
决策树
这里使用ID3算法构造决策树,引用http://my.oschina.net/dfsj66011/blog/343647的内容。
| outlook | temperature | humidity | windy | play |
| sunny | hot | high | false | no |
| sunny | hot | high | true | no |
| overcast | hot | high | false | yes |
| rainy | mild | high | false | yes |
| rainy | cool | normal | false | yes |
| rainy | cool | normal | true | no |
| overcast | cool | normal | true | yes |
| sunny | mild | high | false | no |
| sunny | cool | normal | false | yes |
| rainy | mild | normal | false | yes |
| sunny | mild | normal | true | yes |
| overcast | mild | high | true | yes |
| overcast | hot | normal | false | yes |
| rainy | mild | high | true | no |
(可以看到在决策树构建中,特征的取值需要时标称的)
现在我们使用ID3归纳决策树的方法来求解该问题。
预备知识:信息熵
熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:

通常以2为底数,所以信息熵的单位是bit。
补充两个对数去处公式:
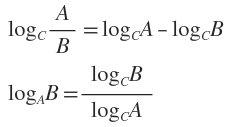
ID3算法
构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
在没有给定任何天气信息时,根据历史数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为:
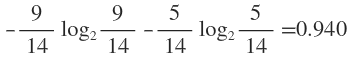
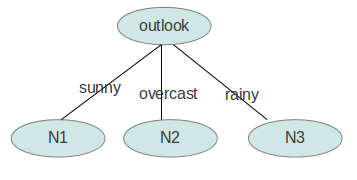
属性有4个:outlook,temperature,humidity,windy。我们首先要决定哪个属性作树的根节点。
对每项指标分别统计:在不同的取值下打球和不打球的次数。
下面我们计算当已知变量outlook的值时,信息熵为多少。
outlook=sunny时,2/5的概率打球,3/5的概率不打球。entropy=0.971
outlook=overcast时,entropy=0
outlook=rainy时,entropy=0.971
而根据历史统计数据,outlook取值为sunny、overcast、rainy的概率分别是5/14、4/14、5/14,所以当已知变量 outlook的值时,信息熵为:5/14 × 0.971 + 4/14 × 0 + 5/14 × 0.971 = 0.693
这样的话系统熵就从0.940下降到了0.693,信息增溢gain(outlook)为0.940-0.693=0.247
同样可以计算出gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
gain(outlook)最大(即outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。
********************************************************************************************
http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297405.html随机森林
这里只是准备简单谈谈基础的内容,主要参考一下别人的文章,对于随机森林与GBDT,有两个地方比较重要,首先是information gain,其次是决策树。这里特别推荐Andrew Moore大牛的Decision Trees Tutorial,与Information Gain Tutorial。Moore的Data Mining Tutorial系列非常赞,看懂了上面说的两个内容之后的文章才能继续读下去。
决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树:

就是将空间划分成下面的样子:

这样使得每一个叶子节点都是在空间中的一个不相交的区域,在进行决策的时候,会根据输入样本每一维feature的值,一步一步往下,最后使得样本落入N个区域中的一个(假设有N个叶子节点)
随机森林(Random Forest):
随机森林是一个最近比较火的算法,它有很多的优点:
- 在数据集上表现良好
- 在当前的很多数据集上,相对其他算法有着很大的优势
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
- 在创建随机森林的时候,对generlization error使用的是无偏估计
- 训练速度快
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
- 实现比较简单
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之 后,当有一个新的输 入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本 为那一类。
在建立每一棵决策树的过程中,有两点需要注意 - 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那 么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M 个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一 个分类。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个 精通于某一个窄领域 的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数 据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
随机森林的过程请参考Mahout的random forest 。这个页面上写的比较清楚了,其中可能不明白的就是Information Gain,可以看看之前推荐过的Moore的页面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号