Python数据预处理(牛客)
1 数据的生成与导入
这里主要使用的pandas
import pandas as pd
#加载excel数据
df_excel=pd.read_excel('')
df_excel.head()
#加载text数据
df_text=pd.read_table('')
df_text.head()
#加载csv数据
df_csv=pd.read_csv('')
df_csv.head()
2 读取多个数据并合并
import glob
glob.glob(path)
返回所有符合path条件的文件的路径。
import glob
#设置文件路径
path='/user/..../data2'
#合并多个数组
all_files=glob.glob(path+'/*.csv')
all_data=[]
for filename in all_files:
df=pd.read_csv(filename,index_col=None,header=0)
all_data.append(df)
data2=pd.concat(all_data,axis=0,ignore_index=True)
文件
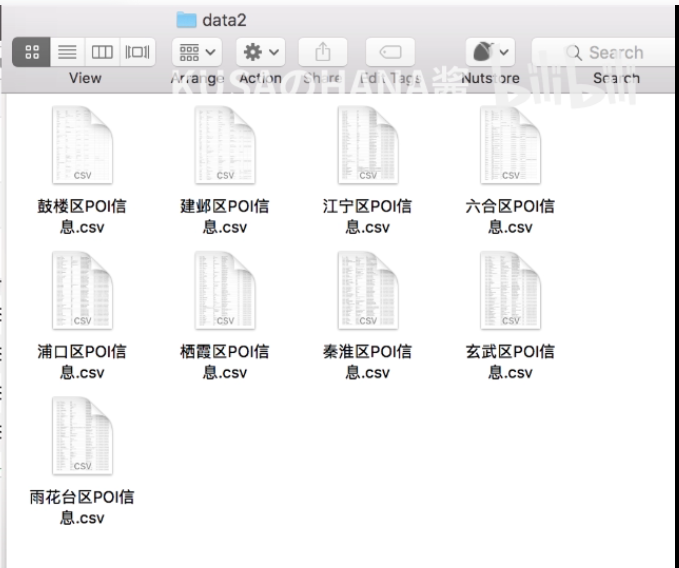


3 数据的信息查看
#查看数据规模(维度)
data.shape
#查看各变量的数据类型
data.dtypes
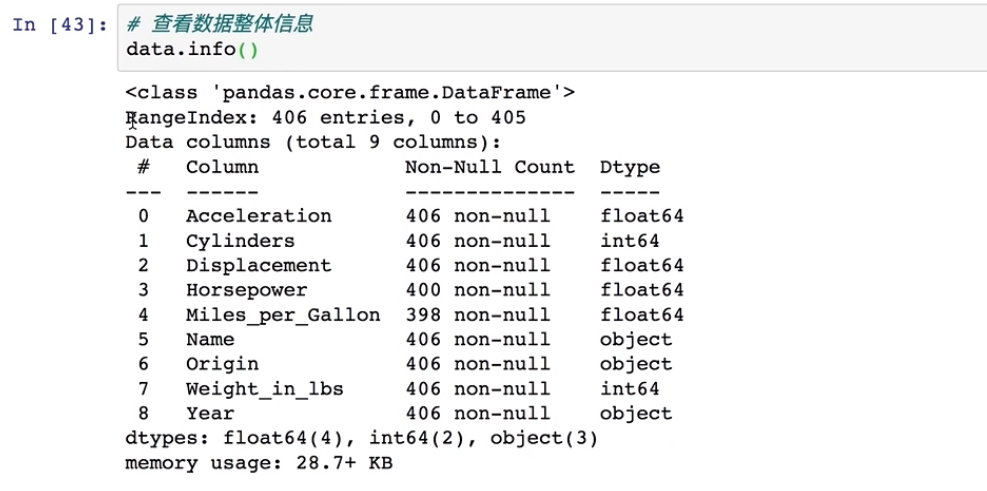
#查看数据的整体信息
data.info()
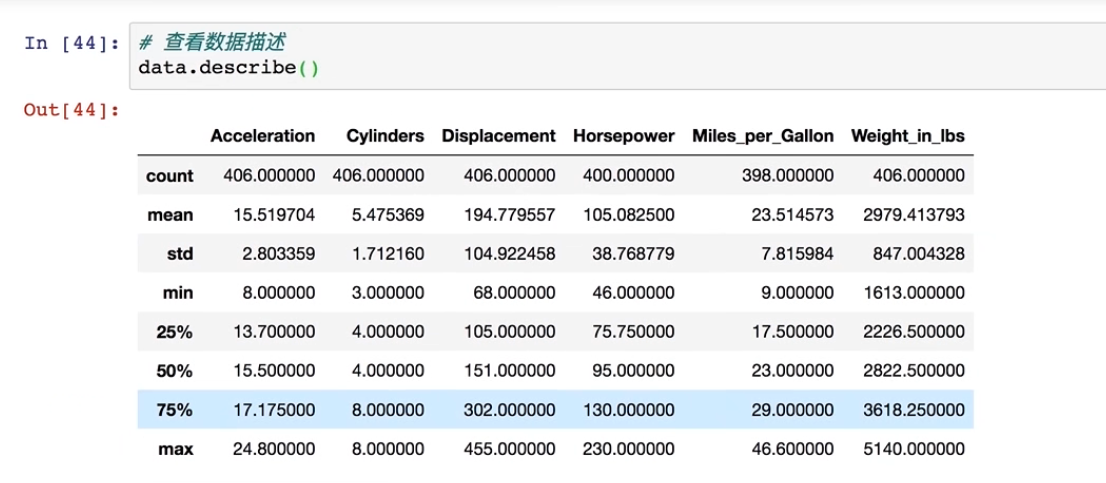
#查看数据的描述
data.decribe()
#查看数据的列名
data.columns
#查看Origin唯一值
data['Origin'].unique()
#查看数据表值
data['Origin'].values
#查看前5行
data.head()
#查看后5行
data.tail()


4 数据清洗与预处理
4.1 查找空值
这个的axis=0就是按照列为标准(一列一列看)
axis=1就是按照行为标准(一行一行看)
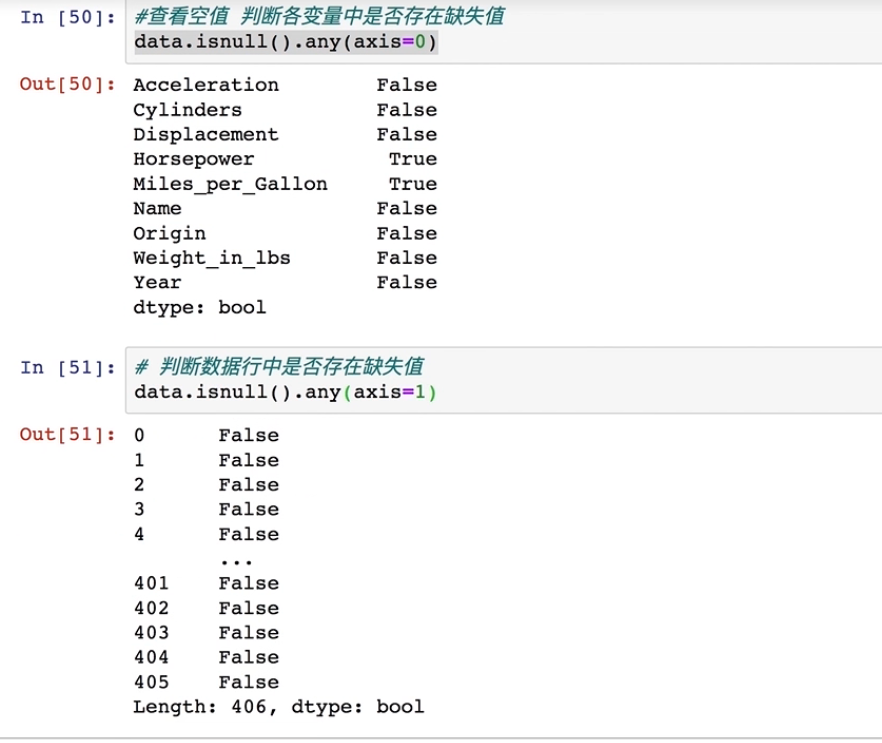
#查看空值,判断各变量中是否存在缺失值
data.isnull().any(axis=0)
#判断数据行中是否存在缺失值
data.isnull().any(axis=1)
#定位缺失值所在的行
data.loc[data.isnull().any(axis=1)]
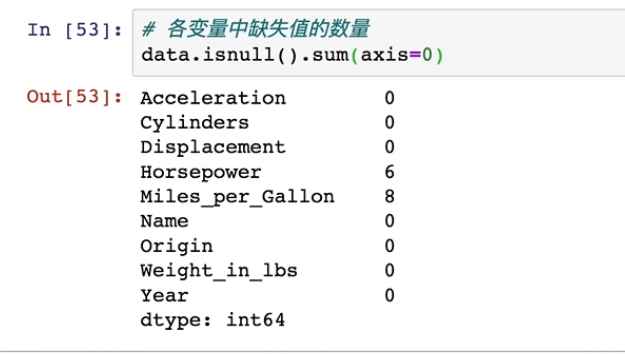
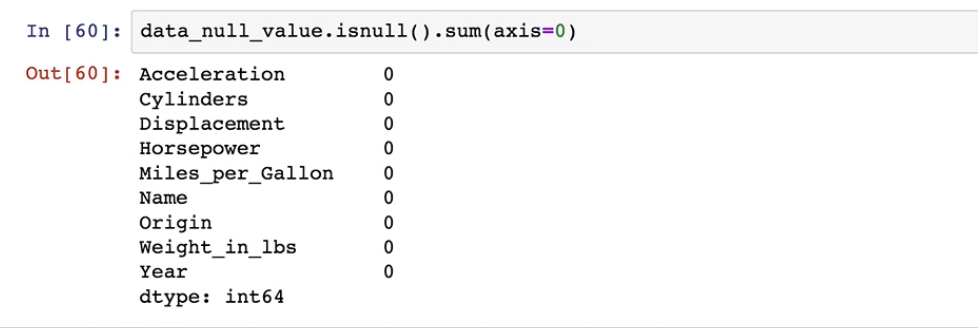
#统计各变量中的缺失值的数量
data.isnull().sum(axis=0)

4.2 处理空值
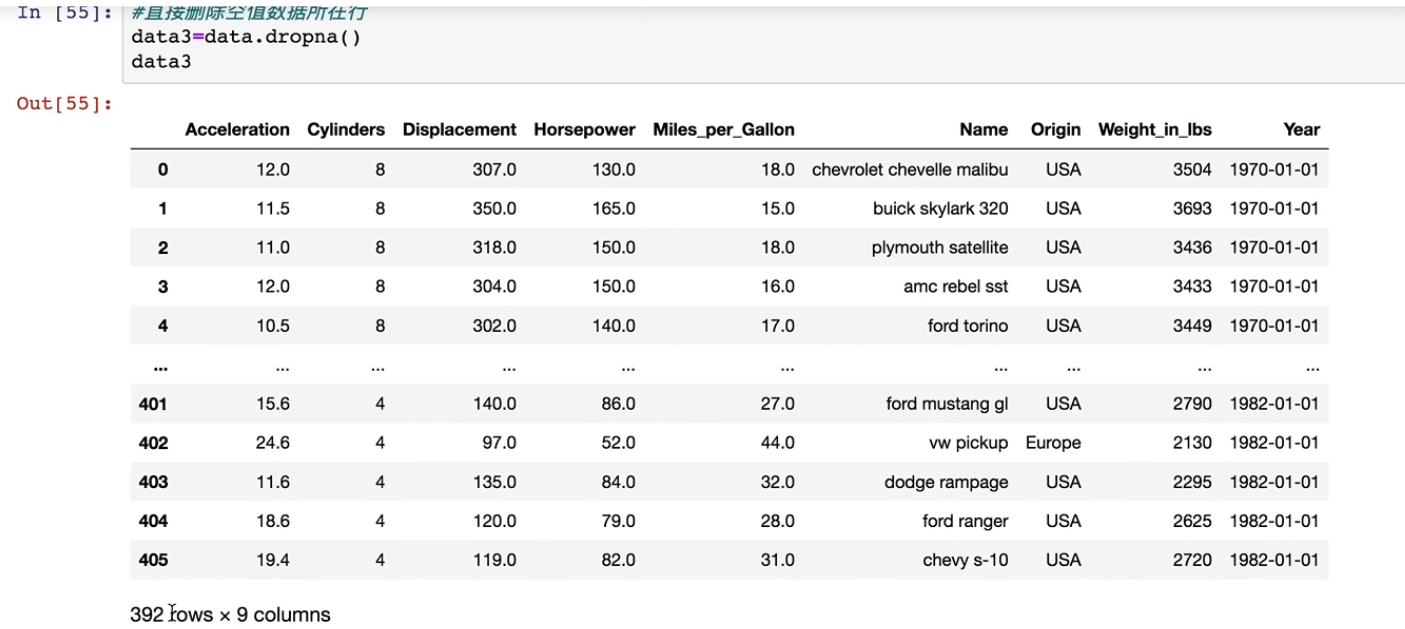
#直接删除空值所在行
data3=data.dropna()
data3
DataFrame.fillna(value=, method=, axis=, inplace=False, limit=, downcast=)
value:用于填充缺失值的值,可以是标量、字典、Series 或 DataFrame。
method:填充缺失值的方法,可选值包括 backfill(向前填充)、bfill(向后填充)、pad(用前面的非缺失数据填充)、ffill(用后面的非缺失数据填充)等。
axis:指定在哪个轴上执行填充操作。
inplace:是否在原 DataFrame 上直接进行修改,True就是把原来的DataFram修改,False反之。
limit:对于前向填充和后向填充,限制填充缺失值的最大数量。
downcast:指定填充后的数据类型,可选值包括infer(自动推断)、integer(整型)等。
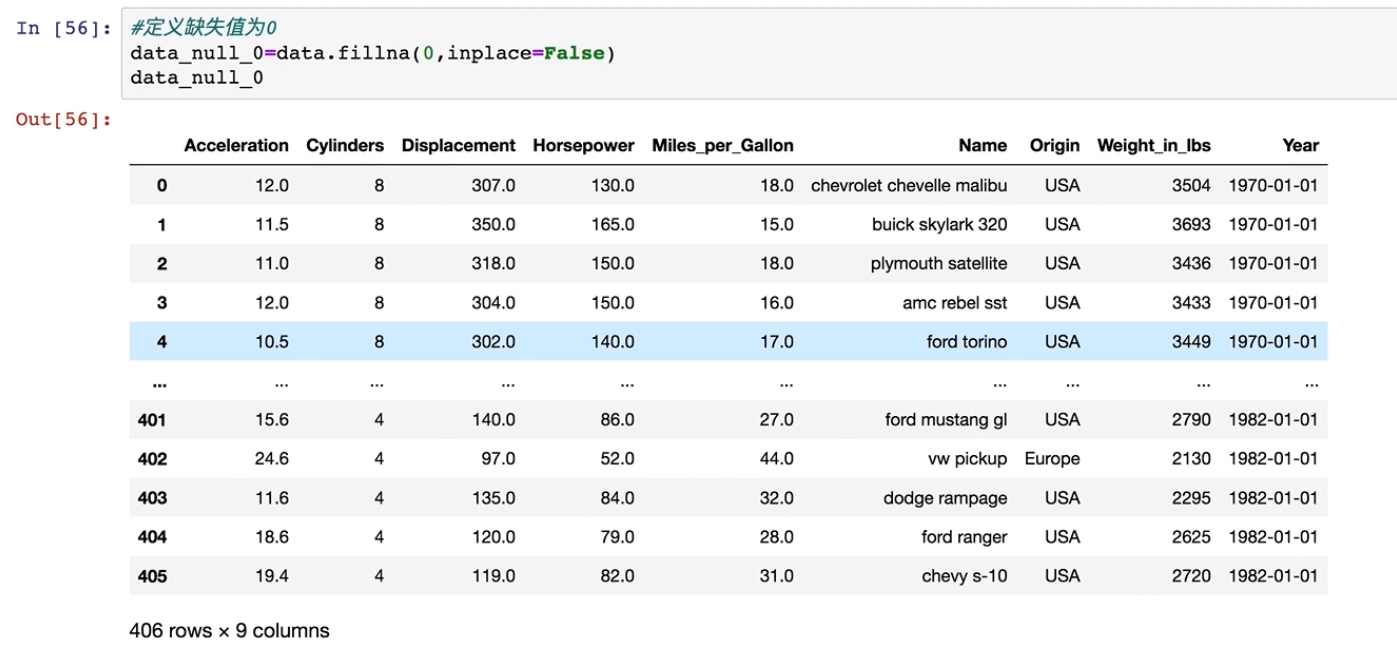
#定义缺失值为0
data_null_0=data.fillna(0,inplace=False)
data_null_0
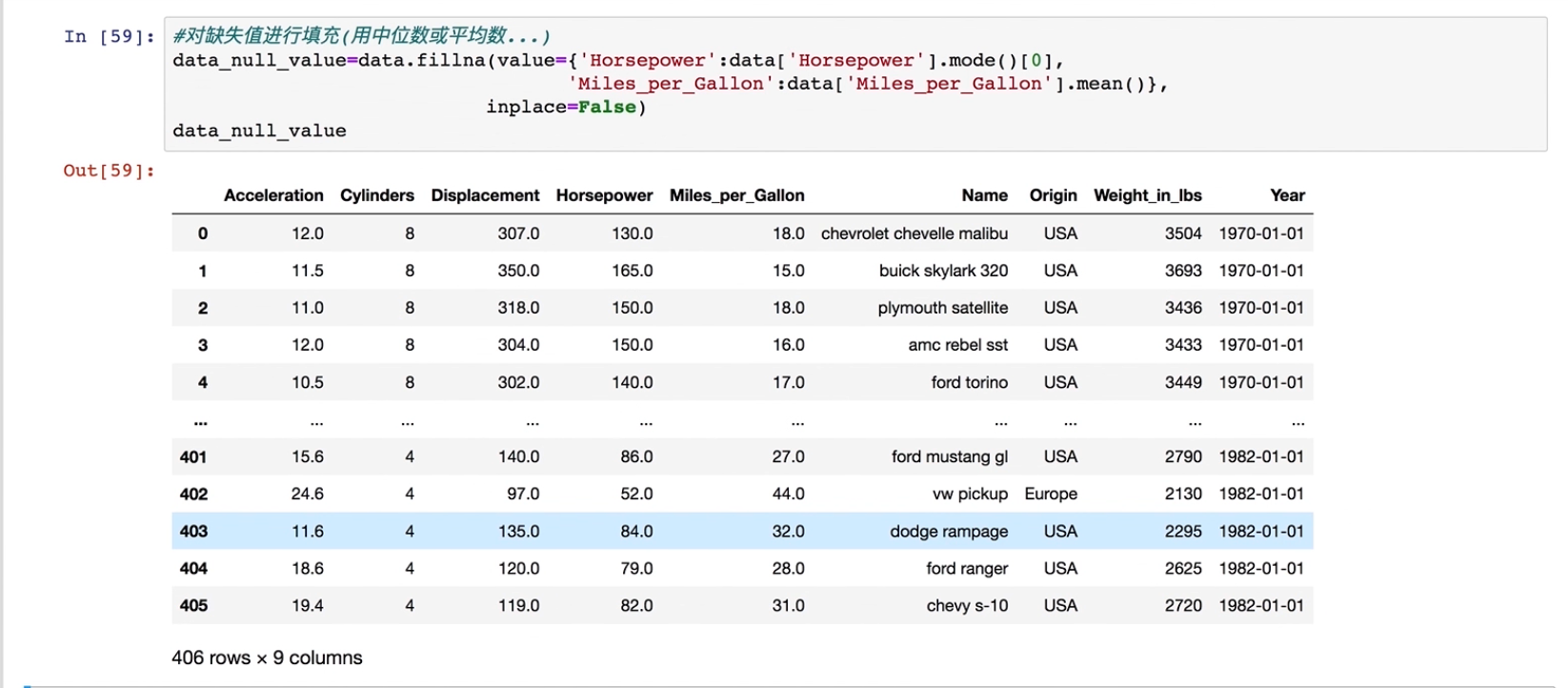
#对缺失值进行填充(用中位数或者平均数
data_null_value=data.fillna(value={'Horsepower':data['Horsepower'].mode()[0],
'Miles_per_Gallon':data['Miles_per_Gallon'].mean()},inplace=False)
data_null_value
上面是因为fillna支持字典的形式
验证:
4.3 处理重复数据
data_du=pd.read_csv('....csv')
data_du
这里一共有417rows*9columns

