
python笔记 内置模块
os模块
# os.path.abspath(path) 返回path规范化的绝对路径
# os.path.split(path) 将path分割成目录和文件名二元组返回
# os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
# os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
# os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
# os.path.isabs(path) 如果path是绝对路径,返回True
# os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
# os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
# os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
# os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
# os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
# os.path.getsize(path) 返回path的大小
# os.path.normpath(path) 规范path字符串形式
re模块
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi')
['alvin']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \
参考文章:https://blog.csdn.net/yufenghyc/article/details/51078107
元字符之. ^ $ * + ? { }
. 匹配除换行符('\n')之外的任意单个字符(注意:awk 指令中的句点能匹配换行符)
ret=re.findall('a..in','helloalvin') print(ret)#['alvin']
^ 匹配行首,例如'^dog'匹配以字符串dog开头的行(注意:awk 指令中,'^'则是匹配字符串的开始)
ret=re.findall('^a...n','alvinhelloawwwn') print(ret)#['alvin']
$ 匹配行尾,例如:'^、dog$'匹配以字符串 dog 为结尾的行(注意:awk 指令中,'$'则是匹配字符串的结尾)
ret=re.findall('a...n$','alvinhelloawwwn') print(ret)#['awwwn']
*匹配前面的子表达式 0 次或多次(等价于{0, }),例如:zo* 能匹配 "z"以及 "zoo"
ret=re.findall('abc*','abcccc')#贪婪匹配[0,+oo] print(ret)#['abcccc']
+ 匹配前面的子表达式 1 次或多次(等价于{1, }),例如:zo+能匹配 "zo"以及 "zoo",但不能匹配 "z"
ret=re.findall('abc+','abccc')#[1,+oo] print(ret)#['abccc']
?当该字符紧跟在任何一个其他限制符(*, +, ?, {n},{n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个"o",而 'o+' 将匹配所有 'o'
{ }
{n} n 必须是一个 0 或者正整数,匹配子表达式 n 次,例如:zo{2}能匹配
{n,}"zooz",但不能匹配 "Bob"n 必须是一个 0 或者正整数,匹配子表达式大于等于 n次,例如:go{2,}
{n,m}能匹配 "good",但不能匹配 godm 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次 ,例如:o{1,3}将配"fooooood" 中的前三个 o(请注意在逗号和两个数之间不能有空格)
元字符之字符集[]:字符集中有意义的元字符 - ^ \
[0-9] 匹配从 0 到 9 中的任意一个数字字符(注意:要写成递增)
[xyz] 字符集合,匹配所包含的任意一个字符,例如:'[abc]'可以匹配"lay" 中的 'a'(注意:如果元字符,例如:. *等,它们被放在[ ]中,那么它们将变成一个普通字符)
[^xyz]负值字符集合,匹配未包含的任意一个字符(注意:不包括换行符),例如:'[^abc]' 可以匹配 "Lay" 中的'L'(注意:[^xyz]在awk 指令中则是匹配未包含的任意一个字符+换行符)
[A-Za-z] 匹配大写字母或者小写字母中的任意一个字符(注意:要写成递增)
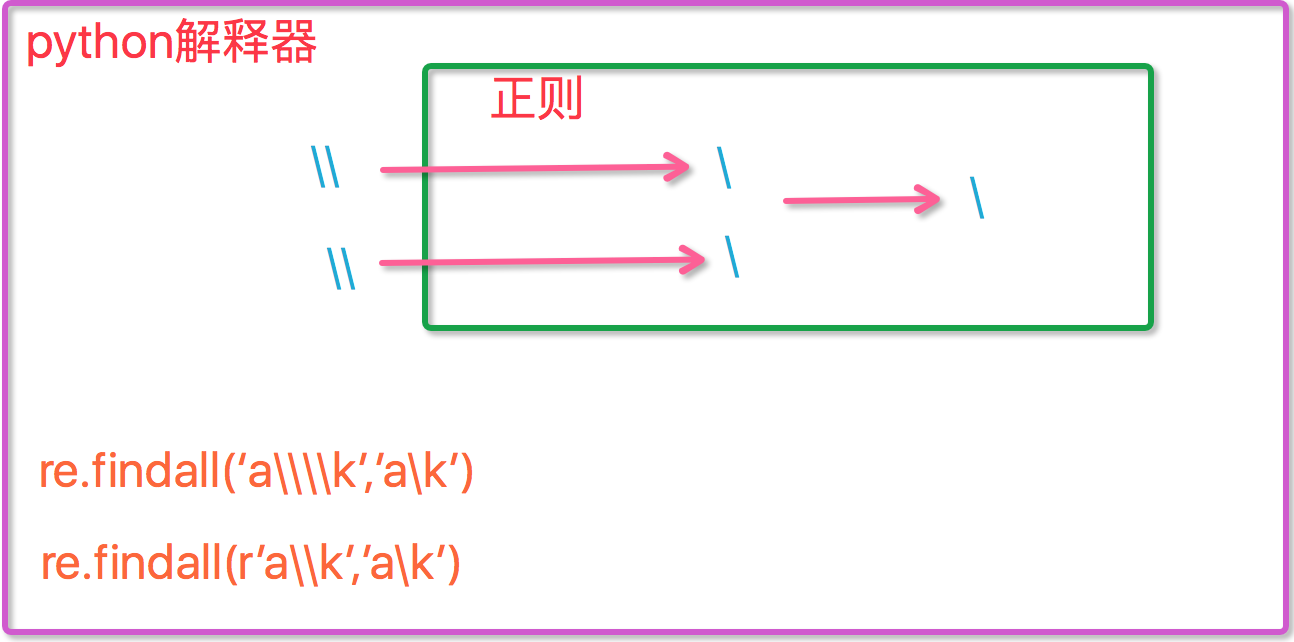
元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
元字符之分组()
元字符之|
re模块下的常用方法
用 '[\u4e00-\u9fa5]‘ 匹配中文
在字符串中匹配中文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号