autogluon--自动机器学习快速训练模型
安装:
pip install autogluon
官网实例
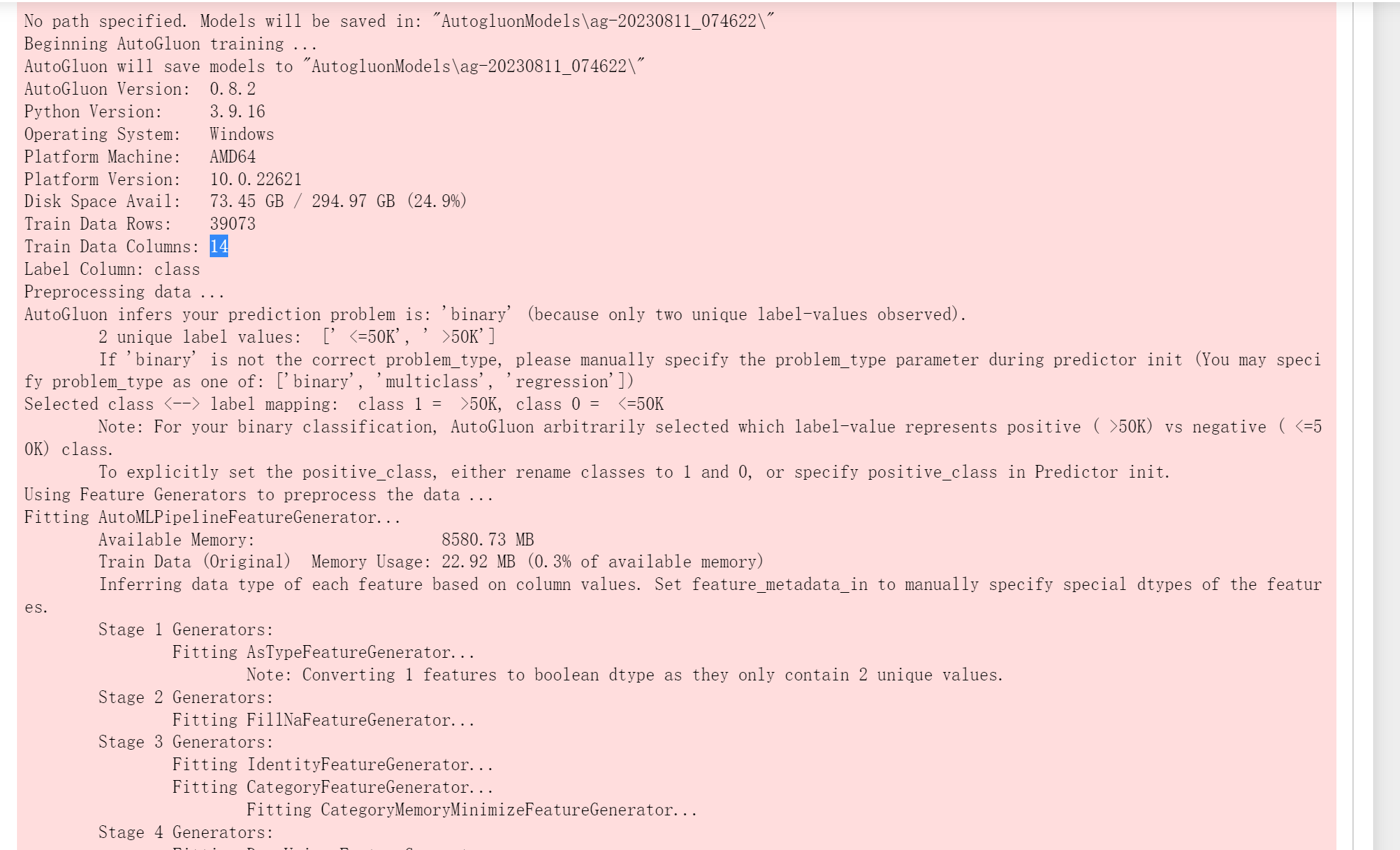
目的:预测一个人的收入是否超出5万美元
from autogluon.tabular import TabularDataset, TabularPredictor
数据读入
这里的这个TabularDataset可以用做读入。
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
train_data.head()
