6、seq2seq - Transformer-Encoder、Transformer-Decoder
-
Attention - 注意力机制
-
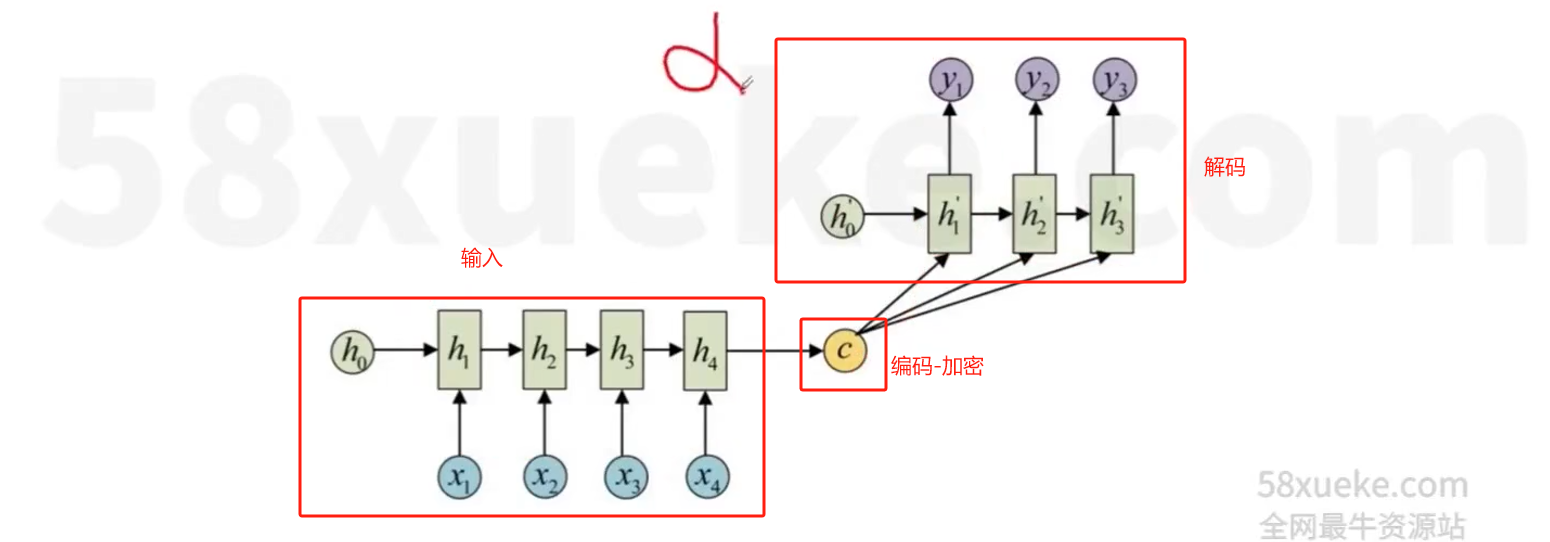
seq2seq是 Sequence to Sequence 的简写,seq2seq模型的核心就是编码器(Encoder)和解码器(Decoder)组成的
-
通过在seq2seq结构中加入Attention机制,是seq2seq的性能大大提升,先在seq2seq被广泛的用于机器翻译、对话生成、人体姿态序列生成等各种任务上,并取得了非常好的效果
- 这里 C1 = X1h2 + X2h2 + .....
