机器学习系统设计的这个问题由两个主要构建块组成:
1-离线组件:该组件侧重于训练和验证推荐模型。
2-在线组件:该组件负责实时生成(推断)推荐。
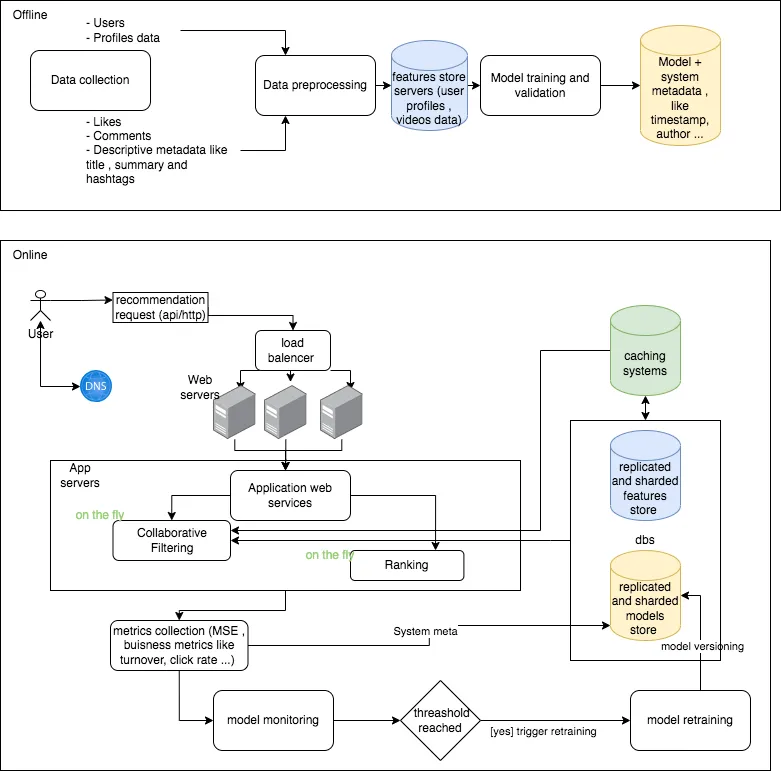
最初的离线训练过程遵循经典的数据科学生命周期,从数据收集和转换为特征开始,到模型构建和验证结束。这些步骤的结果是捕获特征并存储在特征存储中的数据集,以及保存在 Blob 存储介质(例如 S3 等分布式文件系统)中的模型。
本文特别关注在线组件。例如,在此子系统中,用户通过 REST API 提交请求。然后,该请求被转发到包含推荐功能的应用服务器。在我们的架构中,我们建议利用负载均衡器来为服务层提供更高的可扩展性、性能、可靠性和冗余。水平扩展这一层使我们能够处理来自数十亿用户的请求,并通过最小化吞吐量来缩短响应时间。
如图架构所示,推荐模块由两个组件组成:(i) 内容过滤 (CF) 算法,根据每个用户的个人资料和历史观看数据识别相关视频,以及 (ii) 分配分数的排名算法到推荐的视频。
内容过滤 (CF) 中采用的技术范围从基本方法(例如简单的相似性匹配)到涉及深度神经网络模型的更高级方法。在这个特定的示例中,我们重点关注使用上面段落中暗示的模型。在推理时,CF 算法从模型存储中读取模型,并从特征存储中读取其他相关特征(例如用户个人资料数据),并预测与用户及其观看历史匹配的最佳电影。在此架构中,我们利用内存缓存系统来减少访问较慢的存储层时可能出现的数据检索延迟。
生成推荐后,算法会将业务指标(例如营业额和点击率)以及系统级元数据(例如推理时间戳及其响应时间)发送到模型存储。这些指标有助于 (i) 协助触发模型重新训练的决策过程和 (ii) 为监控仪表板提供数据。可以及时触发模型的重新训练(例如,每日模型重新训练)。它还可能是由于数据漂移和概念漂移事件达到某个阈值而导致的。
https://asmazgo.github.io/machine-learning/feature/2023/06/01/recommender-system.html#topofpage



 浙公网安备 33010602011771号
浙公网安备 33010602011771号