这边构造的AutoGluon Dataset对象,也就是TabularDataset是等同于pandas的data.frame的,所以可以用pandas.dataframe的属性来使用它,比如上面说的train_data.head()。

预测:
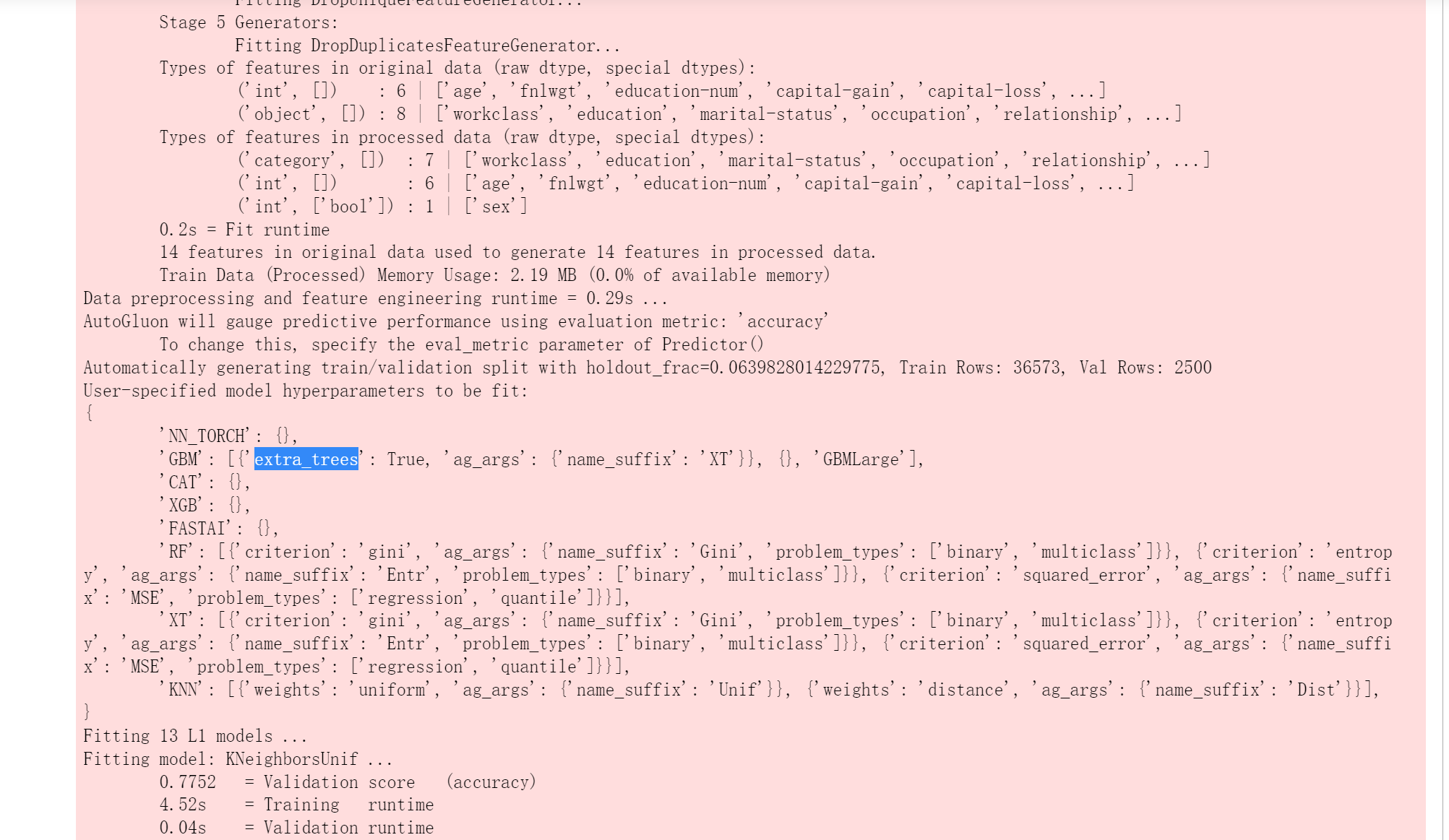
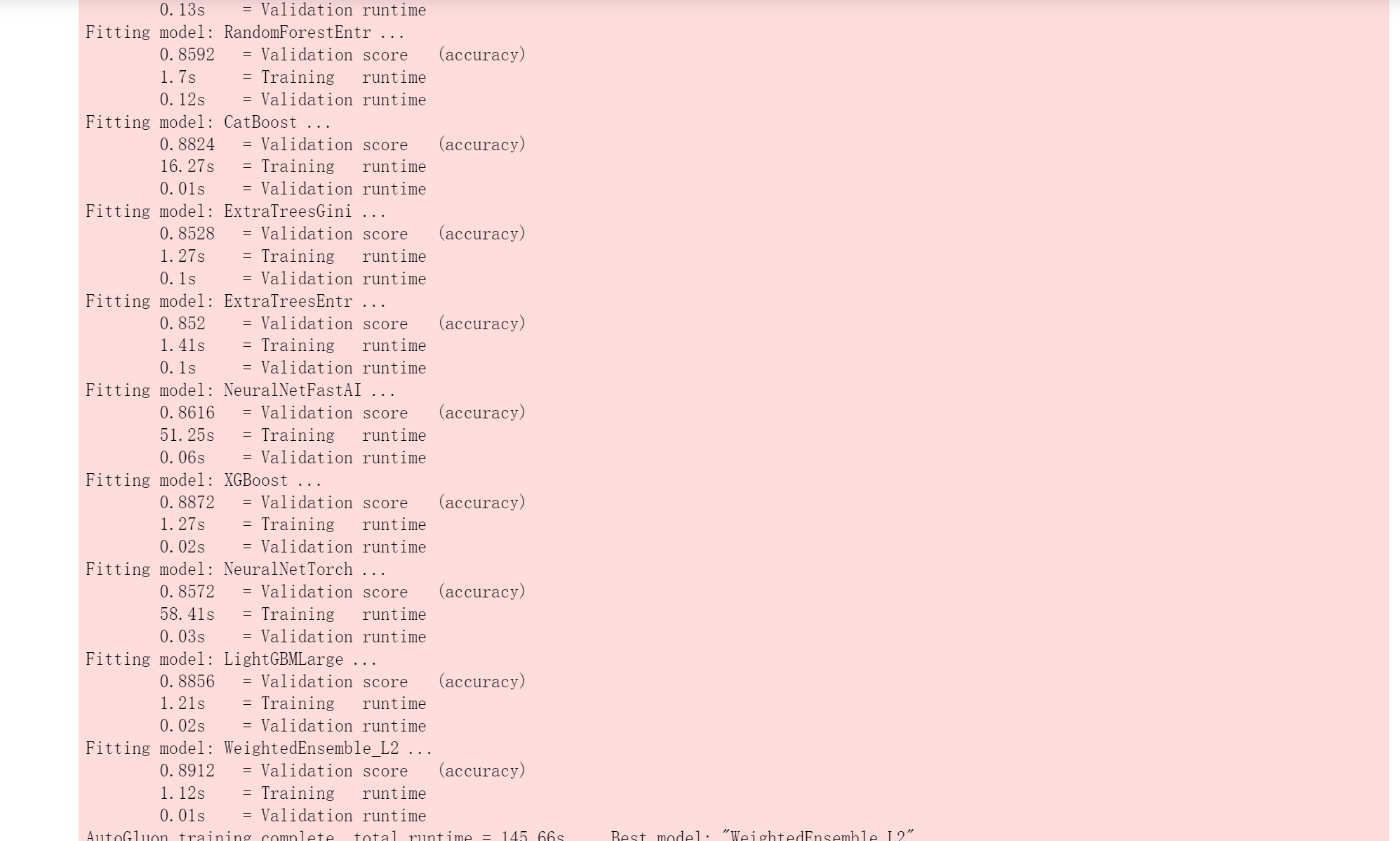
predictor = TabularPredictor(label='class').fit(train_data=train_data)
加载测试集并验证
label = 'class'
y_test = test_data[label] # values to predict
