数据仓库搭建——Inmon与Kimball
一、简介
1.1 历史
搞数据仓库这么久,实践中发现首先搭建数据集市,还是清洗数据之后,直接进入数据立方体(形成维度表和实施表)形成核心数据仓库层,是个选择题...
随后发现这其实涉及到了数据仓库的历史问题,是采用Inmon建模还是采用Kimball建模?甚至有人称之为数据仓库界的宗教之争。下面我说一下自己的理解:
1.2 Inmon
2000年5月,W.H.Inmon在DM Review杂志上发表一篇文章,正是揭示了他的企业信息化工厂的特点。下图是我理解的企业信息化工厂架构图:
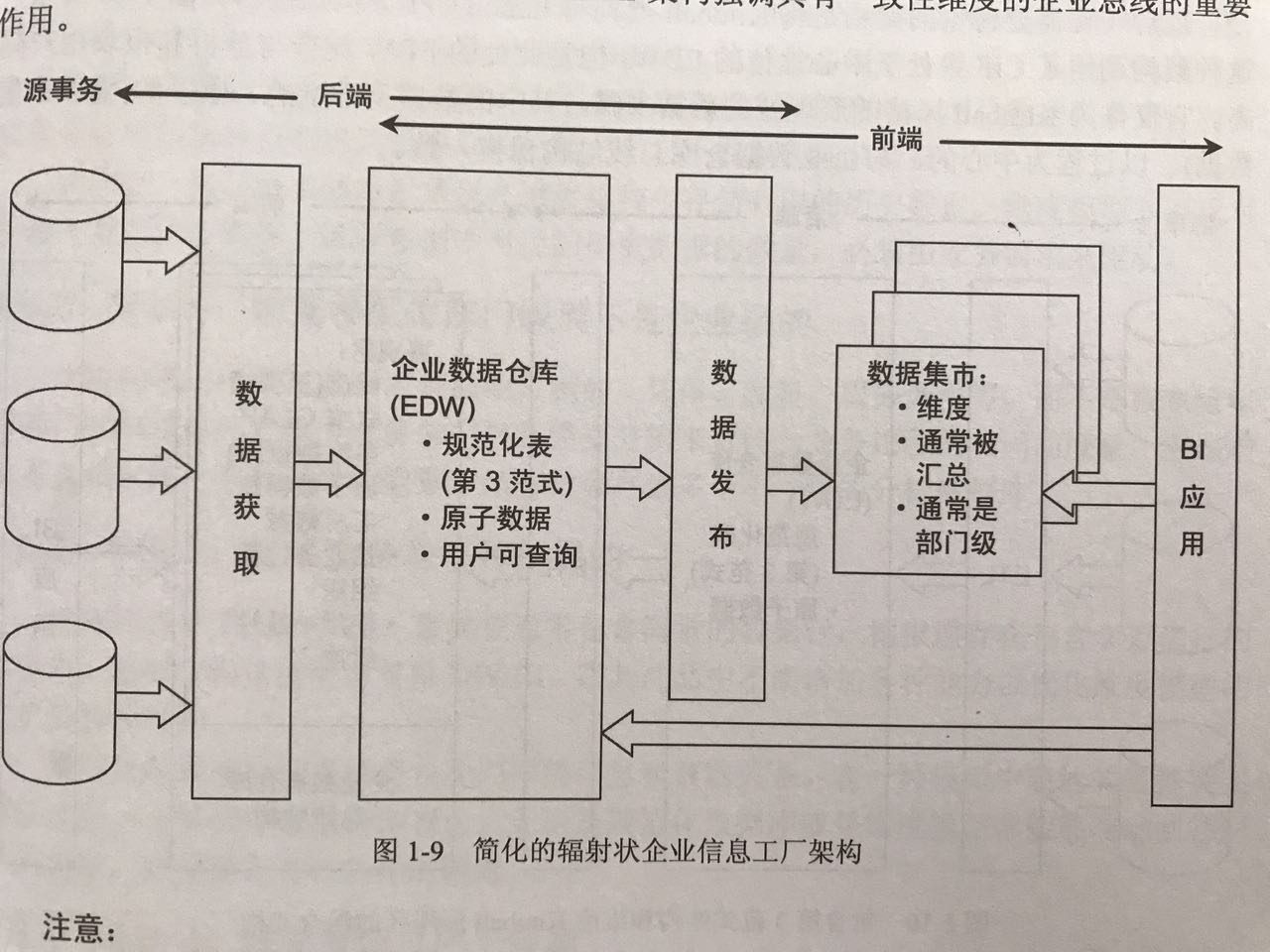
数据获取到之后,先进行整理,并且要求整理的数据是满足第三范式标准的。
1.3 Kimball
我理解,Kimball与Inmon的主要区别就是Kimball更强调一致性事实和维度,也就是一致性维度企业总线的总要作用,这样在数据仓库迭代开发过程中更接近需求,也会提升敏捷性。通常,Kimball都是以最终任务为导向。
