深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
前阵子工作上需要用到Calcite做一些事情,然后发现这个东西也是蛮有意思的,就花了些时间研究了一下。本篇主要围绕SQL 优化这块来介绍Calcite,后面会介绍Hive如何Calcite进行SQL的优化。
此外,也将Calcite的一些使用样例整理成到github,https://github.com/shezhiming/calcite-demo。里面包含了基础的CSV适配器例子,从这个例子延伸出的SQL解析,校验,RBO优化,CBO优化,以及自定义RelNode,自定义Cost信息,自定义rule等使用用例。如果觉得有帮助不妨点个start吧。
Calcite简介与CBO介绍
Calcite背景与介绍
先来说Calcite出现的背景,在上世纪,关系型数据库系统基本主导了数据处理领域,但是在Google三篇创世纪论文发表后,大家开始意识到,一种适合所有场景的数据库是不存在的。事实上,今天也确实是这样,许多特定场景下的数据处理系统已经成为主流,比如流处理领域的Flink,Storm,批处理领域的Spark SQL,文本搜索领域的Elasticsearch等等。而在开发不同特定场景的数据处理系统的时候,有两个主要问题。
- 一个是每种系统基本都需要查询语言(SQL)及相关拓展(比如流式SQL查询),或是开发过程中碰到查询优化问题,没有一个统一框架,那么每个系统都要一套自己的查询解析框架,那无疑是在重复造轮子。
- 另一个问题是,开发的这些系统通常要对接或集成其他系统,比如Kylin集成MR,Spark,Hbase等,如何支持跨异构数据源也是一个问题。
Calcite就是为了解决这些问题而生的。
说完背景,再来简单介绍Calcite。从功能上说,Calcite提供了通过SQL管理数据的能力,但是它本身不存储数据。最简单的例子,假如你有一些CSV文件,想通过SQL来查询这些CSV文件,那Calcite就很适合。要做到这一点,只需要提供一个有关CSV的适配器,告诉Calcite文件位置,字段这些信息(这些信息称为Schema)。Calcite就可以帮你实现SQL查询这些CSV文件,这只是最基础的功能。当然这个例子有些鸡肋,将CSV可以直接导入到Mysql同样能用SQL查询,但换个东西,Elasticsearch的数据,你总不能导到Mysql再用SQL查吧,这时候就能用Calcite实现SQL检索ES的数据。
具体CSV适配器例子,可以看我在最开始的github代码里面看到,:Calcite-demo-csv
实际效果大概是这样:
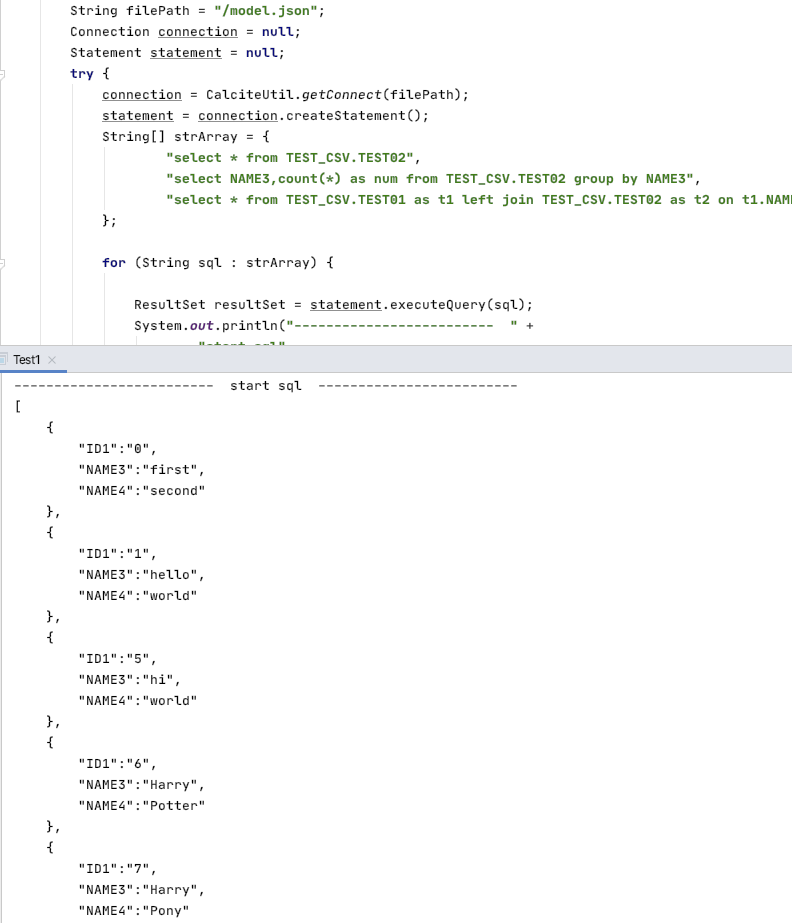
上述例子通过从配置文件中获取定义的Schema信息,然后就能编写对应的SQL进行查询。
从设计特点来说,因为Calcite的目的是提供一个通用的查询引擎,所以它的设计目标就是flexible, embeddable, and extensible,即灵活,可插拔,可拓展。这里可以顺便看一下它的架构图:

Calcite中的各个模块,Parse,Validate,Optimizer,都是可以单独拿出来用,并且可以方便得对其进行拓展。比如你想拓展你的SQL解析,想支持诸如"my select t1.a from t1"这样的语句,Calcite就有提供对应的接口(当然这算是比较高级的用法)。所以诸多开源框架,包括大家耳熟能详的Apache Hive,Apche Storm,Apache Flink,Apache Kylin等等,都会选择使用Calcite作为自己的SQL解析引擎,因为通用的东西直接用,定制化的东西可以方便得自定义。
此外,Calcite还有一些高级用法,比如物化视图,流式SQL支持等等,这里就不做展开。
接下来再介绍下SQL优化。
SQL优化与CBO
SQL从诞生到现在已经有几十年的时间了,尽管前几年nosql一度自我感觉良好号称要去掉sql,却也被现实教做人不得不改口,说是自己其实是not only sql,从这点可以看出sql语言的强大和通用。
说回sql,sql是一种声明式语言,所谓声明式,就是用户只需要告诉机器我要什么样的结果,机器会自己摸索并帮助用户找到结果返回。与之相比的是命令式语言,需要详细告诉机器如何执行,比如常见的编程语言。
那么作为声明式语言,如何帮助用户高效准确地获取到结果,这就是机器的责任。在这其中,SQL优化是许多研究者一直在探索的一个领域。
SQL优化的发展,则可以分为两个阶段,即RBO(Rule Base Optimization),和CBO(Cost Base Optimization)。
先简单说下RBO,RBO主要是开发人员在使用SQL的过程中,有些发现有些通用的规则,可以显著提高SQL执行的效率,比如最经典的filter下推:
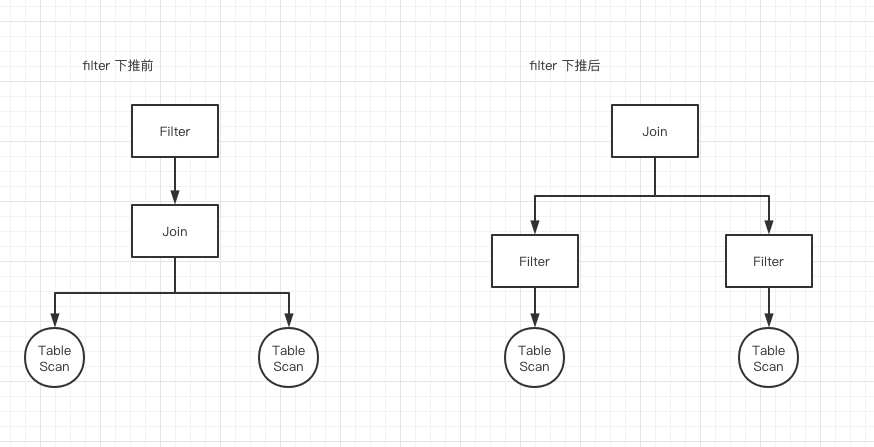
上面图片的意思很明显,我们都知道join是非常耗时的一个操作,且性能与join双方数据量大小呈线性关系(通常情况下)。那么很自然的一个优化,就是尽可能减少join左右双方的数据量,于是就想到了先filter再join这样一个rule。而非常多个类似的rule,就构成了RBO。
但后面开发者发现,RBO确实能够对通用情况下对SQL进行优化,但在有些需要本地状态才能优化的场景却无能为力。比如某个计算引擎,在数据量小于XXX的时候,可以做一些特殊的优化操作,这种场景下RBO无能为力。
而这就是CBO出现的背景了,CBO全称Cost Base Optimization,基于Cost的优化,其中Cost指的是执行SQL所需要的资源,通常是行数rowcount,CPU,内存,IO等等。基于Cost意思就是根据需要的资源,做更加智能的优化。
最典型的例子,就是Spark的join的选择。在Spark中,join会触发Shuffle操作,这种操作类型是非常消耗资源的。而Spark有三种类型的join,分别是broadcase join,将小的表广播到所有节点,在内存中hash碰撞进行join,这种join避免节点间shuffle操作,性能最好,但条件也苛刻。第二种是hash join,就是普通的shuffle join。第三种是sort merge join,先排序然后join,类似归并的思想,排序后能减少一些hash碰撞后的数据扫描,在join双方都是大表的情况下性能较好。
