

Oracle去除重复(某一列的值重复),取最新(日期字段最新)的一条数据
转自 : http://blog.csdn.net/nux_123/article/details/45037719
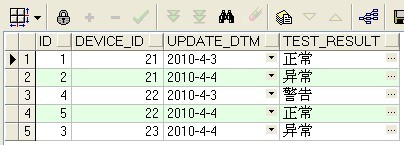
问题:在项目中有一张设备检测信息表DEVICE_INFO_TBL, 每个设备每天都会产生一条检测信息,现在需要从该表中检索出每个设备的最新检测信息。也就是device_id字段不能重复,消除device_id字段重复的记录,而且device_id对应的检测信息test_result是最新的。
解决思路:用Oracle的row_number() over函数来解决该问题。
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下:
1:over后的写法:
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
2:开窗的窗口范围:
over(order by salary range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
举例:
--sum(s)over(order by s range between 2 preceding and 2 following) 表示加2或2的范围内的求和
select name,class,s, sum(s)over(order by s range between 2 preceding and 2 following) mm from t2adf 3 45 45 --45加2减2即43到47,但是s在这个范围内只有45
asdf 3 55 55
cfe 2 74 74
3dd 3 78 158 --78在76到80范围内有78,80,求和得158
fda 1 80 158
gds 2 92 92
ffd 1 95 190
dss 1 95 190
ddd 3 99 198
gf 3 99 198
举例:
select name,class,s, sum(s)over(order by s rows between 2 preceding and 2 following) mm from t2
adf 3 45 174 (45+55+74=174)
asdf 3 55 252 (45+55+74+78=252)
cfe 2 74 332 (74+55+45+78+80=332)
3dd 3 78 379 (78+74+55+80+92=379)
fda 1 80 419
gds 2 92 440
ffd 1 95 461
dss 1 95 480
ddd 3 99 388
gf 3 99 293
解决过程:
1.查看表中的重复记录
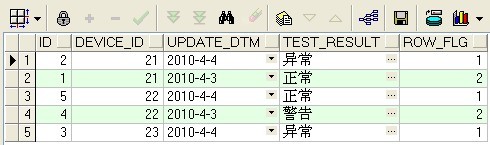
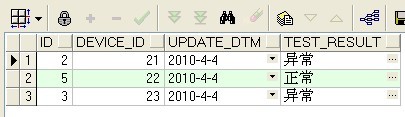
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码.
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序).
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 .
lag(arg1,arg2,arg3):
arg1是从其他行返回的表达式
arg2是希望检索的当前行分区的偏移量。是一个正的偏移量,时一个往回检索以前的行的数目。
arg3是在arg2表示的数目超出了分组的范围时返回的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号