
Spring AI Alibaba 1.0.0-M5.1 Learn
Spring AI Alibaba 1.0.0-M5.1
gitee仓库地址: https://gitee.com/little_lunatic/as-assistant
概述
Spring AI Alibaba 是 Spring AI 生态对阿里云大模型平台的集成实现,当前 1.0.0-M6.1 版本主要支持:
- 通义千问(Qwen)大模型
- 通义万相(WanX)文生图模型
- 向量数据库操作
环境准备
依赖配置
<!-- pom.xml -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-alibaba-ai-spring-boot-starter</artifactId>
<version>1.0.0-M5.1</version>
</dependency>
阿里云配置
spring:
application:
name: ai-assistant
ai:
dashscope:
api-key: ${api-key}
chat:
options:
model: qwen-max
server:
port: 80
servlet:
encoding:
charset: 'UTF-8'
enabled: true
force: true
快速开始
基础聊天示例
同步响应
@RestController
@RequiredArgsConstructor
public class ChatController {
private final ChatClient.Builder chatClient;
@GetMapping("/chat")
public String generate(@RequestParam String message) {
return chatClient.build().prompt(s).call().content();
}
}
流式响应
@RestController
@RequiredArgsConstructor
public class ChatController {
private final ChatClient.Builder chatClient;
@GetMapping("/chat")
public Flux<String> generate(@RequestParam("s") String s){
return chatClient.build().prompt(s).stream().content();
}
}
默认设置
defaultSystem
当 ChatClient 与模型交互时都会自动携带这条 system message,用户只需要指定 user message 即可。
// 方式一,固定默认消息
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a Pirate")
.build();
}
// 方式二,使用模板
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
}
@RequestMapping("demo33")
public Flux<String> demo33(@RequestParam("s") String s, @RequestParam("voice") String voice){
return chatClient.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build()
.prompt(s)
.system(ps-> ps.param("voice", voice))
.stream()
.content();
}
检索增强生成(RAG)
向量数据库存储的是 AI 模型不知道的数据,当用户问题被发送到 AI 模型时,QuestionAnswerAdvisor 会在向量数据库中查询与用户问题相关的文档。
来自向量数据库的响应被附加到用户消息 Prompt 中,为 AI 模型生成响应提供上下文
public Flux<String> demo5(@RequestParam("s") String s){
return chatClient.build()
.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.builder().build()))
.user(s)
.stream()
.content();
}
@Bean
public CommandLineRunner commandLineRunner(VectorStore vectorStore,
@Value("classpath:rag/terms-of-service.txt") Resource termsOfServiceDocs) {
return args -> {
// Ingest the document into the vector store
vectorStore.write(new TokenTextSplitter()
.transform(new TextReader(termsOfServiceDocs).read())
);
};
}
/**
* 向量数据库,也可以使用redis等作为向量数据库
*
* @param embeddingModel 嵌入模型
* @return
*/
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel){
return SimpleVectorStore.builder(embeddingModel).build();
}
聊天记忆
目前提供两种实现方式 InMemoryChatMemory、CassandraChatMemory,分别为聊天对话历史记录提供内存存储和 time-to-live 类型的持久存储。
创建一个包含 time-to-live 配置的 CassandraChatMemory
CassandraChatMemory.create(CassandraChatMemoryConfig
.builder().withTimeToLive(Duration.ofDays(1)).build());
以下 Advisor 实现使用 ChatMemory 接口来使用对话历史记录来增强(advice)Prompt
MessageChatMemoryAdvisor:内存被检索并作为消息集合添加到提示中PromptChatMemoryAdvisor:检索内存并将其添加到提示的系统文本中。VectorStoreChatMemoryAdvisor:构造函数VectorStoreChatMemoryAdvisor(VectorStore vectorStore, String defaultConversationId, int chatHistoryWindowSize)允许您指定要从中检索聊天历史记录的 VectorStore、唯一的对话 ID、要检索的聊天历史记录的大小(以令牌大小为单位)。
public Flux<String> demo4(@RequestParam("s") String s){
return chatClient
.defaultAdvisors(
new PromptChatMemoryAdvisor(chatMemory),// InMemoryChatMemory
new QuestionAnswerAdvisor(vectorStore, SearchRequest.builder().build())
)
.build()
.prompt()
.user(s)
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, 1)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.stream().content();
}
日志记录
SimpleLoggerAdvisor 是一个用于记录 ChatClient 的 request 和 response 数据 Advisor,这对于调试和监控您的 AI 交互非常有用。
要启用日志记录,请在创建 ChatClient 时将 SimpleLoggerAdvisor 添加到 Advisor 链中。建议将其添加到链的末尾:
ChatResponse response = ChatClient.create(chatModel).prompt()
.advisors(new SimpleLoggerAdvisor())
.user("Tell me a joke?")
