pytorch中的transforms
首先我们在使用torchvision中经常会看到这个
dataset=torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
这里transform=torchvision.transforms.ToTensor(),就是让其返回的数据集是一个Tensor类型。
然后这个transforms.ToTensor()也是让一个PIL Image类型或者numpy.ndarray变成一个Tensor类型。
然后这个transforms里面还有很多操作:
transforms.ToTensor()
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img)
这个imgs可以是一个PIL Image类型或者numpy.ndarray类型
我们看一个例子:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img=Image.open("../imgs/dog.png")
print(img)
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img)
print(img_tensor)
首先我们使用PIL打开的,它的size="456*336",通道是三个,然后我们将他变成了一个Tensor类型。

transforms.Normalize()
trans_norm=transforms.Normalize([mean[1],...,mean[n]],[std[1],..,std[n]])
img_norm=trans_norm(img_tensor)
对于这个[mean[1],...,mean[n]]和[std[1],..,std[n]],假如说我们是一个三通道的RBG图像,然后这里就是三个[mean[1],mean[2],mean[3]]和[std[1],std[2],std[3]],也就是第一个通道将均值变成mean[1],方差变成std[1],第二个通道将均值变成mean[2],方差变成std[2],第三个通道将均值变成mean[3],方差变成std[3]。
例如:
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)

transforms.Resize()
transforms.Resize((h,w))
img PIL->resize->img_resize PIL
例如:
print(img.size)
trans_resize=transforms.Resize((512,512))
# img PIL->resize->img_resize PIL
img_resize=trans_resize(img)