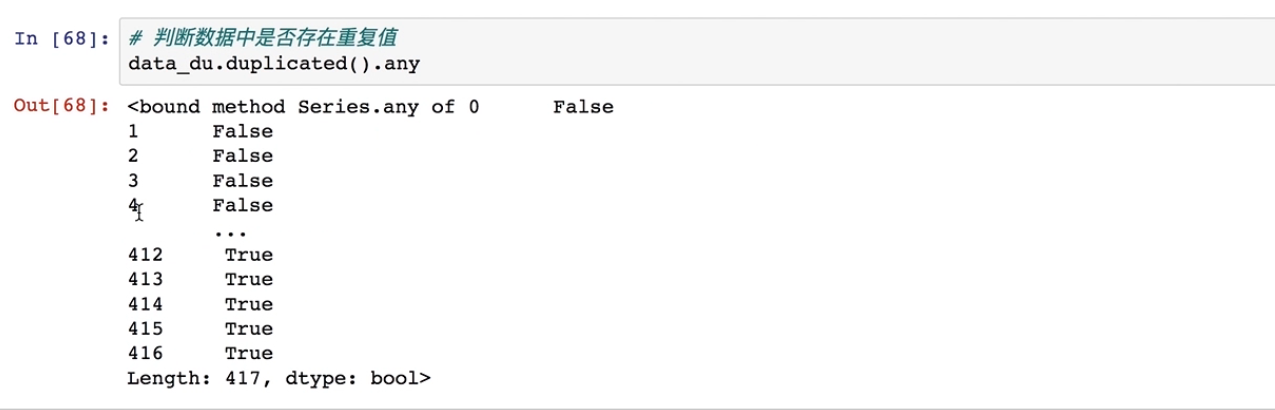
#判断数据中是否有重复值
data_du.dupilcated().any()
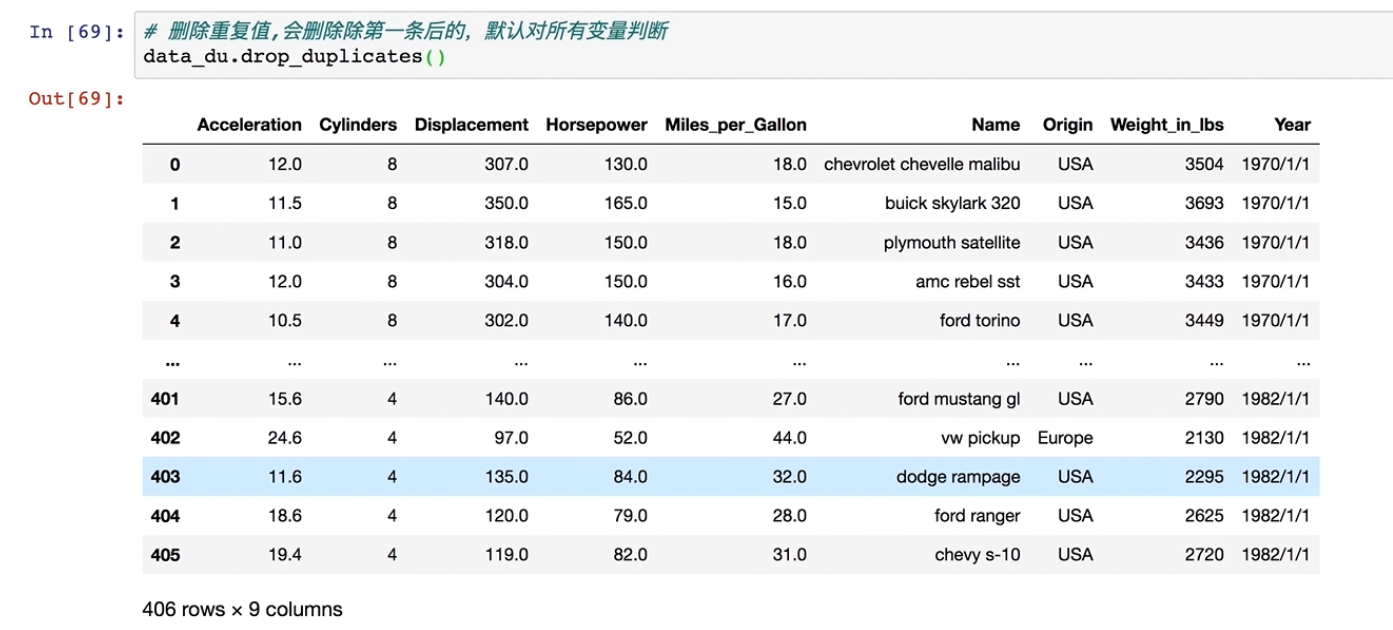
#删除重复值,会删除除第一条后的,默认对所有变量判断
data_du.drop_duplicates()
这里我们看见变成了406*9
#指定变量判断
data_du.drop_duplicates(subset=['Horsepower','Miles_per_Gallon'],keep='First',inplace=False)
#first保留第一个,inplace=True对原数据进行修改

4.4 数据的提取和筛选
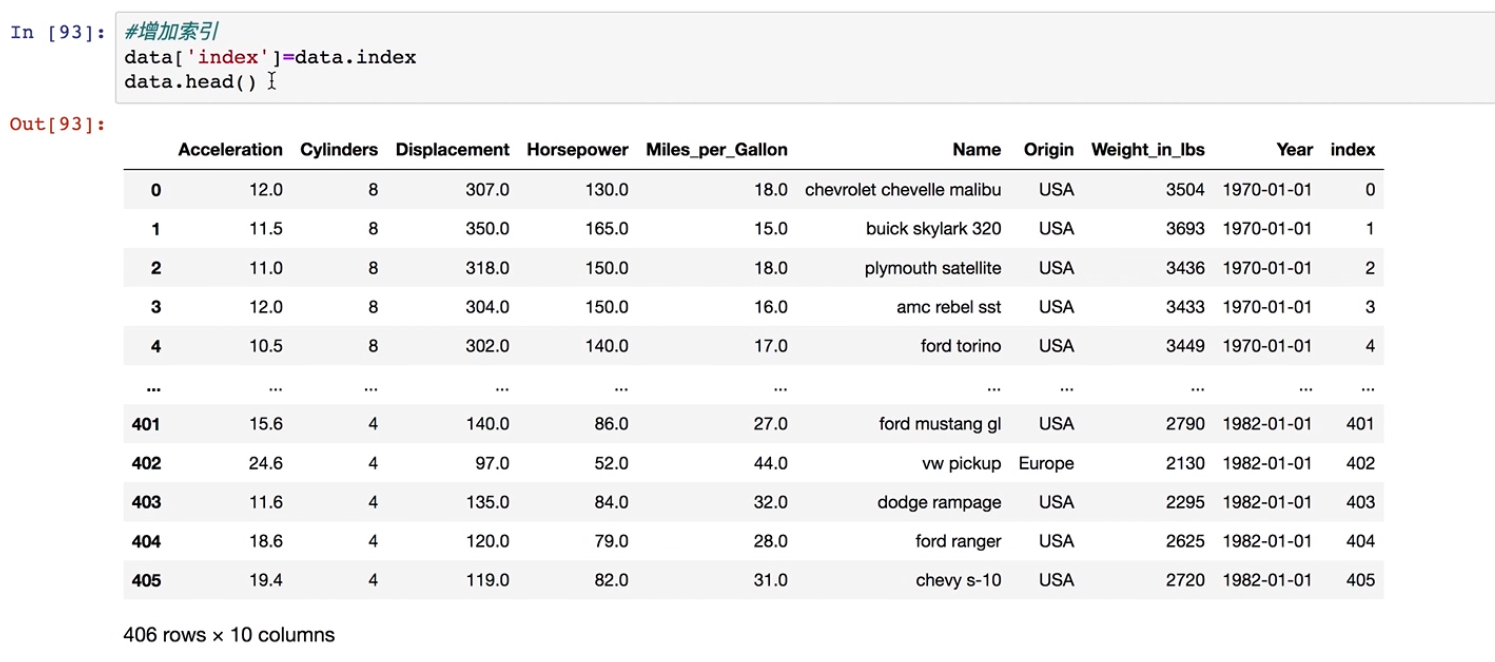
#增加索引
data['index']=data.index
data.head()
#新增一行
data['Country']=data['Origin']
data.head()
#删除特定列
data_new=data.drop(collumns='Origin')
data_new.head()
#删除特定行 #根据索引删除行
data_new=data.drop(index=1,axis=1)
data_new.head()
#删除特定几行 #根据索引删除行
data_new=data.drop(index=[1,2,3],axis=1)
data_new.head()
#某一列是否有数据'USA'
data['Country'].isin(['USA'])

#某一列有数据'USA'的全部数据
data[data['Country'].isin(['USA'])]

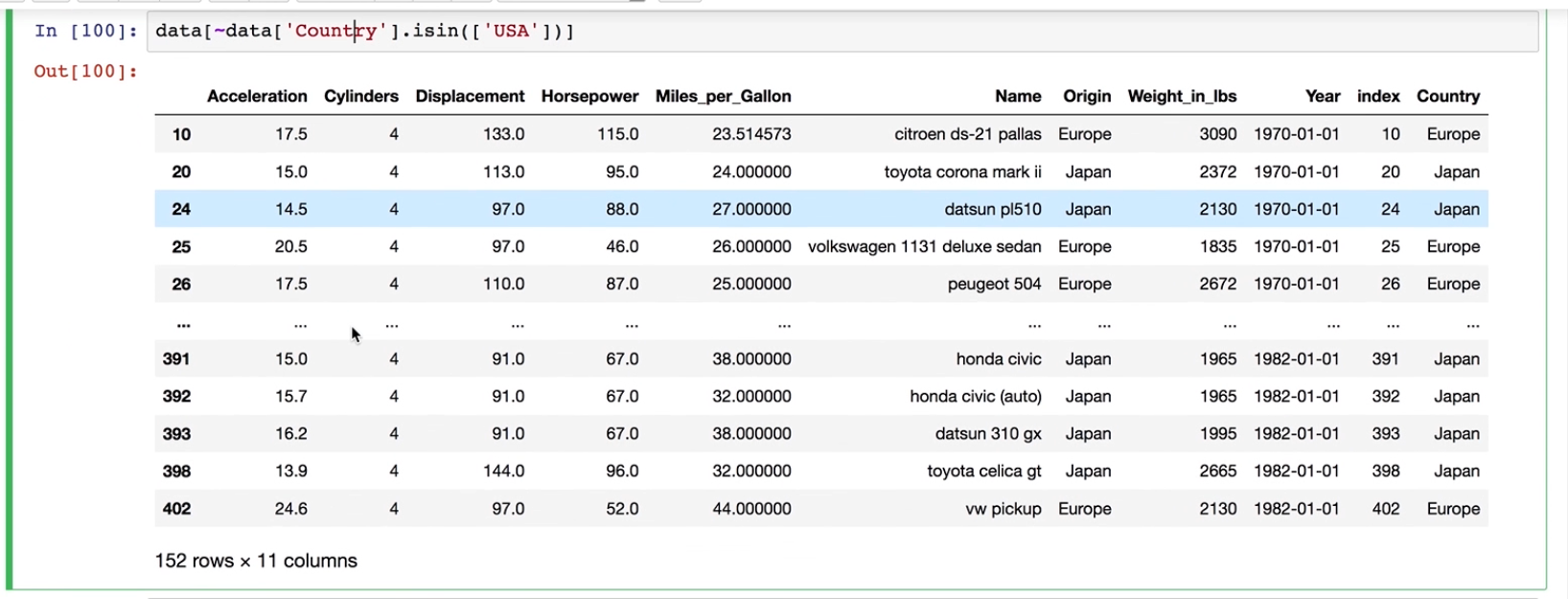
#某一列不包含数据'USA'的全部数据
data[~data['Country'].isin(['USA'])]
#某一列的数据不在某一个范围内
data[~data['Horsepower'].isin(list(range(0,200)))]

