个构造器:
1、由外部传入初始容量和装填因子
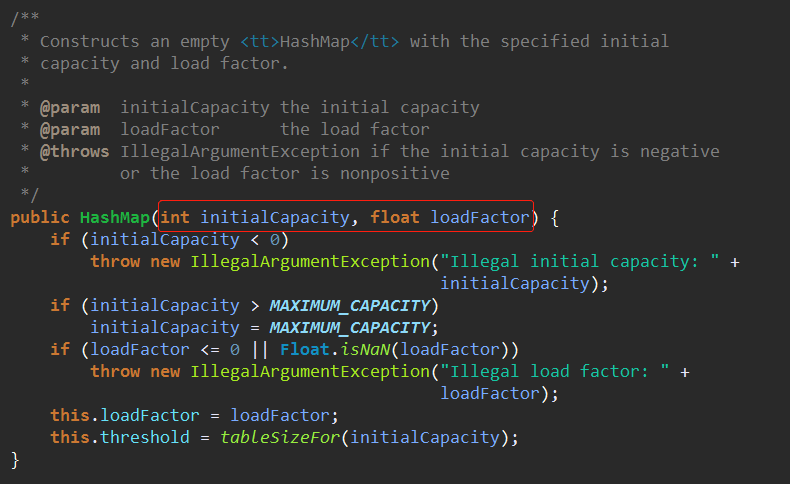
2、外部传入初始容量,装填因子采用默认的0.75
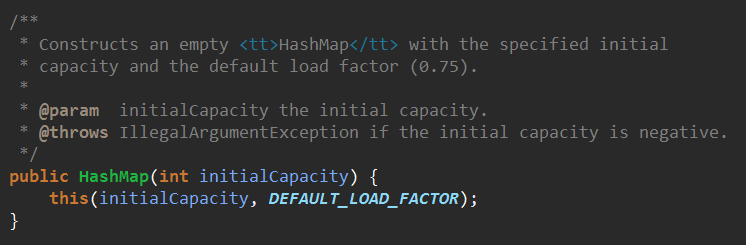
3、什么都不传入
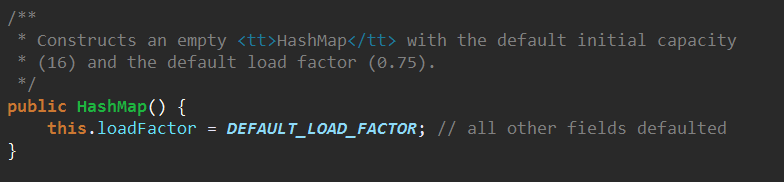
4、使用另一个Map来构造HashMap
下面先看get方法:
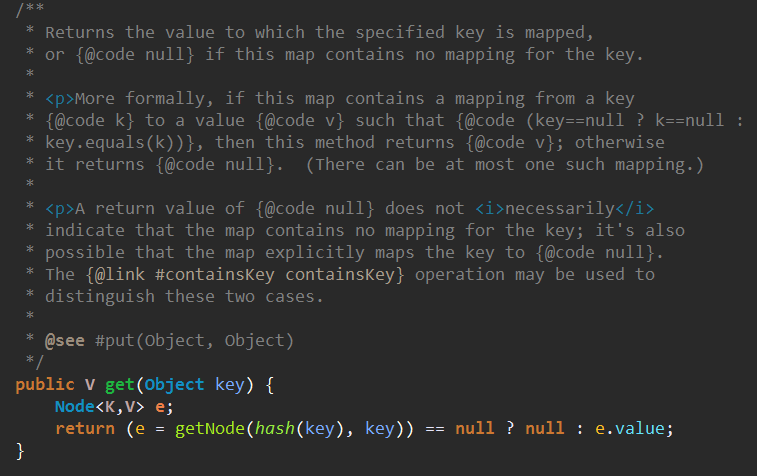
get调用了一个getNode方法
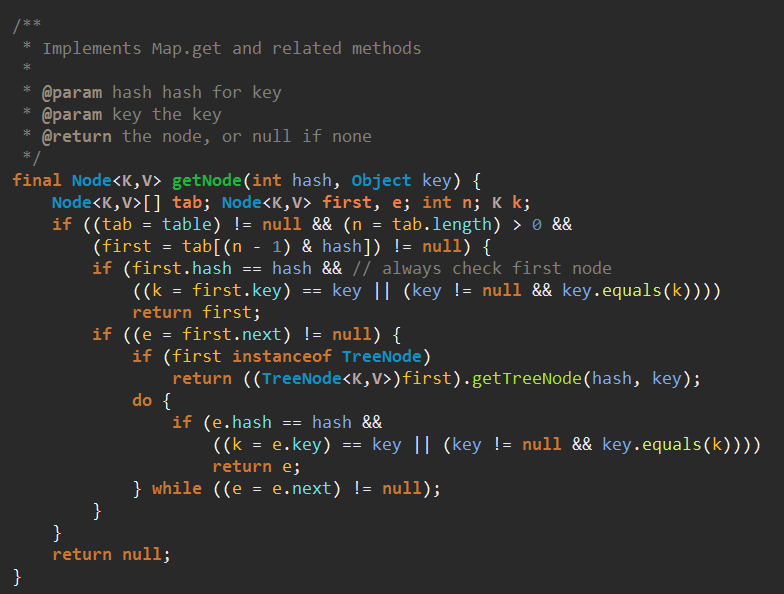
getNode的流程:
1、先判断链表数组是否为空,然后再判断对应位置的链表的头结点是否为空。如果其中一个为空的话直接返回null
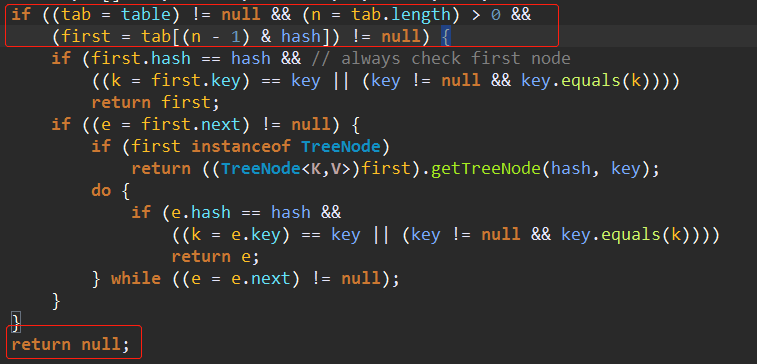
2、检查头结点,如果头结点不为空的话返回头结点