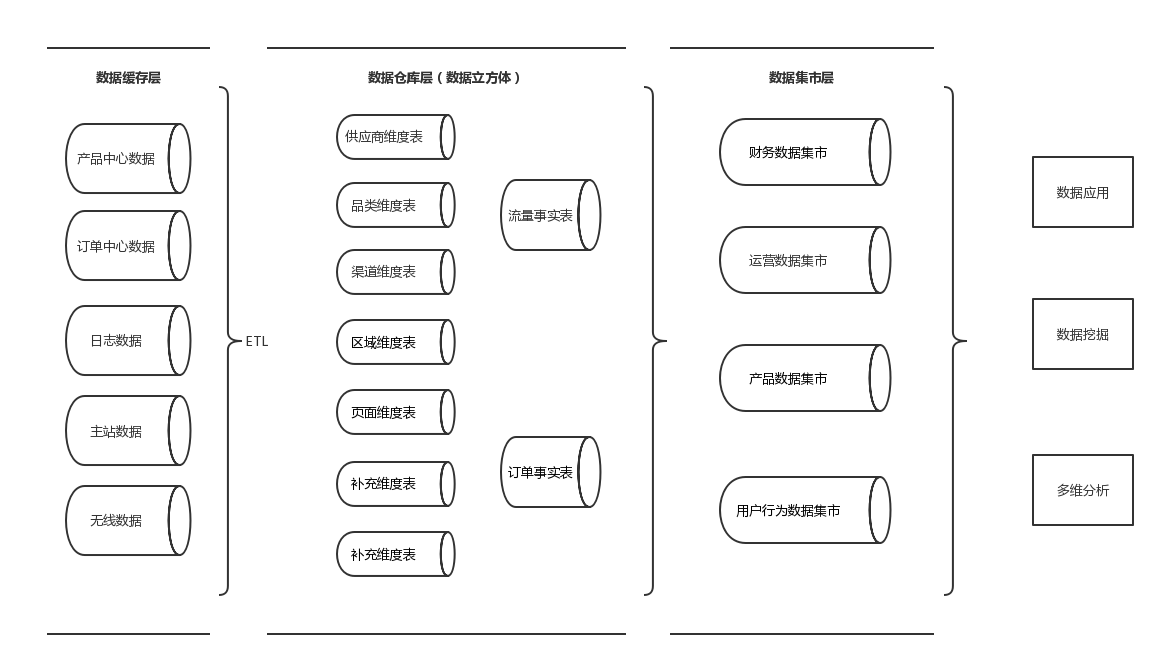
首先,在得到数据后需要先做数据的探索,深入理解业务逻辑与数据表的关系。
然后,在明确数据依赖后,按照目标需求,直接生成事实表+维度表。
最后,(数据集市层)拆分出部分的事实表和维度表
结果,数据集市一方面可以直接向BI环节输出数据,另一方面也可以向数据仓库层输出数据,方便后续的多维分析。如下图:
二、特点
他们之间的区别用这个图表体现非常合适:
| 特性 | Kimball | Inmon |
|---|---|---|
| 时间 | 快速交付 | 路漫漫其修远兮 |
| 开发难度 | 小 | 大 |
| 维护难度 | 大 | 小 |
| 技能要求 | 入门级 | 专家级 |
| 数据要求 | 特定业务 | 企业级 |
三、参考文献
https://segmentfault.com/a/1190000006255954
http://blog.csdn.net/paicMis/article/details/53236869

 浙公网安备 33010602011771号
浙公网安备 33010602011771号