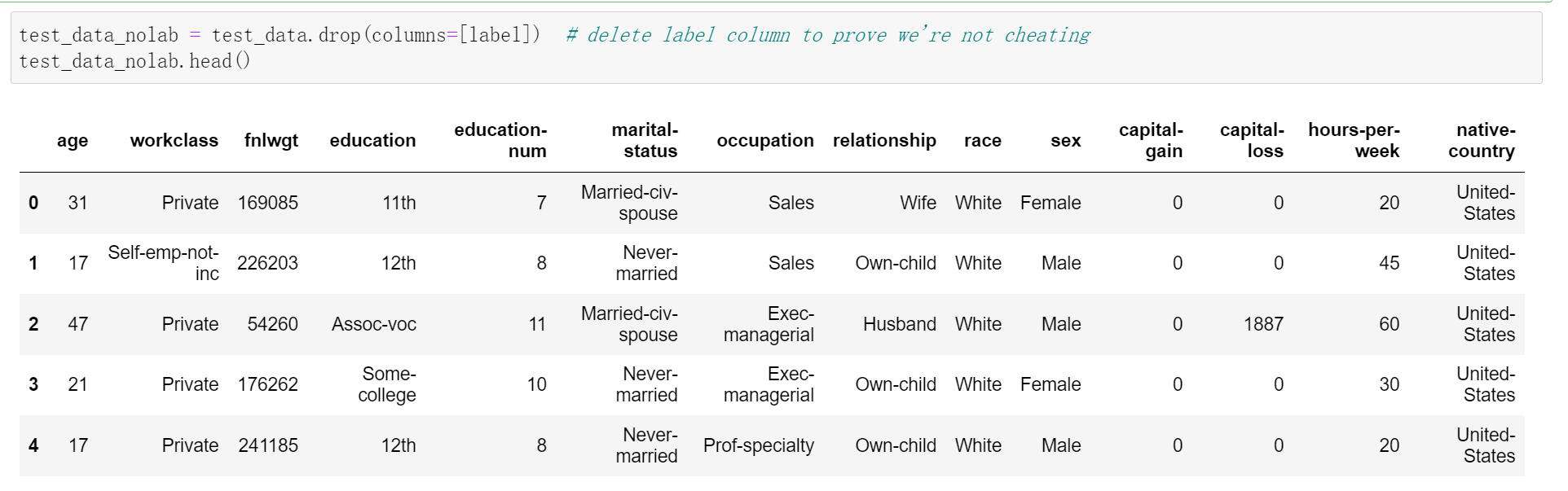
test_data_nolab = test_data.drop(columns=[label]) # delete label column to prove we're not cheating
test_data_nolab.head()
# model evalute
y_pred = predictor.predict(test_data_nolab)
print("Predictions: \n", y_pred)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