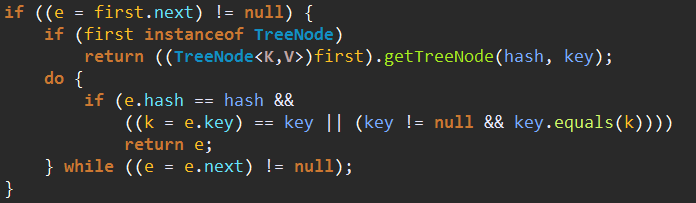
3、判断头结点的next是否为空,不为空的话判断头结点是不是一个TreeNode,是的话按照TreeNode的方式去搜索结果,不是的话按照链表的方式去搜索结果。
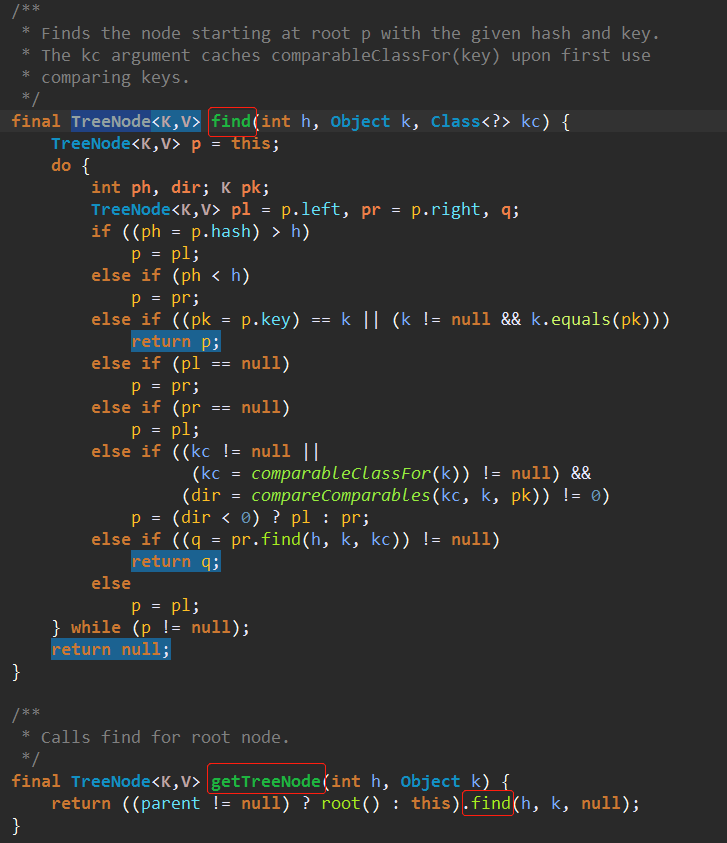
getTreeNode的方法有点复杂,暂时先搁置具体过程研究。
下面看put方法:
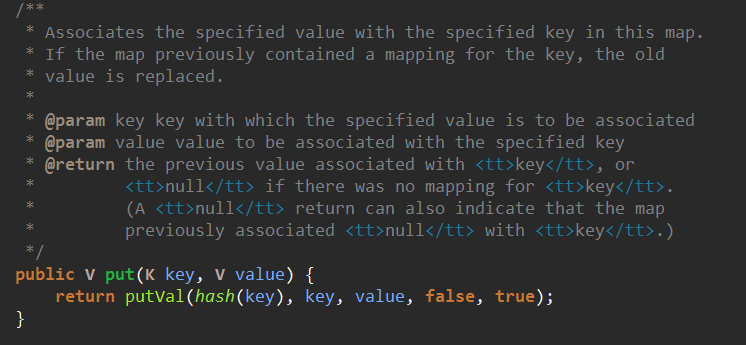
put调用了putVal这个方法
putVal一共有5个参数,参数介绍如下