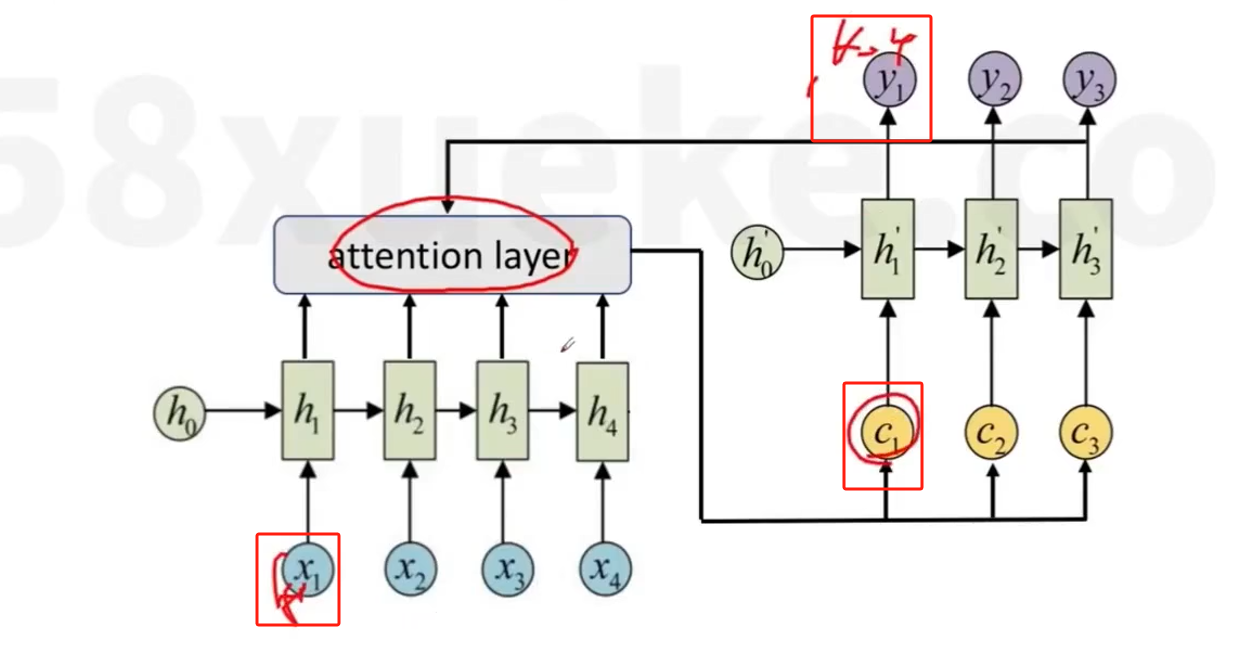
- 这里 C1 = X1h2 + X2h2 + .....
+对于Decoder的每一步解码i,都有一个输入Ci,对输入序列所有隐藏信息h1,h2....进行加权求和
- 相当于在预测下一个词时,会把输入序列的隐藏信息都看一遍,决定预测当前词语输入序列的哪些词最相关
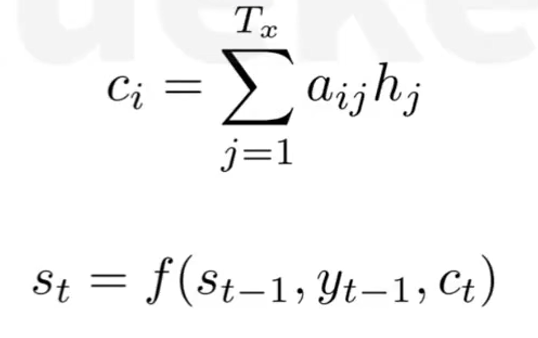
-
-
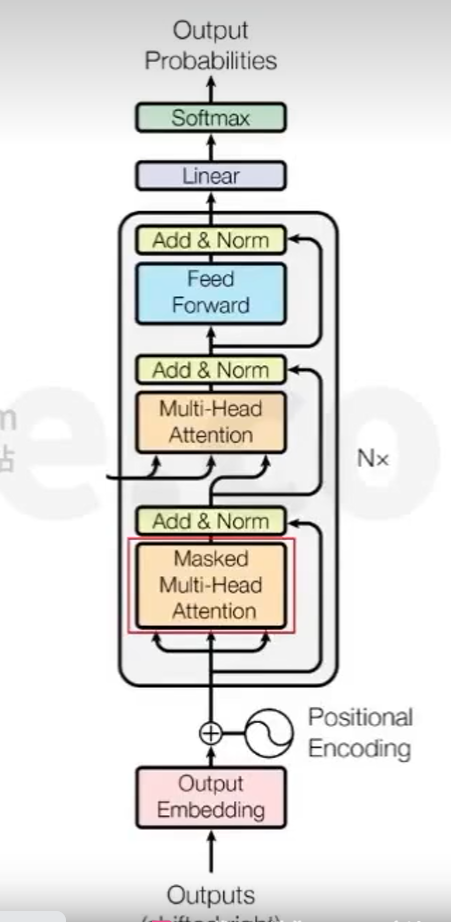