.call()
.chatResponse();
要查看日志,请将 Advisor 包的日志记录级别设置为 DEBUG:
logging:
level:
# 根据你的需要,指定包下的日志级别,尽可能让日志范围小一点
org.springframework.ai.chat.client.advisor: debug
com.lunatic: debug
对话模型(Chat Model)
-
ChatModel,文本聊天交互模型,支持纯文本格式作为输入,并将模型的输出以格式化文本形式返回。 -
ImageModel,接收用户文本输入,并将模型生成的图片作为输出返回。 -
AudioModel,接收用户文本输入,并将模型合成的语音作为输出返回。
嵌入模型 (Embedding Model)
嵌入(Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
嵌入模型(EmbeddingModel)是嵌入过程中采用的模型。当前EmbeddingModel的接口主要用于将文本转换为数值向量。
@GetMapping("/demo7")
public Map embed(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
EmbeddingResponse embeddingResponse = embeddingModel.embedForResponse(List.of(s));
return Map.of("embedding", embeddingResponse);
}
工具(Function Calling)
“工具(Tool)”或“功能调用(Function Calling)”允许大型语言模型(LLM)在必要时调用一个或多个可用的工具,这些工具通常由开发者定义。工具可以是任何东西:网页搜索、对外部 API 的调用,或特定代码的执行等
自定义函数需要提供一个 name、description 和 function call signature,以便模型知道函数能做什么、期望的输入参数。
Spring AI 使这一过程变得简单,只需定义一个返回 java.util.Function 的 @Bean 定义,并在调用 ChatModel 时将 bean 名称作为选项进行注册。
定义&注册函数
@Description("获取天气") // 或者使用@JsonClassDescription 注释WeatherService.Request来提供函数描
@Bean
public Function<WeatherService.Request, WeatherService.Response> weatherFunction(WeatherService weatherService) {
return weatherService::getWeather;
}
@Service
public class WeatherService {
public Response getWeather(Request request) {
String weather = "阴天雨天想你的一天。";
return new Response(String.format("天气:%s, 城市:%s", weather, request.city));
}
public Response getTemper(Request request) {
String temper = "38℃";
return new Response(String.format("气温:%s, 城市:%s", temper, request.city));
}
public Response orderTik(Request request) {
String orderId = UUID.randomUUID().toString();
return new Response(String.format("订购成功, 目的城市:%s, 订单号:%s", request.city, orderId));
}
// @JsonClassDescription("获取本地天气")
