
Kubernetes集群均衡器Descheduler
在介绍 Kubernetes 集群均衡器之前我们还是非常有必要再来回顾下 kube-scheduler 组件的概念。我们知道基本上所有的分布式系统都需要一个流程或应用来调度集群中的任务来执行,同样 Kubernetes 也需要这样一个调度器来执行任务,我们熟知的 kube-scheduler 组件就是扮演这个角色的,该组件是作为 Kubernetes 整个控制面板的一部分来运行的,并监听所有未分配节点新创建的 Pod,为其选择一个最合适的节点绑定运行。kube-scheduler 是如何来选择最合适的节点的呢?
一、调度器
整个调度器执行调度的过程需要两个阶段:过滤 和 打分。
过滤:找到所有可以满足 Pod 要求的节点集合,该阶段属于强制性规则,满足要求的节点集合会输入给第二阶段,如果过滤处理的节点集合为空,则 Pod 将会处于Pending状态,期间调度器会不断尝试重试,直到有节点满足条件。打分:该阶段对上一阶段输入的节点集合根据优先级进行排名,最后选择优先级最高的节点来绑定 Pod。一旦kube-scheduler确定了最优的节点,它就会通过绑定通知 APIServer。
根据 K8S 调度框架文档描述,在 K8S 调度框架中将调度过程和绑定过程合在一起,称之为调度上下文(scheduling context)。调度框架是 K8S 调度程序的一种新的可插拔调度框架,可以用来简化自定义调度程序,需要注意的是调度过程是同步运行的(同一时间点只为一个 Pod 进行调度),绑定过程可异步运行(同一时间点可并发为多个 Pod 执行绑定)。
下图展示了调度框架中的调度上下文及其中的扩展点,一个扩展可以注册多个扩展点,以便可以执行更复杂的有状态的任务。
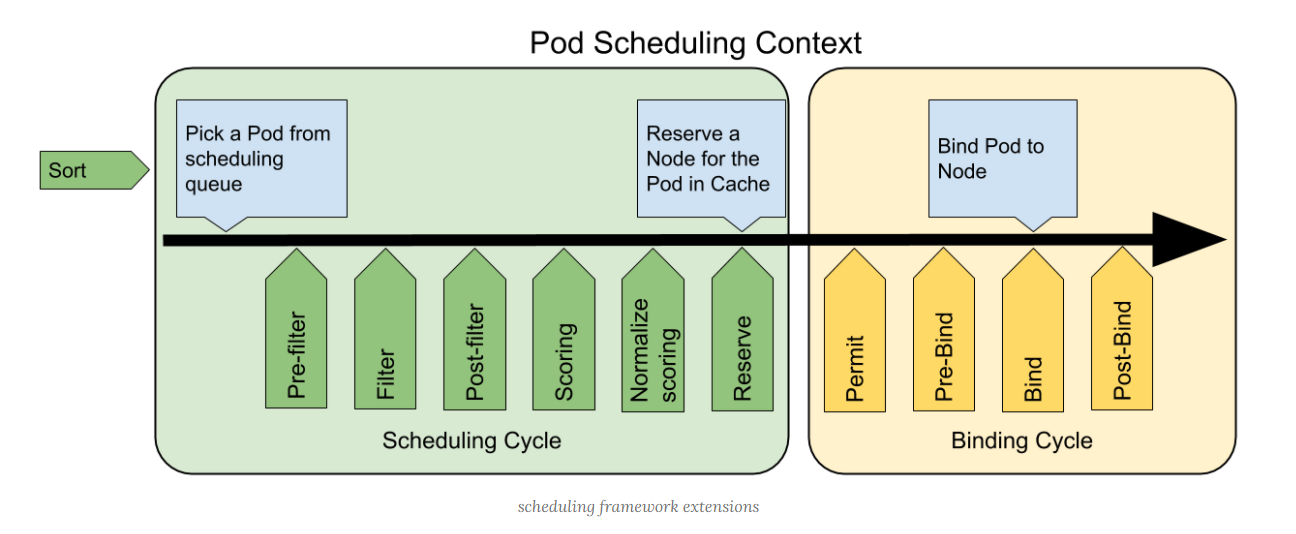
二、为什么需要集群均衡器
从 kube-scheduler 的角度来看,它通过各种算法计算出最佳节点去运行 Pod 是非常完美的,当出现新的 Pod 进行调度时,调度程序会根据其当时对 Kubernetes 集群的资源描述做出最佳调度决定。但是 Kubernetes 集群是非常动态的,由于整个集群范围内的变化,比如一个节点为了维护,我们先执行了驱逐操作,这个节点上的所有 Pod 会被驱逐到其他节点去,但是当我们维护完成后,之前的 Pod 并不会自动回到该节点上来,因为 Pod 一旦被绑定了节点是不会触发重新调度的,由于这些变化,Kubernetes 集群在一段时间内就出现了不均衡的状态,所以需要均衡器来重新平衡集群。
三、解决方案
要解决这个问题,当然我们可以去手动做一些集群的平衡,比如手动去删掉某些 Pod,触发重新调度就可以了,但是显然这是一个繁琐的过程,也不是解决问题的方式。要解决这个问题我们首先需要根据集群新的状态去确定有哪些 Pod 是需要被重新调度的,然后再重新找出最佳节点去调度这些 Pod。对于第二部分是不是 kube-scheduler 的打分阶段就已经解决了这个问题,所以我们只需要找出被错误调度的 Pod 然后将其移除就可以。原理是这样的吧?