4.5 数据排序
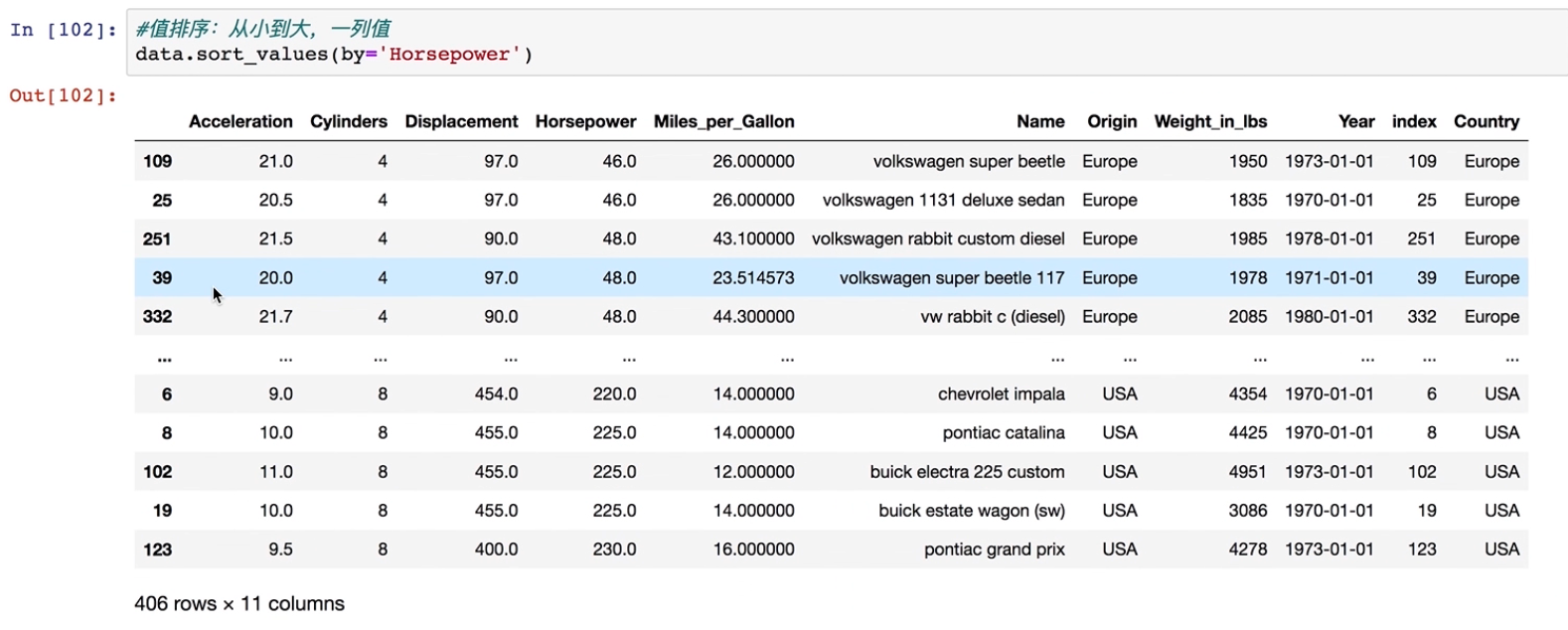
#按照值排序,从小到大,一列值
data.sort_values(by='Horsepower')
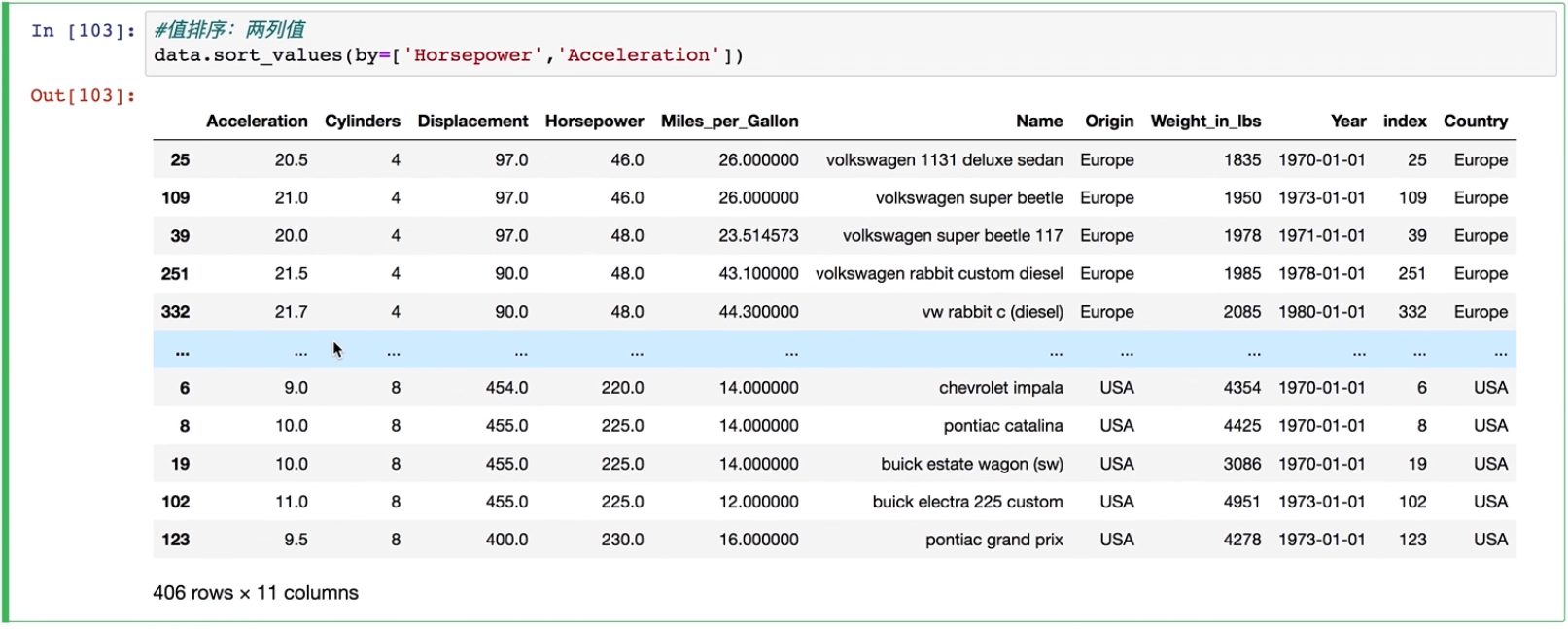
#按照值排序,两列值
data.sort_values(by=['Horsepower','Acceleration'])
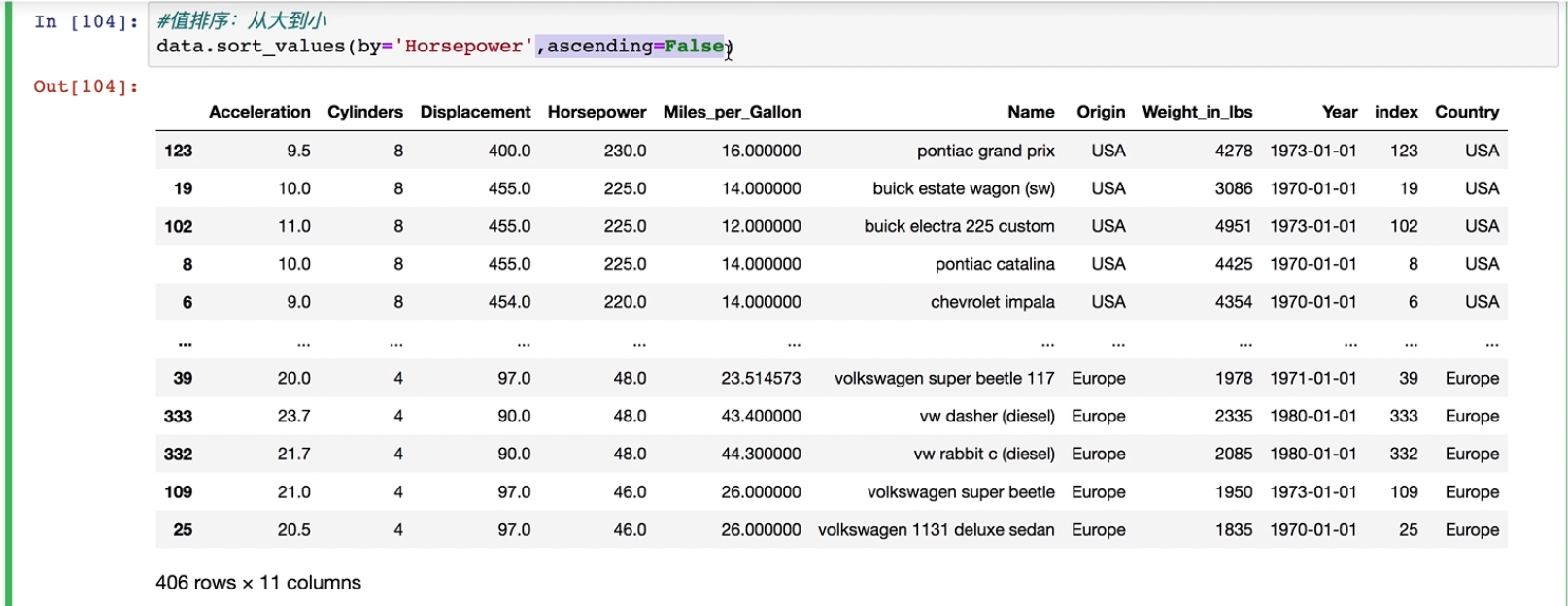
#值排序,从大到小
data.sort_values(by='Horsepower',ascending=False)
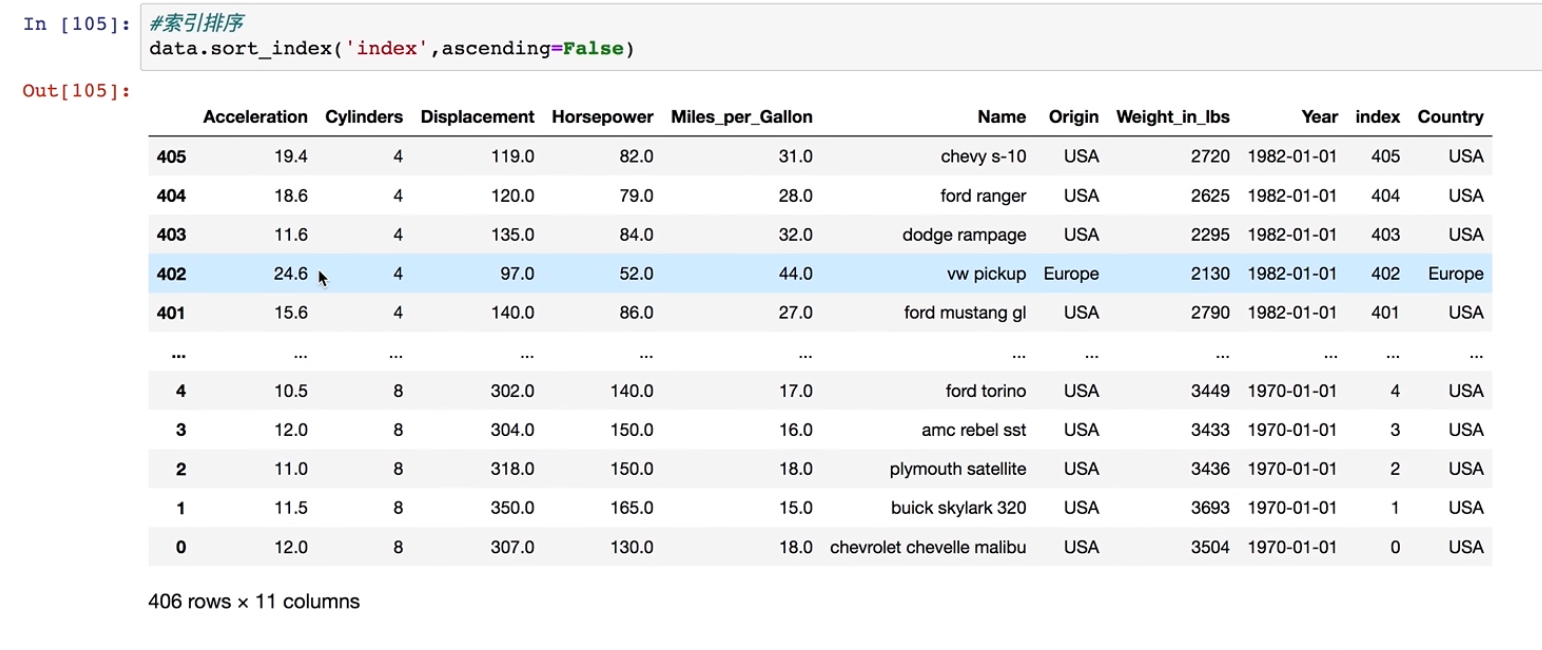
#索引排序
data.sort_index('index',ascending=False)
4.6 数据汇总
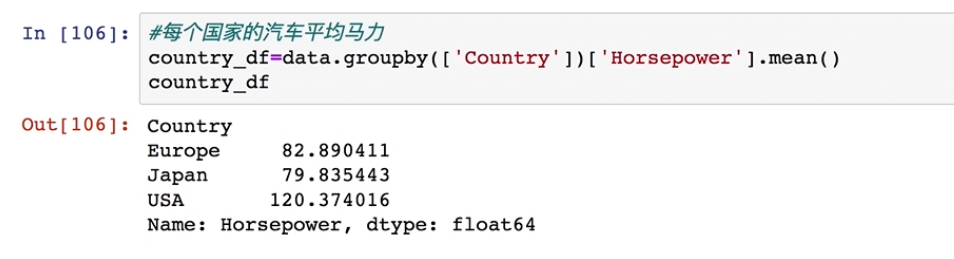
#每个国家的汽车的平均马力
country_df=data.groupby(['Country'])['Horsepower'].mean()
country_df
这个先按照国家分组,然后每个分组的数据是这个平均值
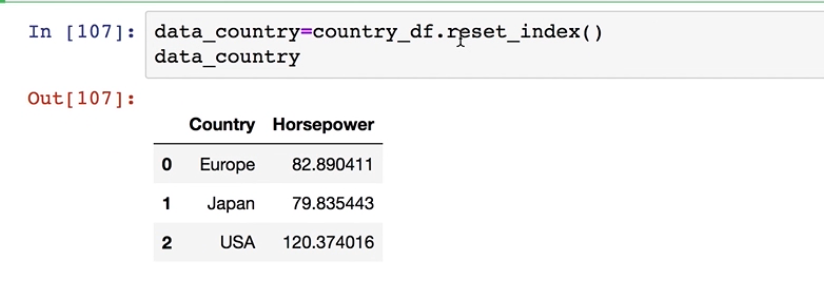
#上面排好序的数据重新按照索引进行排序
data_country=country_df.reset_index()
data_country
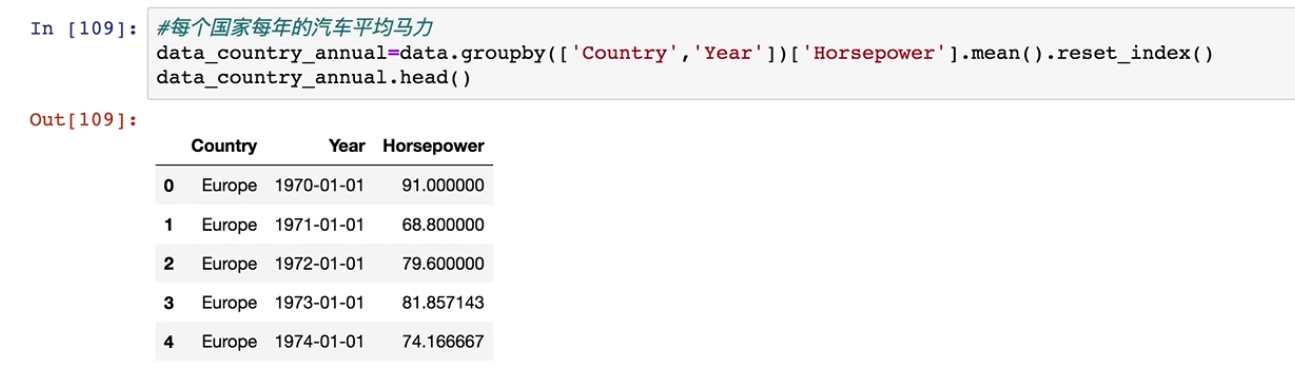
#每个国家每年的汽车平均马力
data_country_annual=data.groupby(['Country','Year'])['Horsepower'].mean().reset_index()
5 数据标准化
X=data['Horsepower']
import numpy as np
5.1 [0,1]标准化
就是将指定的数据压缩到0~1之间。
其公式就是:\(\frac{x-min}{max-min}\)
def MaxMinnormalization(x):
x=(x-np.min(x))/(np.max(x)-np.min(x))
return x
#调用函数
MaxMinnormalization(X)

x=MaxMinNormalization(x).reset_index()
x

5.2 z-score标准化
标准化后的数据是均值为0,方差为1的正态分布
def ZescoreNormalization(x):
x=(x-np.mean(x))/np.std(x)
return x
y=ZescoreNormalization(X).reset_index()
y

6 牛客练习题
6.1 查看数据
1.
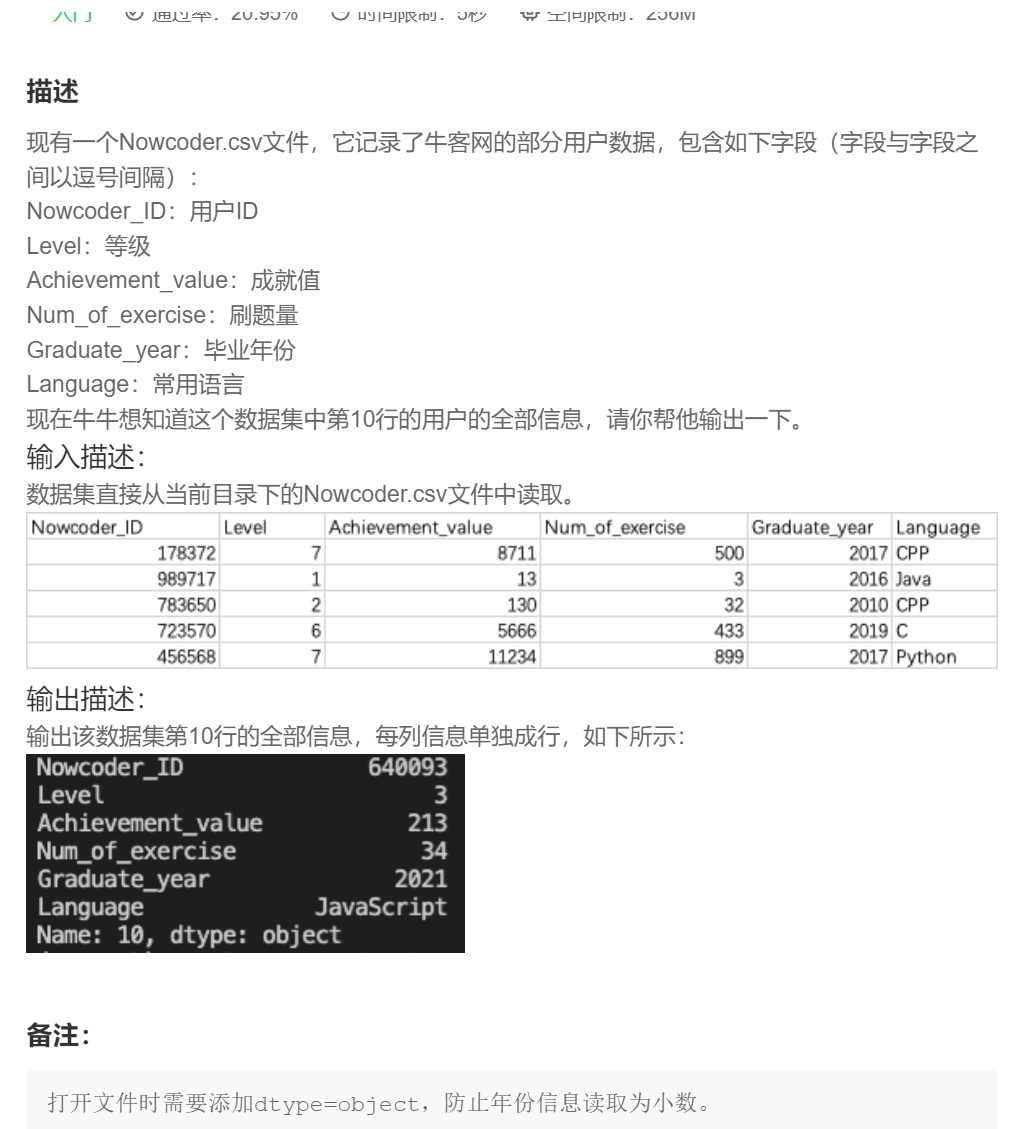
import pandas as pd
data=pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
data1=data.iloc[10]
print(data1)
iloc和loc区别:
其中iloc是位置索引,loc是条件索引
data.iloc是位置索引
x = data.iloc[0:2,0:3]
这个是输出第0-1行,第0-2列的数据
data.loc是标签索引
例如:
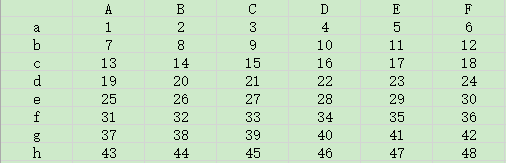
按照条件进行索引,例如获取A列中数值大于19,同时位于第三列和第五列的数值:
x=data.loc[data['A'] > 19, ['C', 'E']]
print(x)
C E
e 27 29
f 33 35
g 39 41
h 45 47
如果想要索引间隔的行和列:
例如获取第二行和第四行且位于第一列和第四列的数值
x=data.loc[['b','d'],['A','D']]
print(x)
A D
b 7 10
d 19 22
2.
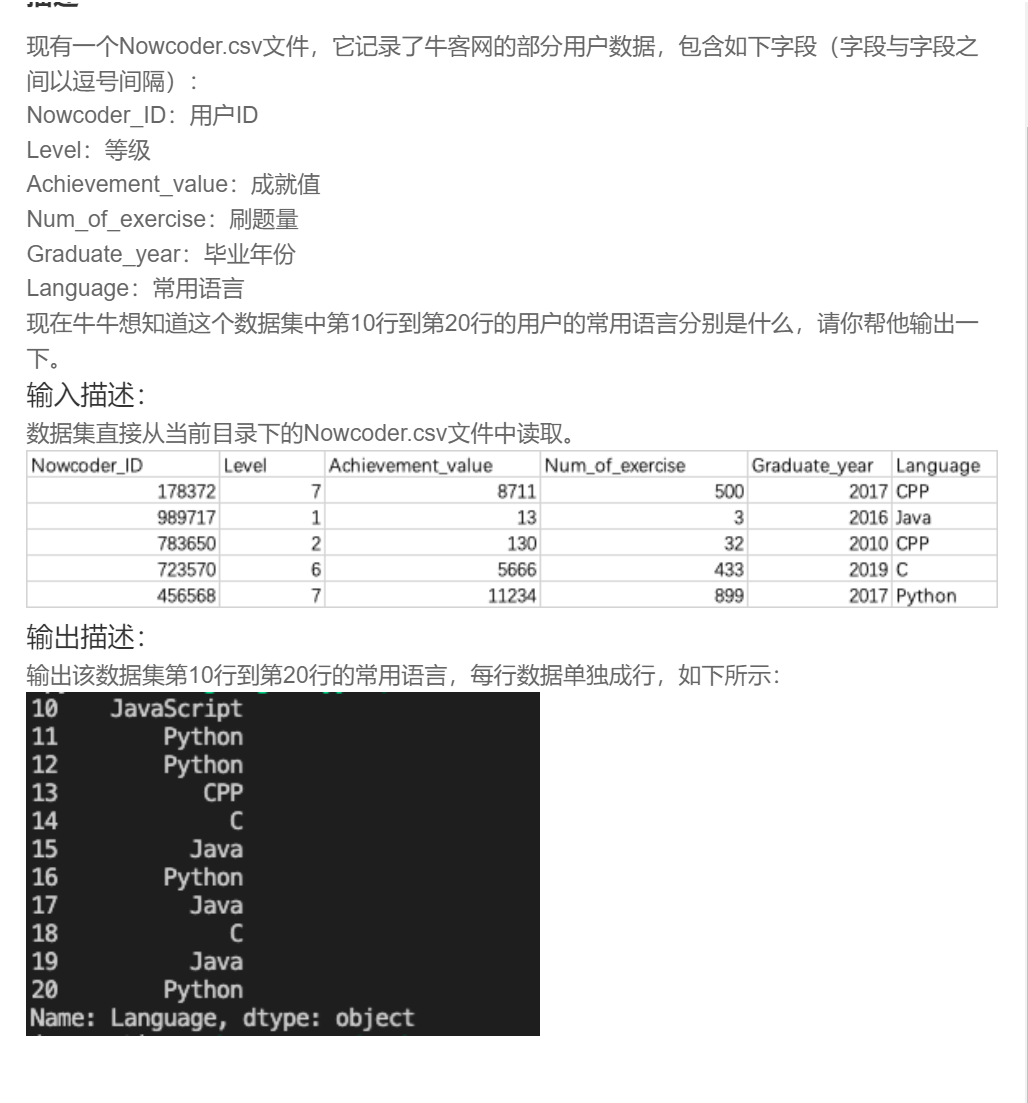
import pandas as pd
data=pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
data1=data['Language']
print(data1.iloc[10:21])#用位置索引
6.2 数据索引
3.

