91--spring cloud (solr安装配置/测试)
Solr全文搜索服务
Solr是一个高性能,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
solr 安装
下载地址:https://lucene.apache.org/solr/
https://www.apache.org/dyn/closer.lua/lucene/solr/8.6.2/solr-8.6.2.tgz
下面我们来安装 solr 服务器
把 solr-8.1.1.tgz 传到服务器
先切换到 /usr/local 目录
cd /usr/local
把文件传到 /usr/local 目录下
解压 solr
cd /usr/local
# 上传 solr-8.1.1.tgz 到 /usr/local 目录
# 并解压缩
tar -xvf solr-8.1.1.tgz
启动 solr
cd /usr/local/solr-8.1.1
# 当前所在目录solr-8.1.1
# 不建议使用管理员启动 solr,加 -force 强制启动
bin/solr start -force
# 开放 8983 端口
firewall-cmd --zone=public --add-port=8983/tcp --permanent
firewall-cmd --reload
浏览器访问 solr 控制台
- 注意修改地址
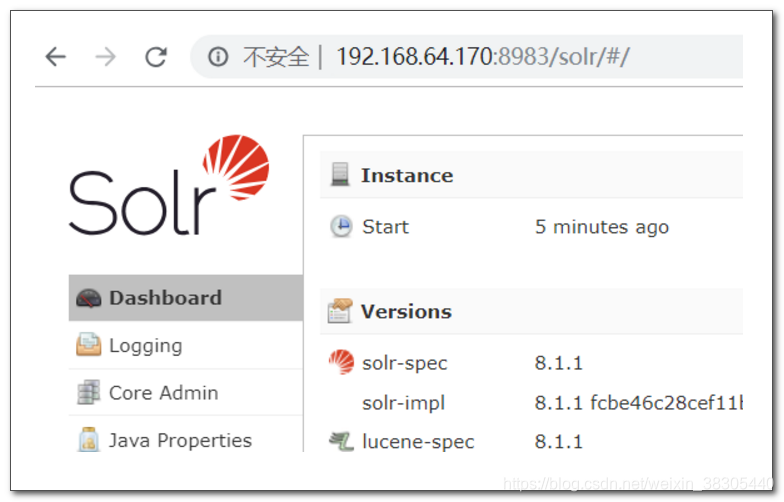
创建 core
在solr 中创建核心 core
core: 用来存储相同类型、具有相同结构的文档
数据库中 pd_item 表中的商品数据, 在 solr 中保存索引数据, 一类数据, 在 solr 中创建一个 core 保存索引数据
创建一个名为 pd 的 core, 首先要准备以下目录结构:
# solr目录/server/solr/
# pd/
# conf/
# data/
cd /usr/local/solr-8.1.1
mkdir server/solr/pd
mkdir server/solr/pd/conf
mkdir server/solr/pd/data
conf 目录是 core 的配置目录, 存储一组配置文件, 我们以默认配置为基础, 后续逐步修改
复制默认配置
cd /usr/local/solr-8.1.1
cp -r server/solr/configsets/_default/conf server/solr/pd
创建名为 pd 的 core
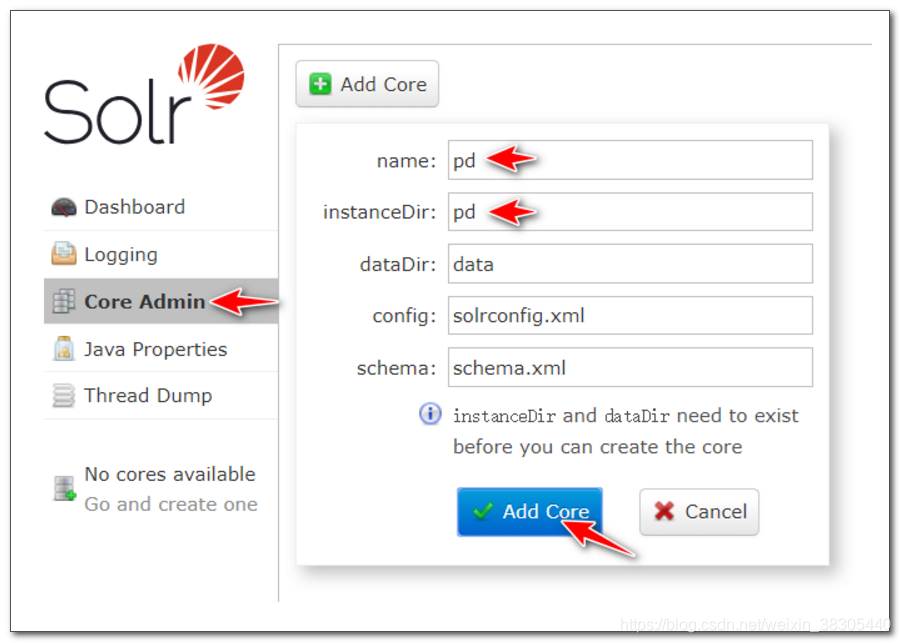
中文分词测试
第一步: 在左侧下拉框选择pd,然后选择Analysis ,然后输入信息,设置FieldType ,进行分词
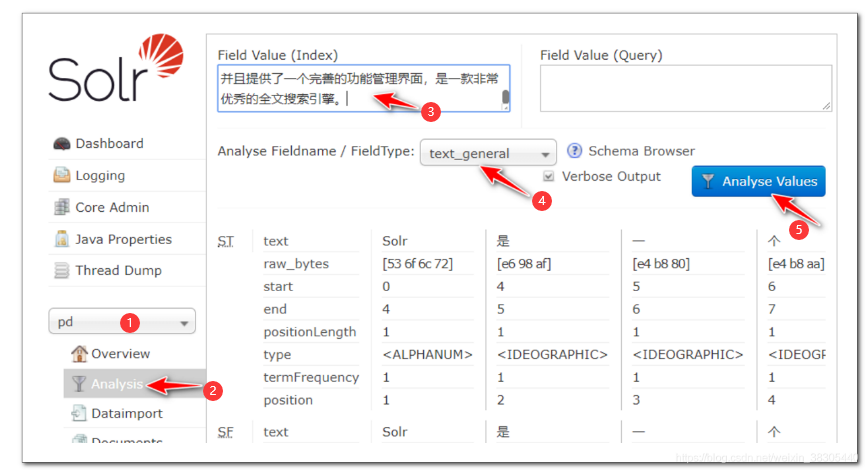