# img PIL->totensor->img_resize tensor
img_resize=trans_totensor(img_resize)
print(img_resize.shape)
transforms.RandomCrop()
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
size:期望随机裁剪之后输出的尺寸
padding:填充边界的值,单个(int),两个([左/右,上/下]),四个(各个边界)
pad_if_needed :bool值,避免数组越界
fill:填充
padding_mode :填充模式
“constant”:利用常值进行填充
“edge”:利用图像边缘像素点进行填充
“reflect”:利用反射的方式进行填充[1, 2, 3, 4] 》[3, 2, 1, 2, 3, 4, 3, 2]
“symmetric”:对称填充方法[1, 2, 3, 4] 》》[2, 1, 1, 2, 3, 4, 4, 3]
例如:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img=Image.open("../imgs/dog.png")
trans_random=transforms.RandomCrop(128, padding=4)
trans_compose_2=transforms.Compose([trans_random,trans_totensor])
for i in range(30):
img_crop=trans_compose_2(img)
print(img_crop.shape)
writer.add_image("RandomCrop",img_crop,i)
然后我们看看效果

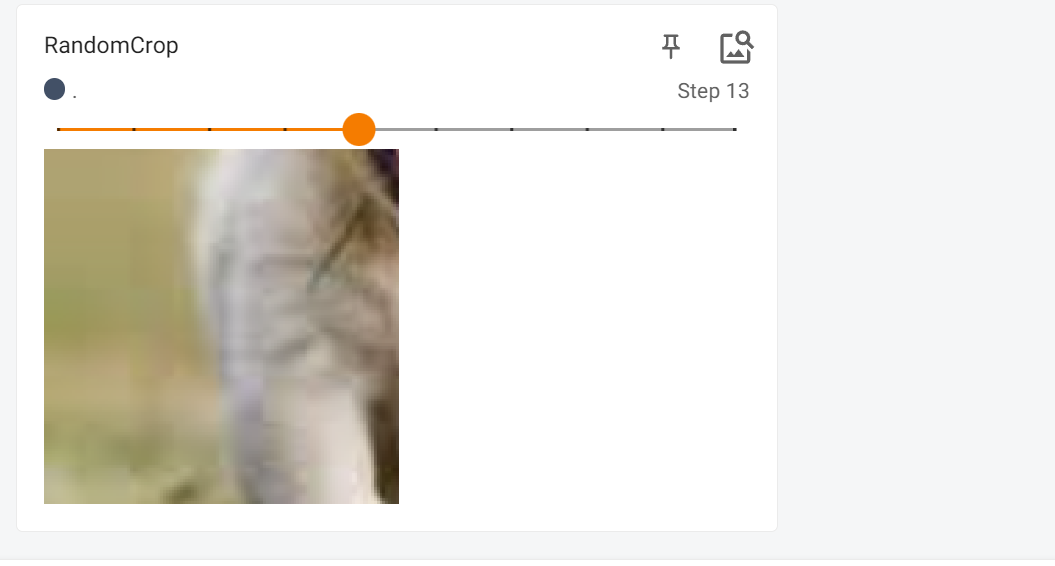
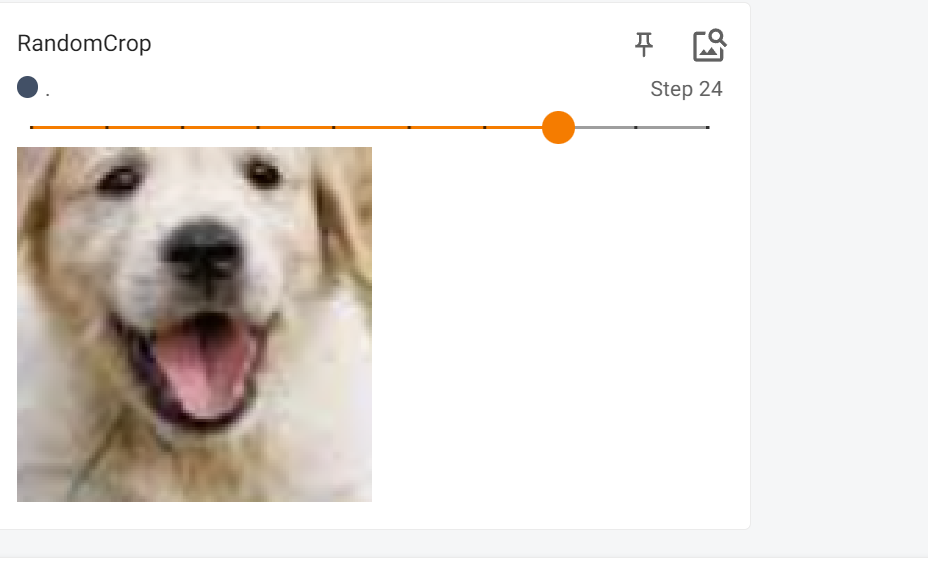
并且剪裁后它的尺寸变成了torch.Size([3, 128, 128])
RandomHorizontalFlip()
transforms.RandomHorizontalFlip()
镜像翻转
trans_randomHorizontalFlip=transforms.RandomHorizontalFlip()
for i in range(10):
trans_randomHorizontalFlip_2=trans_randomHorizontalFlip(img_resize)
writer.add_image("RandomHorizontalFlip",trans_randomHorizontalFlip_2,i)
我们可以发现这个是镜像翻转的,
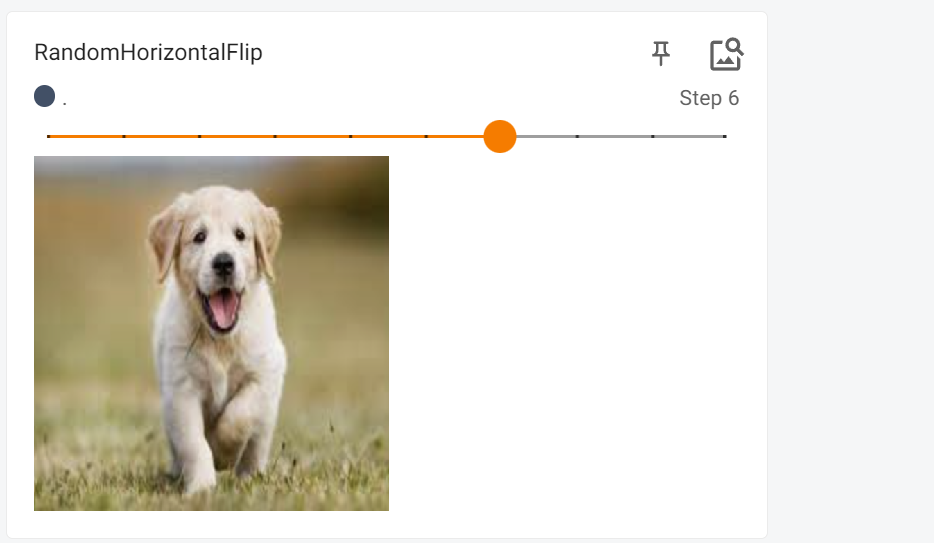