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)
print(data.isnull().any(axis=0))
其中axis=0,是列,axis=1,是行。
4.
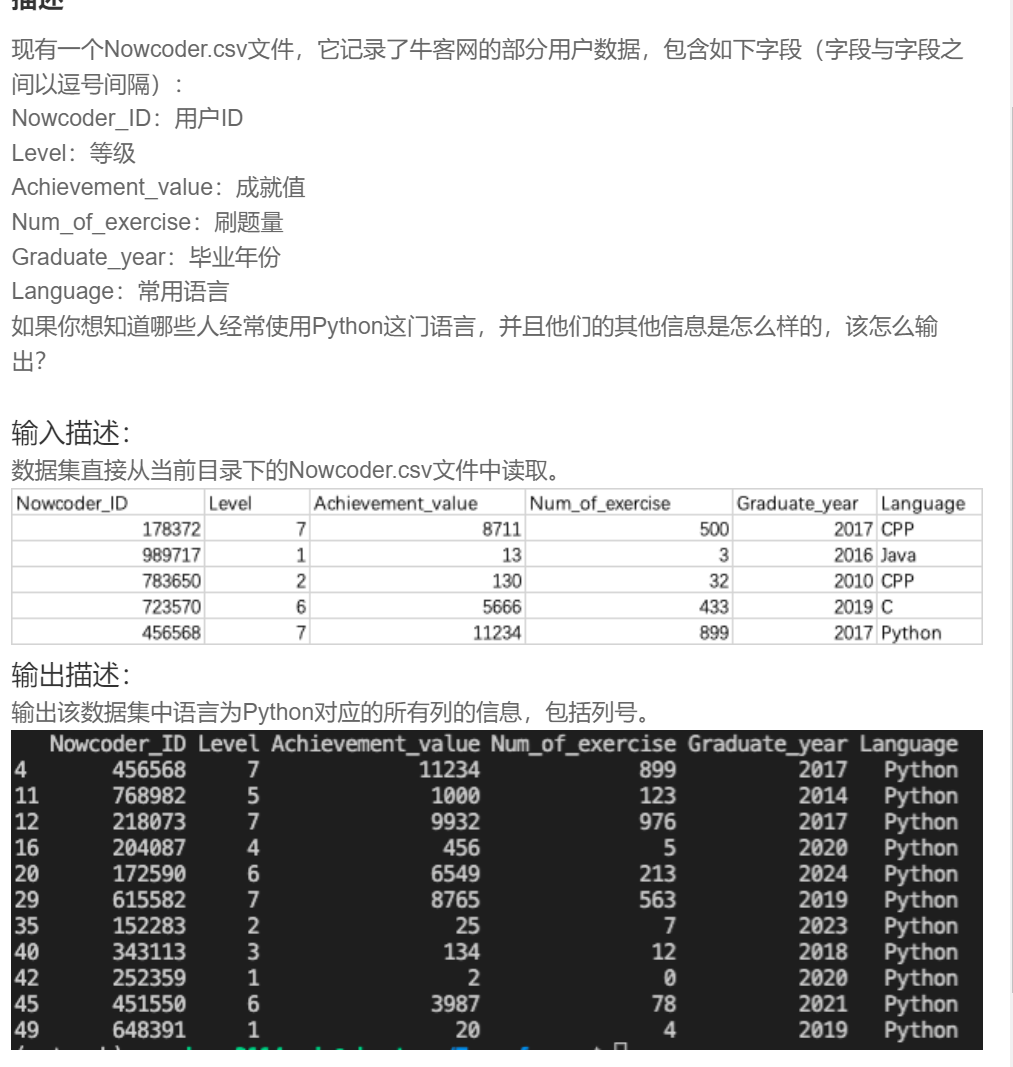
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)
print(data[data['Language'].isin(['Python'])])
5.
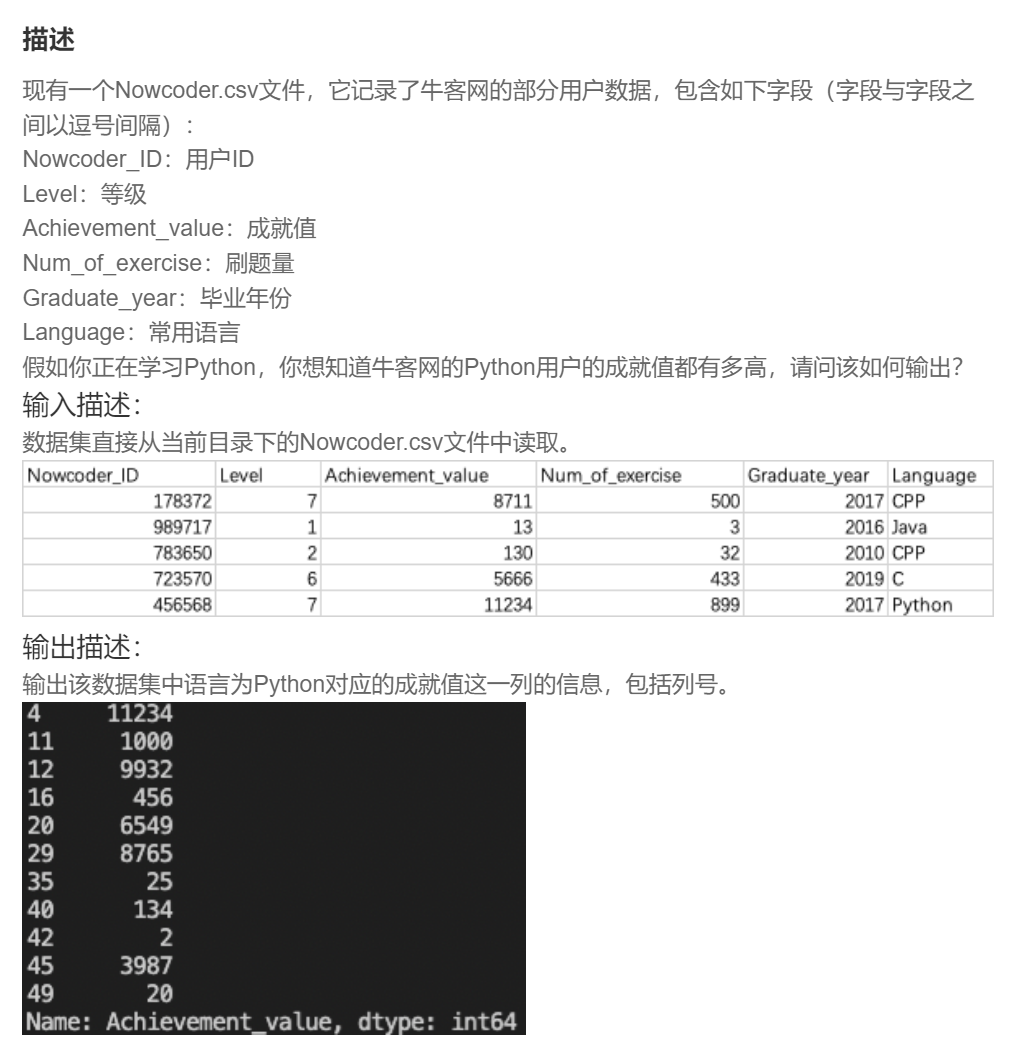
import pandas as pd
data = pd.read_csv("Nowcoder.csv", dtype=object)
print(data[data['Language']=='Python']['Achievement_value'])
6.

import pandas as pd
data = pd.read_csv("Nowcoder.csv")
data1=data[['Nowcoder_ID','Level','Achievement_value','Language']]
print(data1.tail(5))
6.3 逻辑运算
7.
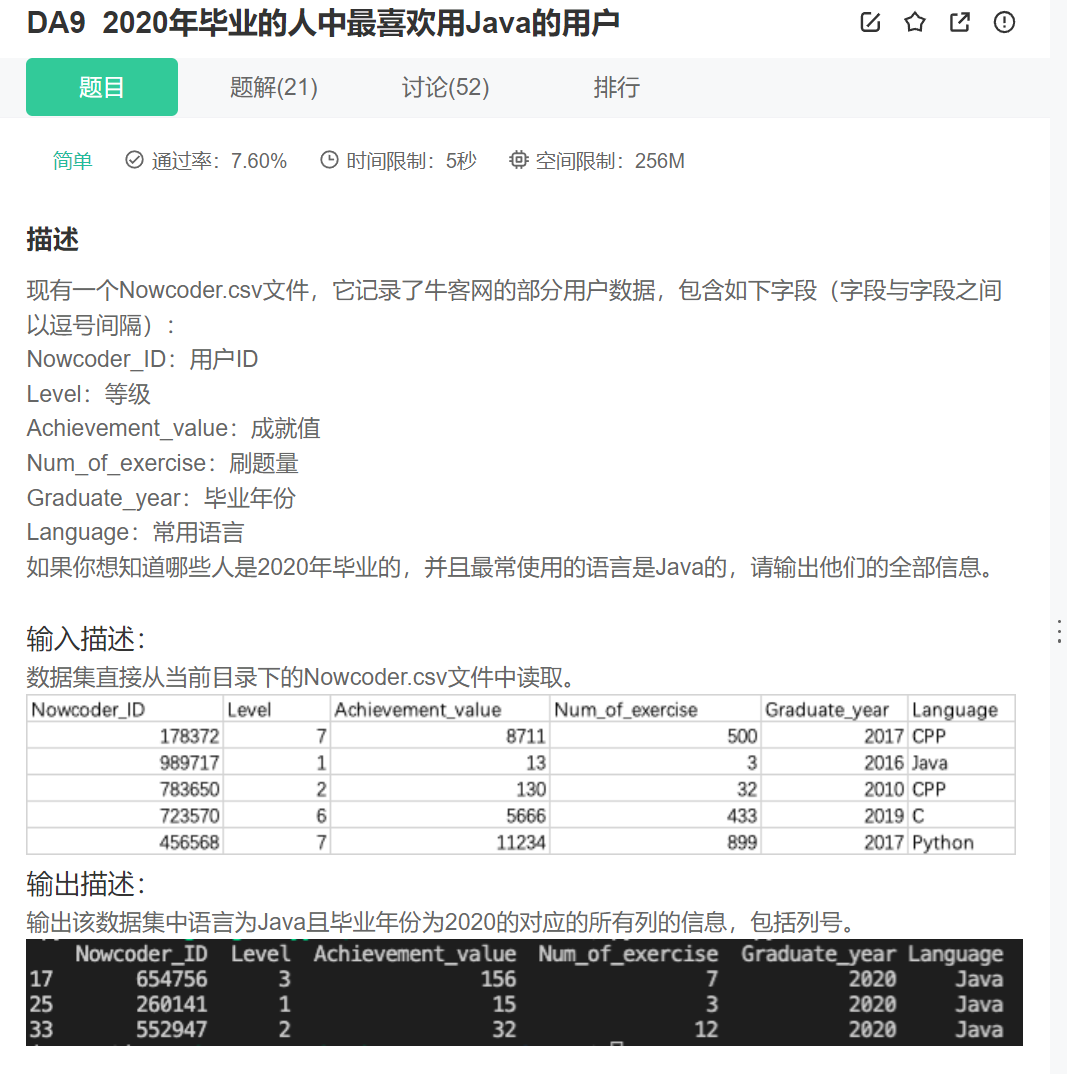
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data.loc[(data['Language']=='Java')&(data['Graduate_year']==2020),:])
这里用位置索引。
8.

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data.loc[((data['Language']=='CPP') | (data['Language']=='C') | (data['Language']=='C#')),:])
或者
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data[data['Language'].isin(['CPP','C','C#'])])
9.
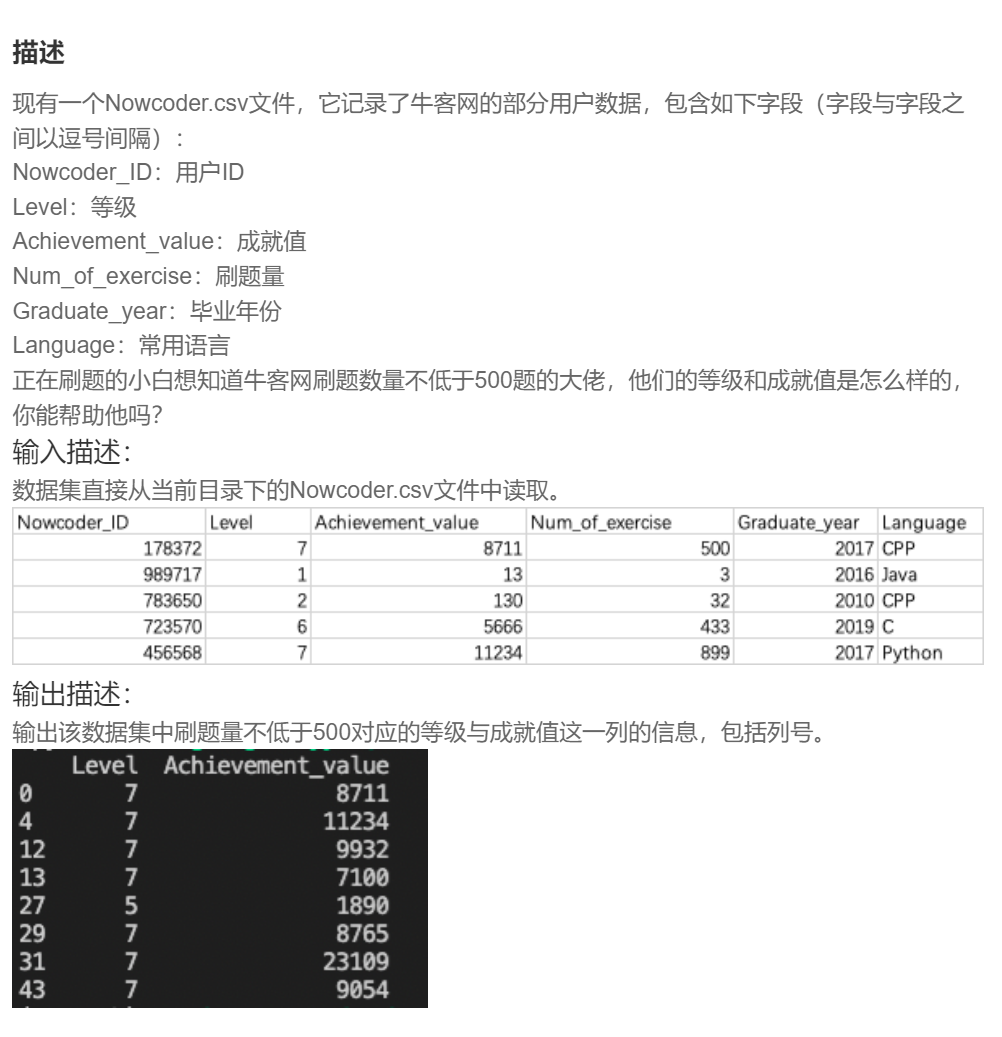
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data.loc[(data['Num_of_exercise']>=500),['Level','Achievement_value']])
或者这里不用loc也可以
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder[Nowcoder.Num_of_exercise>=500][['Level','Achievement_value']])
再看一个例子:

这个可以前面是条件后面是索引。
10.
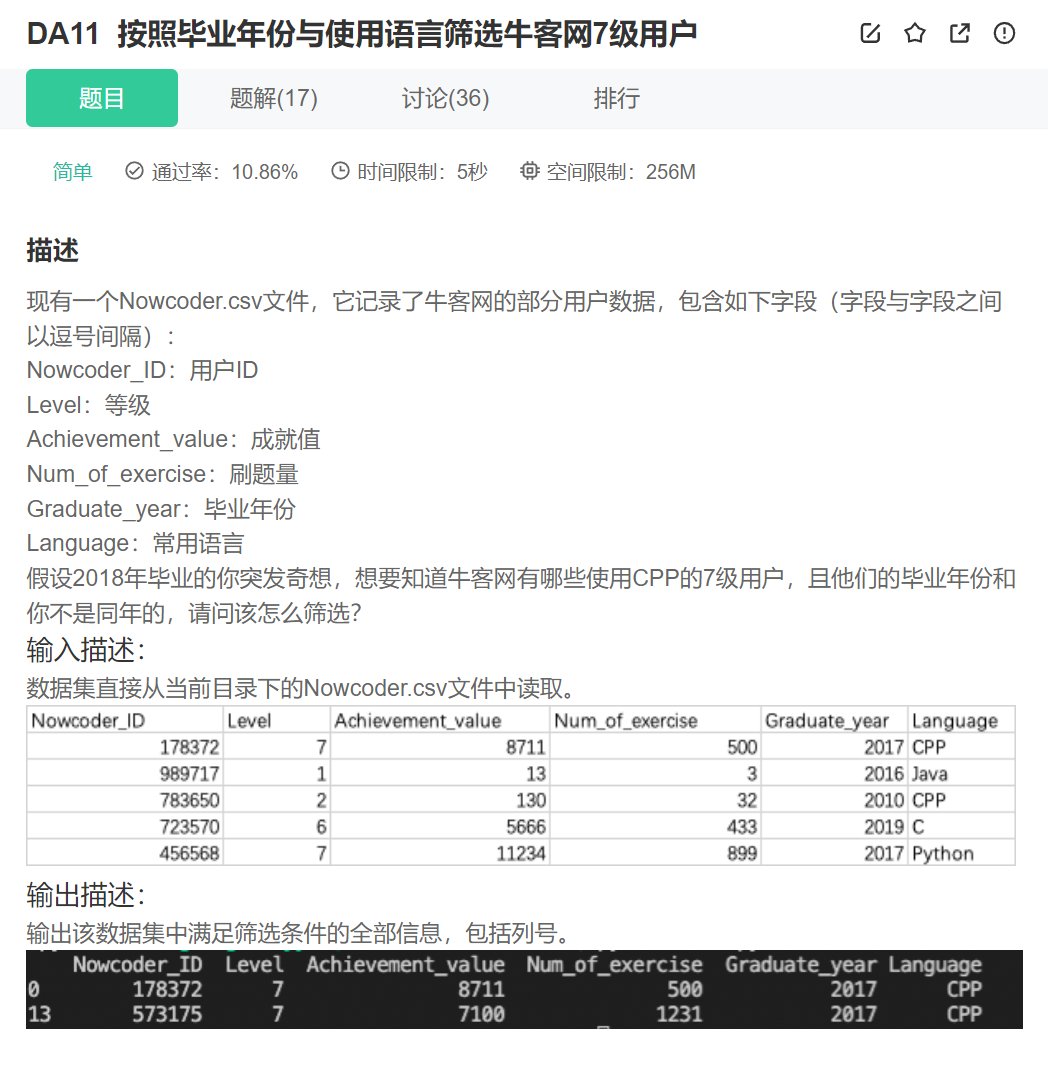
还是有两种写法:
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data[(data.Level==7)&(data.Language=='CPP')& (data.Graduate_year!='2018')])
#print(data.loc[(data['Level']==7)&(data['Language']=='CPP')&(data['Graduate_year']!='2018')])
6.4 中级函数(最大、最小、平均值)
11.value_counts()

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(data["Language"].value_counts())
12.

求这一行的最大、最小值
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(data['Continuous_check_in_days'].max())
print(data['Continuous_check_in_days'].min())
13.平均数

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(round(data[data.Language=='Python']['Number_of_submissions'].mean(),1))
14.中位数

