


支持大模型的小模型
https://www.arxiv.org/pdf/2408.12748 (SLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection )

平衡会话 AI 幻觉检测中的延迟、可解释性和一致性
介绍
大型语言模型(llm)在实时任务(如同步的会 话 ui)中与延迟作斗争。
当额外的开销增加时,比如检查幻觉,那么这个问题就会加剧。 因此,微软研究院提出了一个框架,利用小语言模型(SLM)作为初始检测器, LLM 作为约束推理器,为任何检测到的幻觉生成详细的解释。 目的是通过引入将 llm 生成的解释与 SLM 决策相结合的提示技术,优化实时、可解释的幻觉检测。
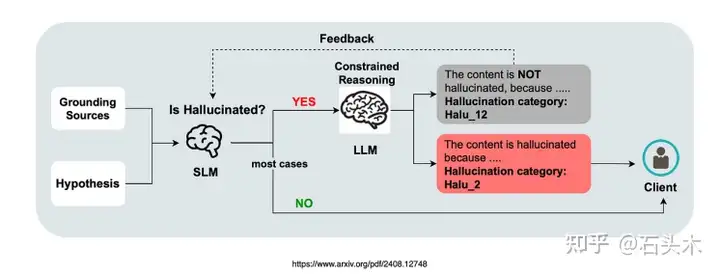
考虑到上图,它展示了用 LLM 作为约束推理器的幻觉检测……
初始检测:将grounding sources和假设对输入到小型语言模型(SLM)分类器中。
无幻觉:如果未检测到幻觉,则直接将“无幻觉”结果发送给客户端。
检测到幻觉:如果 SLM 检测到幻觉,基于 llm 的约束推理器会介入来解释 SLM 的决定。
一致性检查:如果推理者同意 SLM 的幻觉检测,则此信息连同原始假设一 起发送给客户。
差异:如果存在分歧,可能存在问题的假设要么被过滤掉,要么被用作改进 SLM 的反馈。
更多关于微软的方法
鉴于在实际使用中很少出现幻觉,使用llm对幻觉文本进行推理的平 均时间和成本是可控的。
这种方法利用了llm现有的推理和解释能力,消除了对大量特定领域 数据和昂贵的微调的需要。
虽然llm传统上被用作端到端解决方案,但最近的方法已经探索了它 们通过潜在特征解释小分类器的能力。
SLM 和 LLM 协议
这种实现的一个挑战是 SLM 的决定和 LLM 的解释之间可能存在差异。
• 这项工作引入了一种用于幻觉检测的约束推理器,平衡了延迟性和可解 释性。
• 提供对上下游一致性的全面分析。
• 提供切实可行的解决方案,以提高检测和解释之间的一致性。
• 展示了在多个开源数据集上的有效性。
总之
• 这项研究的重点是为会话 ui 引入护栏和检查。
• 当与真实用户交互时,结合人在循环的方法有助于通过审查对话进行数 据注释和持续改进。
• 它还增加了发现、观察和解释的元素,提供了对幻觉检测有效性的见解。
• 本研究中呈现的架构提供了对未来的一瞥,展示了一种更加协调的方法, 其中多个模型协同工作。
• 该研究还解决了当前的挑战,如成本、延迟以及对任何额外开销进行批 判性评估的需求。
• 使用小型语言模型是有利的,因为它允许使用开源模型,从而降低了成 本,提供了托管灵活性,并提供了其他好处。
• 此外,这种架构可以异步应用,框架在对话发生后对其进行审查。然后, 这些人工监督的审查可用于微调 SLM 或执行系统更新.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号