102302141_易敏亮第三次数据采集作业
| 课程 | 数据采集 |
|---|---|
| 仓库 | https://gitee.com/lisu6/data_collect/tree/master/3 |
| 作业1当当多线程 | https://gitee.com/lisu6/data_collect/tree/master/3/dangdang |
| 作业2东方财富scrapy | https://gitee.com/lisu6/data_collect/tree/master/3/eastmoney_scrapy |
| 作业3中国银行网scrapy | https://gitee.com/lisu6/data_collect/tree/master/3/forex |
| 学号姓名 | 102302141 易敏亮 |
一、作业目标与要求回顾
- 图片爬取要求:指定网站(如中国气象网)爬取图片并保存到
images/,要求实现单线程与多线程,且受学号尾数控制的页数与图片总数限制。 - Scrapy 要求:掌握
Item与Pipeline的序列化输出;将抓取结果写入 MySQL 数据库并给出示例表结构。
二、作业①:图片爬取(设计与实现要点)
- 设计要点
- 控制爬取范围:提供
MAX_PAGES、MAX_IMAGES两个参数,分别控制最大页数与最大下载图片数(通过学号尾数设置)。 - 文件命名:用页面
title作为文件名,保留原扩展名,并把非法字符替换为下划线,避免 Windows 文件名错误。 - 并发下载:提供单线程顺序下载和基于
concurrent.futures.ThreadPoolExecutor的多线程下载实现。
- 关键代码(保存图片并以 title 命名)
import os
import requests
img_ext = os.path.splitext(img_url)[1] or '.jpg'
safe_title = ''.join(c if c.isalnum() else '_' for c in title)[:100]
save_dir = 'images'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, safe_title + img_ext)
resp = requests.get(img_url, headers=headers, timeout=10)
resp.raise_for_status()
with open(save_path, 'wb') as f:
f.write(resp.content)
print('已保存:', save_path)
- 多线程下载示例骨架
from concurrent.futures import ThreadPoolExecutor, as_completed
def download_task(args):
url, title = args
# 同上:构造 safe_title、save_path,然后写文件
with ThreadPoolExecutor(max_workers=8) as ex:
futures = [ex.submit(download_task, (url, title)) for url, title in to_download]
for fut in as_completed(futures):
fut.result()
- 运行与注意事项
- 在抓取时设置合理的
timeout与重试策略;避免短时间内大量请求,遵守robots.txt;Windows 上文件名长度控制在 100 字符以内。