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(int(data[data.Num_of_exercise >= 10]['Level'].median()))
15.一列数组的去重
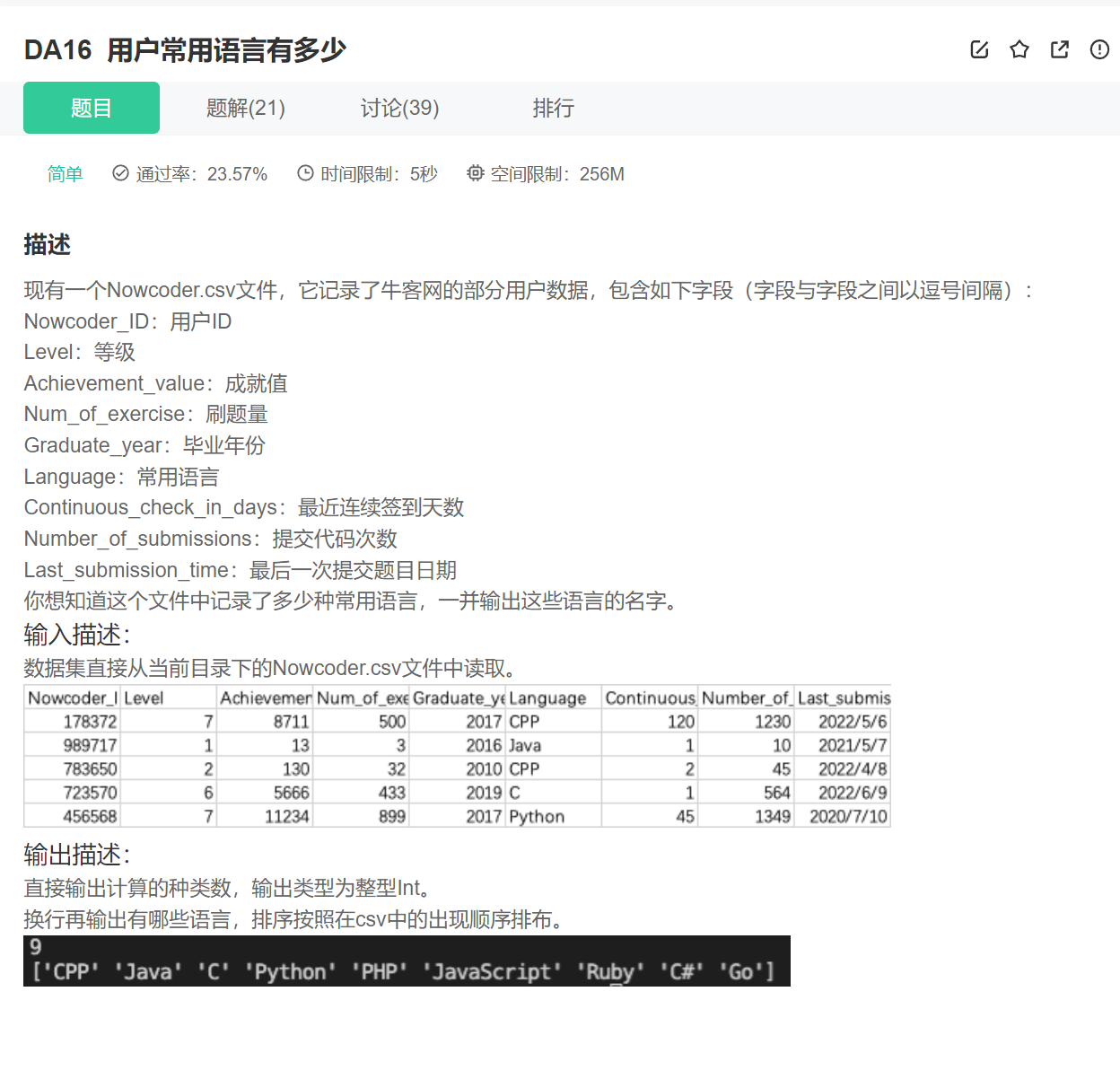
import pandas as pd
data = pd.read_csv('Nowcoder.csv', sep=',')
print(len(data.Language.unique()))
print(list(data.Language.unique()))
或者
import pandas as pd
data = pd.read_csv('Nowcoder.csv', sep=',')
print(len(data['Language'].unique()))
print(list(data['Language'].unique()))
16.众数
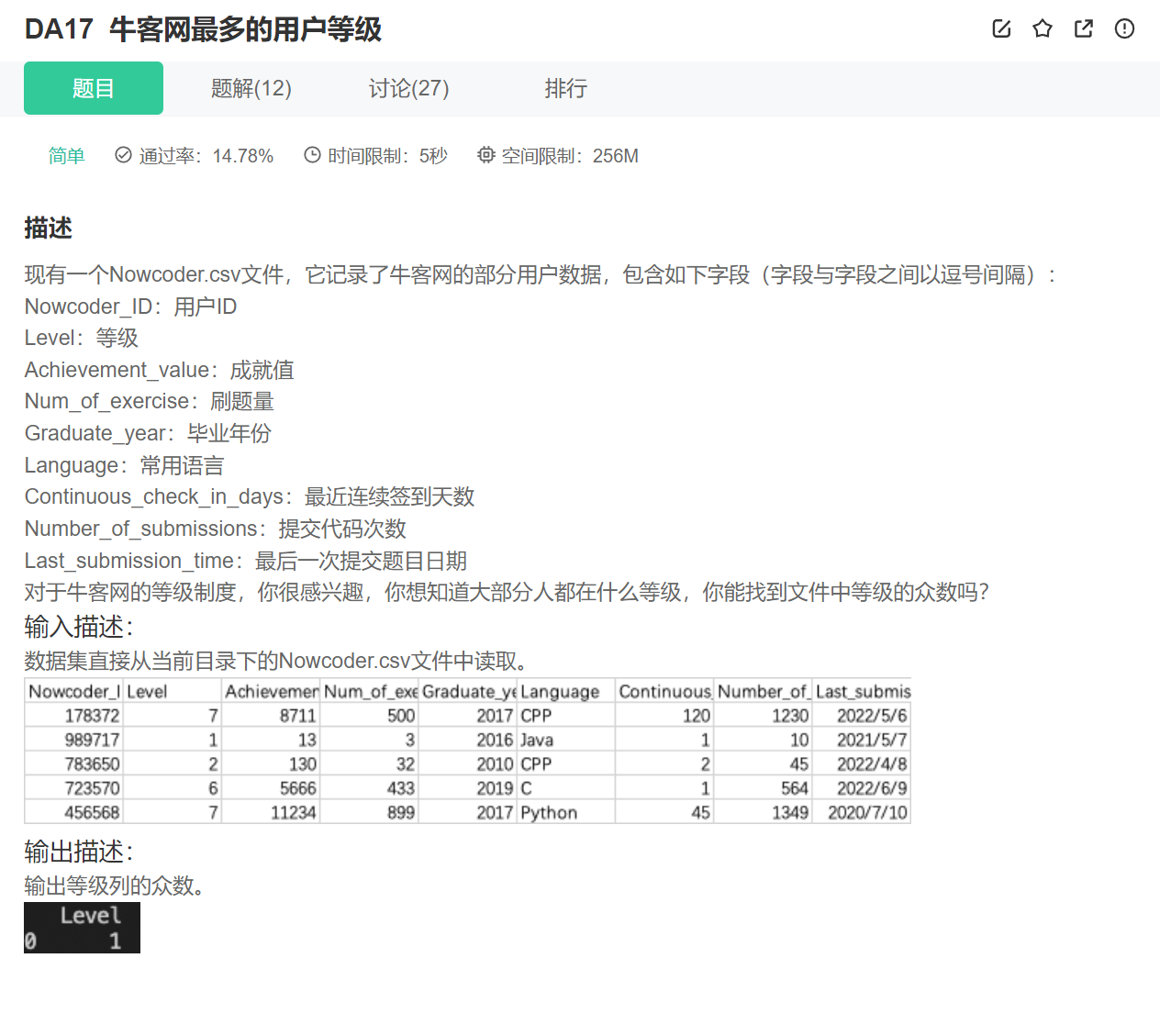
这里有个点需要注意:
我们只是这样输出的话:
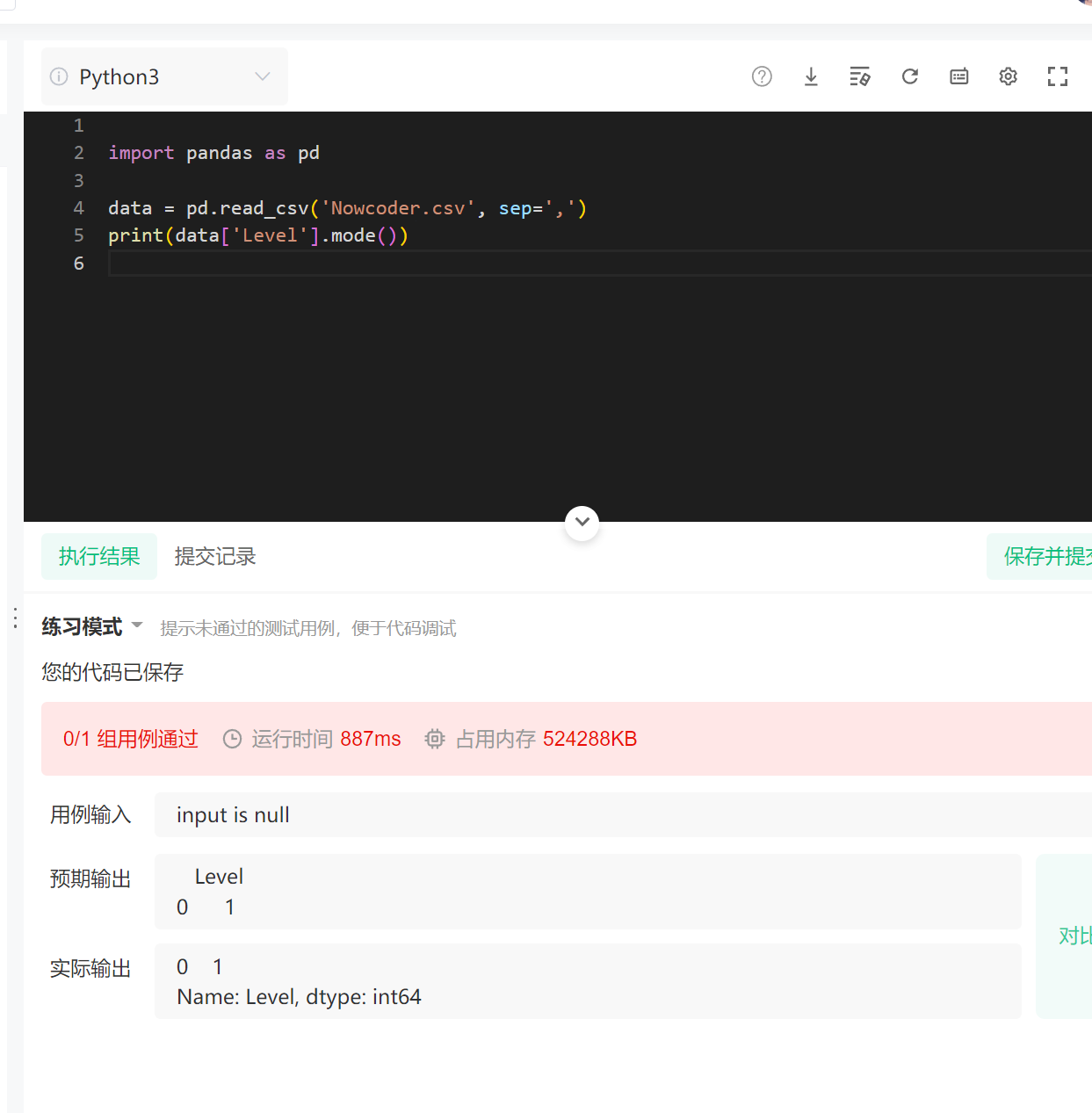
他要输出一个表格的形式
这里有两种方法:
import pandas as pd
data = pd.read_csv('Nowcoder.csv', sep=',')
print(data['Level'].mode().to_frame())
print(pd.DataFrame(data.Level.mode()))
17.分位数
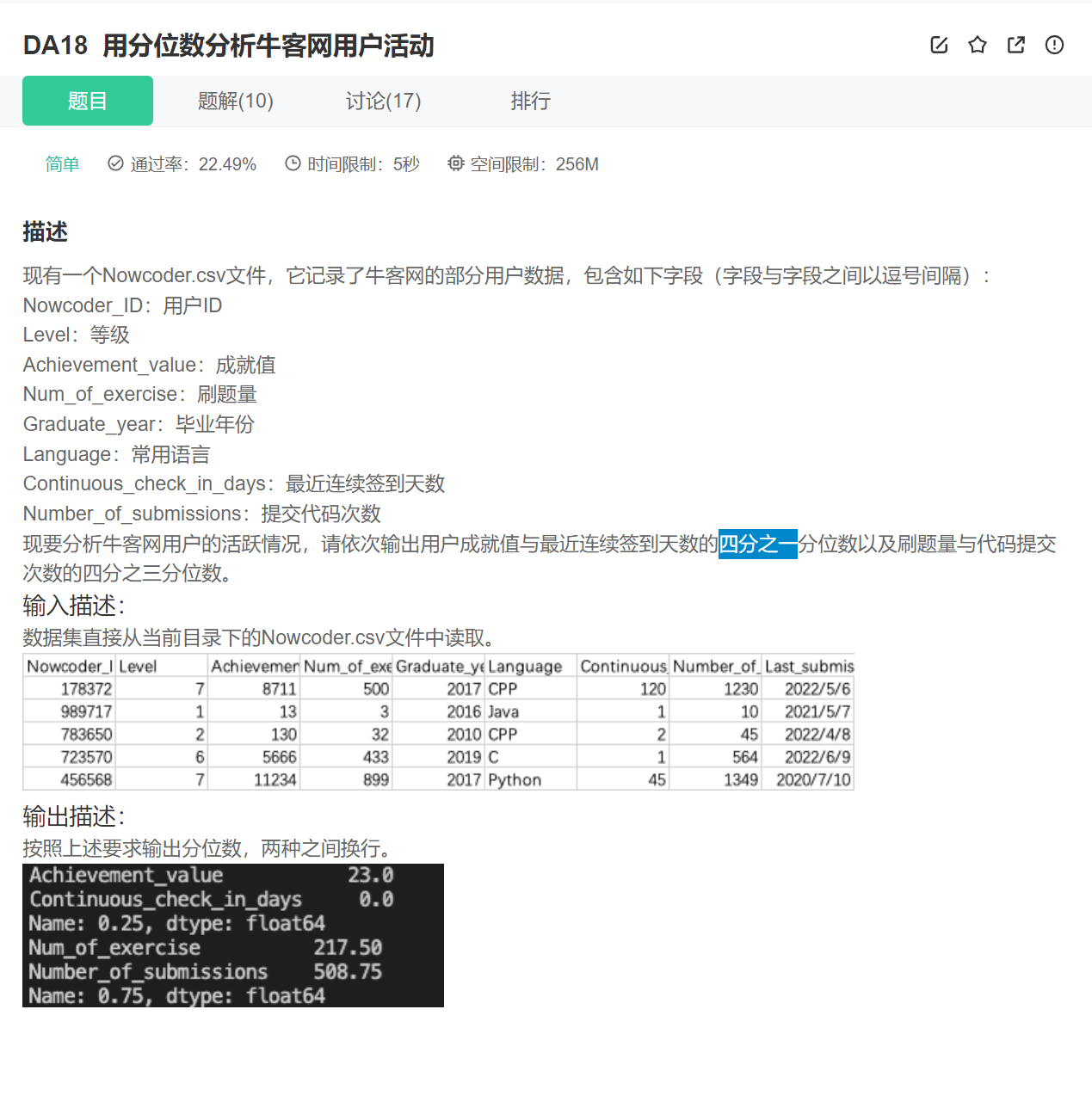
quantile( q=0.5, axis: 'Axis' = 0, numeric_only: 'bool' = True, interpolation: 'str' = 'linear', )
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
print(Nowcoder[["Achievement_value", "Continuous_check_in_days"]].quantile(q=0.25))
print(Nowcoder[["Num_of_exercise", "Number_of_submissions"]].quantile(q=0.75))
18.最大值减最小值
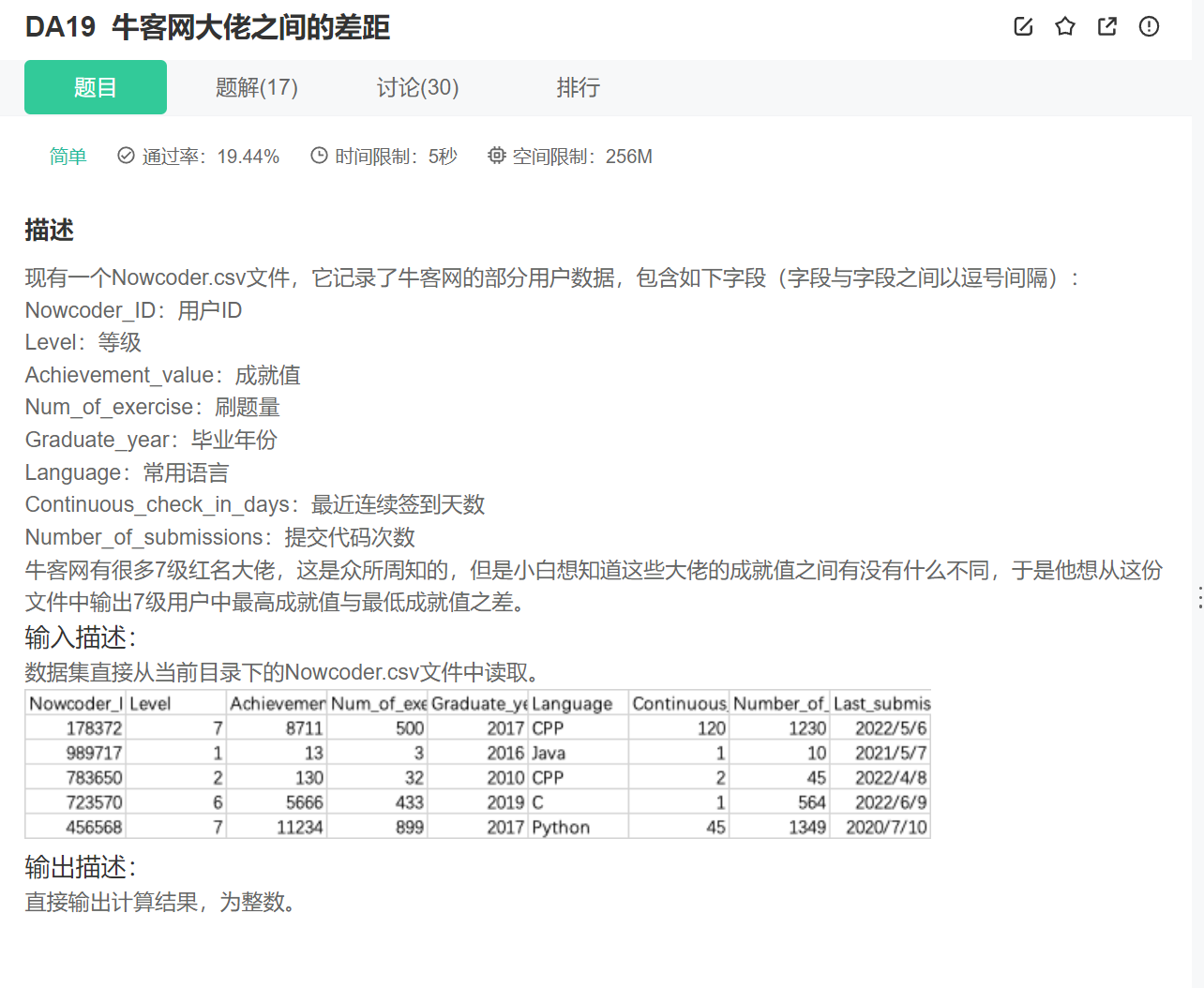
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(
data[data.Level == 7]["Achievement_value"].max()
- data[data.Level == 7]["Achievement_value"].min()
)
print(
int(
data[data["Level"] == 7]["Achievement_value"].max()
- data[data["Level"] == 7]["Achievement_value"].min()
)
)
19.方差、标准差