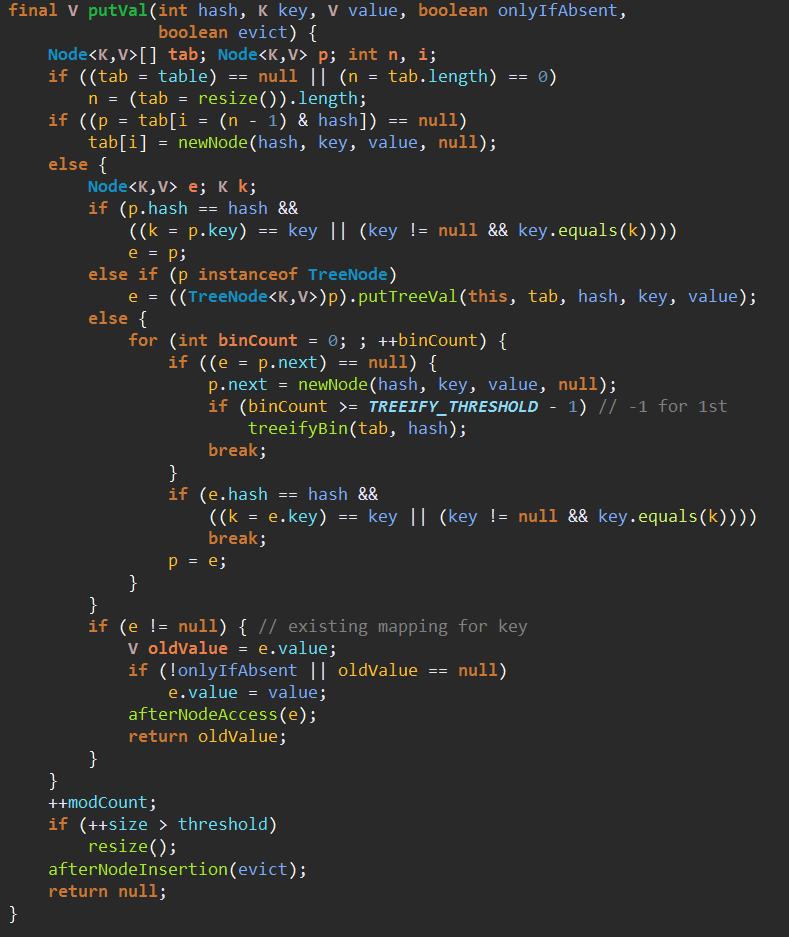
putVal的流程:
1、判断链表数组是否为空或者长度为0,是的话需要重新resize()一下。