三、作业②:爬取股票数据(Scrapy 实现)
- 项目结构
eastmoney_scrapy/
scrapy.cfg
eastmoney_scrapy/
spiders/eastmoney_spider.py
items.py
pipelines.py
settings.py
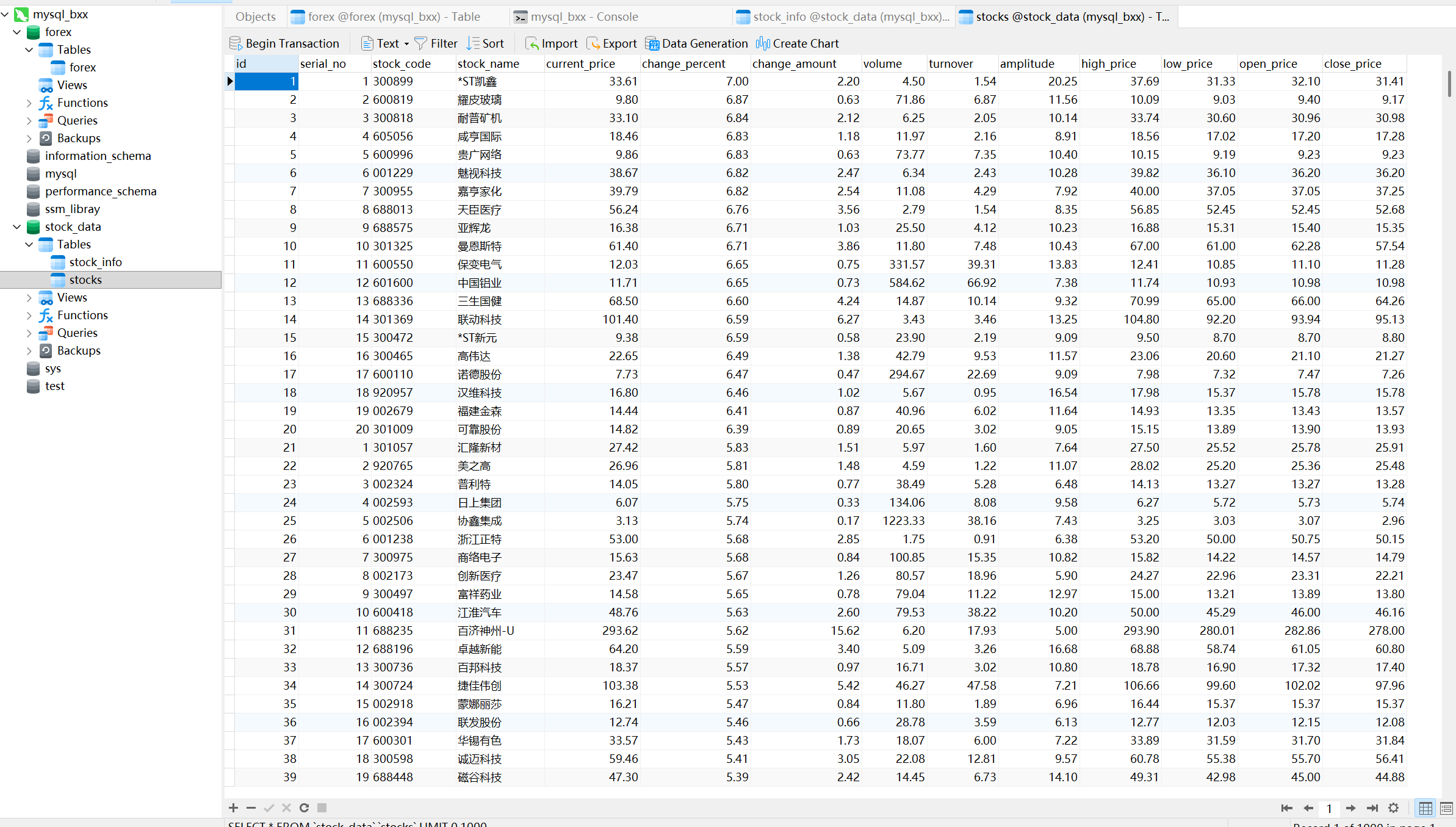
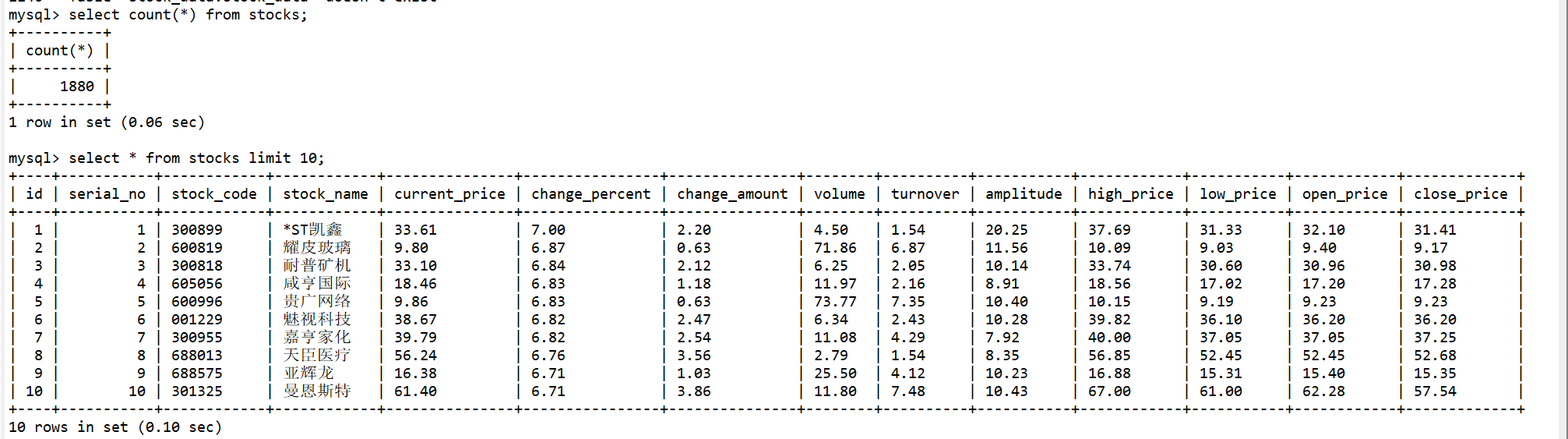
items.py示例
import scrapy
class StockItem(scrapy.Item):
stock_code = scrapy.Field()
stock_name = scrapy.Field()
latest_price = scrapy.Field()
change_percent = scrapy.Field()
change_amount = scrapy.Field()
volume = scrapy.Field()
amplitude = scrapy.Field()
high_price = scrapy.Field()
low_price = scrapy.Field()
open_price = scrapy.Field()
prev_close = scrapy.Field()
pipelines.py写入 MySQL 的关键片段
import pymysql
from itemadapter import ItemAdapter
class StockPipeline:
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
db=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
)
def open_spider(self, spider):
self.conn = pymysql.connect(host=self.host, user=self.user, password=self.password, database=self.db, charset='utf8mb4')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
a = ItemAdapter(item)
self.cursor.execute("""
INSERT INTO stocks (stock_code, stock_name, latest_price, change_percent, change_amount, volume, amplitude, high_price, low_price, open_price, prev_close)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
""", (
a.get('stock_code'), a.get('stock_name'), a.get('latest_price'), a.get('change_percent'), a.get('change_amount'), a.get('volume'), a.get('amplitude'), a.get('high_price'), a.get('low_price'), a.get('open_price'), a.get('prev_close')