import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(data["Num_of_exercise"].var().round(2))
print(round(data["Number_of_submissions"].std(),2))
20.求和,百分比
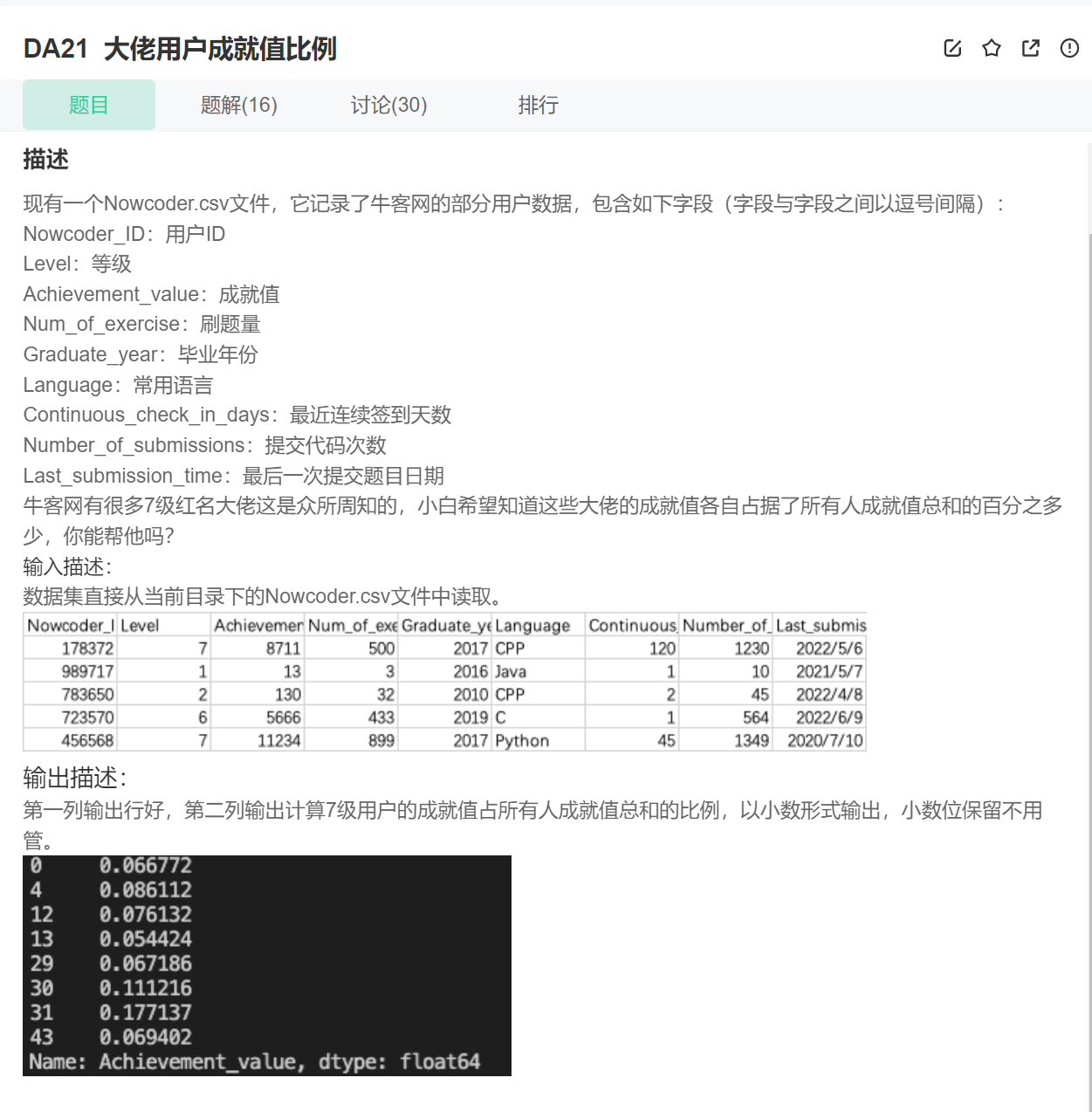
23.cnblogs.com/blog/1914163/202306/1914163-20230627160327557-1859637303.png)
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
print(data[data.Level==7]["Achievement_value"]/data["Achievement_value"].sum())
21.最高的正确率
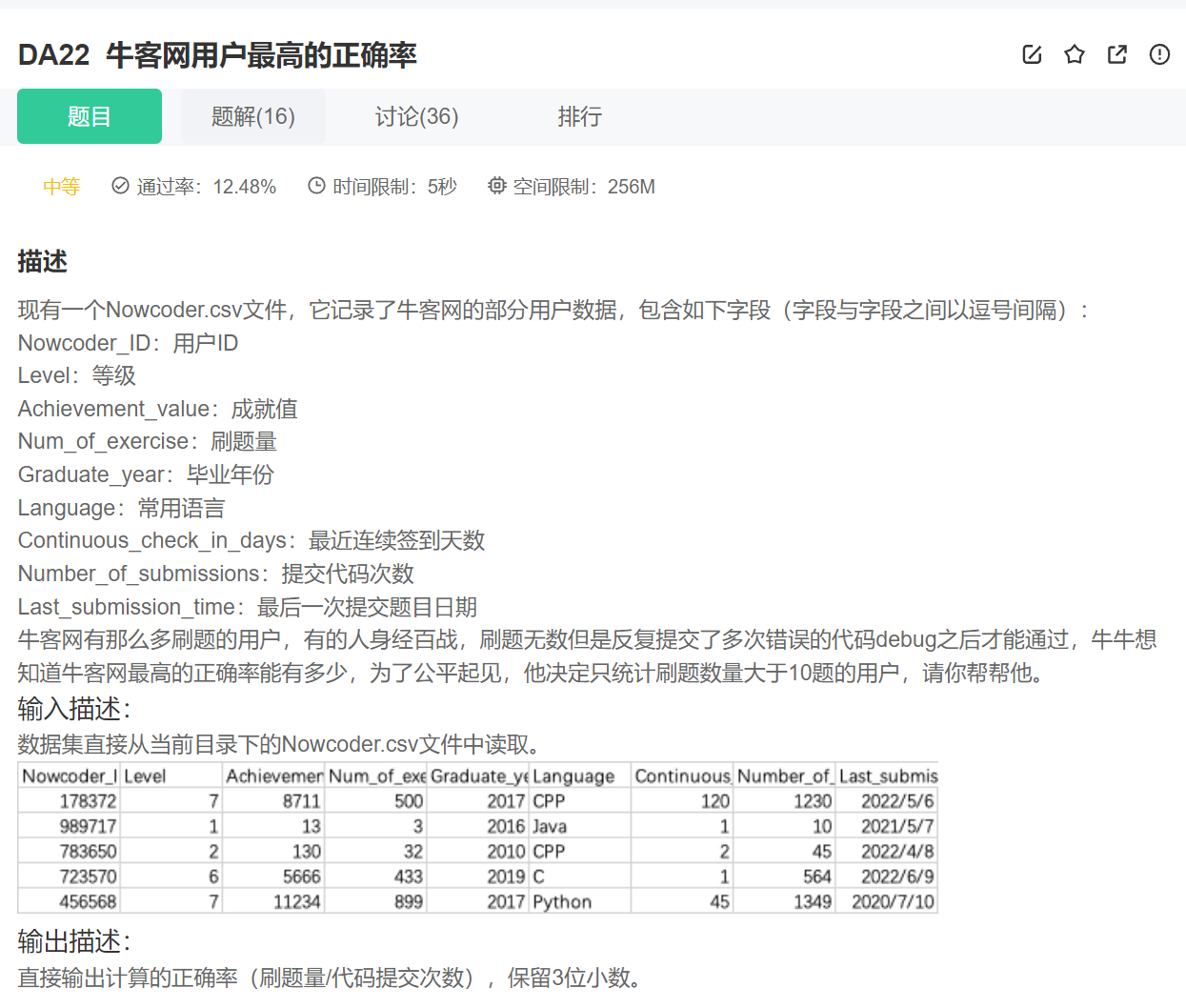
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
data1=data[data.Num_of_exercise>10]['Num_of_exercise']/data[data.Num_of_exercise>10]['Number_of_submissions']
print(data1.max().round(3))
或者:
import pandas as pd
df = pd.read_csv("Nowcoder.csv")
over_ten_users = df.query("Num_of_exercise > 10")
print(round(sorted(over_ten_users.Num_of_exercise/over_ten_users.Number_of_submissions,reverse=True)[0],3))
22.名字的长度

也是两种方法:
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder['Name'].str.len())#方法一
#print(Nowcoder['Name'].apply(len))#方法二:使用apply
或者
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
data1=data['Name']
tep=0
for i in data1:
data1[tep]=len(i)
tep=tep+1
print(data1)
6.5 分类聚合(groupby())
23.分组每日练题量
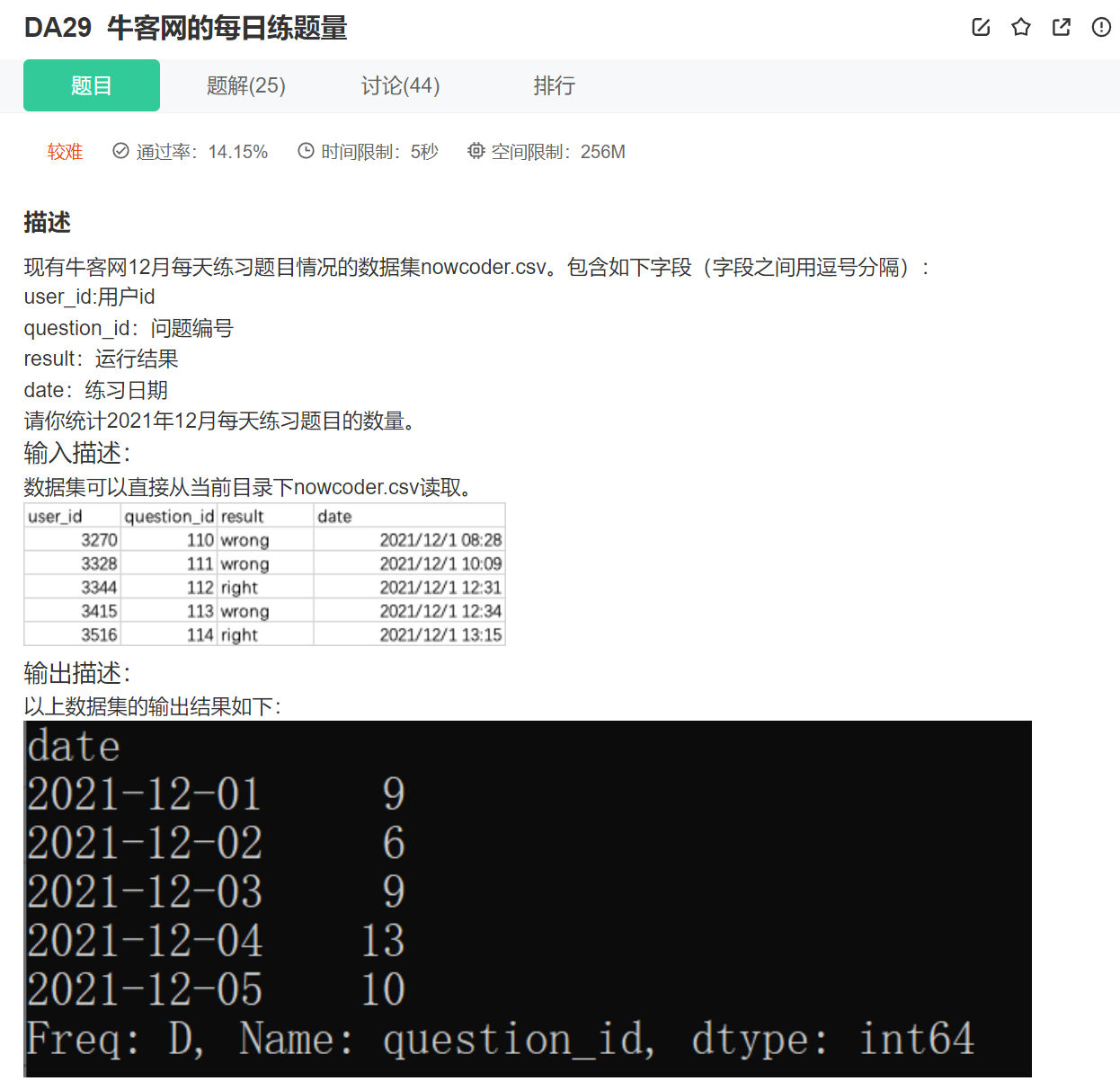
这个有两种方法,第一种就是可以把data的数据变成to_datetime()类型。
变成这种有一个好处,就是data.dt.year就可以返回其年份,data.dt.month就可以返回其月份
import pandas as pd
nowcoder = pd.read_csv("nowcoder.csv", sep=",")
# 日期转换
nowcoder["date"] = pd.to_datetime(nowcoder["date"], format="%Y-%m-%d")
# 筛选2021年12月数据
nowcoder = nowcoder[
(nowcoder["date"].dt.year == 2021) & (nowcoder["date"].dt.month == 12)
]
# 统计
print(nowcoder.groupby('date')['question_id'].count())
或者在加载csv的时候,看见日期就可以处理掉
pd.read_csv('',parse_dates=True)
就是这个parse_dates
import pandas as pd
nowcoder = pd.read_csv('nowcoder.csv', parse_dates=True, index_col='date')
daily_num = nowcoder.groupby('date')['question_id'].count()
print(daily_num)
24.正误总数
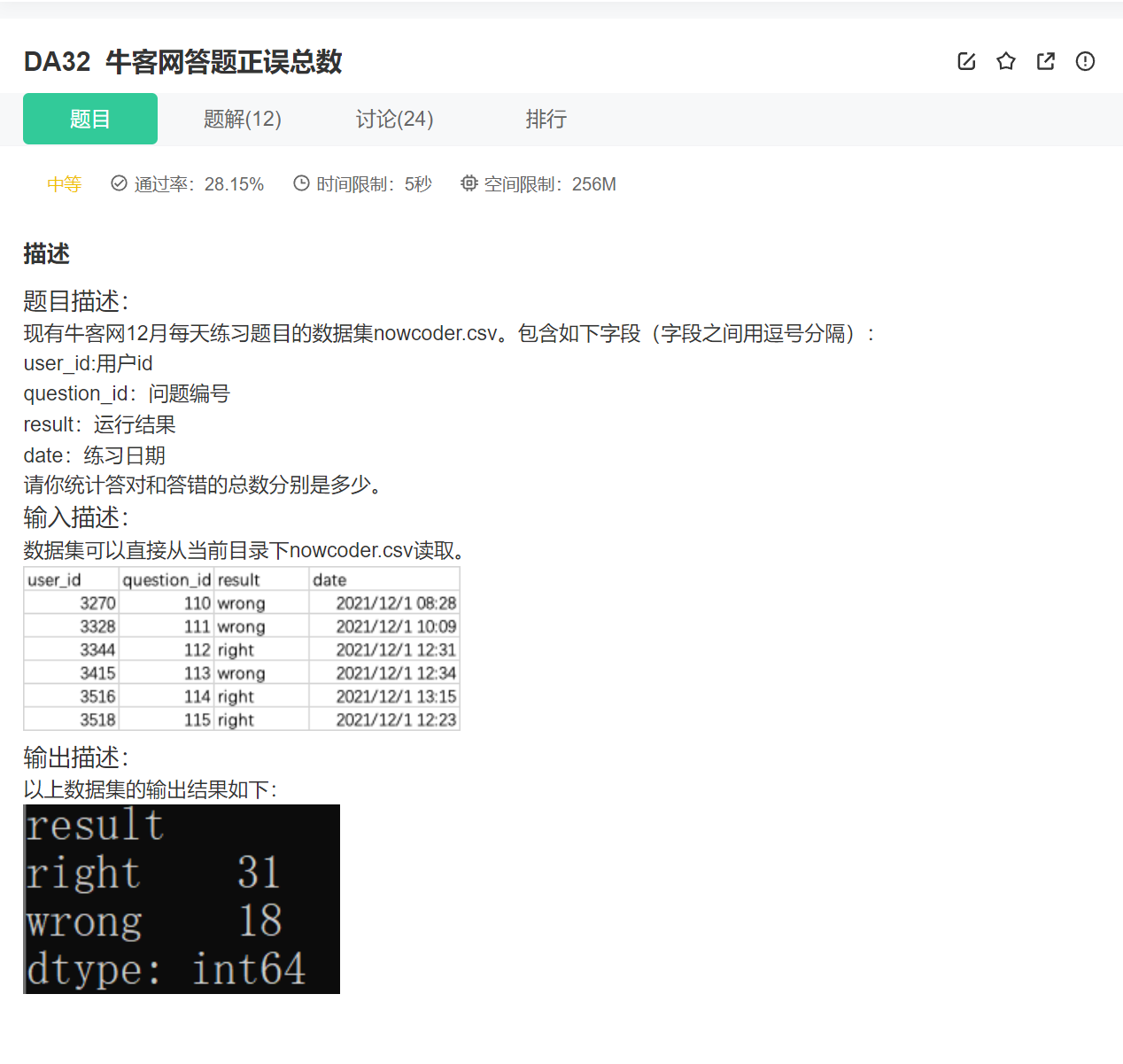
import pandas as pd
nowcoder = pd.read_csv('nowcoder.csv')
result_df = nowcoder.groupby('result')
print(result_df.size())
25.分组最大
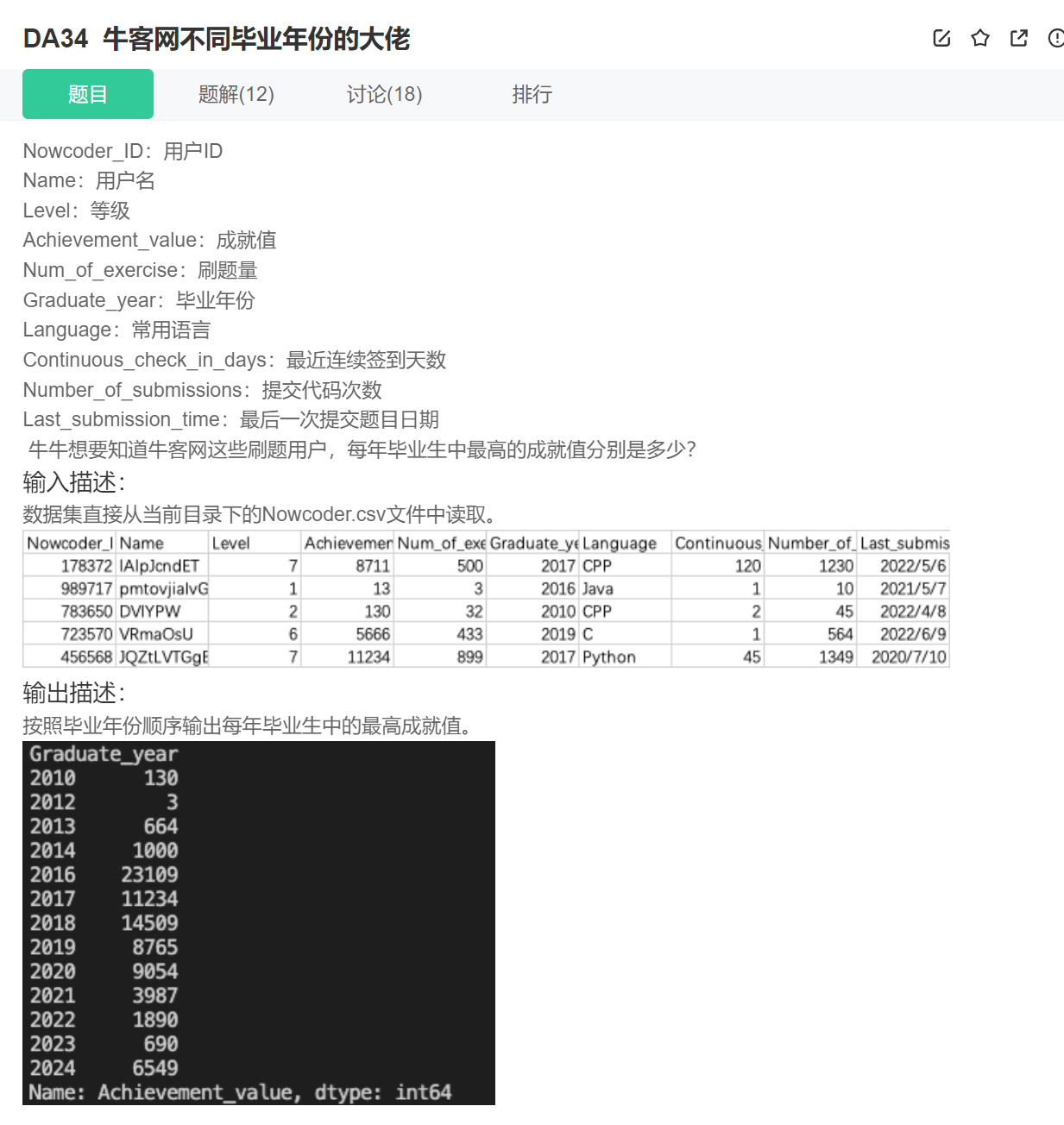
import pandas as pd
data = pd.read_csv('Nowcoder.csv')
print(data.groupby(['Graduate_year'])['Achievement_value'].max())
26.按照两个分组
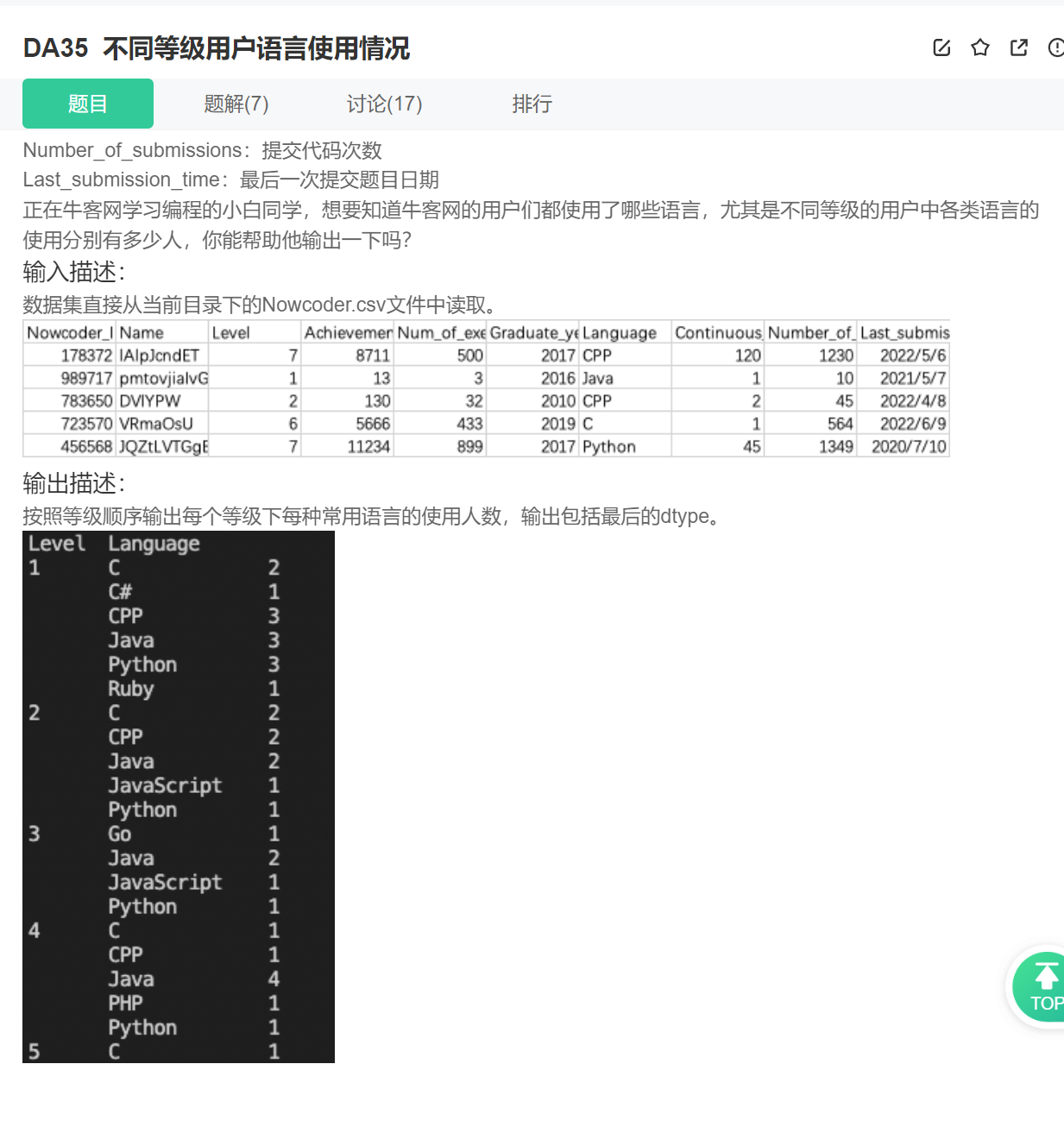
这个如果是查看数量的话,就用.value_counts(),然后这个还按照两个关键词进行分组。
import pandas as pd
from numpy.core.defchararray import count
data = pd.read_csv("Nowcoder.csv")
print(data.groupby(['Level','Language'])['Level','Language'].value_counts())
27.等级人数分组