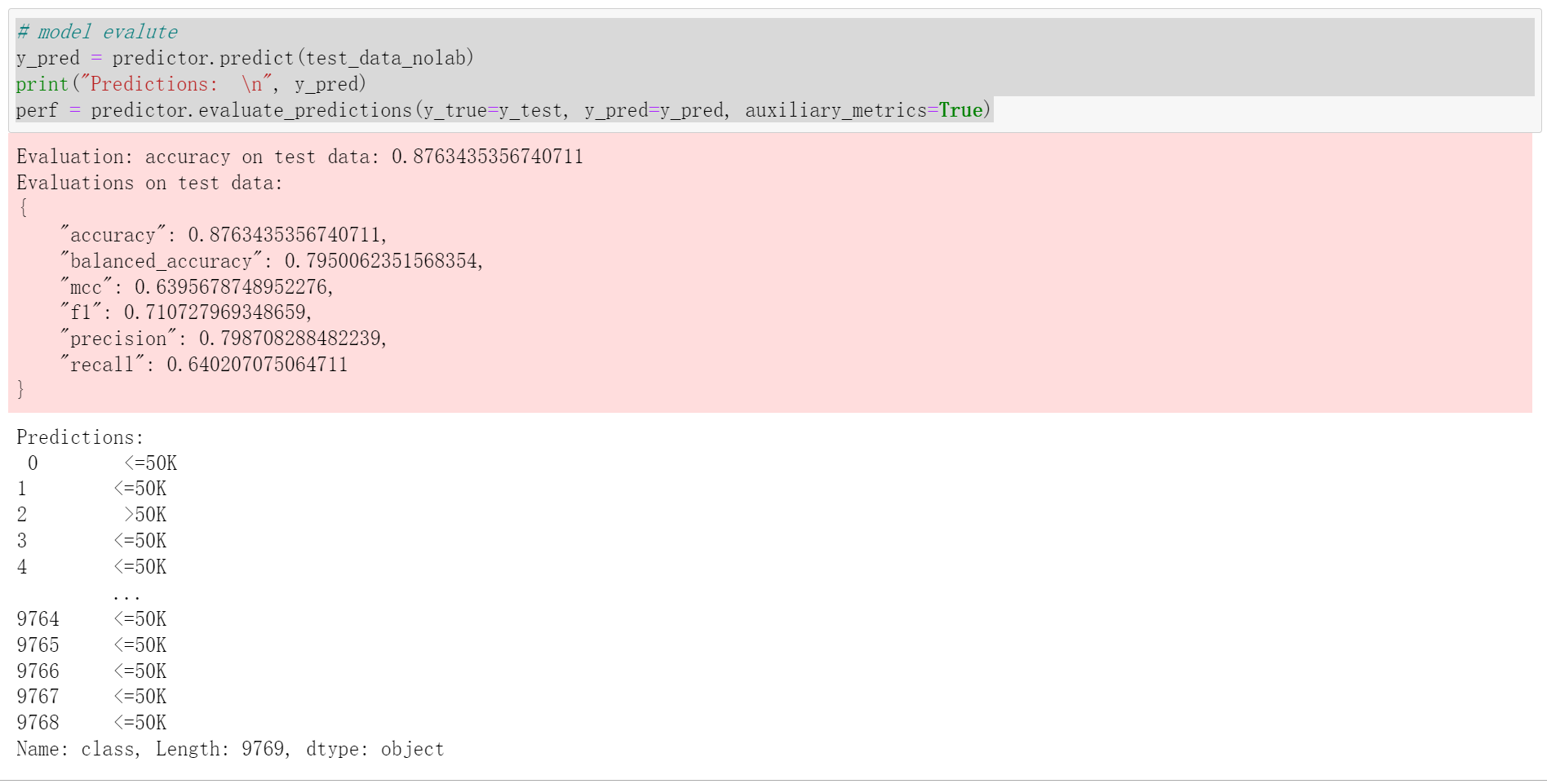
展示所有预训练模型在测试集的效能
predictor.leaderboard(test_data, silent=True)
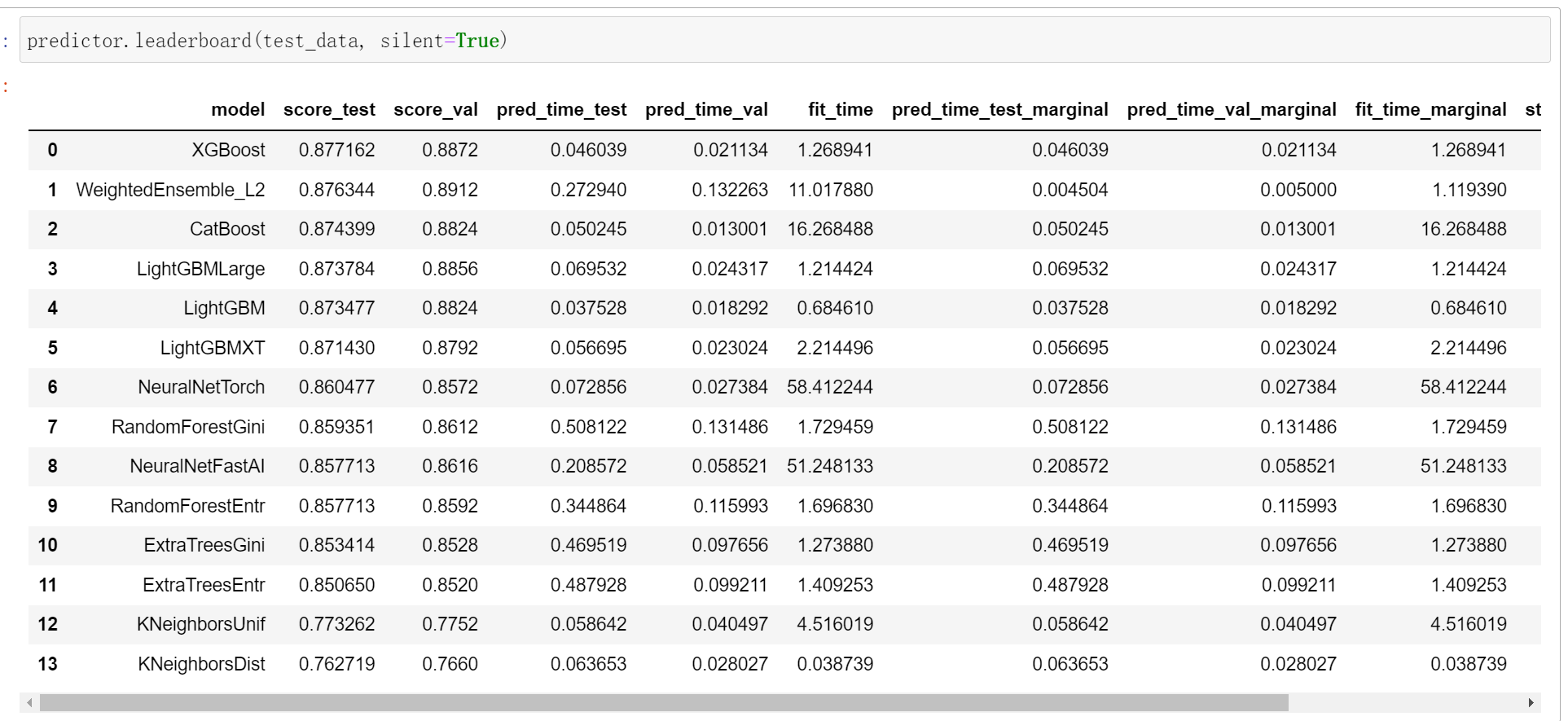
展示特定分类器的精度
predictor.predict(test_data, model='LightGBM')
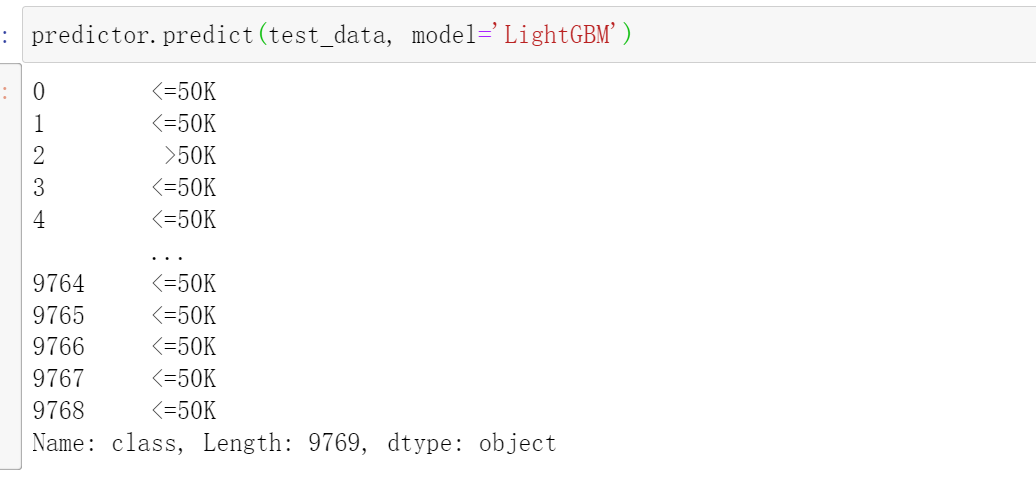
输出预测概率
pred_probs = predictor.predict_proba(test_data_nolab)
pred_probs.head(5)