))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
- MySQL 建表示例
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20),
stock_name VARCHAR(100),
latest_price DECIMAL(10,2),
change_percent DECIMAL(6,2),
change_amount DECIMAL(10,2),
volume DECIMAL(20,2),
amplitude DECIMAL(6,2),
high_price DECIMAL(10,2),
low_price DECIMAL(10,2),
open_price DECIMAL(10,2),
prev_close DECIMAL(10,2)
);
- 运行命令
cd eastmoney_scrapy
scrapy crawl eastmoney
四、作业③:爬取外汇数据(Scrapy 实现要点)
-
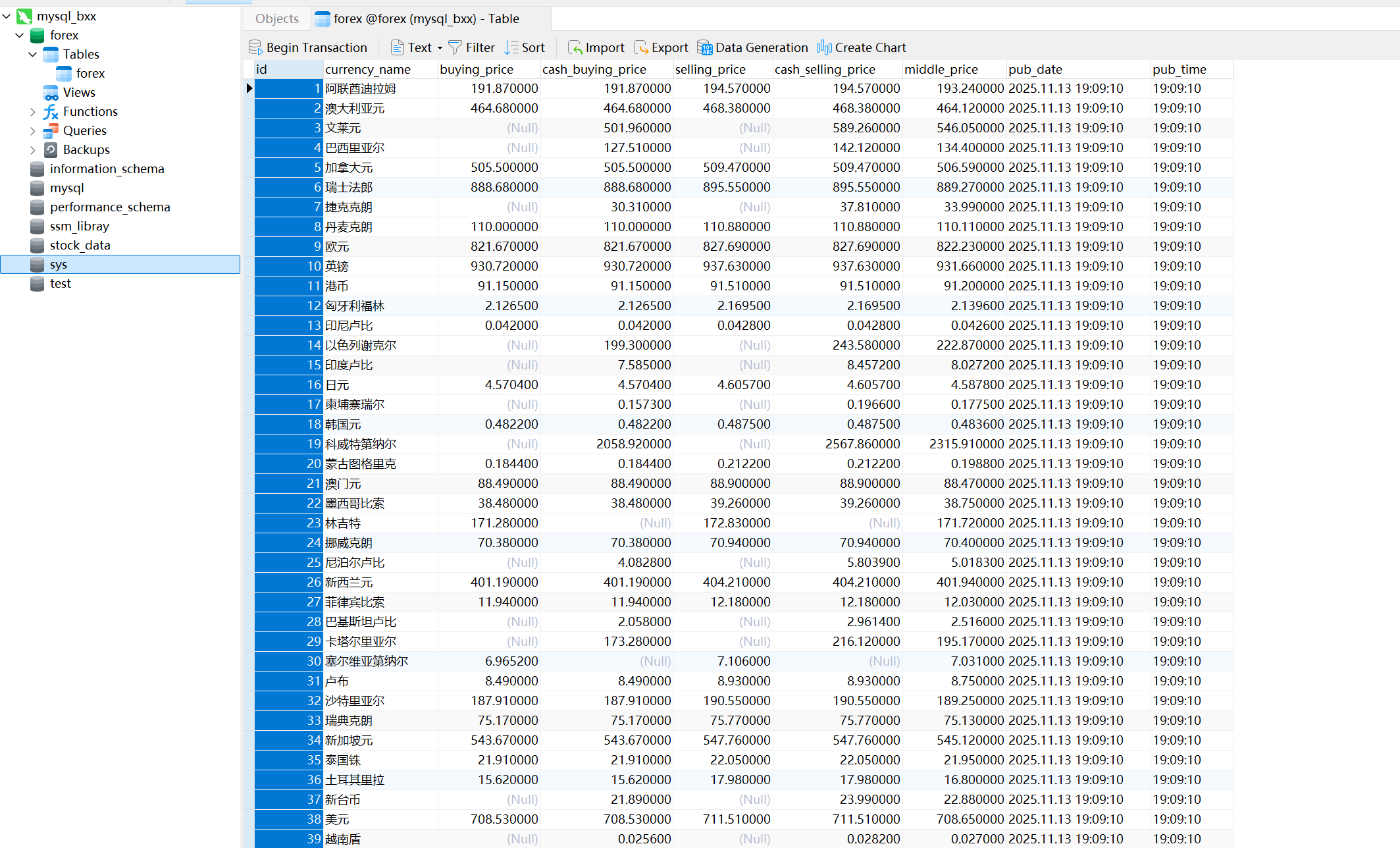
目标页面:
https://www.boc.cn/sourcedb/whpj/,页面包含外汇牌价表格。 -
items.py示例(外汇)
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
- forex_spider
import scrapy
from ..items import ForexItem
from scrapy.selector import Selector
class EastmoneySpider(scrapy.Spider):
name = "forex"
allowed_domains = ["boc.cn"]
custom_settings = {
'ITEM_PIPELINES': {
'forex.pipelines.ForexPipeline': 300,
}
}
urls_list = [
"https://www.boc.cn/sourcedb/whpj/index.html",
"https://www.boc.cn/sourcedb/whpj/index_1.html",
"https://www.boc.cn/sourcedb/whpj/index_2.html",
"https://www.boc.cn/sourcedb/whpj/index_3.html",
"https://www.boc.cn/sourcedb/whpj/index_4.html",
"https://www.boc.cn/sourcedb/whpj/index_5.html",
"https://www.boc.cn/sourcedb/whpj/index_6.html",
"https://www.boc.cn/sourcedb/whpj/index_7.html",
"https://www.boc.cn/sourcedb/whpj/index_8.html",
"https://www.boc.cn/sourcedb/whpj/index_9.html",
]
def start_requests(self):
for url in self.urls_list:
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
table = response.xpath('//div[@class="BOC_main"]//table[@align="left"]')