import pandas as pd
data = pd.read_csv('Nowcoder.csv', sep = ',', dtype = object)
print(data.groupby(['Level'])['Nowcoder_ID'].count() > 5)
6.6 合并
28.合并表
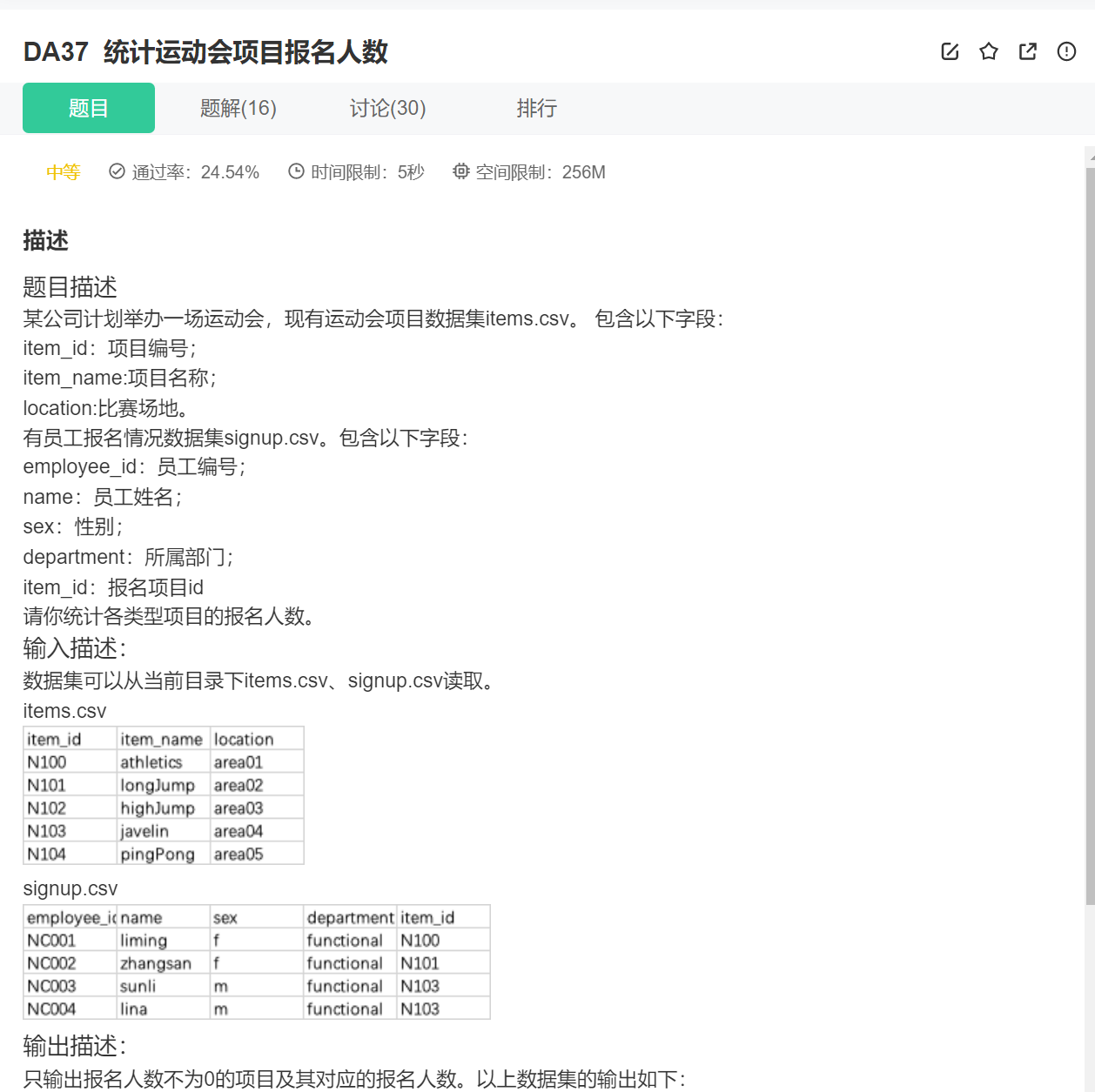
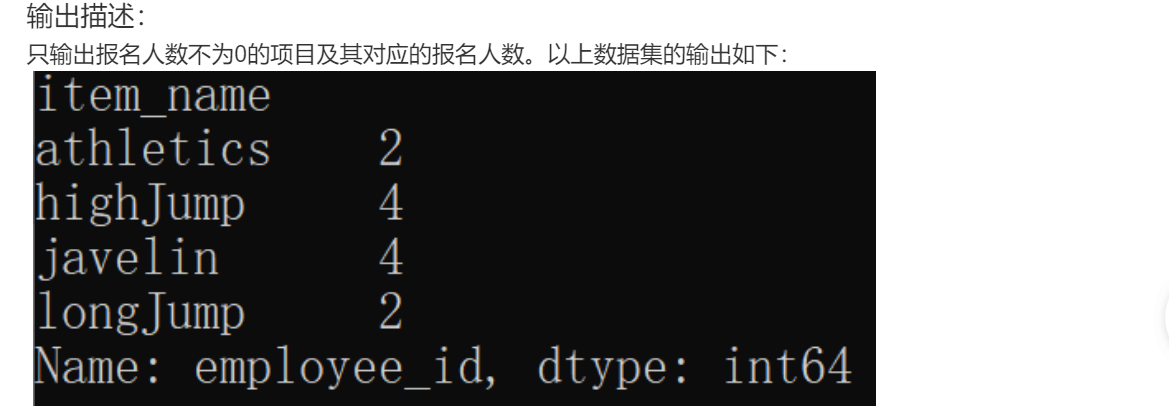
import pandas as pd
data_item = pd.read_csv('items.csv')
data_signup=pd.read_csv('signup.csv')
data=pd.merge(data_item, data_signup, how="inner",left_on='item_id', right_on='item_id')
print(data.groupby(['item_name'])['item_id'].count())
注意看我用这个value_counts()的区别:
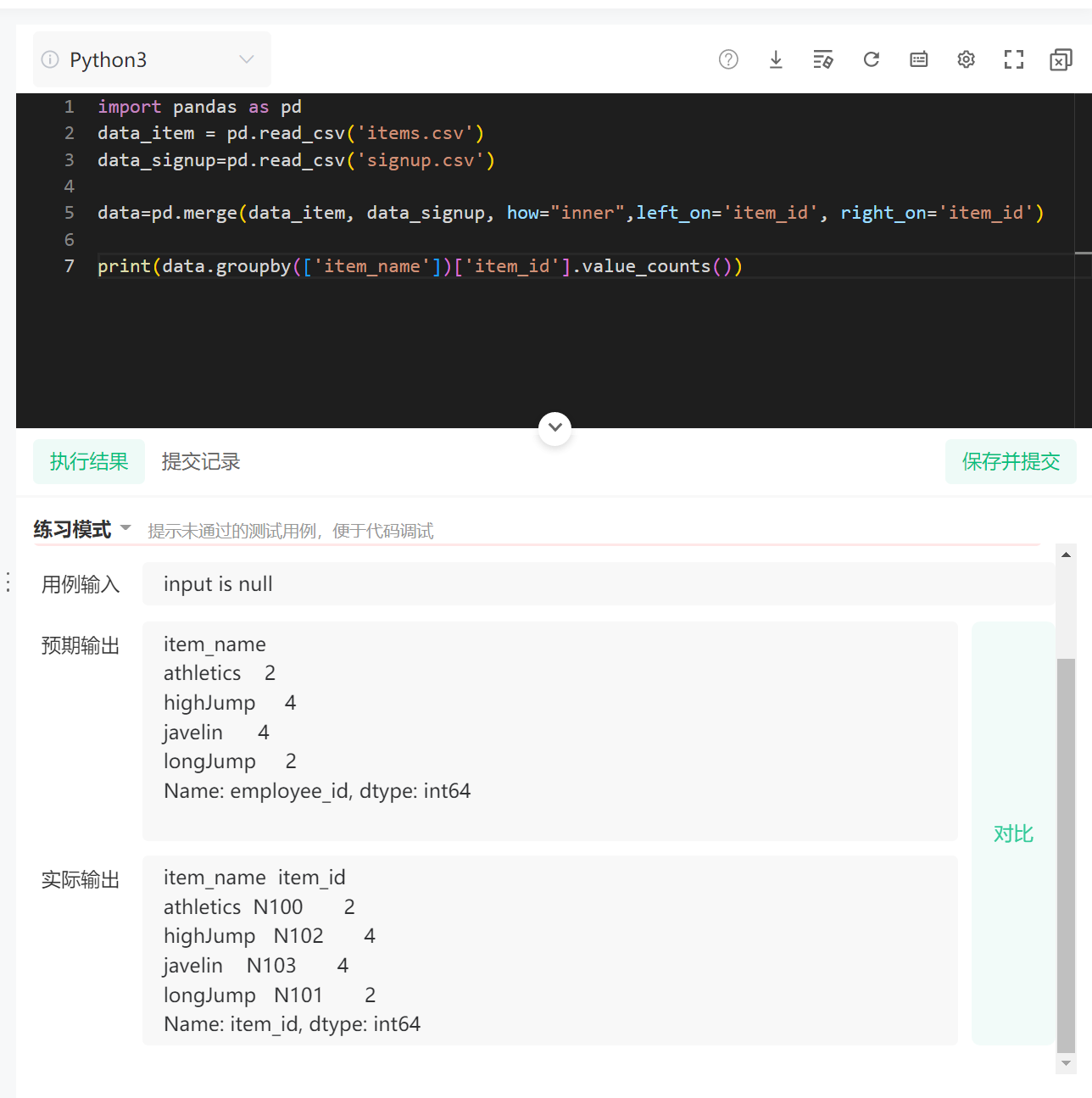
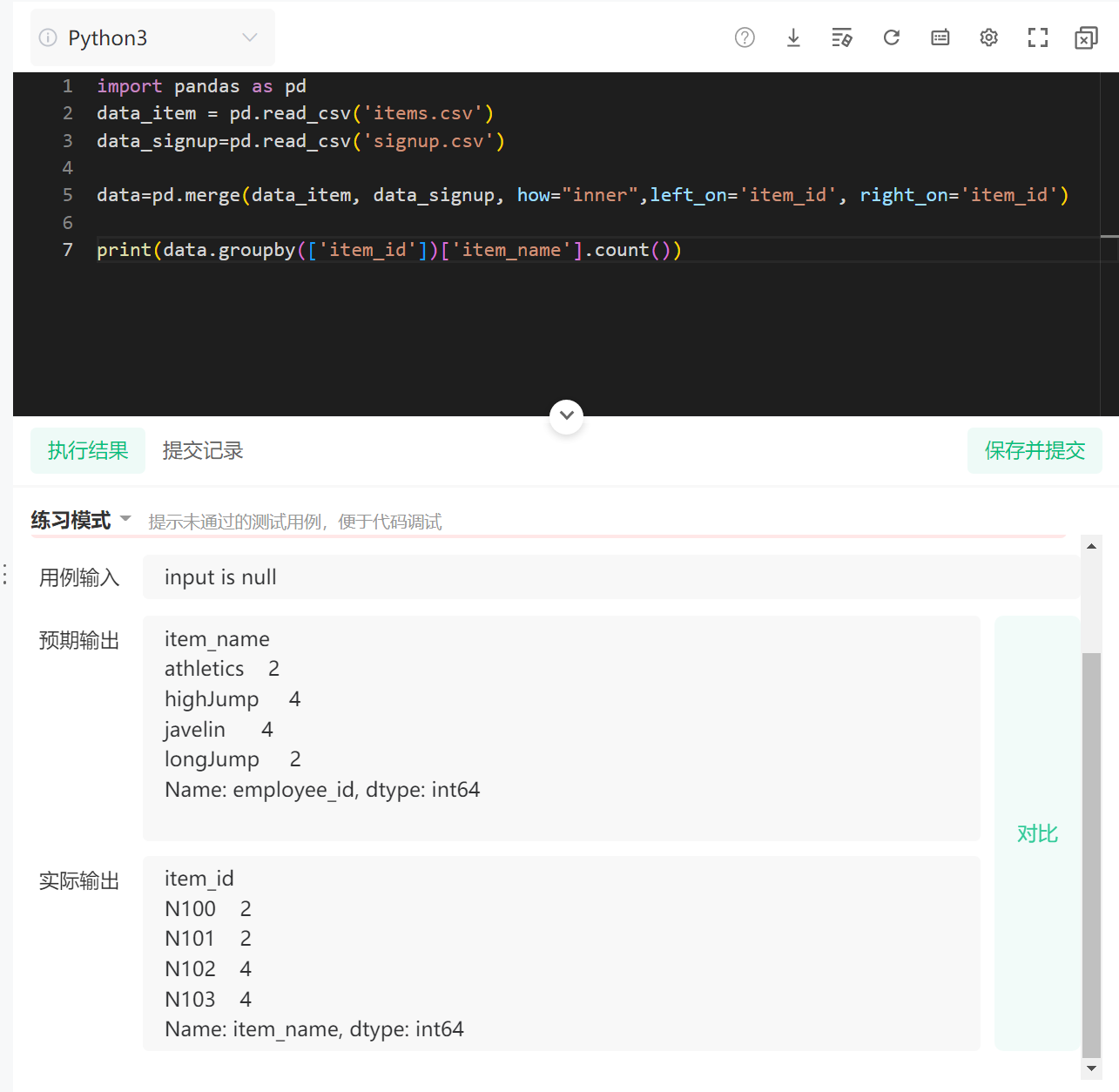
如果是print(data.groupby(['item_id'])['item_name'].count()),就是这样的:
29.合并表

这个跟上一个差不多,但是这个很明显是左连接,就是items.csv连接上signup.csv
import pandas as pd
data_item = pd.read_csv("items.csv")
data_signup = pd.read_csv("signup.csv")
data = pd.merge(
data_item, data_signup, how="left", left_on="item_id", right_on="item_id"
)
print(data.groupby(["item_name"])["item_id"].count())
30.两种合并


这里用到两种合并
pd.concat( objs, axis=0, join=‘outer’, join_axes=None)
这里合并完之后是这样的:
objs 表示需要连接的对象,比如:[df1, df2],需要将合并的数据用综括号包围;
axis=0 表拼接方式是上下堆叠,当axis=1表示左右拼接;
join 参数控制的是外连接还是内连接,join='outer’表示外连接,保留两个表中的所有信息;join="inner"表示内连接,拼接结果只保留两个表共有的信息;
join_axes参数是在内连接时选择要完整保留哪个表的索引,但是这个参数在官方文档中提醒即将被弃用,所以不做详细讲解,只看一下join参数的表现吧

import pandas as pd
signup = pd.read_csv('signup.csv')
signup1 = pd.read_csv('signup1.csv')
items = pd.read_csv('items.csv')
signup_all = pd.concat([signup, signup1])
data = pd.merge(
items, signup_all, how="inner", left_on="item_id", right_on="item_id"
)
print(data.groupby(["item_name"])["item_id"].count())
31.合并加重置下标
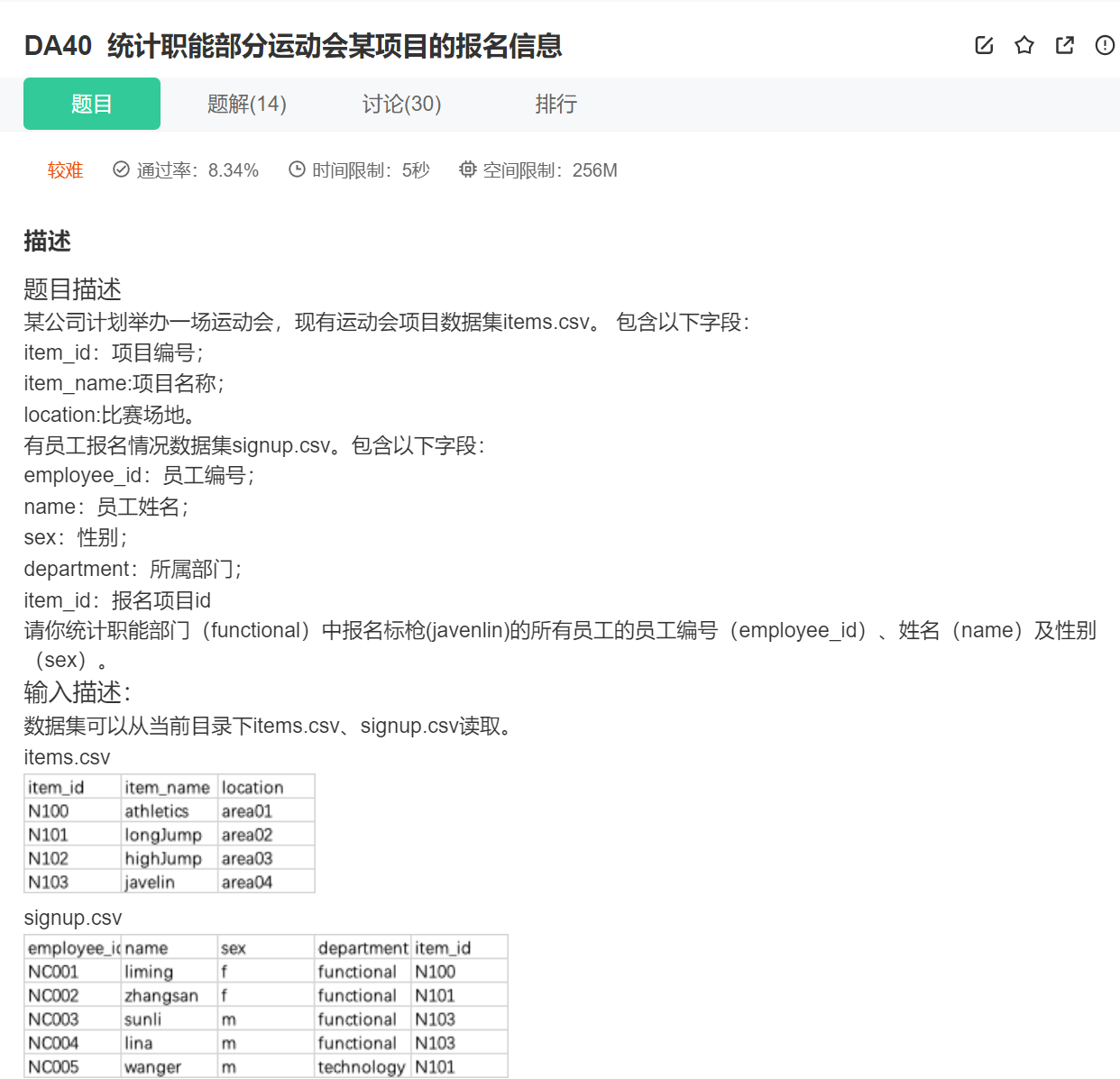