@JsonInclude(JsonInclude.Include.NON_NULL)
public record Request(
//这里的JsonProperty将转换为function的parameters信息, 包括参数名称和参数描述等
/*
{
"orderId": {
"type": "string",
"description": "订单编号, 比如1001***"
},
"userId": {
"type": "string",
"description": "用户编号, 比如2001***"
}
}
*/
@JsonProperty(required = true, value = "city") @JsonPropertyDescription("城市,比如北京") String city) {
}
public record Response(String description) {
}
}
public Flux<String> demo8(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return chatClient.defaultFunctions("weatherFunction", "getTemper","orderTik")
.build().prompt().user(s).stream().content();
}
模型上下文协议MCP(Model Context Protocol)
Spring AI MCP
Spring AI MCP 为模型上下文协议提供 Java 和 Spring 框架集成。它使 Spring AI 应用程序能够通过标准化的接口与不同的数据源和工具进行交互,支持同步和异步通信模式。
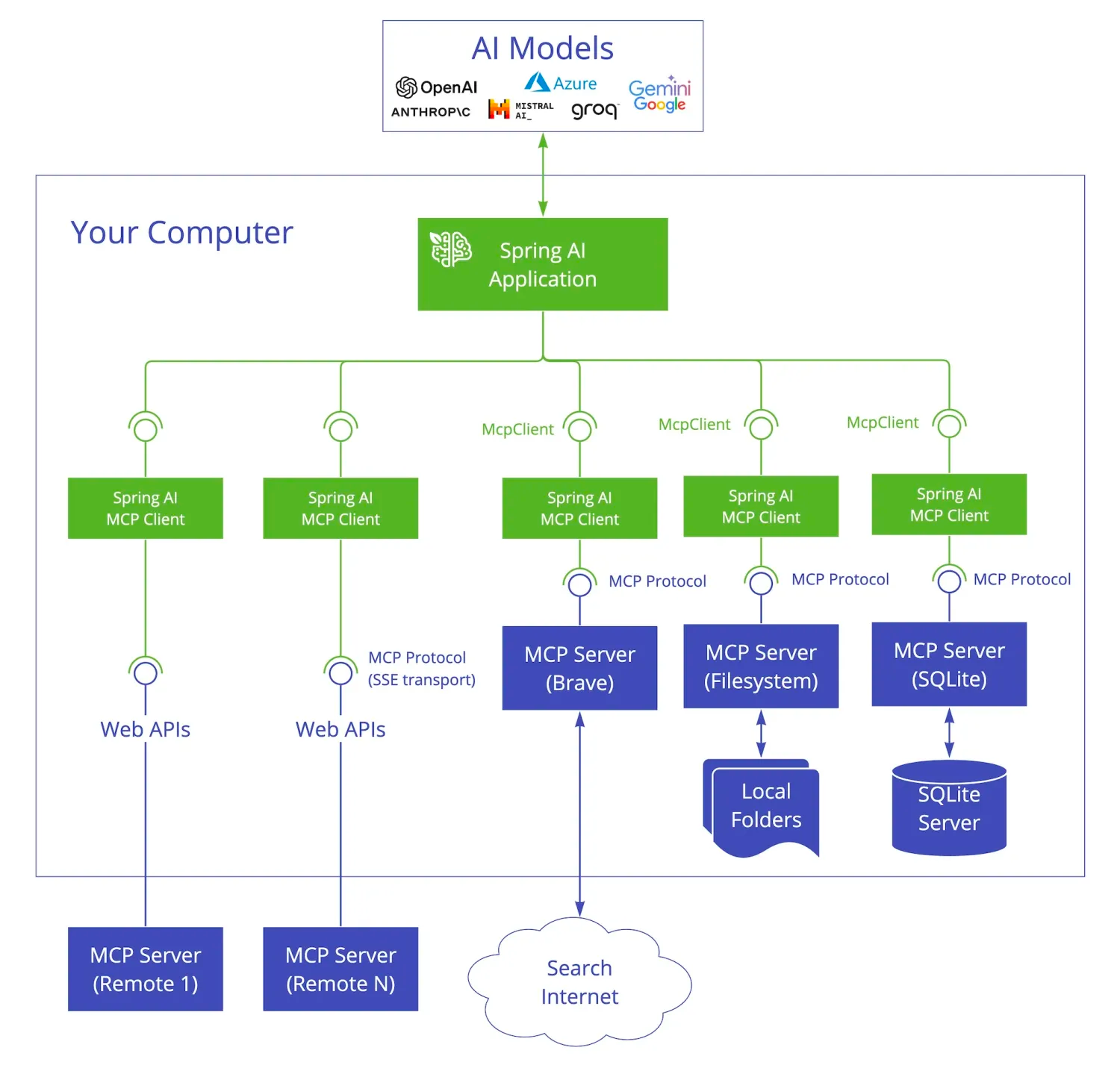
Spring AI MCP 采用模块化架构,包括以下组件:
- Spring AI 应用程序:使用 Spring AI 框架构建想要通过 MCP 访问数据的生成式 AI 应用程序
- Spring MCP 客户端:MCP 协议的 Spring AI 实现,与服务器保持 1:1 连接
- MCP 服务器:轻量级程序,每个程序都通过标准化的模型上下文协议公开特定的功能
- 本地数据源:MCP 服务器可以安全访问的计算机文件、数据库和服务
- 远程服务:MCP 服务器可以通过互联网(例如,通过 API)连接到的外部系统
RAG(检索增强生成)
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术范式。RAG技术就像给AI装上了「实时百科大脑」,通过先查资料后回答的机制,让AI摆脱传统模型的”知识遗忘”困境。
Spring AI 标准接口实现 RAG
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();
// 生成一个机器人产品说明书的文档
List<Document> documents = List.of(
new Document("产品说明书:产品名称:智能机器人\n" +
"产品描述:智能机器人是一个智能设备,能够自动完成各种任务。\n" +
"功能:\n" +
"1. 自动导航:机器人能够自动导航到指定位置。\n" +
"2. 自动抓取:机器人能够自动抓取物品。\n" +
"3. 自动放置:机器人能够自动放置物品。\n"));
simpleVectorStore.add(documents);
return simpleVectorStore;
}
@GetMapping("/demo9")
public Flux<String> demo9(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return chatClient.defaultSystem("你将作为一名机器人产品的专家,对于用户的使用需求作出解答")
.build()
.prompt()
.user(s)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.stream()