填入文本, 观察分词结果:
ik中文分词器
https://github.com/magese/ik-analyzer-solr
下载 ik-analyzer 分词 jar 文件,传到 solr目录/server/solr-webapp/webapp/WEB-INF/lib
为了后续操作方便,我们把后面用到的jar文件一同传到服务器,包括四个文件:
gitee地址:https://gitee.com/erli_liqiang/data/tree/master
- ik-analyzer-8.1.0.jar
- mysql-connector-java-5.1.46.jar
- solr-dataimporthandler-8.1.1.jar
- solr-dataimporthandler-extras-8.1.1.jar
复制6个文件到 solr目录/server/solr-webapp/webapp/WEB-INF/classes
# classes目录如果不存在,需要创建该目录
mkdir /usr/local/solr-8.1.1/server/solr-webapp/webapp/WEB-INF/classes
将6个文件复制到 classes 目录下
IKAnalyzer.cfg.xml
ext.dic
stopword.dic
stopwords.txt
ik.conf
dynamicdic.txt
- 配置 managed-schema
修改 solr目录/server/solr/pd/conf/managed-schema,添加 ik-analyzer 分词器
注意:修改文件的时候,最好不要用软件的编辑器,要用电脑自己安装的文本编辑器,否则的话会产生中文乱码的问题,导致服务不能正常启动
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
- 重启 solr 服务
cd /usr/local/solr-8.1.1
bin/solr restart -force
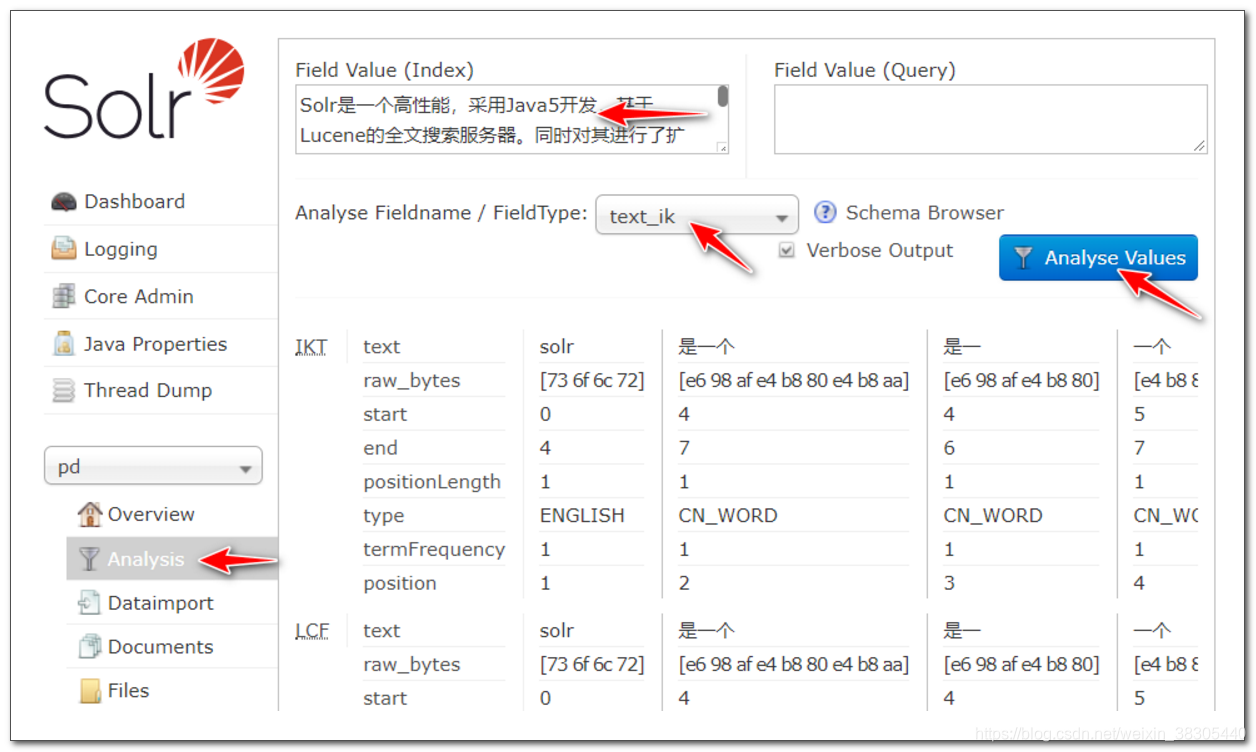
使用 ik-analyzer 对中文进行分词测试
填入以下文本, 选择使用 text_ik 分词器, 观察分词结果:
设置停止词
上传停止词配置文件到 solr目录/server/solr-webapp/webapp/WEB-INF/classes
一般设置停止词 是问了过滤一些敏感信息,以及一些没有价值的词语
stopword.dic
stopwords.txt
重启服务,观察分词结果中,停止词被忽略
bin/solr restart -force
准备 mysql 数据库数据
- 用 sqlyog 执行 sql文件(pd.sql)
- 授予 root 用户 跨网络访问权限