Transformer - 今后的大模型都基于这个模型
-
结构 - 参考seq2seq

-
基本流程
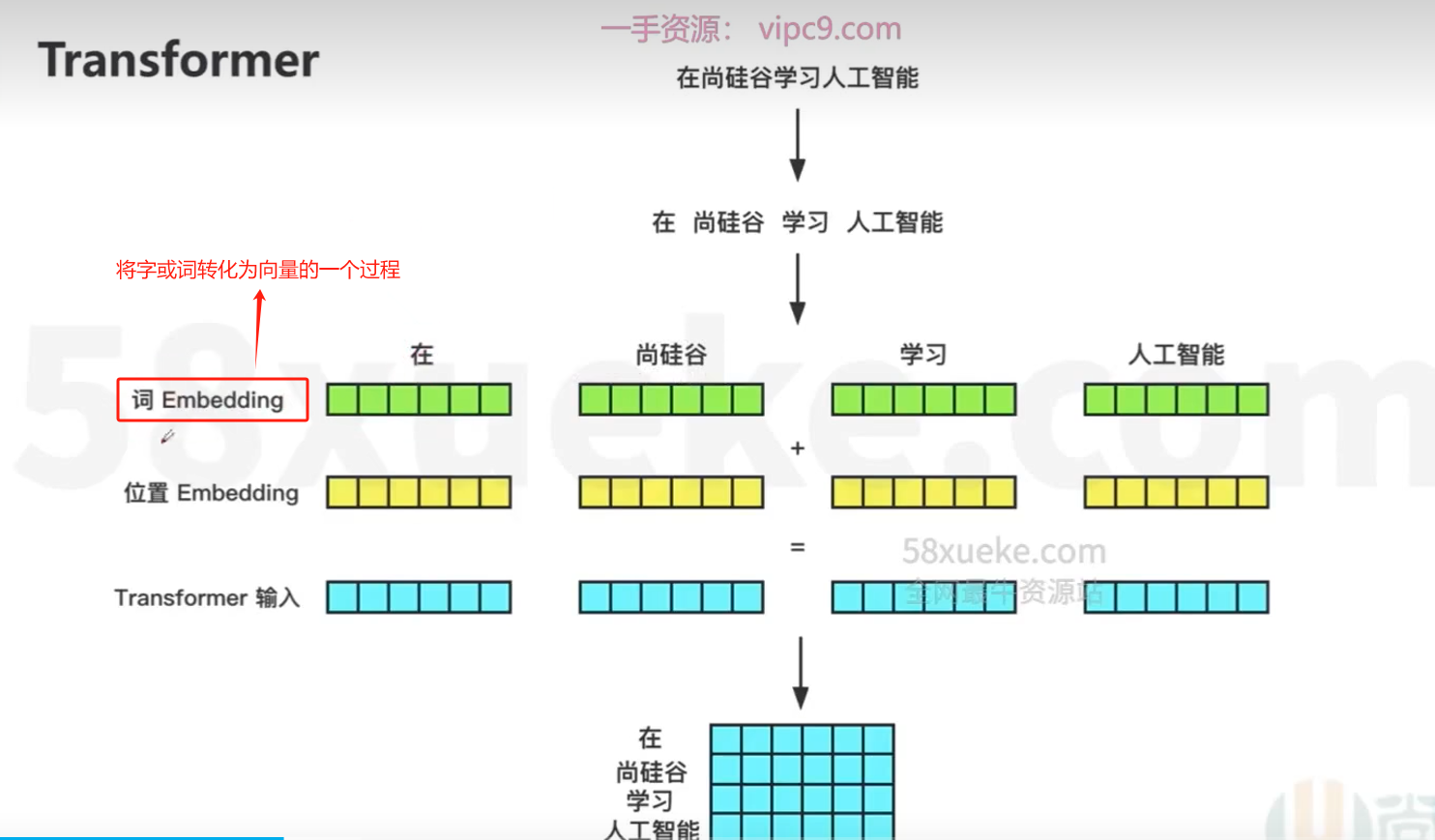
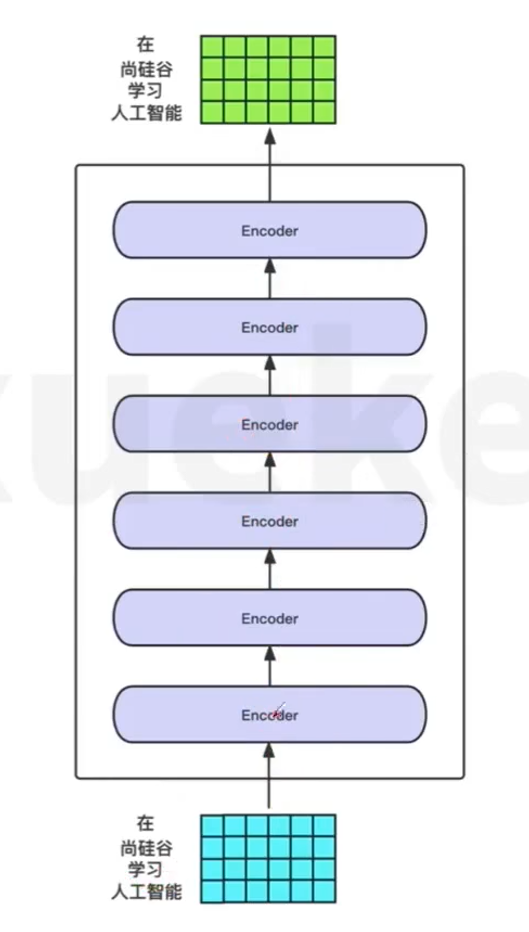
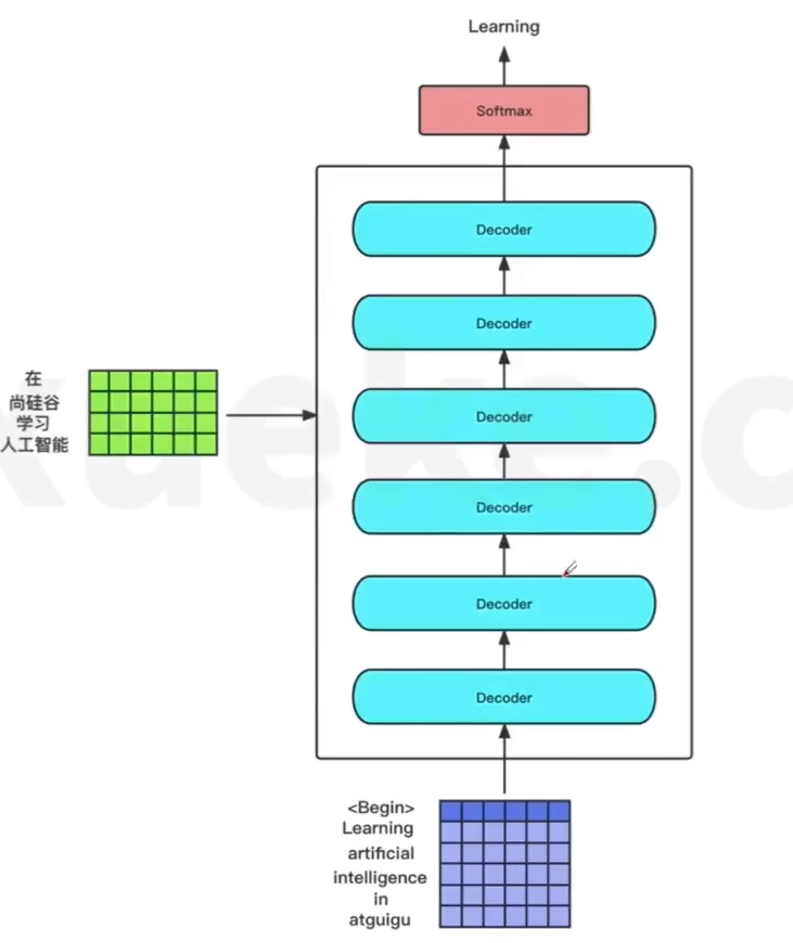
-
位置编码
-
文本是时序型数据,词与词之间的顺序关系往往影响整个句子的含义
-
【绝对位置编码】
- 给每个位置位置信息建模
- 最简单的实现方式:使用每个词汇的次序1,2,...., T作为位置编码信息