.content();
}
Spring AI 高级RAG功能实现
Multi Query Expansion (多查询扩展)
能够自动生成多个相关的查询变体,从而提高检索的准确性和召回率。
@GetMapping("/demo10")
public String demo10(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
ChatClient.Builder builder = chatClient.defaultSystem("你是一位专业的室内设计顾问,精通各种装修风格、材料选择和空间布局。请基于提供的参考资料,为用户提供专业、详细且实用的建议。在回答时,请注意:\\n\" +\n" +
" \"1. 准确理解用户的具体需求\\n\" +\n" +
" \"2. 结合参考资料中的实际案例\\n\" +\n" +
" \"3. 提供专业的设计理念和原理解释\\n\" +\n" +
" \"4. 考虑实用性、美观性和成本效益\\n\" +\n" +
" \"5. 如有需要,可以提供替代方案");
// 构建查询扩展器, 用于生成多个相关的查询变体,以获得更全面的搜索结果
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(builder)
.includeOriginal(false) // 不包含原始查询
.numberOfQueries(10) // 生成3个查询变体
.build();
// 执行查询扩展, 将原始问题"请提供几种推荐的装修风格?"扩展成多个相关查询
List<Query> queries = queryExpander.expand(new Query("请提供几种推荐的装修风格"));
return queries.toString();
}
Query Rewrite (查询重写)
将用户的原始查询转换成更加结构化和明确的形式。这种转换可以提高检索的准确性,并帮助系统更好地理解用户的真实意图。
@GetMapping("/demo11")
public void demo11(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
ChatClient.Builder builder = chatClient;
// 创建一个模拟用户学习AI的查询场景
Query query = new Query("我正在学习人工智能,什么是大语言模型?");
// 创建查询重写转换器
QueryTransformer queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
System.out.println(transformedQuery.text());
}
Query Translation (查询翻译)
它能够将用户的查询从一种语言翻译成另一种语言。
// 创建查询翻译转换器,设置目标语言为中文
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(builder)
.targetLanguage("中文") // 设置目标语言为中文
.build();
Context-aware Queries (上下文感知查询)
在实际对话中,用户的问题往往依赖于之前的对话上下文。
@GetMapping("/demo12")
public void demo12(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
ChatClient.Builder builder = chatClient;
// QueryTransformer用于将带有上下文的查询转换为完整的独立查询
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
// 这个例子模拟了一个房地产咨询场景,用户先问小区位置,再问房价
Query query = Query.builder()
.text("那这个小区的二手房均价是多少?") // 当前用户的提问