注意: 此处设置的是远程登录的 root 用户,本机登录的 root 用户密码不变 - mysql 5 或 mariadb
grant all on *.* to 'root'@'%' identified by 'root';
- oracle mysql 8
create user 'root'@'%' identified by 'root';
grant all privileges on *.* to 'root'@'%';
随机修改30%的商品,让商品下架,以便后面做查询测试
UPDATE pd_item SET STATUS=0 WHERE RAND()<0.3
从 mysql 导入商品数据
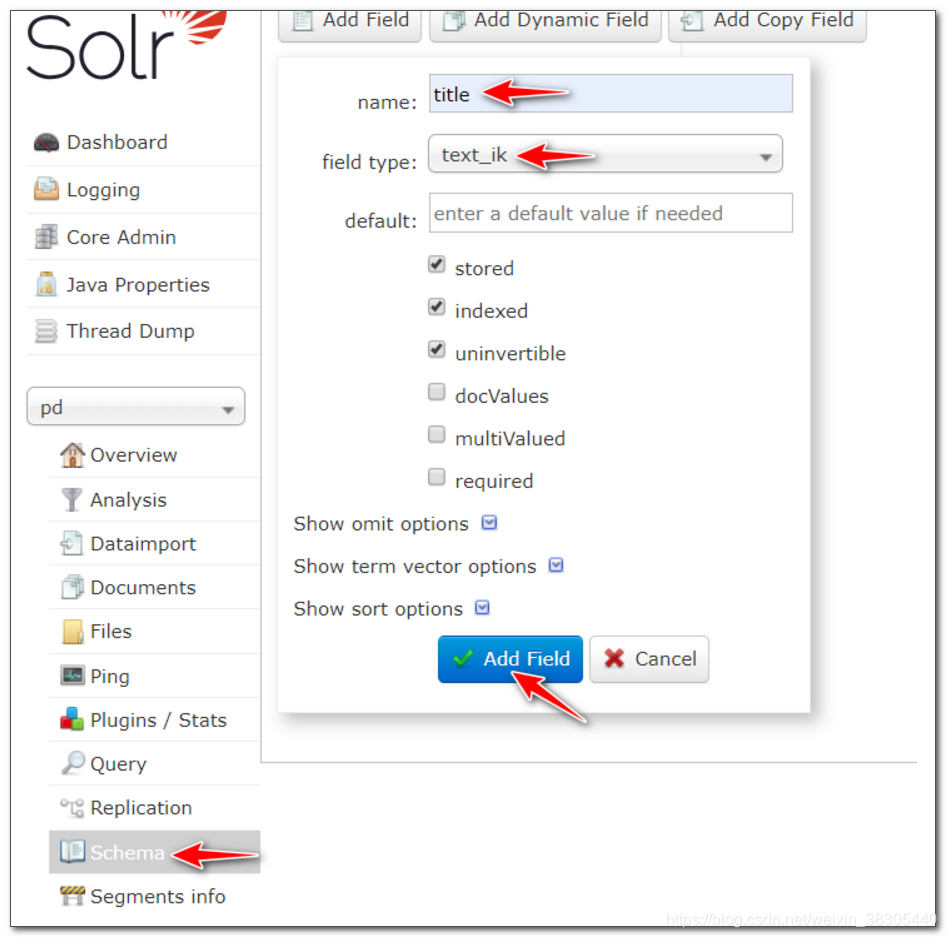
设置字段
- title
text_ik - sellPoint
text_ik - price
plong - barcode
string - image
string - cid
plong - status
pint - created
pdate - updated
pdate
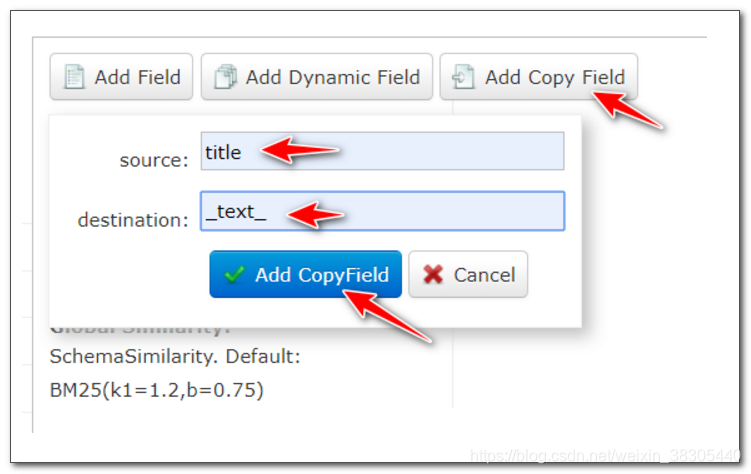
Copy Field 副本字段
查询时需要按字段查询,例如 title:电脑, 可以将多个字段的值合并到一个字段进行查询,默认查询字段 _text_
将 title 和 sellPoint 复制到 _text_ 字段