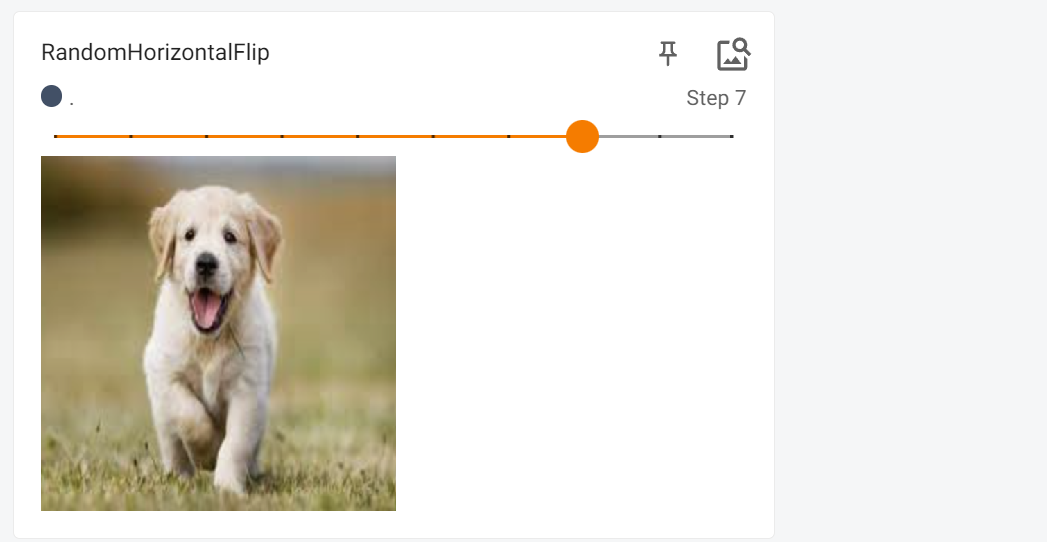
这个就是效果,镜像翻转
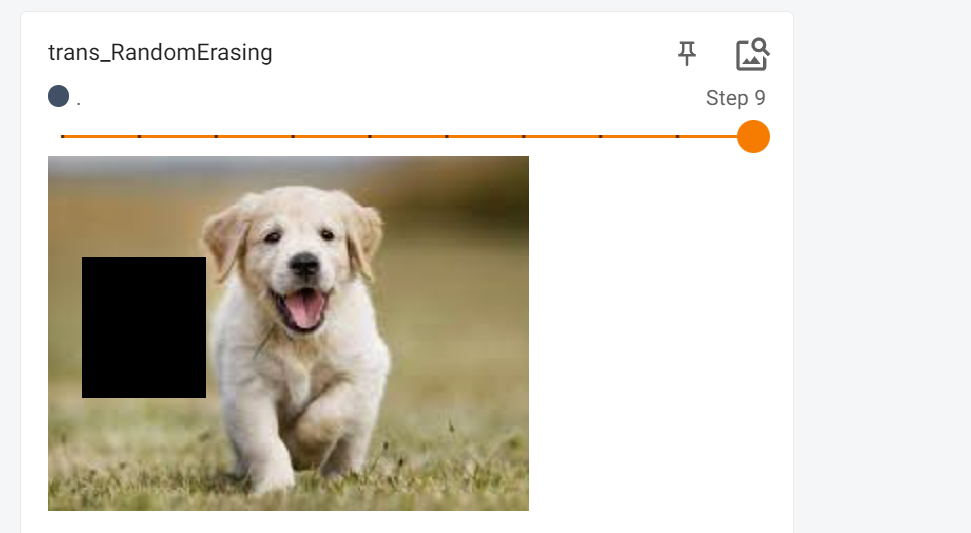
torchvision.transforms.RandomErasing()随机擦拭
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
p-执行随机擦除操作的概率。
scale-擦除区域与输入图像的比例范围。
ratio-擦除区域的纵横比范围。
value-擦除值。默认值为 0。如果是单个 int,则用于擦除所有像素。如果是长度为3的元组,则分别用于擦除R、G、B通道。如果是 ‘random’ 的 str,则使用随机值擦除每个像素。
inplace-布尔值以使此转换就地。默认设置为 False。
trans_RandomErasing=transforms.RandomErasing(scale=(0.04, 0.2), ratio=(0.5, 2)) # 随机遮挡
for i in range(10):
trans_RandomErasing_2=trans_RandomErasing(img_tensor)
writer.add_image("trans_RandomErasing",trans_RandomErasing_2,i)
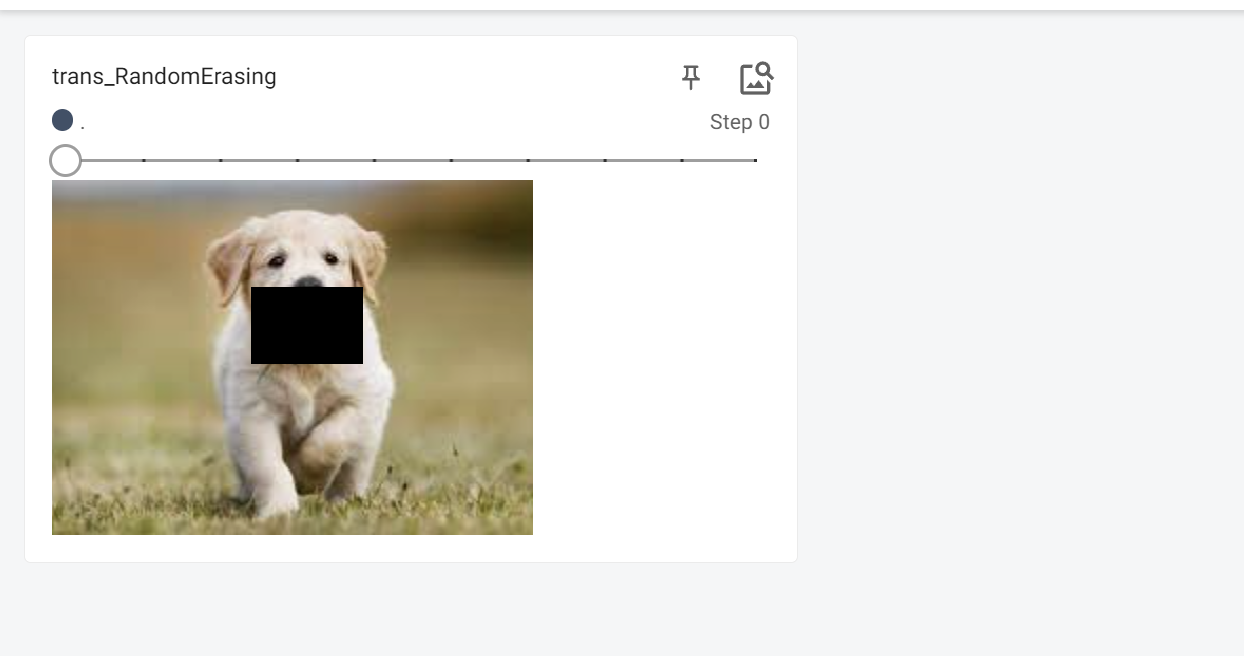