关于resize()先把说明放这,作用是初始化或者翻倍链表数组的容量。
2、判断链表的头结点是不是为空,为空的话可以直接new一个节点出来,完成插入。同时返回null。
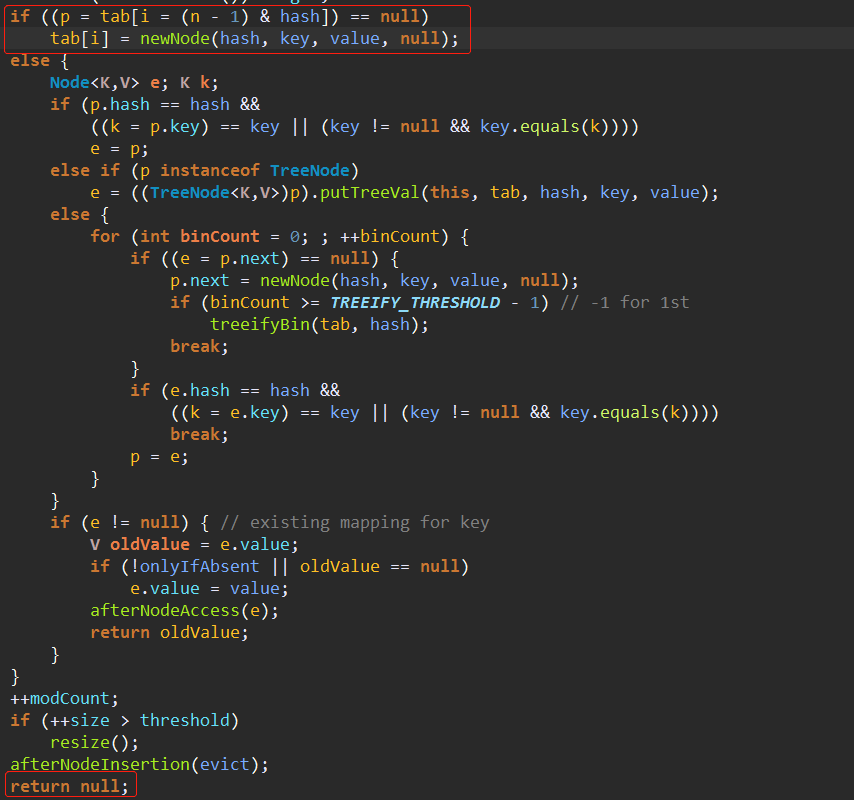
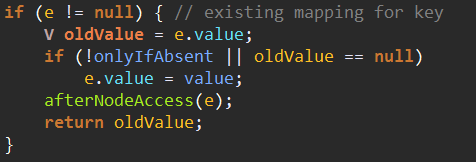
3、判断put的key。val是否和头结点p的key、val相同。相同的话直接将返回值e设置为p。最后会返回被覆盖的value值。
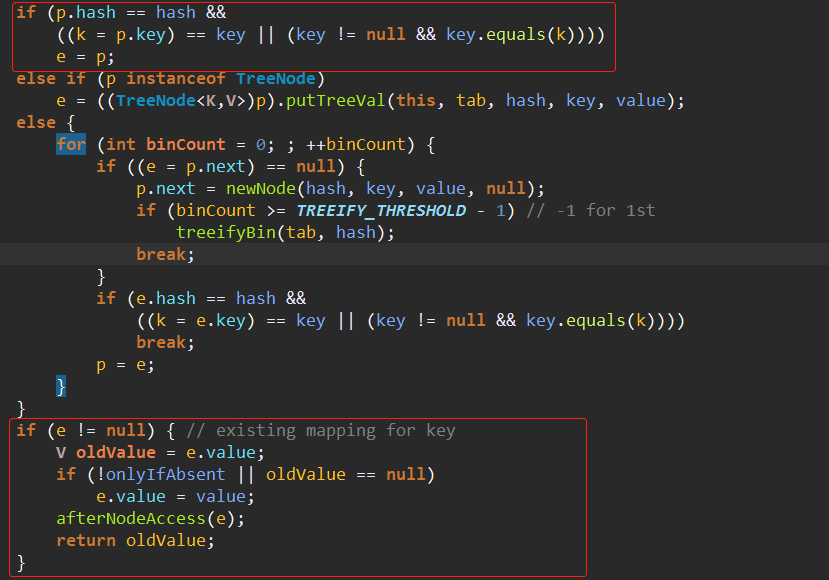
4、如果3的条件不成立,那么判断头结点p是否为TreeNode,是的话就调用putTreeVal来添加。