Data Import Handler 配置
导入数据设置
- dih-config.xml
修改 mysql 的 ip 地址,传到
solr目录/server/solr/pd/conf
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.64.1:3306/pd_store"
user="root"
password="root"
batchSize="100"
autoCommit="false" />
<document name="item">
<entity name="item" pk="id"
query="SELECT id,title,sell_point sellPoint,price,barcode,image,cid,`status`,created,updated FROM pd_item"
deltaQuery="SELECT id,title,sell_point sellPoint,price,barcode,image,cid,`status`,created,updated FROM pd_item WHERE updated > date_add(str_to_date('${dih.last_index_time}','%Y-%m-%d %H:%i:%s'),interval 8 hour)"
transformer="RegexTransformer">
</entity>
</document>
</dataConfig>
此处的数据库的密码是新的用户的密码,不是本地主机的密码,所以需要跟刚才设置的密码一致
-
solrconfig.xml 中添加 DIH 配置
在该文件的末尾添加以下配置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">dih-config.xml</str>
</lst>
</requestHandler>
重启 solr
cd /usr/local/solr-8.1.1
bin/solr restart -force
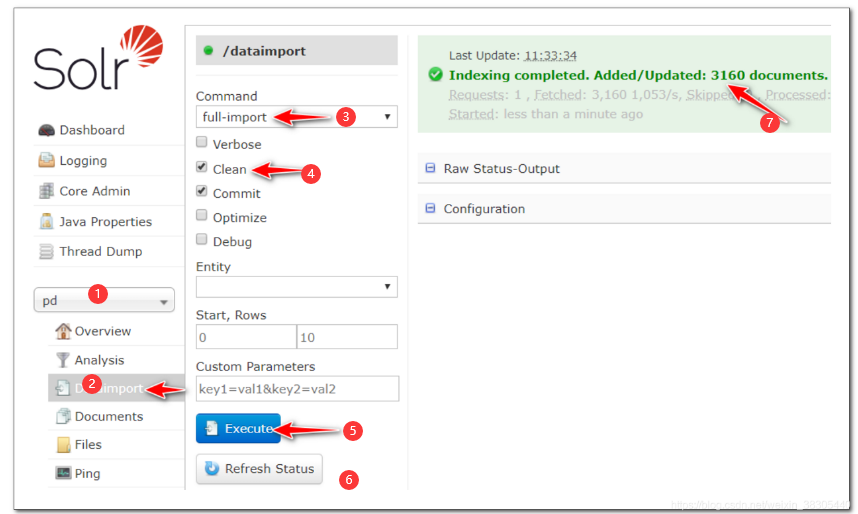
导入数据
重启 solr 后导入数据,确认导入的文档数量为 3160
查询测试
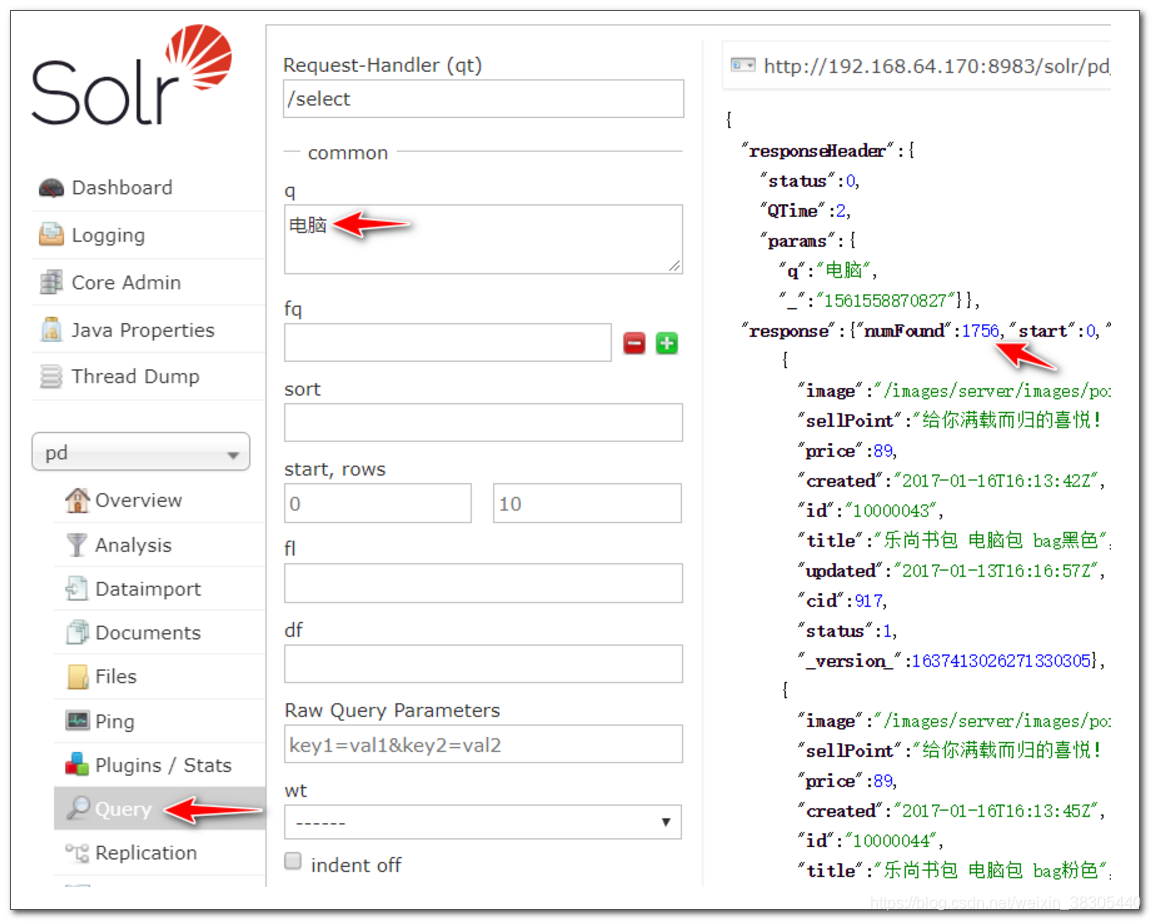
在复制字段 _text_ 中查找 电脑
所有字段中包含电脑的会被查询出来
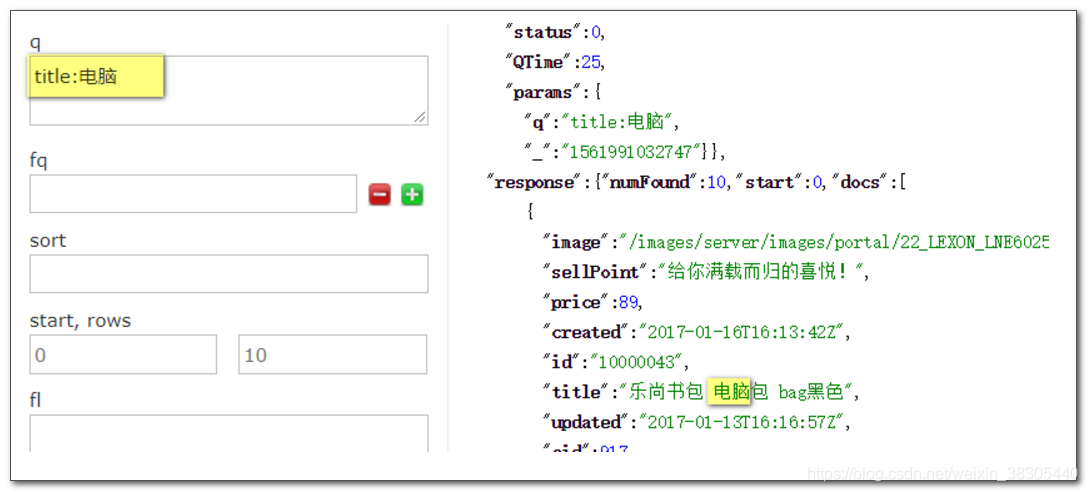
在标题中查找 电脑
标题中含有电脑的会查询出来
用双引号查找完整词 "笔记本"
如果不加双引号的话,则会进行分词,加上双引号以后就当成一个整体进行查询

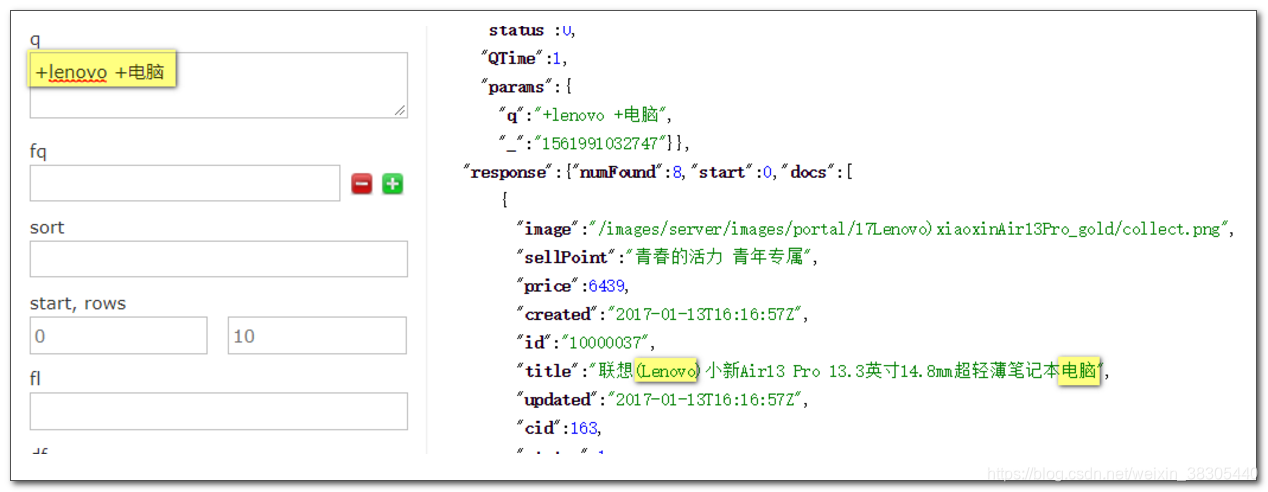
搜索 +lenovo +电脑
代表的是选择Lenovo 并且是电脑类型
