
Spark学习(二) -- Spark整体框架
标签(空格分隔): Spark
还记得上次的wordCount程序嘛?通过这个小程序,我们来一窥Spark的框架是什么样子的。
sc.textFile("/usr/local/Cellar/apache-spark/1.3.0/README.md").flatMap(line => line.split(" ")).map(w => (w, 1)).reduceByKey(_+_).foreach(println)
整个单词统计的过程可以分为4个阶段:1)读取文件;2)单词分割;3)单词计数;4)单词归并。前三步都是非常容易并行的,但最后一步的并行度并不是很高。
RDD
将上面的单词计数操作用另一种形式表示:
Data1 ---Operation1---> Data2 ---Operation2---> Data3 ...... -->DataN
所以,整个过程其实就是在不断的进行数据输入和数据处理。
RDD(Resilient Distributed Dataset),弹性分布式数据集,用来包装数据输入和数据处理,其主要特点是:
- 数据全集被分割为多个正相交的子集,每个子集可以被派发到任一计算节点进行处理;
- 计算的中间结果会被保存。出于可靠性,同一个计算结果会被保存于多个计算节点;
- 如果其中某一数据子集在处理中出现问题,针对该子集的处理会被重新调度进而重新处理。
Operation
Operation有两种类型:Transformation和Action。
- Transformation是领取任务的过程;
- Action则是真正触发执行的过程。
Spark的运行框架
1. 作业提交
Spark在接收到提交的作业后,会进行如下处理:
- RDD之间的依赖性分析。RDD之间形成一个有向无环图,这个依赖关系的分析和判断由DAGScheduler负责;
- 根据DAG的分析结果将一个作业分成多个Stage。划分Stage的一个主要依据就是当前的计算因子输入是否是确定的,如果是则划分在一个Stage中;
- DAGScheduler确定完Stage之后,会向TaskScheduler提交任务集,而TaskScheduler负责将这些任务一一分到集群的计算节点。
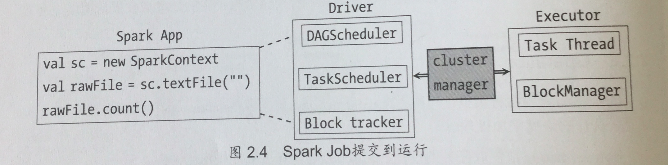
2. 集群节点的构成
Spark集群由4个节点构成:Driver, Master, Worker, Executor.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号