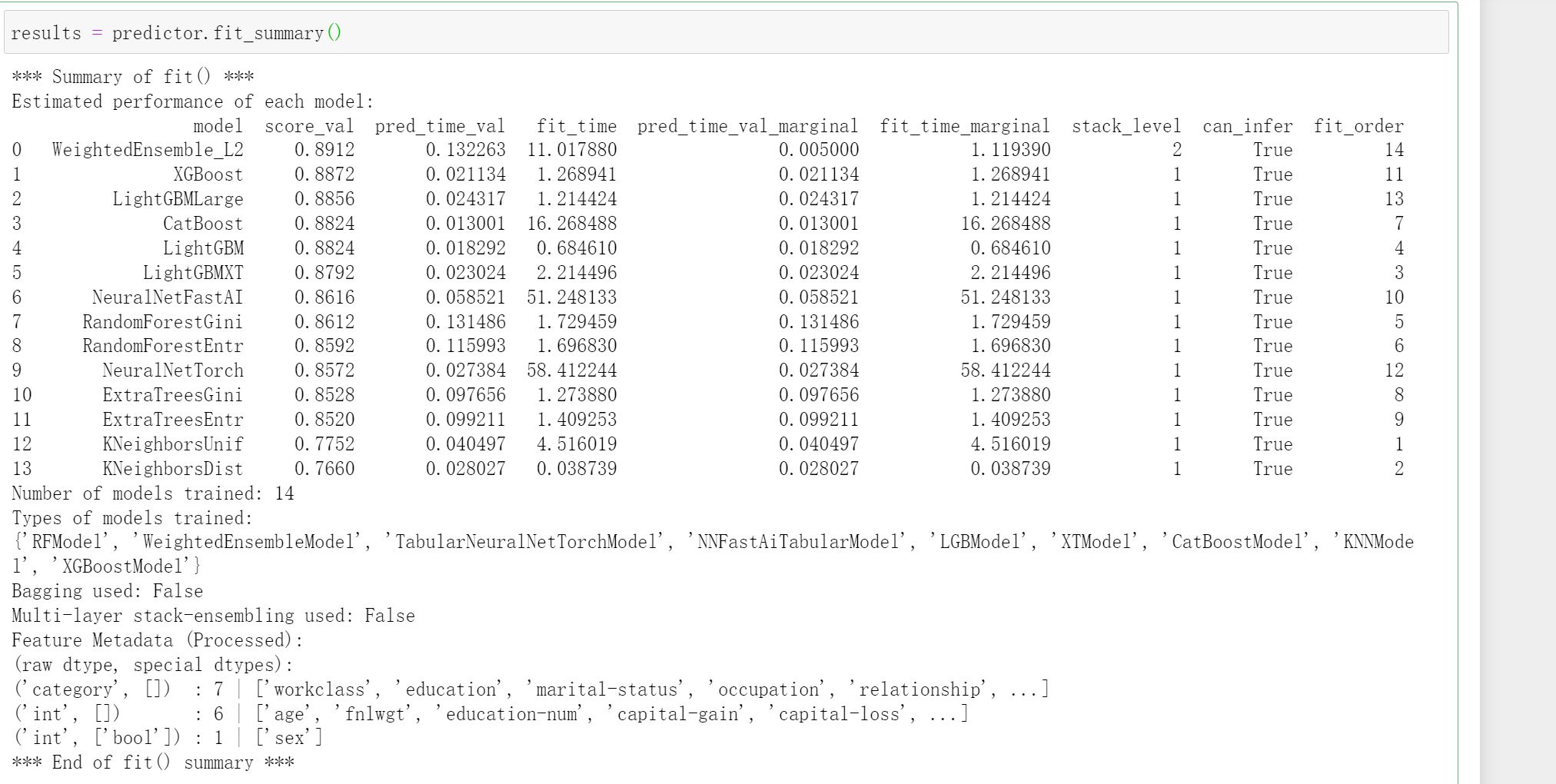
输出拟合信息
results = predictor.fit_summary()
.fit函数
time_limit : 模型训练的最长等待时间,通常不设置
eval_metric: 评估指标,AUC还是精度等
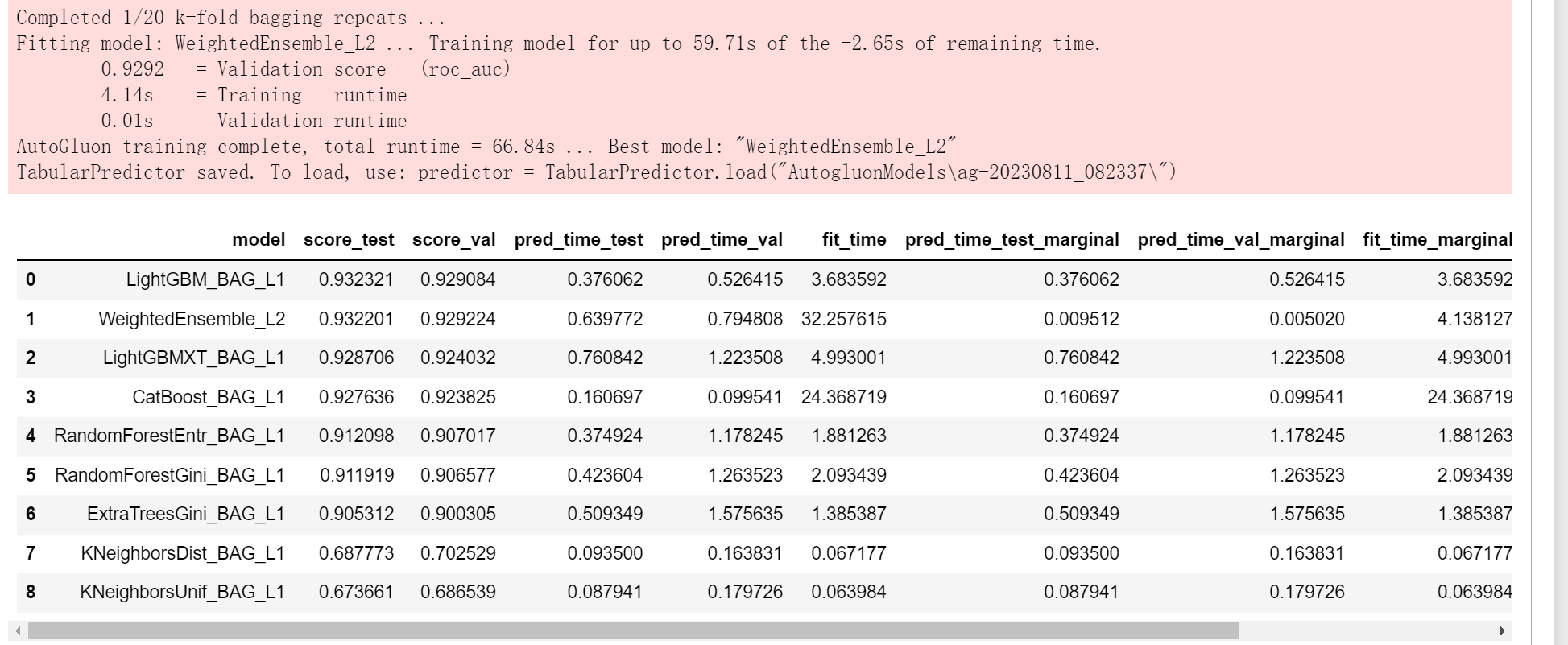
presets: 默认为’medium_quality_faster_train’,损失了精度但是速度比较快。要是设置为“best_quality”,则会做做bagging和stacking以提高性能