putTreeVal挺复杂的,具体流程先放一边搁置。

5、如果不是TreeNode,则按照链表的方式处理。
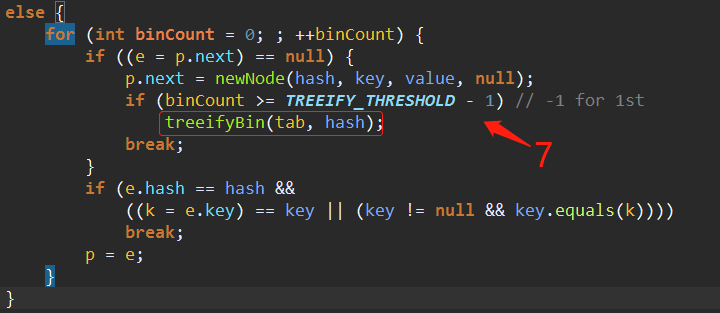
在遍历链表过程中如果遇到key相同的,那么依然会走到下面这一步。
如果遍历链表都没有key相同,那么直接尾部插入一个新节点。尾插法,之前一直记错了,把HashMap记成头插法了。
如果插入节点后长度超过7的话,那么会调用

将链表转换为红黑树。
6、最后如果新的key、value队插入的的话++modCount,同时size加1.如果size超过了threshold,就会扩容。

下面我们来看resize()方法的流程。resize()方法有扩容兼初始化的作用。
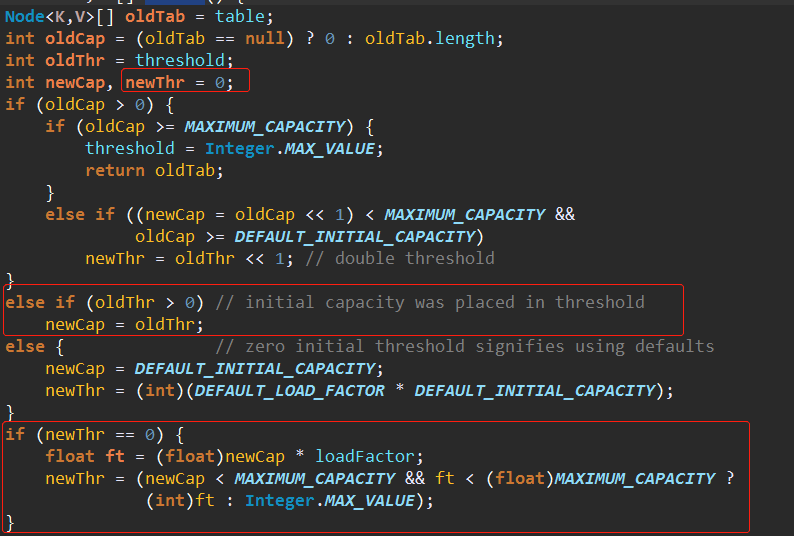
1、
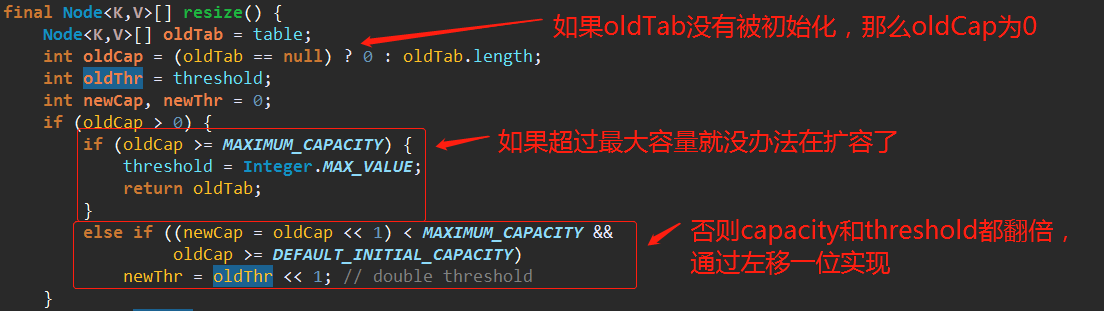
2、如果oldCap为0,oldThr > 0的话,那么会执行以下这一步,把oldThr赋值给newCap。