- 如:BERT使用的是Learned Positional Embedding,先初始化位置编码,再放到预训练过程中,训练出每个位置的位置向量
- 绝对位置编码存在一个严重的问题,例如,模型最大序列长度为512,那么预测阶段输入超过512的序列就无法进行处理
-
【嫌贵位置编码】
- 相对位置并没有完整建模每个输入的位置信息,而是在计算Attention的时候考虑当前位置与被Attention的位置的相对距离
- 由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现,在Transformer中使用的就是相对位置编码的方式
-
【更好的编码方式】
- 目前,已经出现了更优秀的位置编码方式,例如旋转位置编码,他兼顾了绝对位置信息与相对位置信息
-
【为什么Transformer需要位置编码信息?】


-
根据上面讨论,我们希望位置编码满足以下的需求:
-
能够体现词汇在不同位置的区别(特别是同一词汇在不同位置的区别)
-
能够体现词汇的先后次序,并且编码值不依赖于文本的长度
-
有值域范围限制
-
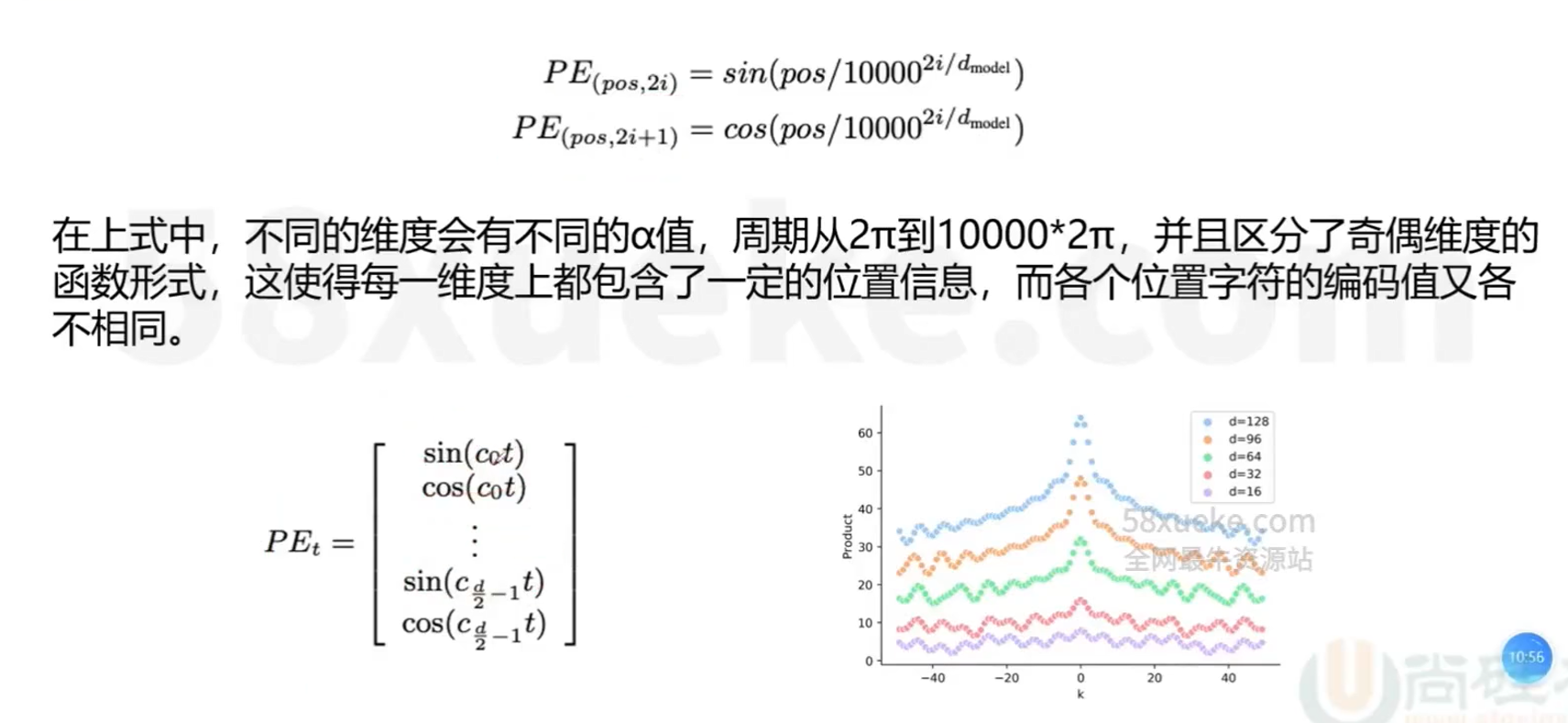
