
《从机器学习到深度学习》笔记(5)集成学习之随机森林
集成学习模型与其他有监督模型的出发点大相径庭,之前的模型都是在给定的训练集上通过构建越来越强大的算法进行数据拟合。而集成学习着重于在训练集上做文章:将训练集划分为各种子集或权重变换后用较弱的基模型拟合,然后综合若干个基模型的预测作为最终整体结果。在Scikit-Learn中实现了两种类型的集成学习算法,一种是Bagging methods,另一种是Boosting methods。
随机森林(Random Forrest)是Bagging方法的一个典型代表,由它的名称就可以联想到它是一种使用决策树作为基模型的集成学习方法。
1. 集成框架
随机森林在训练过程中对训练集进行随机抽样,分别进行训练后形成若干个小的决策树。分类问题的预测通过这些基决策树的投票完成,回归问题的预测通过对基决策树结果求平均完成,整个流程如图3-17所示。
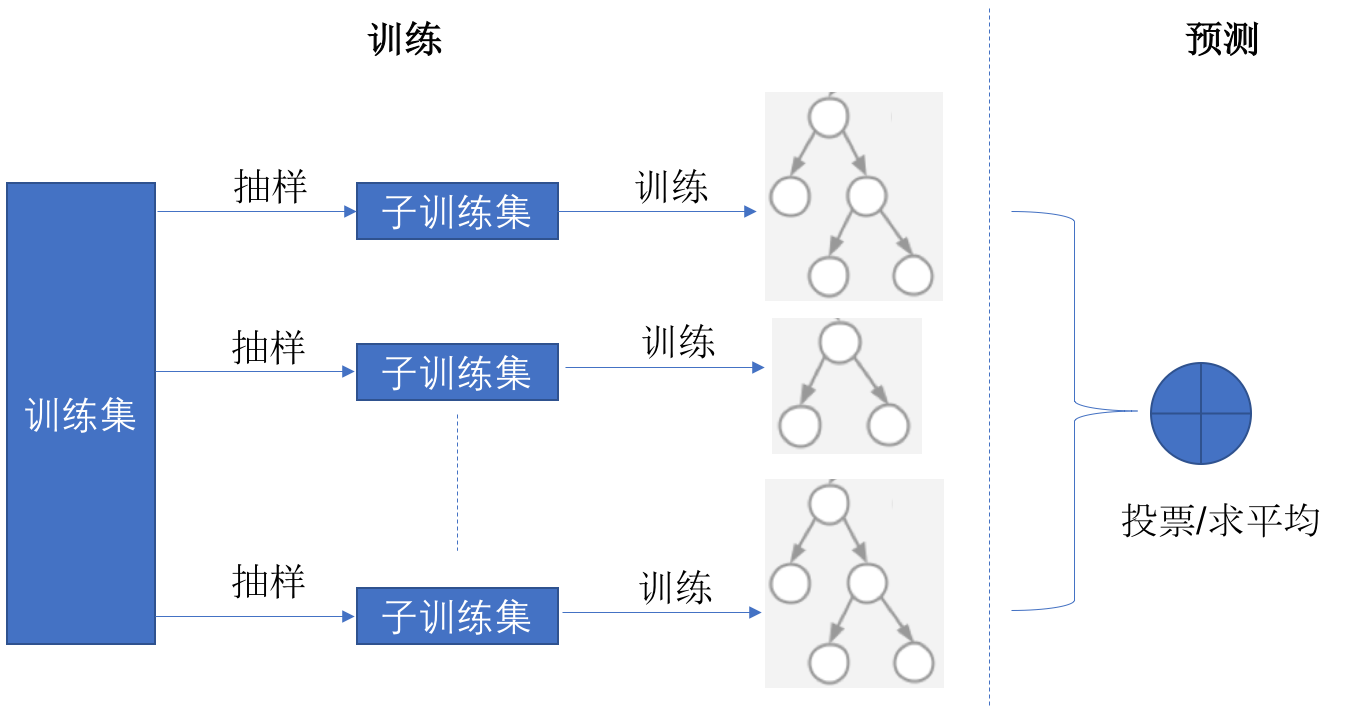
![]()
图3-17 随机森林算法原理
随机森林基模型中的决策树一般采用有较大偏差和较小方差的“弱模型”,和普通的决策树相比具体体现在:
- 样本裁剪:通过随机采样每个弱模型只训练部分样本数据;
- 特征裁剪:每个基模型的决策树只选用数据特征中的一部分进行训练和预测;随机抽样保证了所有特征都能被部分弱模型学习到;
- 小树:由于特征和样本数量有限每个弱模型决策树都长不高,所以不需要像普通决策树那样在训练结束后为避免过度拟合而执行剪枝。
2. 有放回采样(bootstrap)
在从整体训练集中进行随机采样划分子训练集时,随机森林通常采用所谓的有放回采样(bootstrap)手段。有放回采样是指每次抽取一个样本放入子集后将改样本仍保留在被采样空间中,使得它仍有可能被再次采样到。比如有盘水果:1个橘子,2个苹果,3个香蕉,对该盘水果进行2次有放回采样完全可能采样到2个橘子(虽然概率比较小);如果使用无放回采样则最多采样到1个橘子。
在整体样本数量足够多的情况下,通过bootstrap采样到的子集只有期望约为63.2%的无重复样本。使用这种采样有什么好处呢?