这里就需要引出本文的主人公:Descheduler 项目了,该项目本身就是属于 kubernetes sigs 的项目,所以完全不用担心项目的问题。Descheduler 可以根据一些规则和配置策略来帮助我们重新平衡集群状态,当前项目实现了五种策略:RemoveDuplicates、LowNodeUtilization、RemovePodsViolatingInterPodAntiAffinity、RemovePodsViolatingNodeAffinity 和 RemovePodsViolatingNodeTaints,这些策略都是可以启用或者禁用的,作为策略的一部分,也可以配置与策略相关的一些参数,默认情况下,所有策略都是启用的。
1、RemoveDuplicates
该策略确保只有一个和 Pod 关联的 RS、RC、Deployment 或者 Job 资源对象运行在同一节点上。如果还有更多的 Pod 则将这些重复的 Pod 进行驱逐,以便更好地在集群中分散 Pod。如果某些节点由于某些原因崩溃了,这些节点上的 Pod 漂移到了其他节点,导致多个与 RS 或者 RC 关联的 Pod 在同一个节点上运行,就有可能发生这种情况,一旦出现故障的节点再次准备就绪,就可以启用该策略来驱逐这些重复的 Pod,当前,没有与该策略关联的参数,要禁用该策略,也很简单,只需要配置成 false 即可:
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "RemoveDuplicates": enabled: false
2、LowNodeUtilization
该策略查找未充分利用的节点,并从其他节点驱逐 Pod,以便 kube-scheudler 重新将它们调度到未充分利用的节点上。该策略的参数可以通过字段 nodeResourceUtilizationThresholds 进行配置。
节点的利用率不足可以通过配置 thresholds 阈值参数来确定,可以通过 CPU、内存和 Pod 数量的百分比进行配置。如果节点的使用率均低于所有阈值,则认为该节点未充分利用。
此外,还有一个可配置的阈值 targetThresholds,该阈值用于计算可从中驱逐 Pod 的那些潜在节点,对于所有节点 thresholds 和 targetThresholds 之间的阈值被认为是合理使用的,不考虑驱逐。targetThresholds 阈值也可以针对 CPU、内存和 Pod 数量进行配置。thresholds 和 targetThresholds 可以根据你的集群需求进行动态调整,如下所示示例:
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 20 "pods": 20 targetThresholds: "cpu" : 50 "memory": 50 "pods": 50

 浙公网安备 33010602011771号
浙公网安备 33010602011771号