因此,Transformer引入了相对位置的概念,使用sin/cos函数(有界周期函数)来表示相对位置,sin/cos函数周期变化规律稳定,使得编码具有一定的不变性
-
如下例子:

-
-
-
-
Transformer Encoder
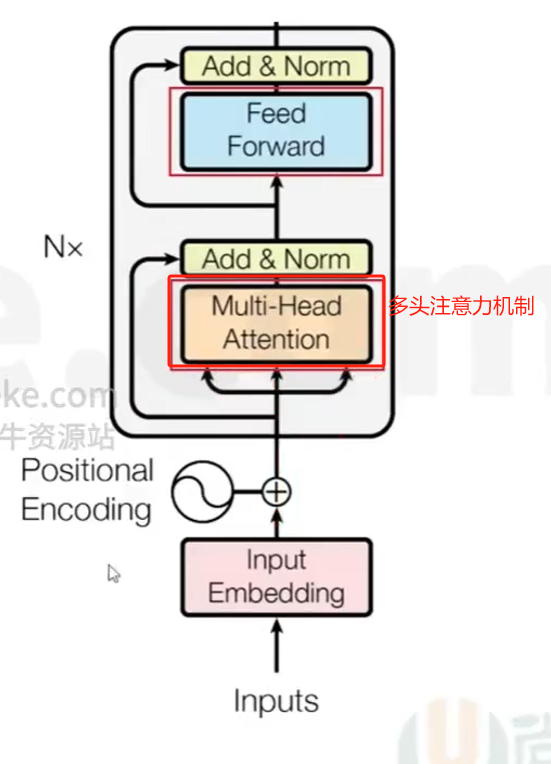
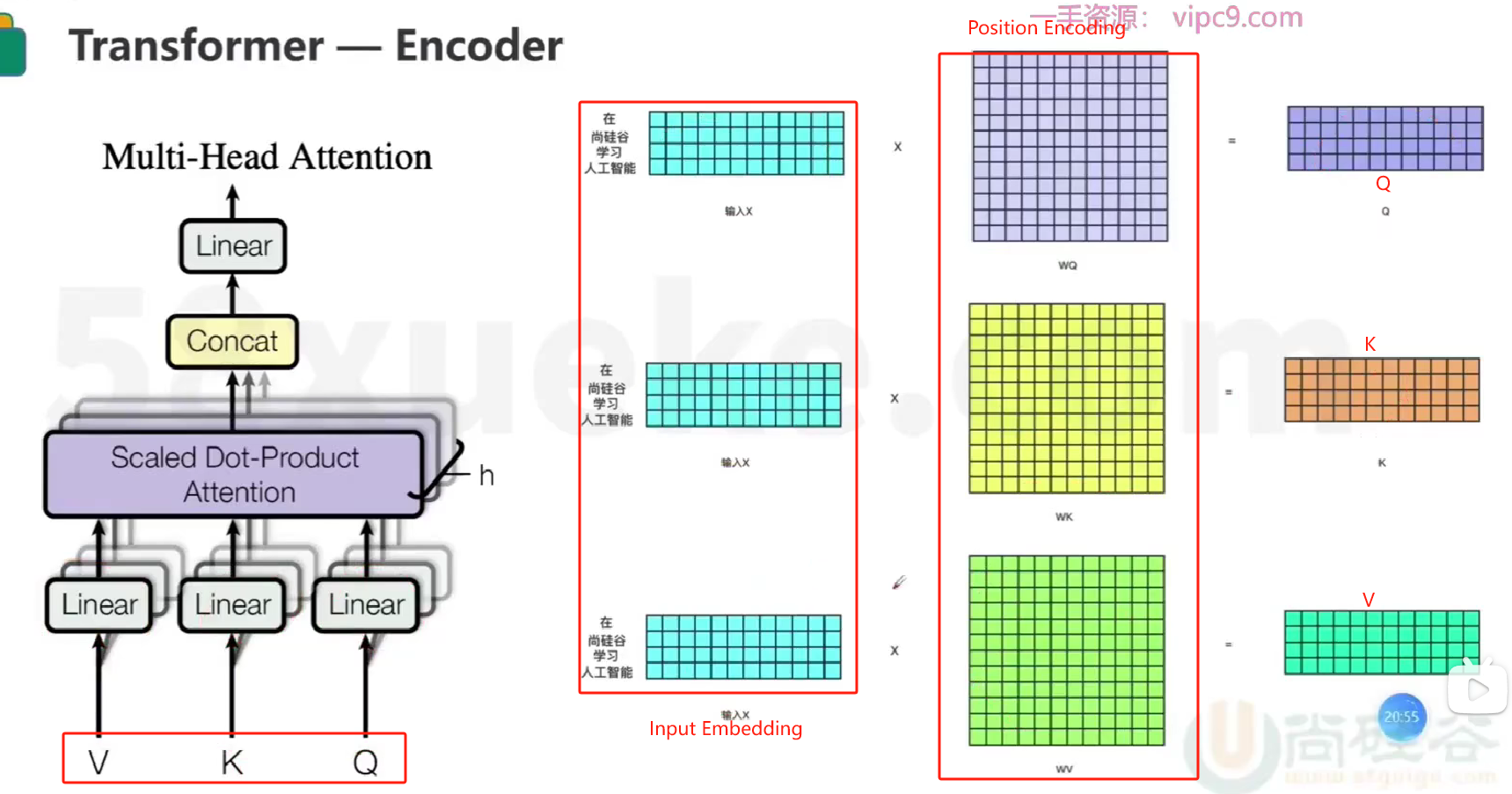
- 【Multi-Head Attention】
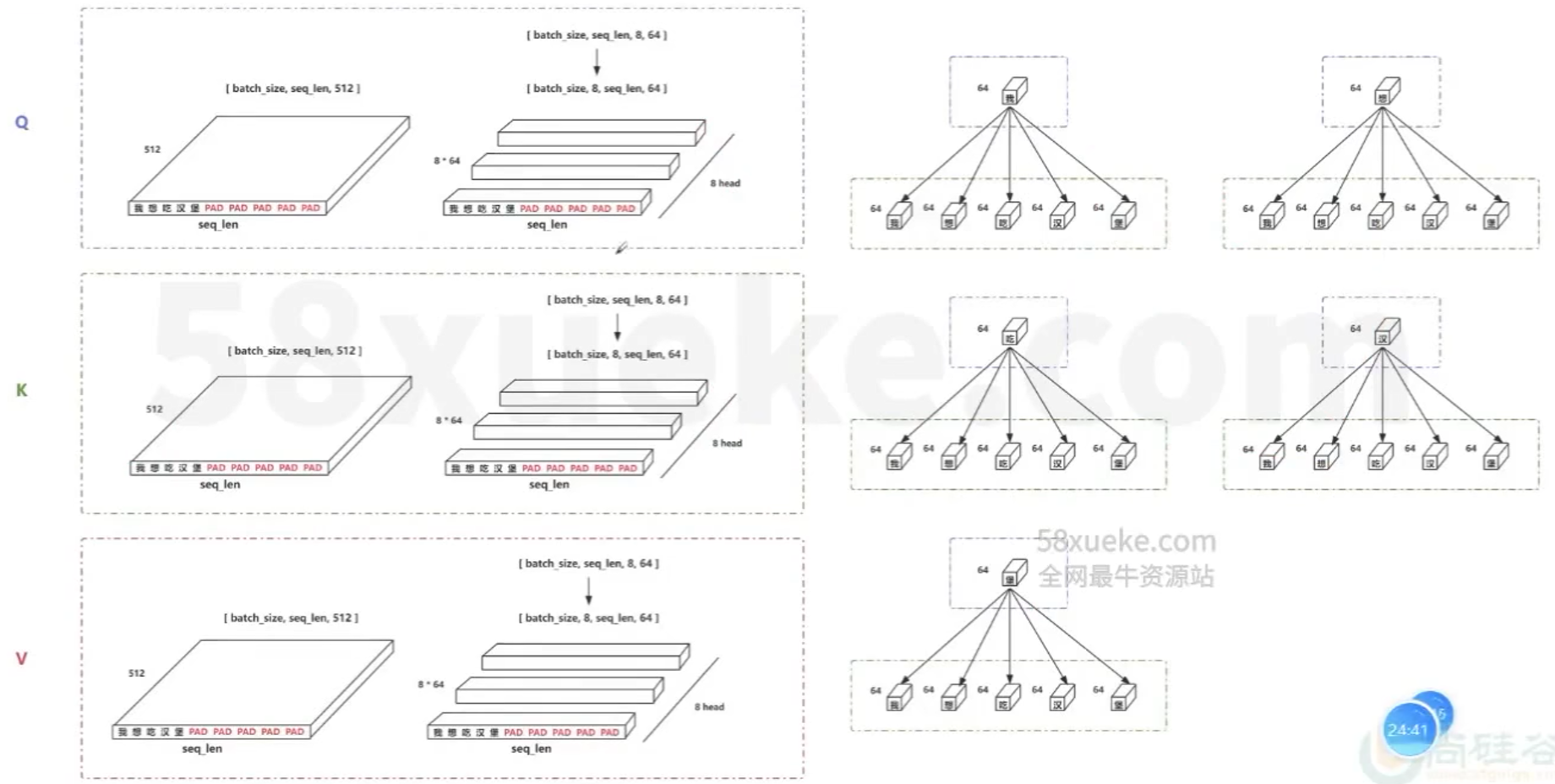
