


spark集群安装部署
-
事先搭建好zookeeper集群
-
1、下载安装包
https://archive.apache.org/dist/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
spark-2.3.3-bin-hadoop2.7.tgz
-
2、规划安装目录
/kkb/install
-
3、上传安装包到服务器
-
4、解压安装包到指定的安装目录
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /kkb/install
-
5、重命名解压目录
mv spark-2.3.3-bin-hadoop2.7 spark
-
6、修改配置文件
-
进入到spark的安装目录下对应的conf文件夹
-
vim spark-env.sh ( mv spark-env.sh.template spark-env.sh)
#配置java的环境变量 export JAVA_HOME=/kkb/install/jdk1.8.0_141 #配置zk相关信息 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
-
vim slaves ( mv slaves.template slaves)
#指定spark集群的worker节点 node02 node03
-
-
-
7、分发安装目录到其他机器
scp -r /kkb/install/spark node02:/kkb/install scp -r /kkb/install/spark node03:/kkb/install -
8、修改spark环境变量
-
vim /etc/profile
export SPARK_HOME=/kkb/install/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
-
-
9、分发spark环境变量到其他机器
scp /etc/profile node02:/etc scp /etc/profile node03:/etc -
10、让所有机器的spark环境变量生效
-
在所有节点执行
source /etc/profile
5. spark集群的启动和停止
5.1 启动
-
1、先启动zk
-
2、启动spark集群
-
可以在任意一台服务器来执行(条件:需要任意2台机器之间实现ssh免密登录)
-
$SPARK_HOME/sbin/start-all.sh
-
在哪里启动这个脚本,就在当前该机器启动一个Master进程
-
整个集群的worker进程的启动由slaves文件
-
-
后期可以在其他机器单独在启动master
-
$SPARK_HOME/sbin/start-master.sh
-
-
(1) 如何恢复到上一次活着master挂掉之前的状态?
在高可用模式下,整个spark集群就有很多个master,其中只有一个master被zk选举成活着的master,其他的多个master都处于standby,同时把整个spark集群的元数据信息通过zk中节点进行保存。
后期如果活着的master挂掉。首先zk会感知到活着的master挂掉,下面开始在多个处于standby中的master进行选举,再次产生一个活着的master,这个活着的master会读取保存在zk节点中的spark集群元数据信息,恢复到上一次master的状态。
整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个活着的master的转态,整个恢复过程一般需要1-2分钟。
(2) 在master的恢复阶段对任务的影响?
a)对已经运行的任务是没有任何影响
由于该任务正在运行,说明它已经拿到了计算资源,这个时候就不需要master。
b) 对即将要提交的任务是有影响
由于该任务需要有计算资源,这个时候会找活着的master去申请计算资源,由于没有一个活着的master,该任务是获取不到计算资源,也就是任务无法运行。
5.2 停止
-
在处于active Master主节点执行
-
$SPARK_HOME/sbin/stop-all.sh
-
-
在处于standBy Master主节点执行
-
$SPARK_HOME/sbin/stop-master.sh
-
6. spark集群的web管理界面
-
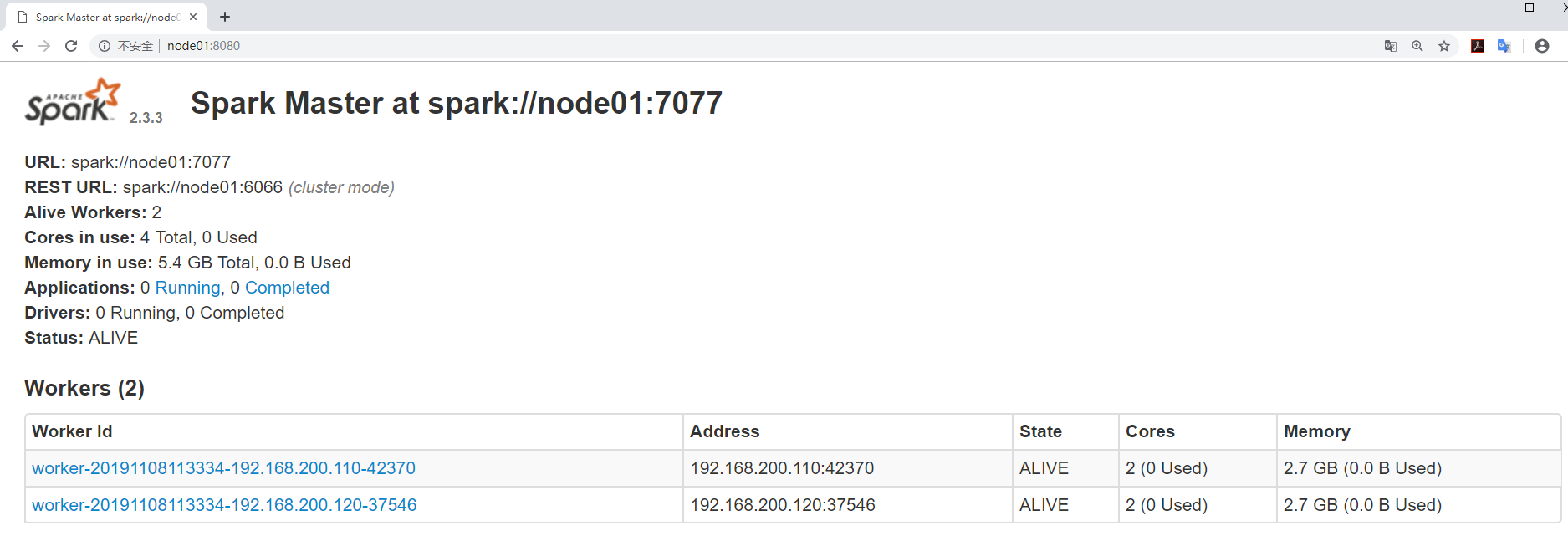
当启动好spark集群之后,可以访问这样一个地址
-
http://master主机名:8080
-
可以通过这个web界面观察到很多信息
- 整个spark集群的详细信息
- 整个spark集群总的资源信息
- 整个spark集群已经使用的资源信息
- 整个spark集群还剩的资源信息
- 整个spark集群正在运行的任务信息
- 整个spark集群已经完成的任务信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号