.history(new UserMessage("深圳市南山区的碧海湾小区在哪里?"), // 历史对话中用户的问题
new AssistantMessage("碧海湾小区位于深圳市南山区后海中心区,临近后海地铁站。")) // AI的回答
.build(); // 将模糊的代词引用("这个小区")转换为明确的实体名称("碧海湾小区")
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
System.out.println(transformedQuery.text());
}
文档检索 (Document Retriever)
文档检索(DocumentRetriever)是一种信息检索技术,旨在从大量未结构化或半结构化文档中快速找到与特定查询相关的文档或信息。文档检索通常以在线(online)方式运行。
@Bean
public DocumentRetriever documentRetriever(DashScopeApi dashScopeApi) {
return new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder()
.withIndexName("spring-ai知识库")
.build());
}
@GetMapping("/ai/retrieve")
public List<Document> retrieve(@RequestParam(value = "m", defaultValue = "What's spring ai") String m) {
return this.documentRetriever.retrieve(Query.builder().text(m).build());
}
格式化输出(Structured Output)
在 LLM 调用之前,转换器会将期望的输出格式附加到 prompt 中,为模型提供生成所需输出结构的明确指导,这些指令充当蓝图,塑造模型的响应以符合指定的格式。
当前 Spring AI 提供的 Converter 实现有 AbstractConversionServiceOutputConverter, AbstractMessageOutputConverter, BeanOutputConverter, MapOutputConverter and ListOutputConverter。
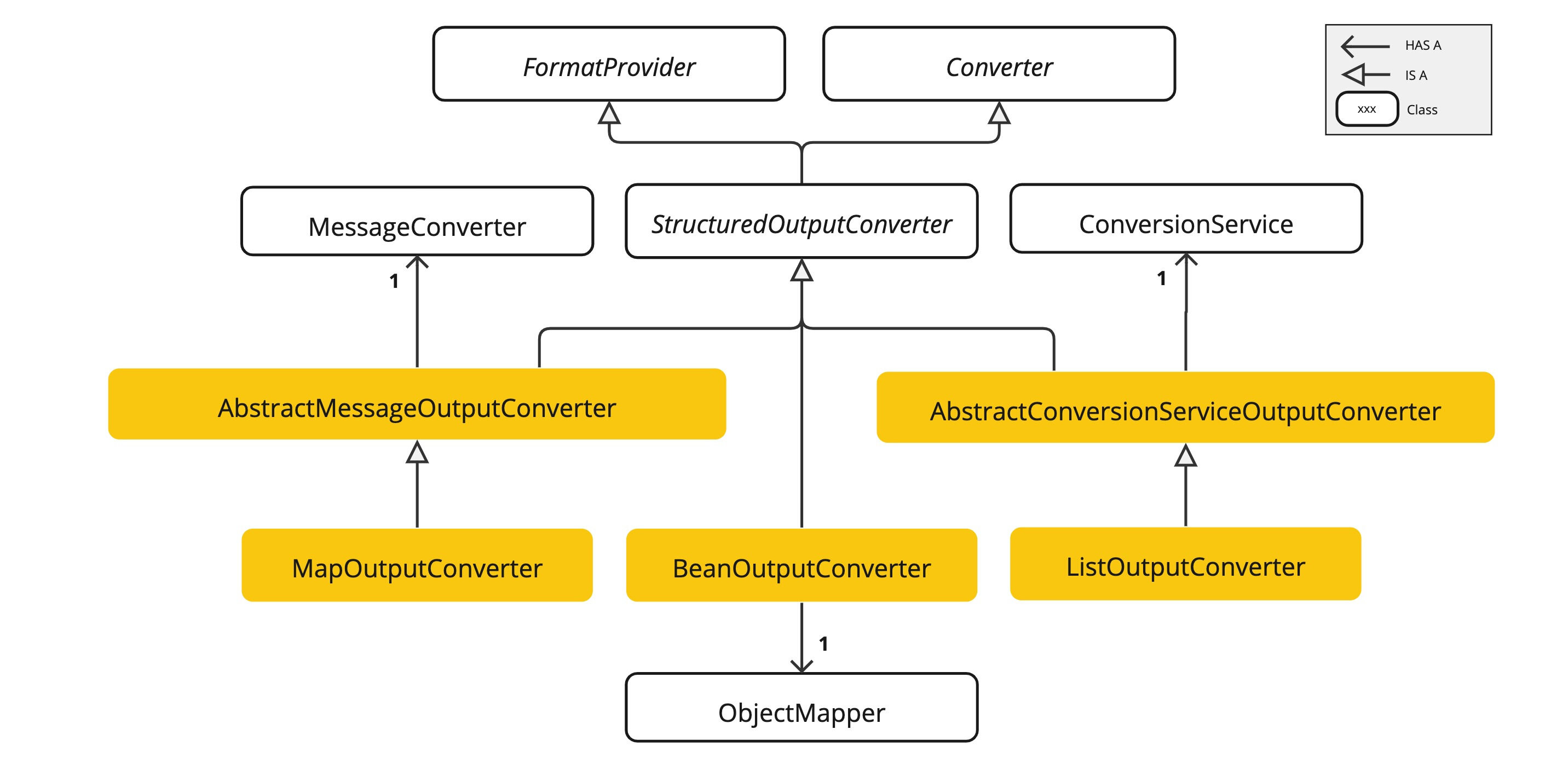
BeanOutputConverter- 使用指定的 Java 类(例如 Bean)或 ParameterizedTypeReference 配置,此转换器指示 AI 模型生成符合 DRAFT_2020_12 的 JSON 响应,JSON 模式派生自指定的 Java 类,随后,它利用 ObjectMapper 将 JSON 输出反序列化为目标类的 Java 对象实例。MapOutputConverter- 该实现指导 AI 模型生成符合 RFC8259 的 JSON 响应,此外,它还包含一个转换器实现,该实现利用提供的 MessageConverter 将 JSON 负载转换为 java.util.Map<String, Object> 实例。ListOutputConverter- 该实现指导 AI 模型生成逗号分隔的格式化输出,最终转换器将模型文本输出转换为 java.util.List。
public record ActorFilms(String code, List<String> msg) {
}
@GetMapping("/demo13")
public ActorFilms demo13(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return ChatClient.create(chatModel).prompt()
.user(u -> u.text("Generate the filmography of 5 movies for {actor}.")
.param("actor", "Tom Hanks"))