为什么是把oldThr赋值给newCap?
回头去看,oldThr的值是threshold,那么threshold的值是谁呢?
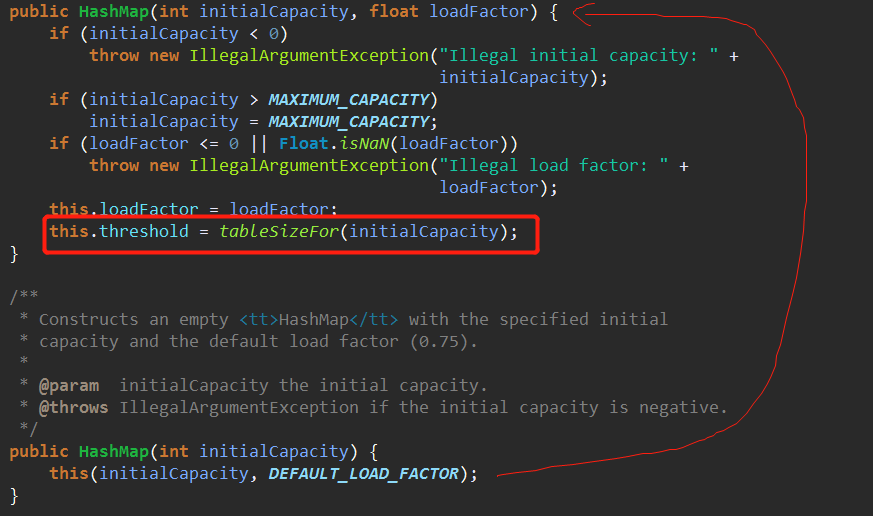
再回头去翻。回到构造函数。如果threshold没有被动过的话那么按照Java的规范应该默认初始化为0。而这里的值不为0,那么自然得找动过threshold的构造函数。
于是发现了这两个构造函数有给threshold赋值。
继续看tableSizeFor这个方法。
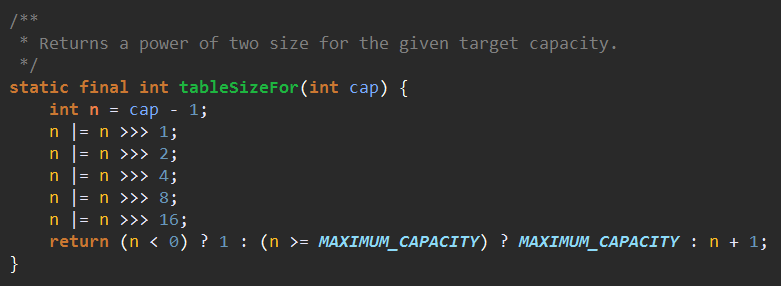
这个方法的作用是当在实例化HashMap实例时,如果给定了initialCapacity,由于HashMap的capacity都是2的幂,因此这个方法用于找到大于等于initialCapacity的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)。
所以最后构造器里的这句this.threshold = tableSizeFor(initialCapacity)在未执行resize()之前其实代表的是capacity的数值。也就是说下图的代码的作用是在我使用了带initialCapacity参数的构造器的时候,第一次使用resize()时(比如第一次put的时候,put就会调用resize()初始化链表数组)给Node<K,V>[] tab初始化capacity参数