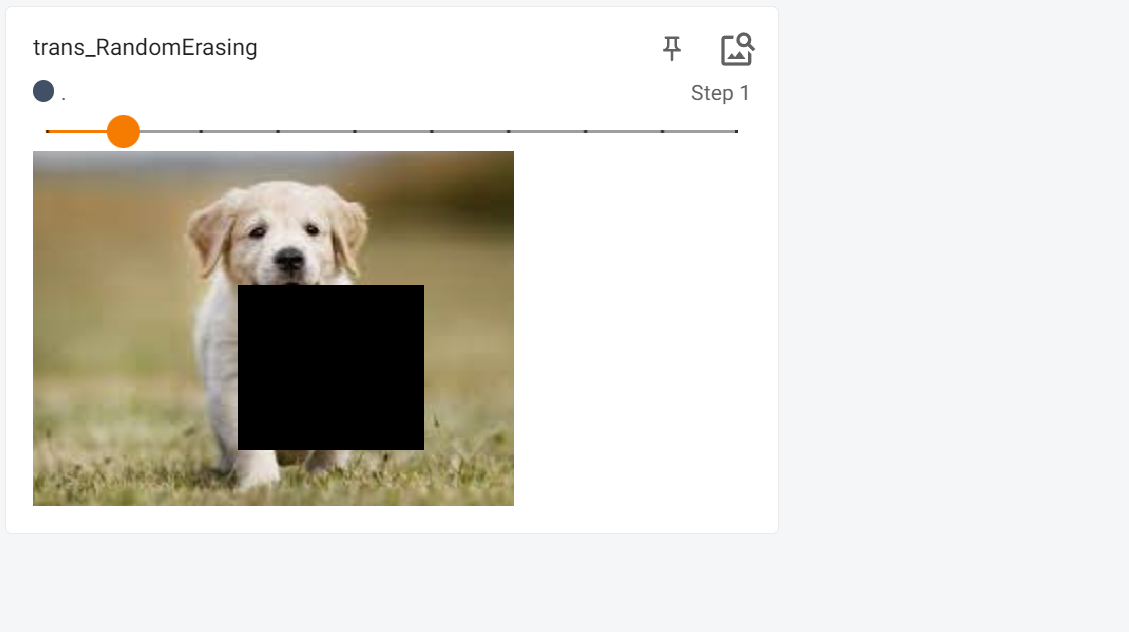
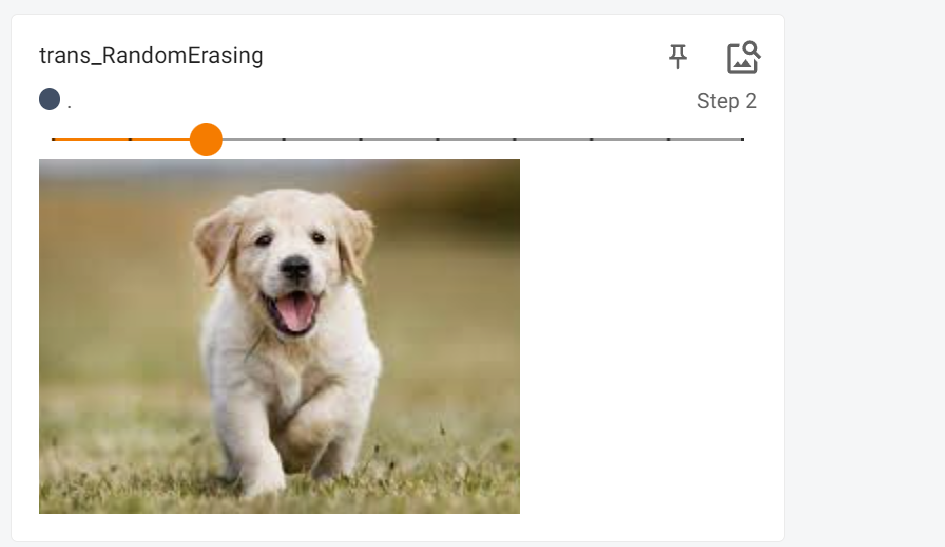
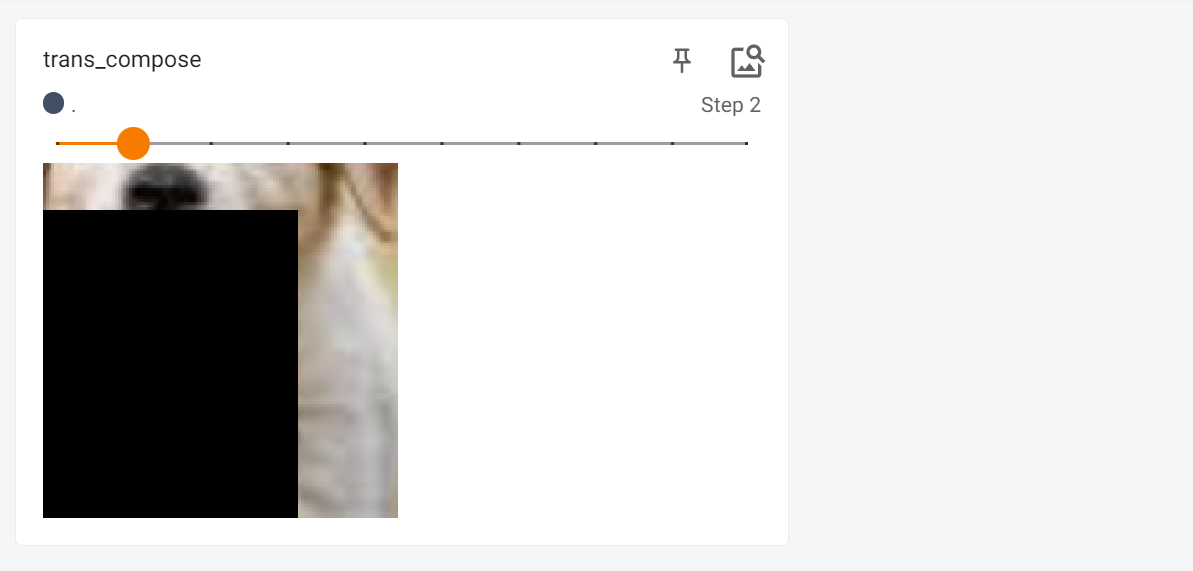
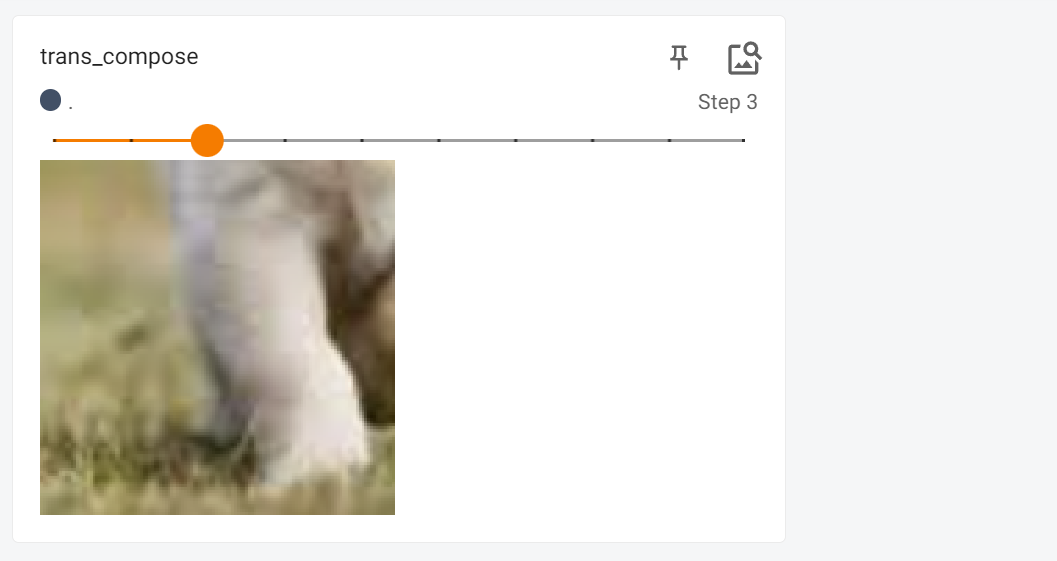
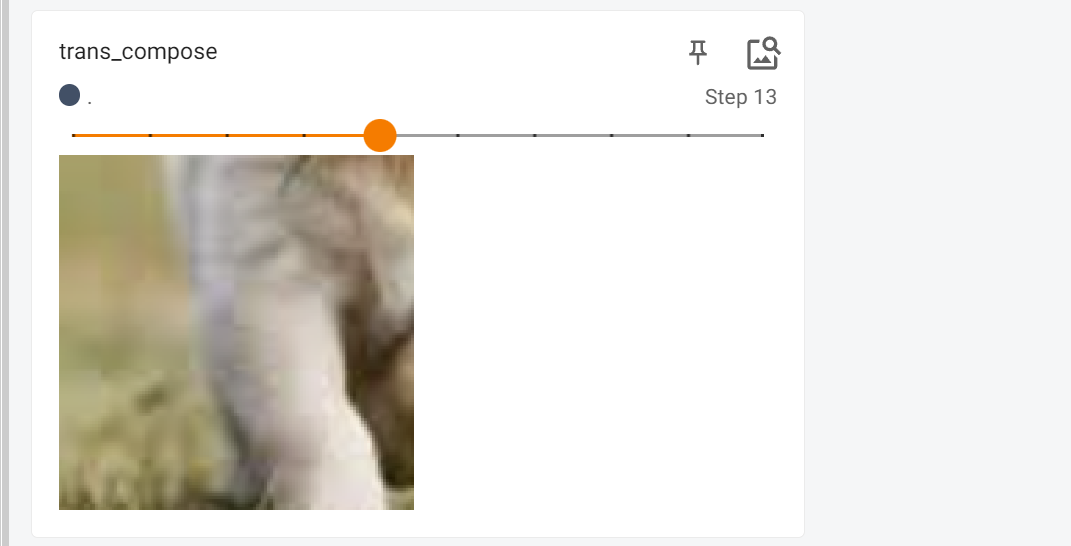
transforms.Compose()
torchvision.transforms.Compose()。
这个类的主要作用是串联多个图片变换的操作。
例如:
trans_compose = transforms.Compose([transforms.ToTensor(), # 将PILImage转换为张量
# 将[0,1]归一化到[-1,1]
# transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]),
transforms.RandomHorizontalFlip(), # 随机水平镜像
transforms.RandomErasing(scale=(0.04, 0.2), ratio=(0.5, 2)), # 随机遮挡
transforms.RandomCrop(128, padding=4) # 随机中心裁剪
])