time_limit = 60 # for quick demonstration only, you should set this to longest time you are willing to wait (in seconds)
metric = 'roc_auc' # specify your evaluation metric here
predictor = TabularPredictor(label, eval_metric=metric).fit(train_data, time_limit=time_limit, presets='best_quality')
predictor.leaderboard(test_data, silent=True)
示例二
这是沐神比赛的时候的代码:
预测房价
from autogluon.tabular import TabularDataset, TabularPredictor
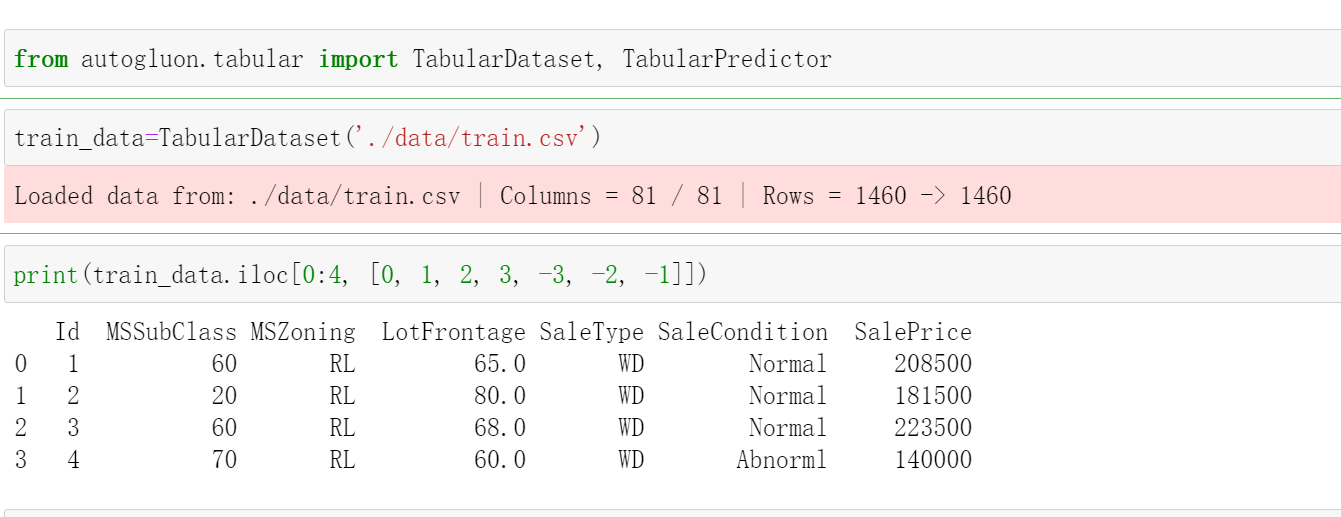
train_data=TabularDataset('./data/train.csv')
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
id,label='Id','SalePrice'
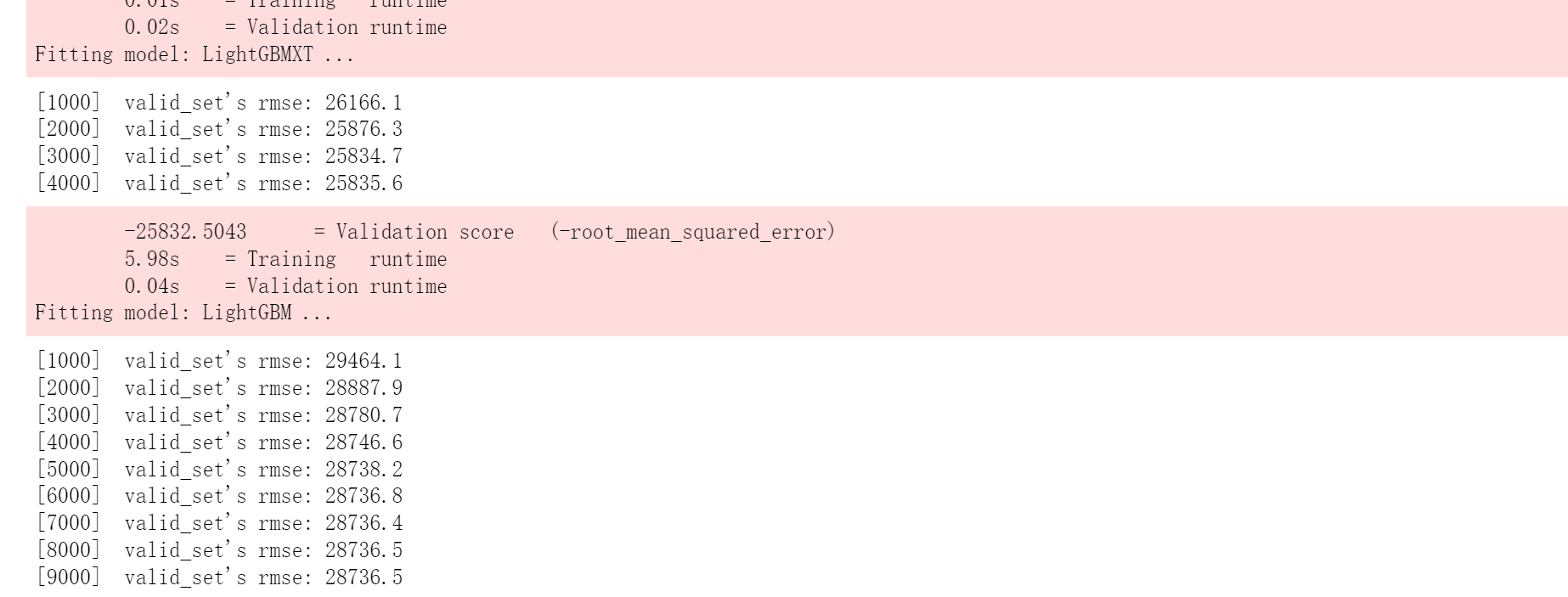
predictor=TabularPredictor(label=label).fit(train_data.drop(columns=[id]))
import pandas as pd
test_data=TabularDataset('./data/test.csv')
preds=predictor.predict(test_data.drop(columns=[id]))
保存文件
submission=pd.DataFrame({id:test_data[id],label:preds})
submission.to_csv('submission1.csv',index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号