3、与2相对的是下图代码就是在使用不指定initialCapacity参数的构造器构造HashMap时,初始化capacity和threshold。

4、如果进入了2步骤中的判断的话,那么需要给newThr赋值。
5、将newThr赋值给变量threshold。
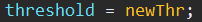
6、根据newCap建立一个新的链表数组。

7、如果oldTab不为空,遍历oldTab。并将原来的oldTab[j]赋值为空
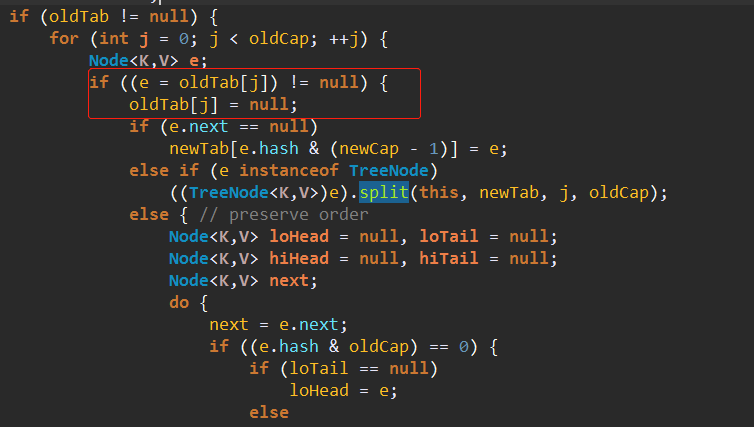
8、如果原oldTab处的链表只有一个节点的话,那么直接放入newTab对应的位置即可。

9、否则如果e是TreeNode,那么调用split拆分。

关于split,搁置。
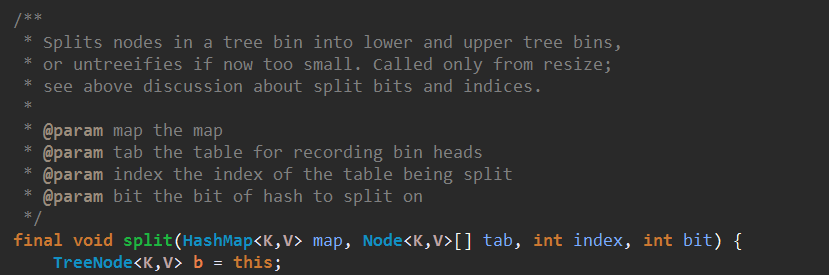
10、这一块比较难理解。
如果e.next != null,e也不是TreeNode,那么进行链表复制。
方法比较特殊:它并没有重新计算元素在数组中的位置,而是采用了原始位置加原数组长度的方法计算得到位置。
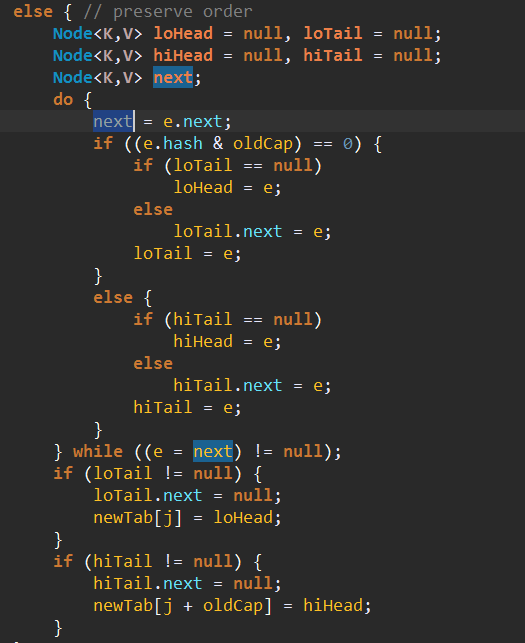
结合网上有人写的分析:

中间的do while循环


11、resize()末尾返回newTab

贴一个网上说的JDK1.8和JDK1.7的区别
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,
经过rehash之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。对应的就是下方的resize的注释。