因为bootstrap能够生成出与训练样本整体不同的数据分布,这样等于扩充了训练样本空间,所以通过bootstrap采样能够训练出适应性更强的模型。
3. Out-of-bag Estimation
在本书第1章中有介绍过,一般机器学习模型的评估需要通过与训练集相互独立的另一个测试集完成。而Bagging类模型在训练过程中划分不同独立数据子集的行为在侧面引入了另一个好处,就是可以使用训练数据本身进行模型准确率的评估。
这就是所谓的Out-of-bag Estimation(简称OOB),是指基模型的评估预测只采用未参与到其本身训练的数据集上。因此虽然整体上没有给出独立的测试集,但每个基模型自己使用的训练数据和预测数据是完全隔离的,如图3-18所示。
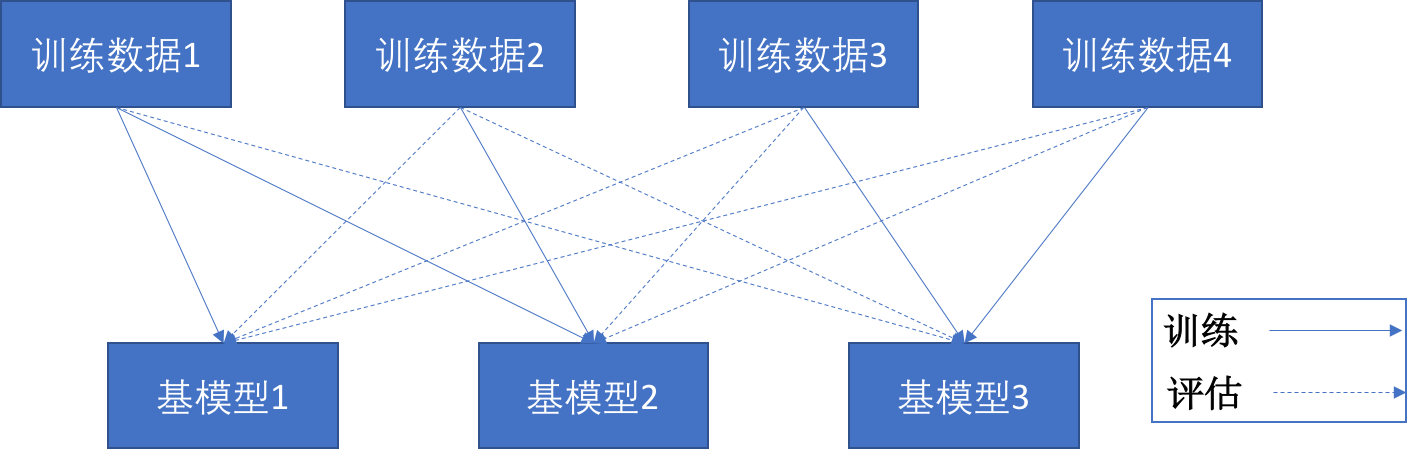
![]()
图3-18 Out-of-bag示意图
图中的实线标示基模型训练时使用的数据,虚线标示进行评估预测时基模型使用的数据。只要保证每条训练数据没有重复的被应用在单个基模型上,就可以保证评估结果的公允性。
4. RandomForestClassifier和RandomForestRegressor
在sklearn.ensemble包中提供了完整封装的随机森林模型RandomForestClassifier和RandomForestRegressor,它们的使用方式与其他模型无异。在模型参数方面,由于随机森林使用决策树作为基模型,所以在模型初始化过程中保留了所有DecitionTreeXXX模型中的决策树相关参数,此外还提供了关于抽样方式和OOB评估的配置属性,比如:
>>>from sklearn.datasets import load_iris >>>from sklearn.ensemble import RandomForestClassifier >>>iris = load_iris() # 导入iris数据库 >>>clf = RandomForestClassifier(n_estimators = 20, bootstrap=True, oob_score=True) >>>clf.fit(iris.data, iris.target) # 训练 >>>clf.oob_score_ # 查看OOB评估结果 0.946666666667
上述代码使用了Scikit-learn的测试数据库iris作为训练数据来源,在初始化随机森林回归模型的时候配置n_estimators定义基模型的数量、配置了参数bootstrap=True使用有放回采、配置oob_score=True指定在训练后进行OOB测试,在训练后马上通过oob_score_属性获得了准确性评估。
注意:如果未在模型初始化时指定oob_score=True则不能在训练后访问oob_score_属性。
从机器学习,到深度学习
从深度学习,到强化学习
从强化学习,到深度强化学习
从优化模型,到模型的迁移学习
一本书搞定!

![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号