- 所谓多头,是将线性变换之后的QKV切分为H份,然后对每一份进行后续的self-attention操作,可以理解成将高维向量拆分成了H个低维向量,在H个低维空间里求解各自的self-attention

- 所谓多头,是将线性变换之后的QKV切分为H份,然后对每一份进行后续的self-attention操作,可以理解成将高维向量拆分成了H个低维向量,在H个低维空间里求解各自的self-attention
- 相当于是在原来的一个768维空间里求任意两个字符的相关度,变成在12个64维空间里求相关度,最后将12个64维拼接在一起变成768维的相关度
- 相当于是从不同的角度(12个角度)去研究任意两个字符之间的相关度,这比从一个角度去研究的结果更多
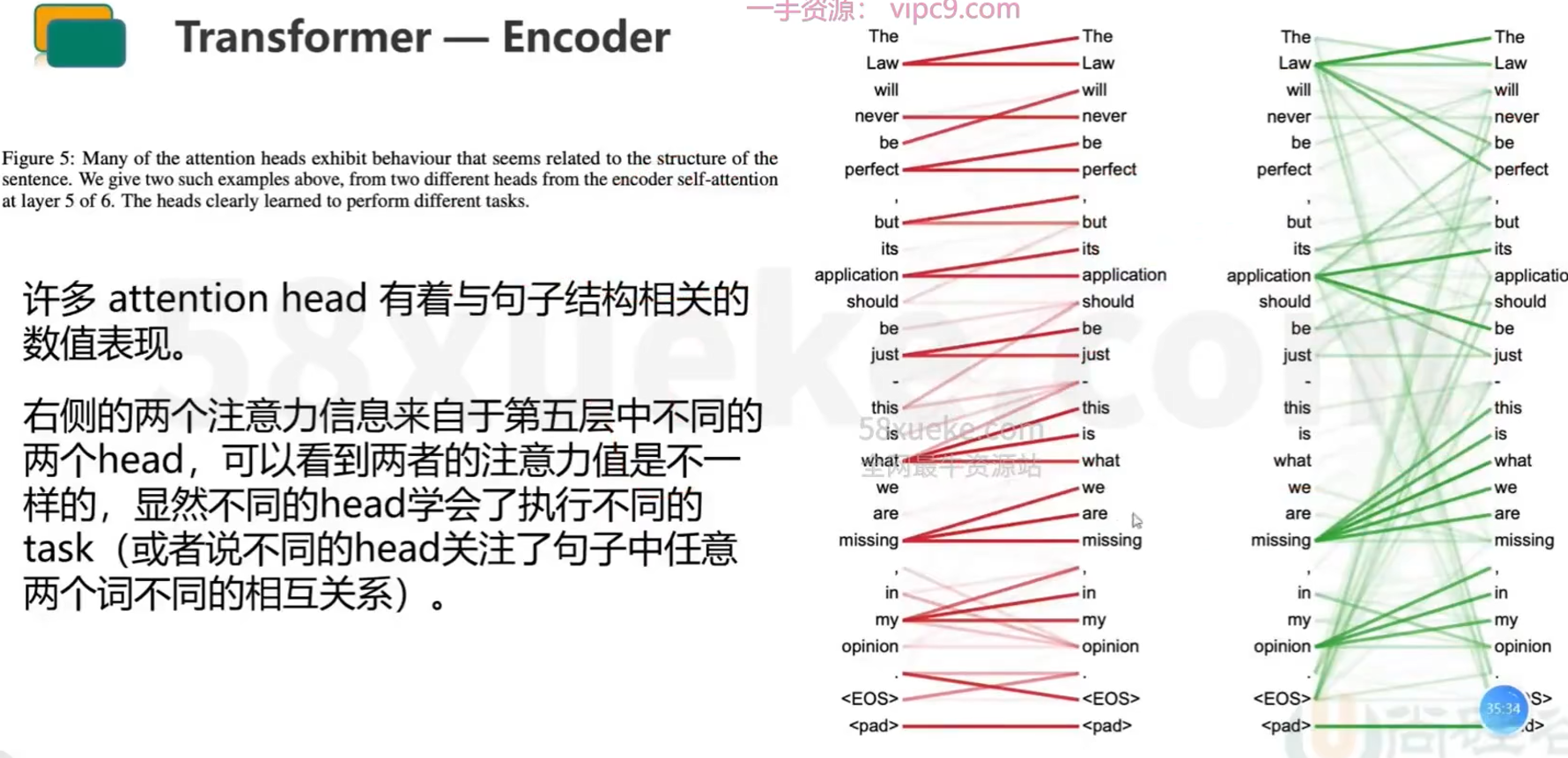
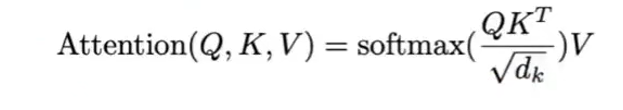
- 【Multi-Head Attention】
-
Add & Norm

-
Feed Forword

- Transformer Decoder

 浙公网安备 33010602011771号
浙公网安备 33010602011771号