rows = table.xpath('.//tr')[1:] # 跳过表头行
for idx, row in enumerate(rows, start=1):
item = ForexItem()
item['currency_name'] = row.xpath('./td[1]/text()').get()
item['buying_price'] = row.xpath('./td[2]/text()').get()
item['cash_buying_price'] = row.xpath('./td[3]/text()').get()
item['selling_price'] = row.xpath('./td[4]/text()').get()
item['cash_selling_price'] = row.xpath('./td[5]/text()').get()
item['middle_price'] = row.xpath('./td[6]/text()').get()
item['pub_date'] = row.xpath('./td[7]/text()').get()
item['pub_time'] = row.xpath('./td[8]/text()').get()
yield item
- 抽取要点
- 使用 XPath 定位到牌价表格:
//table[contains(@class, 'BOC_main')]//tr,跳过表头,按列索引提取每列文本并清洗。
- 写入 MySQL 的
pipelines与股票类似,只是字段不同。
数据库表结构:
CREATE TABLE IF NOT EXISTS forex (
id INT AUTO_INCREMENT PRIMARY KEY,
currency_name VARCHAR(100),
buying_price DECIMAL(15,6),
cash_buying_price DECIMAL(15,6),
selling_price DECIMAL(15,6),
cash_selling_price DECIMAL(15,6),
middle_price DECIMAL(15,6),
pub_date VARCHAR(40),
pub_time VARCHAR(40)
)
五、心得体会
- 学会了从需求出发拆解任务
- 本次作业分为图片抓取、股票数据抓取与外汇数据抓取三部分。把整体任务拆成“页面发现 → 元素定位 → 数据清洗 → 存储/保存”四步,使实现更有条理,也便于调试与复用。
- 熟悉了文件命名与保存的细节
- 在图片下载中,以页面 title 命名文件是用户友好的做法,但要注意文件名合法性(替换特殊字符、控制长度、保留扩展名)。实践中我把非法字符替换为下划线,并截断过长文件名,避免了 Windows 下的路径/命名问题。
- 掌握了并发下载的常见模式与注意点
- 使用
ThreadPoolExecutor可以显著提高下载速度,但要注意线程安全(如下载计数器与日志输出需用锁保护)、合理控制并发数、设置超时与重试以提高稳定性,避免被目标站点封禁。
- 深化了对 Scrapy 中 Item 与 Pipeline 的理解
- Scrapy 的 Item 用于定义数据结构,Pipeline 负责统一处理和持久化(写入 MySQL 等)。将数据校验、去重与持久化放在 Pipeline 中能让爬虫逻辑更清晰、易维护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号