Floor报错原理分析
最近开始打ctf了,发现好多sql注入都忘了,最近要好好复习一下。
基础知识:
floor(): 返回<=某数的最大整数 rand(): 产生随机数 rand(x): 每个x对应一个固定的值,但是如果连续执行多次值会变化,不过也是可预测的 floor报错payload: select count(*), floor(rand(0)*2) as a from information_schema.tables group by a;原理:
这个payload的重点在group by a,也就是group by floor(rand(0)*2)。首先,floor(rand(0)*2)的意思是随机产生0或1。虽说是随机,但是它是有规律可循的。看看上面解释的rand(x),对于rand(0)而言,虽说是随机数,但是它的值与执行rand(0)的次数是意义对应的,即每一次执行rand(0)得到的结果都是固定的。基本是011011...这个序列。 那它为什么会报错呢?先来解释一下count(*)与group by是如何共同工作的。首先,系统会建立一个虚拟表: 假设有表:

执行count(*) from ... group by age的过程中,会形成这样的虚拟表:

它是如何一步步形成这张表的呢?看上上图。由于group by的是age,第一次读取的就是18,在虚拟表中寻找是否已经存在18,由于表是空的,直接插入一条新数据,这时虚拟表变成这样:
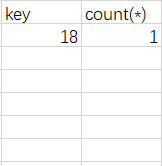
继续。下一个是19,由于虚拟表中依旧没有key为19的字段,故插入。再下一个是20,继续插入。再下一个又是20。由于已经有了20,故将key为20的字段的count(*)的值加1,变为了2。剩下的以此类推,最后形成了这个虚拟表:
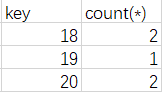
好了,现在group by原理讲完了。那究竟是如何将其与floor联合起来,进行floor报错呢?
先来回顾一下payload: select count(), floor(rand(0)2) as a from information_schema.tables group by a;
总体是一个group by语句,只不过这里group by的是floor(rand(0)2)。这是一个表达式,每次运算的值都是随机的。还记得我刚刚说的floor(rand(0)2)的值序列开头是011011...吧?ok,下面开始运算。
首先,建立一张虚拟表:
接着,进行group by floor(rand(0)2)。floor表达式第一次运算的值为0,在表中没有找到key为0的数据,故插入,在插入的过程中需要再取一次group by后面的值(即再进行一次floor运算,结果为1),取到了1,将之插入,并将count()置1。
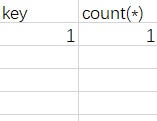
继续,再进行group by floor(rand(0)2)。进行floor表达式运算,由于这是第三次运算了,故值为1。刚好表中有了key为1的数据,故直接将其对应的count()加1即可。
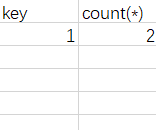
继续进行group by。这是第四次floor运算了,根据刚刚那个011011序列,这次的值为0,在表中找是否有key为0的数据。当然没有,故应当插入一条新记录。在插入时进行floor运算(就像第一次group by那样),这时的值为1,并将count(*)置1。可是你会说,虚拟表中已经有了key为1的数据了啊。对,这就是问题所在了。此时就会抛出主键冗余的异常,也就是所谓的floor报错。
利用:select count(), concat((select database()), '-', floor(rand(0)2)) as a from information_schema.tables group by a; #将select database()换成你想要的东西!~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号