for i in range(30):
trans_compose_2=trans_compose(img)
writer.add_image("trans_compose", trans_compose_2, i)
然后结果就是这样的:
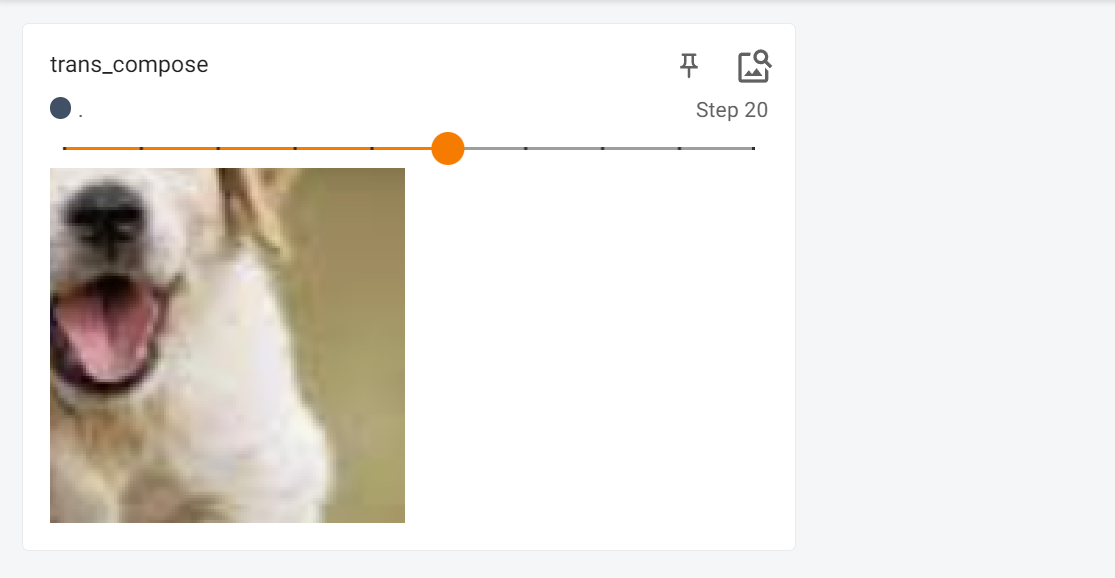
例子
# 使用torchvision可以很方便地下载Cifar10数据集,而torchvision下载的数据集为[0,1]的PILImage格式
# 我们需要将张量Tensor归一化到[-1,1]
norm_mean = [0.485, 0.456, 0.406] # 均值
norm_std = [0.229, 0.224, 0.225] # 方差
transform_train = transforms.Compose([transforms.ToTensor(), # 将PILImage转换为张量
# 将[0,1]归一化到[-1,1]
transforms.Normalize(norm_mean, norm_std),
transforms.RandomHorizontalFlip(), # 随机水平镜像
transforms.RandomErasing(scale=(0.04, 0.2), ratio=(0.5, 2)), # 随机遮挡
transforms.RandomCrop(32, padding=4) # 随机中心裁剪