.call()
.entity(ActorFilms.class);
}
@GetMapping("/demo14")
public List<ActorFilms> demo14(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return ChatClient.create(chatModel).prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<>() {
});
}
@GetMapping("/demo15")
public Map<String, Object> demo15(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return ChatClient.create(chatModel).prompt()
.user(u -> u.text("Provide me a List of {subject}")
.param("subject", "an array of numbers from 1 to 9 under their key name 'numbers'"))
.call()
.entity(new ParameterizedTypeReference<>() {
});
}
@GetMapping("/demo16")
public List<String> demo16(@RequestParam(value = "s", defaultValue = "Tell me a joke") String s) {
return ChatClient.create(chatModel).prompt()
.user(u -> u.text("List five {subject}")
.param("subject", "ice cream flavors"))
.call()
.entity(new ListOutputConverter(new DefaultConversionService()));
}
向量存储(Vector Store)
向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。
Spring AI 提供了一个抽象化的 API,通过 VectorStore 接口与向量数据库进行交互。
要将数据插入 VectorStore,应先将其封装在Document对象中。Document类封装了来自数据源(如 PDF 或 Word 文档)的内容,并将文本表示为字符串。
@Bean
public DashScopeCloudStore dashScopeCloudStore(DashScopeApi dashScopeApi) {
return new DashScopeCloudStore(
dashScopeApi, new DashScopeStoreOptions("spring-ai知识库"));
};
@RestController
public class StoreController {
private final DashScopeCloudStore dashScopeCloudStore;
@Autowired
public StoreController(DashScopeCloudStore dashScopeCloudStore) {
this.dashScopeCloudStore = dashScopeCloudStore;
}
@GetMapping("/ai/search")
public List<Document> store(@RequestParam(value = "message", defaultValue = "What's spring ai") String message) {
return this.dashScopeCloudStore.similaritySearch(message);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号