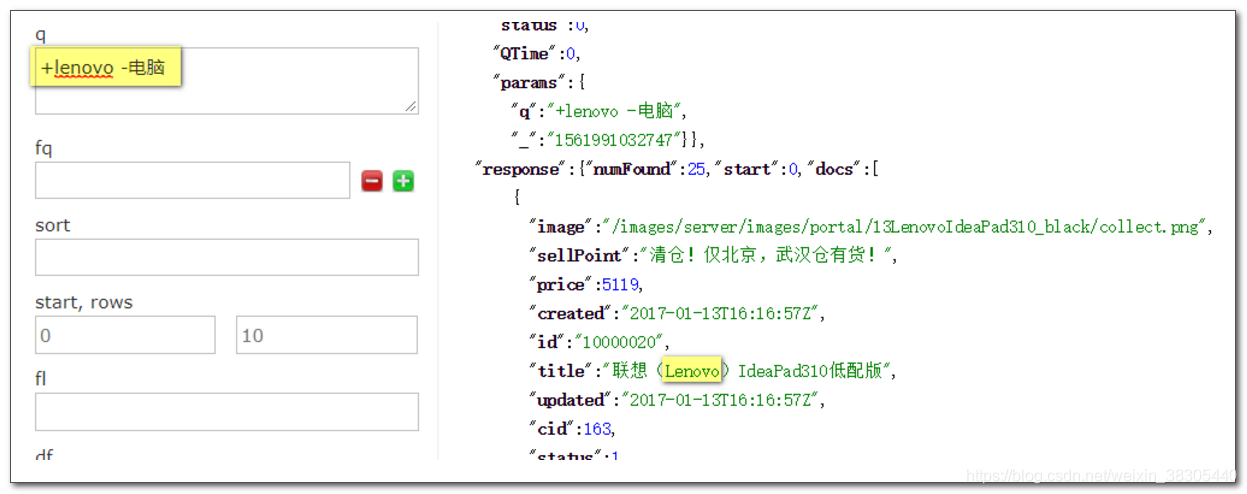
搜索 +lenovo -电脑
代表的是选择Lenovo 但是排除电脑
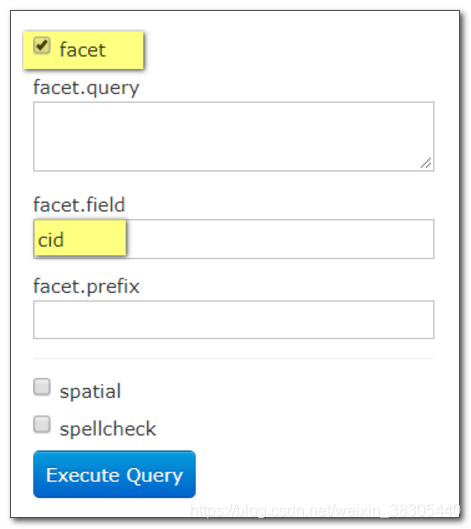
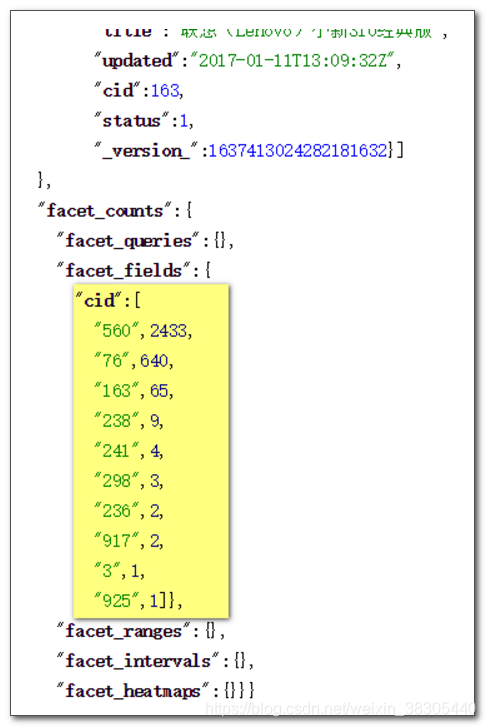
统计 cid
在统计数据的最下面可以显示记录条数
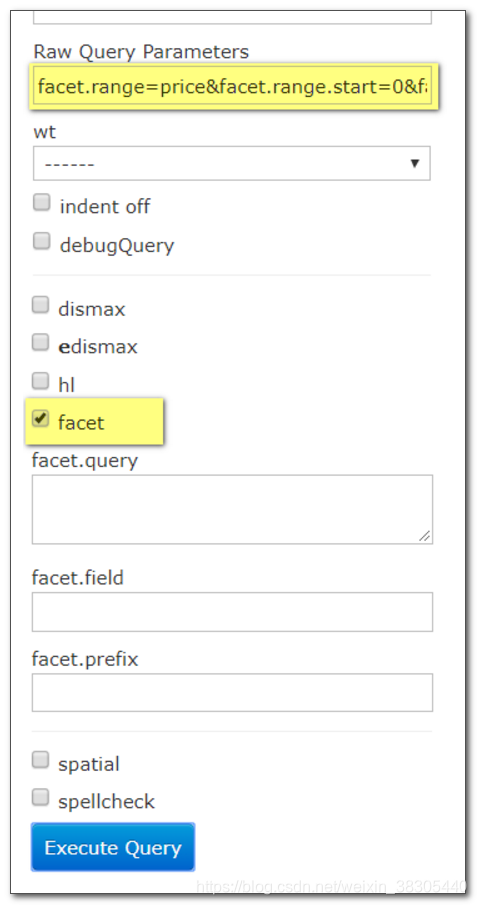
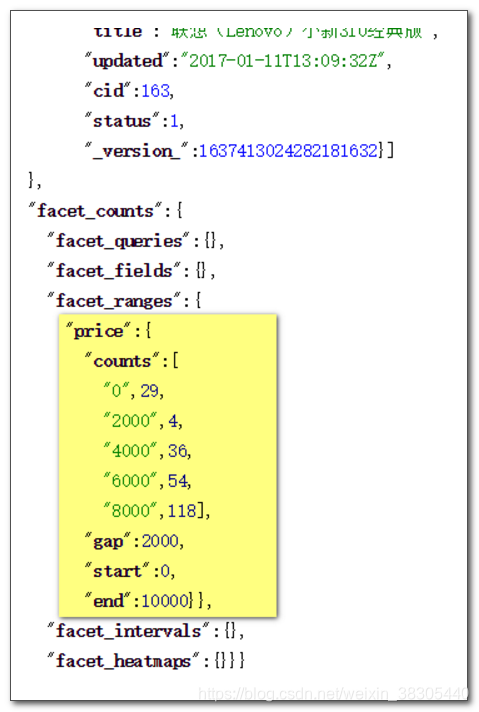
价格范围
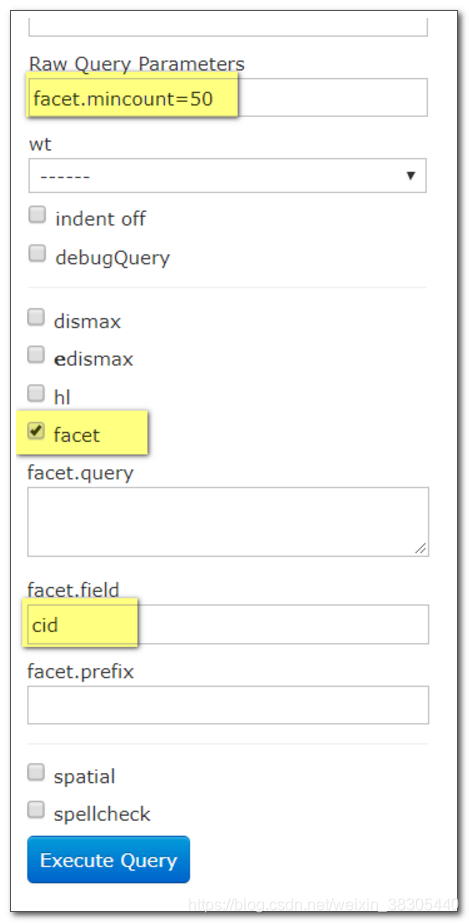
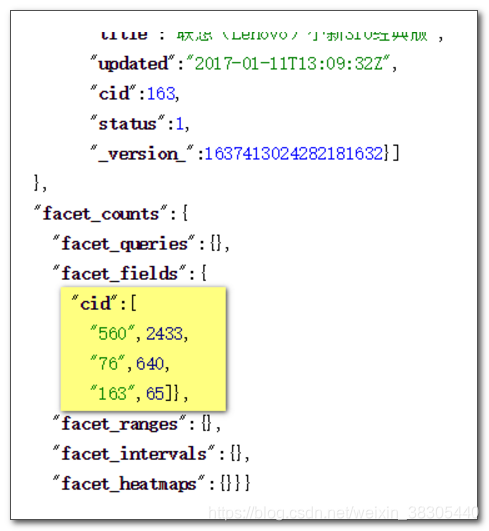
在 Raw Query Parameters 输入框中填入以下内容:
facet.range=price&facet.range.start=0&facet.range.end=10000&facet.range.gap=2000
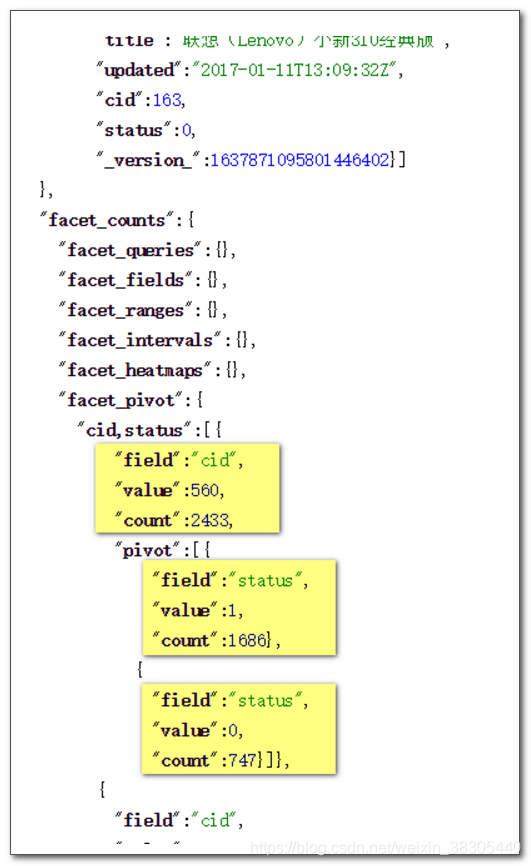
多字段统计
在 Raw Query Parameters 输入框中填入以下内容:
facet.pivot=cid,status



 浙公网安备 33010602011771号
浙公网安备 33010602011771号