])
transform_test = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)])
# 超参数:
batch_size = 256
num_epochs = 200 # 训练轮数
LR = 0.01 # 初始学习率
# 选择数据集:
trainset = datasets.CIFAR10(root='../data', train=True, download=True, transform=transform_train)
testset = datasets.CIFAR10(root='../data', train=False, download=True, transform=transform_test)
# 加载数据:
train_data = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True)
valid_data = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False)
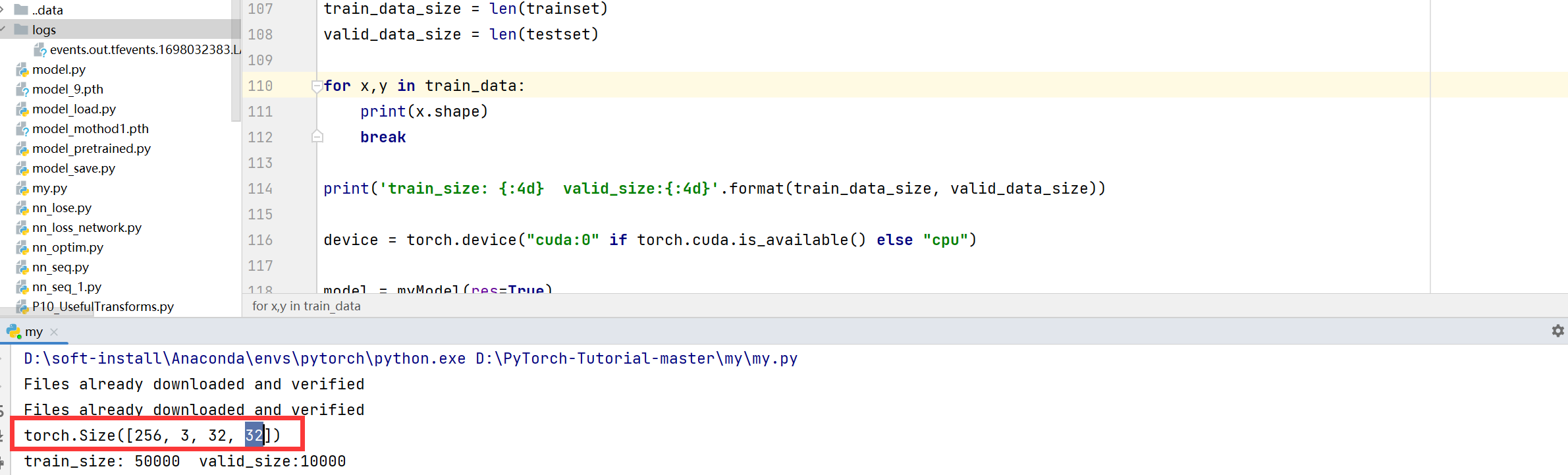
然后这就是结果
这个transforms经常会用在数据增强上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号