看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希值(也就是根据key1算出来的hashcode值)与高位与运算的结果。


元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
再看一下remove()方法
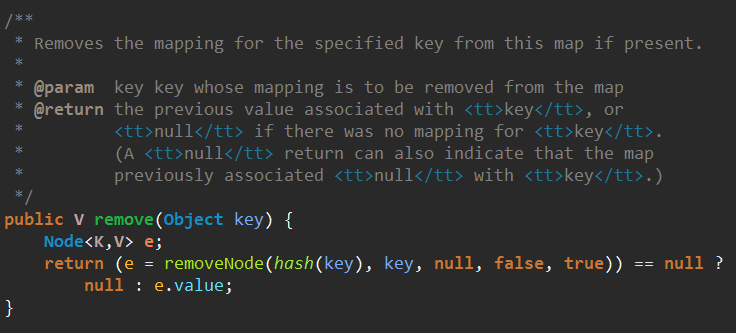
remove()调用了removeNode()方法
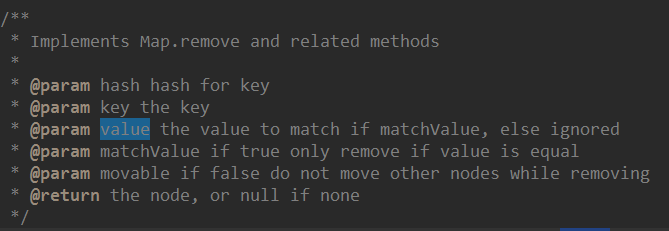

removeNode()流程如下:
1、先获得头结点,然后检查头结点是不是要删除的节点。如果是的话那么给node赋值p。
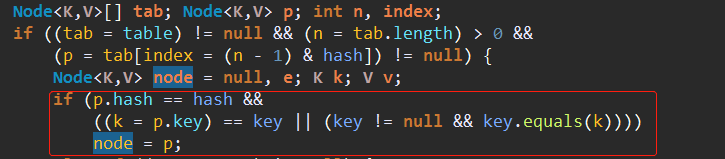
2、否则如果p是TreeNode就按照TreeNode的方法得到待删除的node,如果p是链表的话就遍历链表得到待删除的node。
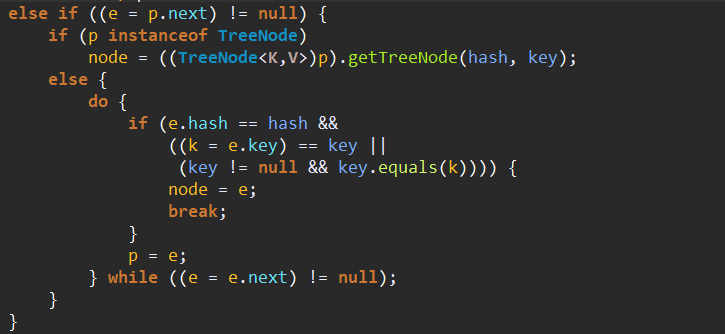
3、看待删除的Node是否为null。不为null的话就使用对应的方法将其移除。
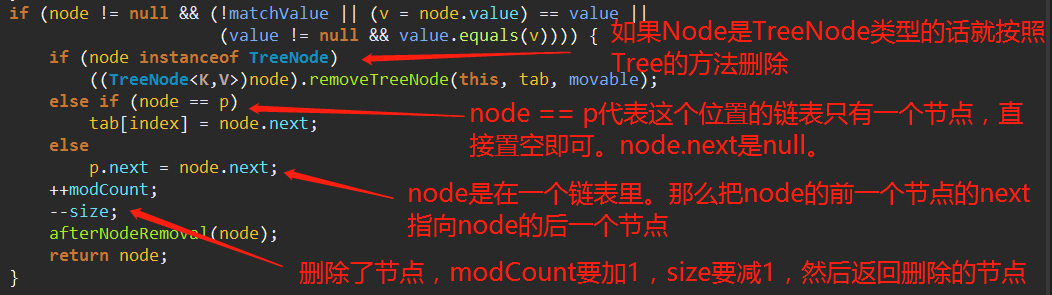
4、如果没有删除节点,就返回null。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号