选择哪种类型的join,就要根据数据类型来选择,如果一方是小表,就用broadcase join,如果双方都是大表,就用sort merge join,否则就是 hash join。而这就需要用到Cost的信息了。
小结一下,RBO和CBO的区别大概在于,RBO只会无脑得应用提供的rule,而CBO会根据给出的Cost信息,智能应用rule,求出一个Cost最低的执行计划。需要纠正很多人误区的一点是,CBO其实也是基于rule的,接触到RBO和CBO这两个概念的时候,很容易将他们对立起来。但实际上CBO,可以理解为就是加上Cost的RBO。
Calcite优化器
HepPlanner优化器与VolcanoPlanner优化器
Calcite提供了两类型的优化器,即上述所说的RBO优化器和CBO优化器,在Calcite中的具体实现类对应HepPlanner(RBO)和VolcanoPlanner(CBO)。
其中HepPlanner简单理解就是两个循环,第一个循环会遍历用户提供的rule,第二个循环会遍历SQL树的节点,每当rule匹配到对应树节点的时候,会重新进行一遍循环。这个比较好理解。
而VolcanoPlanner则相对复杂一些,它不是简单地应用rule,而是会使用动态规划算法,计算每种rule匹配后生成新的SQL树的Cost信息,与原先SQL树的Cost信息相比较,如果新的树的Cost比较低,那么才会真正应用对应的rule。
当然这里都只是简单介绍,更加具体的内容,可以看看下面的两篇文章,一篇主要从理论的角度介绍了Calcite优化的原理,一篇从源码实现的角度剖析优化流程。
同时我的github代码中也有提供RBO和CBO相关的测试样例(主要是Test5和Test6),可以通过debug来看具体的执行流程,再结合理论和上述文章的解析,相信会有更加深入的理解。
Calcite优化样例代码介绍
github代码中Test6主要对比了RBO和CBO的差异,这里再顺便说下Test6测试样例的逻辑,其中的输出结果大概是这样:
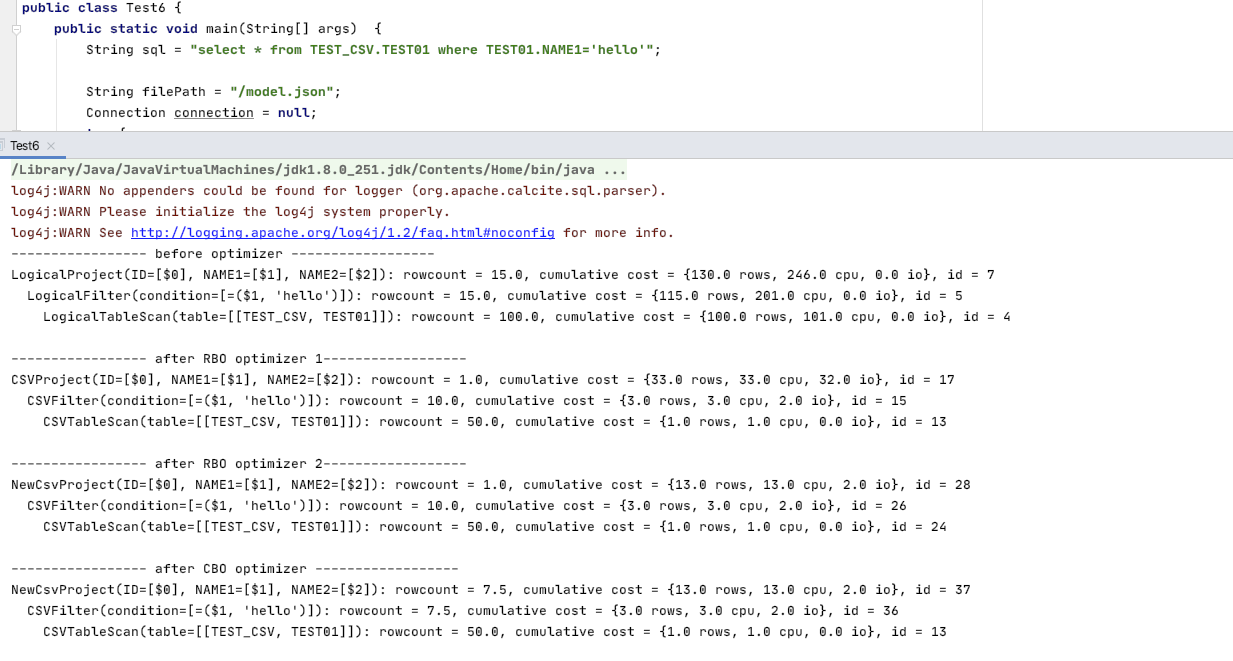
这里有比较多自定义的内容,不过也很好理解。最开始就是简单地将SQL解析成RelNode树(RelNode可以理解树节点吧)。然后提供自定义的rule,使用RBO将对应RelNode转成CSV类型的RelNode(RBO optimizer 1),改变下rule顺序,会发现生成了NewCsvProject而不再是CSVProject(RBO optimizer 2)。
最后是CBO,代码实现是自定义了一个CsvProject->NewCsvProject的rule,添加到VolcanoPlanner中。最终会发现,修改NewCsvProject的computeSelfCost()方法返回的Cost信息,该条rule会产生不同的效果,即CBO的体现。
以上就是本篇的全部内容,下面一篇主要介绍hive Sql解析的流程,以及在这个过程中如何应用Calcite来进行优化。
参考文章:
相关论文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号