import pandas as pd
data1 = pd.read_csv('items.csv')
data2 = pd.read_csv('signup.csv')
data=pd.merge(data1,data2,how='inner',left_on="item_id", right_on="item_id")
print(data[(data.department=='functional')&(data.item_name=='javelin')][['employee_id','name','sex']].reset_index(drop = True))
这里:
注意重置索引
reset_index用来重置索引,因为有时候对dataframe做处理后索引可能是乱的。
drop=True就是把原来的索引index列去掉,重置index。
drop=False就是保留原来的索引,添加重置的index。
两者的区别就是有没有把原来的index去掉
注意如果他没有重置下标的话:
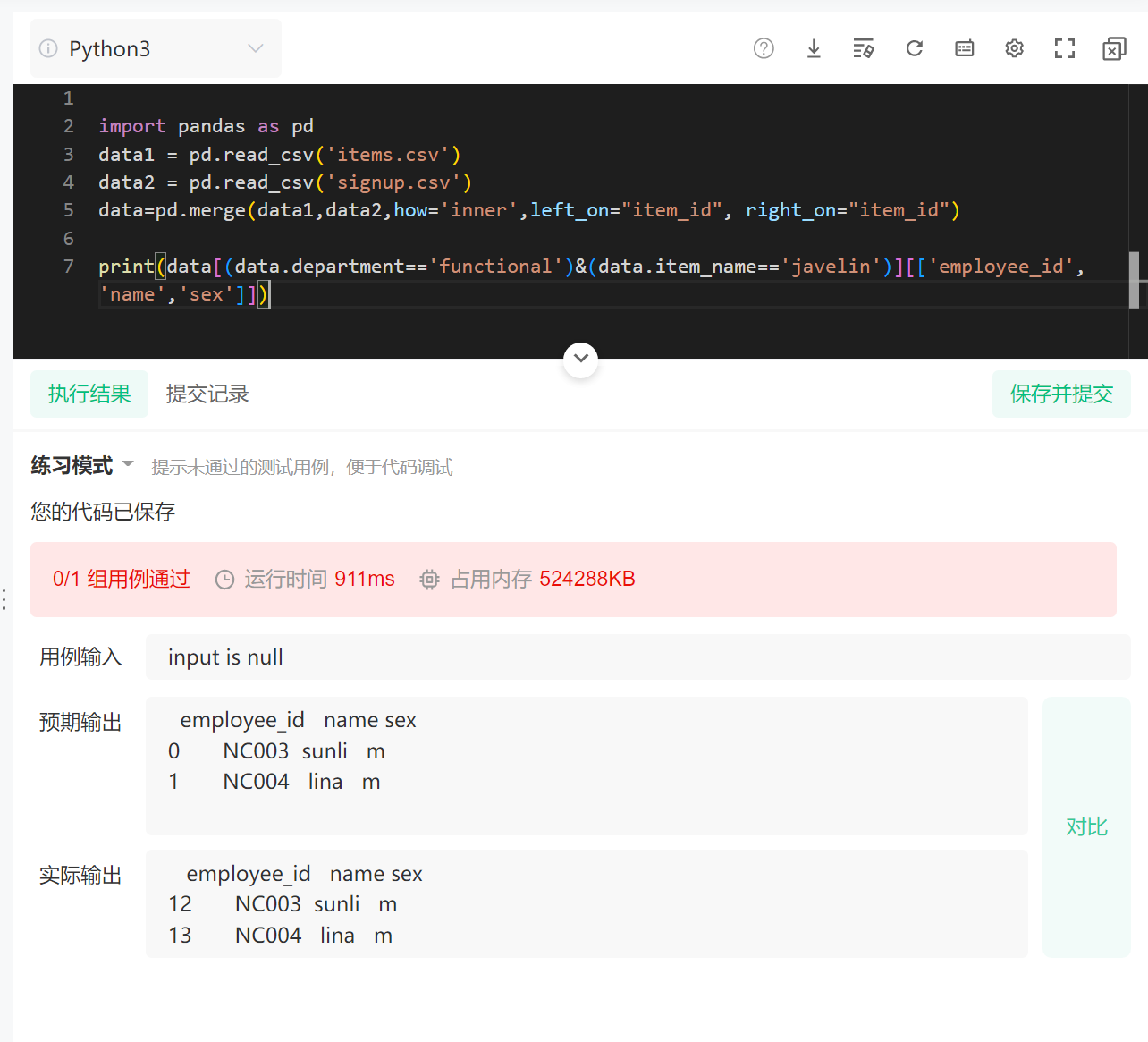
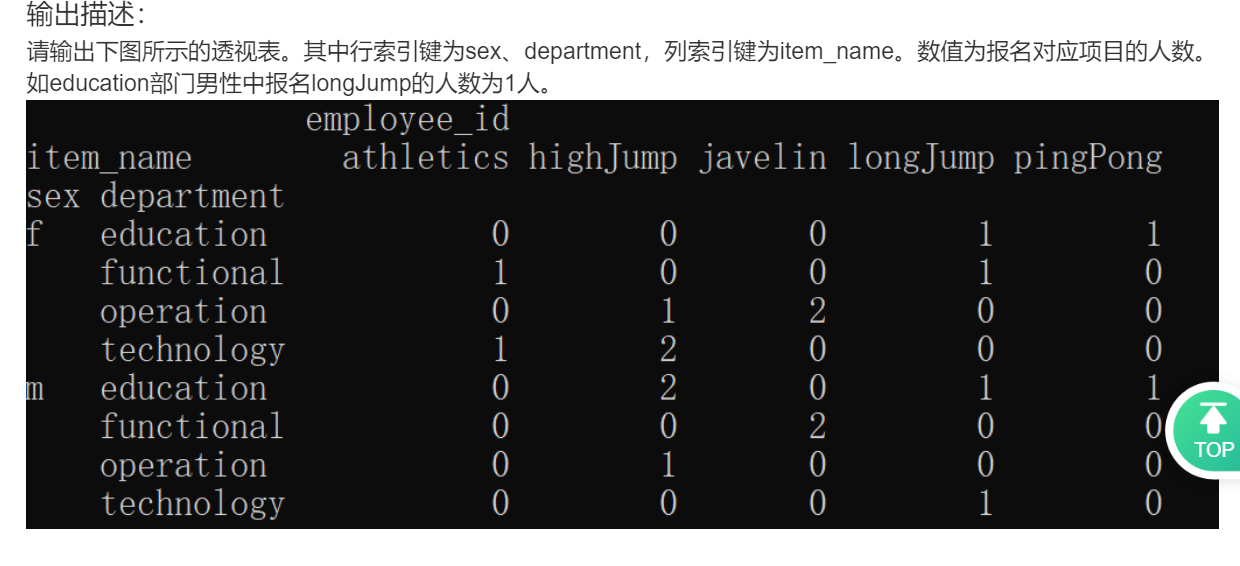
32.透视表

import pandas as pd
signup = pd.read_csv("signup.csv")
items = pd.read_csv("items.csv")
df_all = pd.merge(
signup, items, how="left", left_on=signup["item_id"], right_on=items["item_id"]
)
print(
pd.pivot_table(
df_all,
index=["sex", "department"],
columns=["item_name"],
values=["employee_id"],
aggfunc="count",
fill_value=0,
)
)
33.合并表

这个题就是需要需要设置显示
import pandas as pd
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
data1 = pd.read_csv("Nowcoder1.csv")
data2 = pd.read_csv("Nowcoder2.csv")
data = pd.merge(data1, data2, how="inner",left_on="Nowcoder_ID", right_on="Nowcoder_ID")
print(data)
34.两个表格合并查询

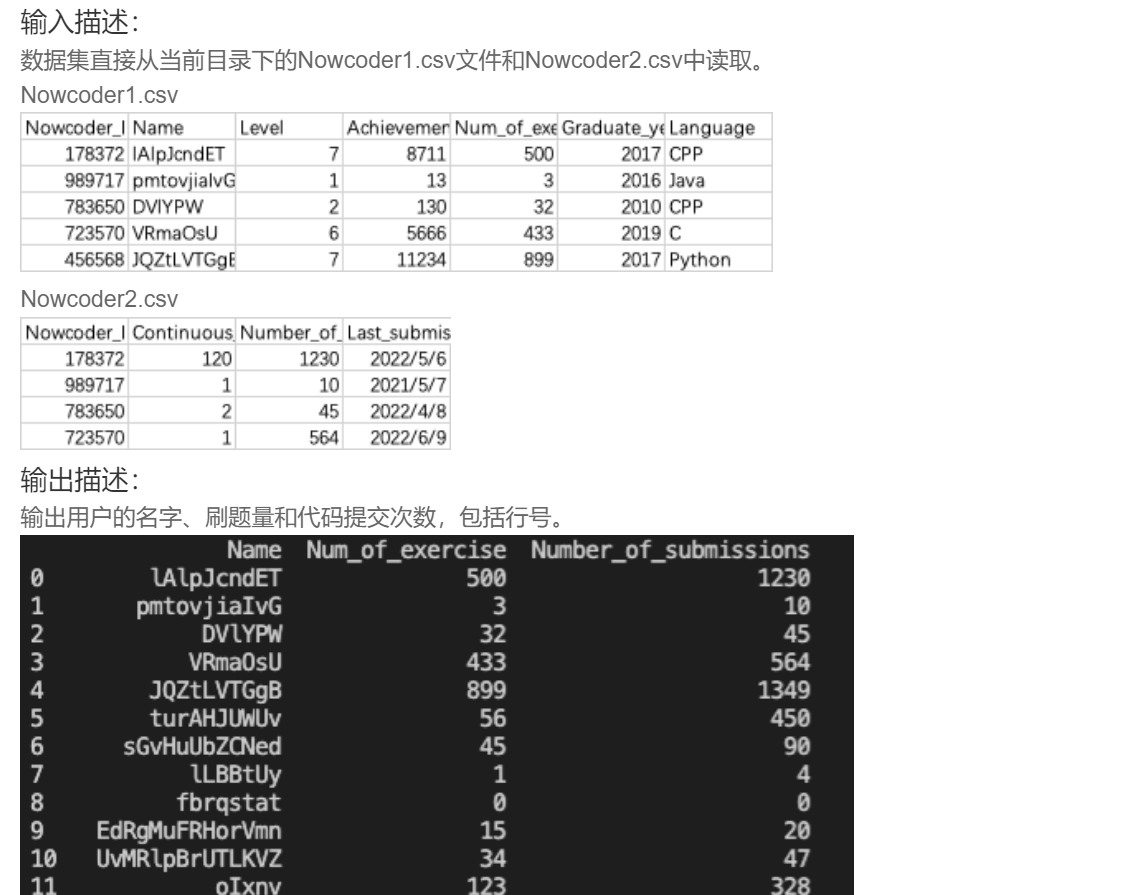
import pandas as pd
data1=pd.read_csv('Nowcoder1.csv')
data2=pd.read_csv('Nowcoder2.csv')
data=pd.merge(data1,data2,how='inner',left_on="Nowcoder_ID", right_on="Nowcoder_ID")
print(data[['Name','Num_of_exercise','Number_of_submissions']])
#print(data.loc[:,['Name','Num_of_exercise','Number_of_submissions']])
6.7 排序
35.排序+重置索引
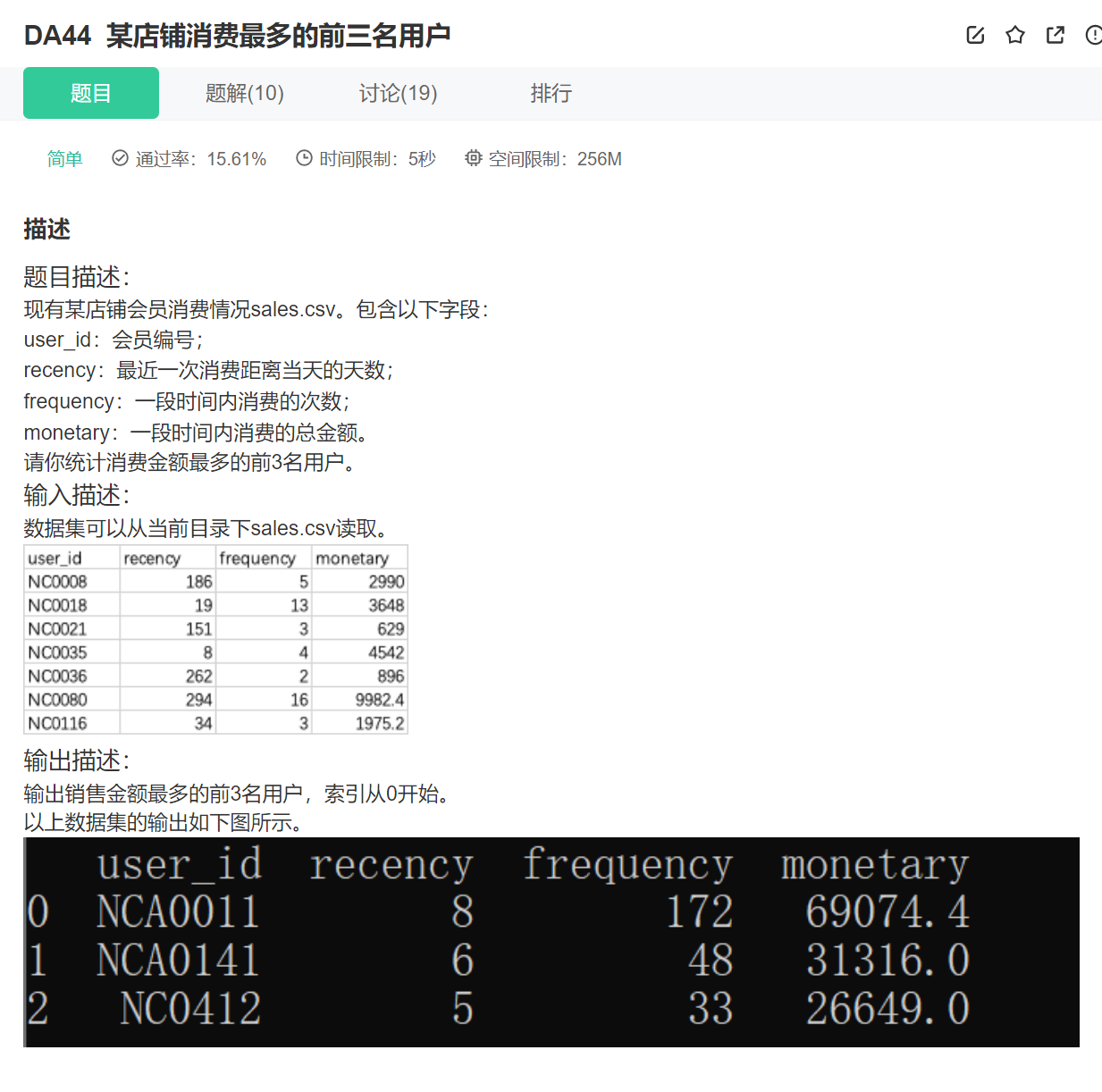
import pandas as pd
data=pd.read_csv('sales.csv')
print(data.sort_values(by='monetary').head(3).reset_index(drop = True))
36.等级递增
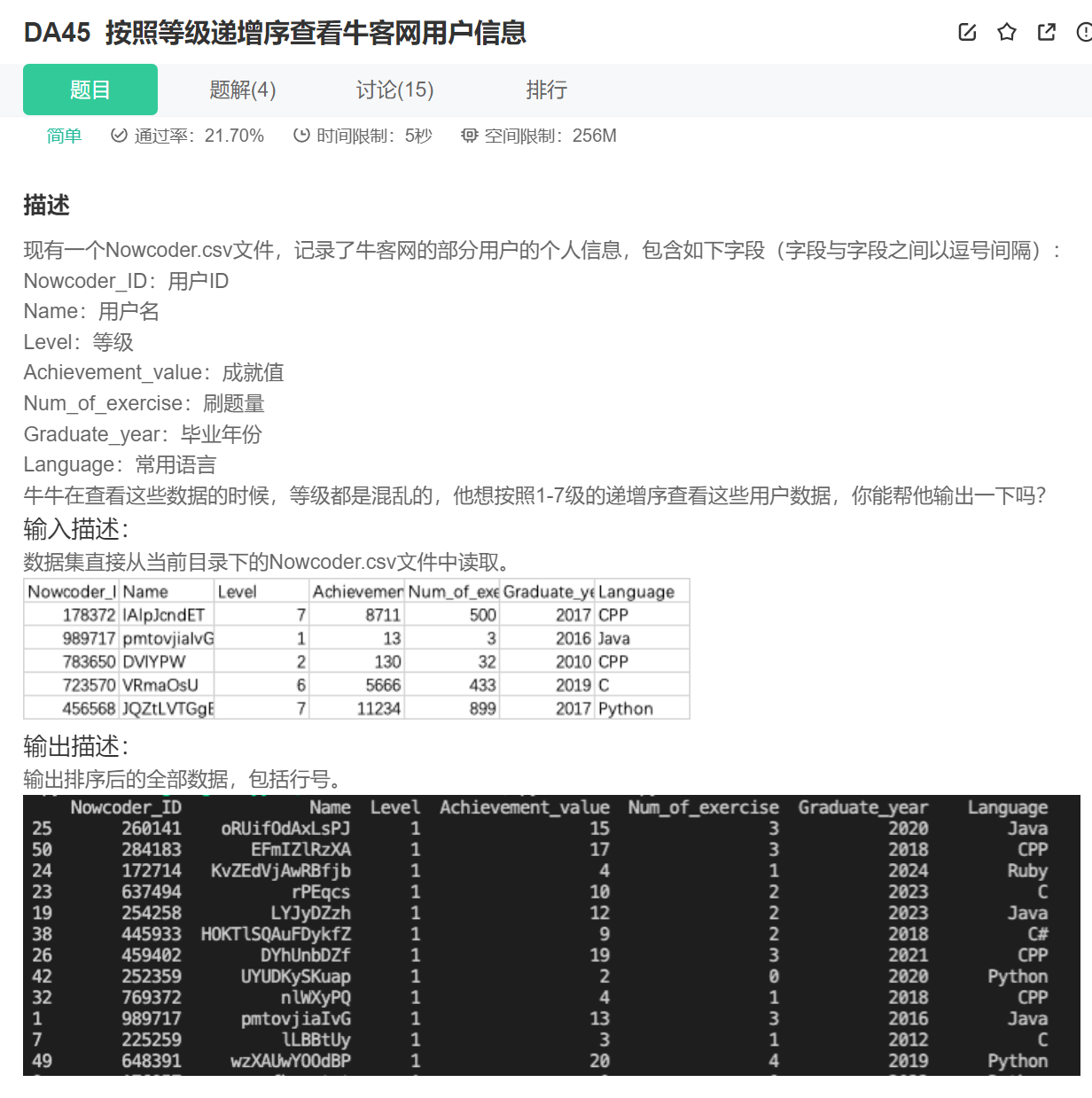
import pandas as pd
data = pd.read_csv("Nowcoder.csv")
# 设置显示宽度为300
pd.set_option("display.width", 300)
# 显示所有列,默认只显示20列
pd.set_option("display.max_columns", None)
# 显示所有行,默认只显示60行
pd.set_option("display.max_rows", None)
print(data.sort_values(by="Level"))
6.8 数据清洗
去除空值

1、删除全为空值的行或列
data=data.dropna(axis=0,how='all',inplace=False)#行
data=data.dropna(axis=1,how='all',inplace=False)#列
2、删除含有空值的行或列
data=data.dropna(axis=0,how='any',inplace=False)#行
data=data.dropna(axis=1,how='any',inplace=False)#列
inplace是否在原数据集上进行操作修改,True代表就地修改,False代表不修改。
import pandas as pd
data = pd.read_csv("Nowcoder.csv",sep=',',dtype=object)
pd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
data3 = data.dropna(axis=0,how='any')
print(data3)
修补缺失用户的数据
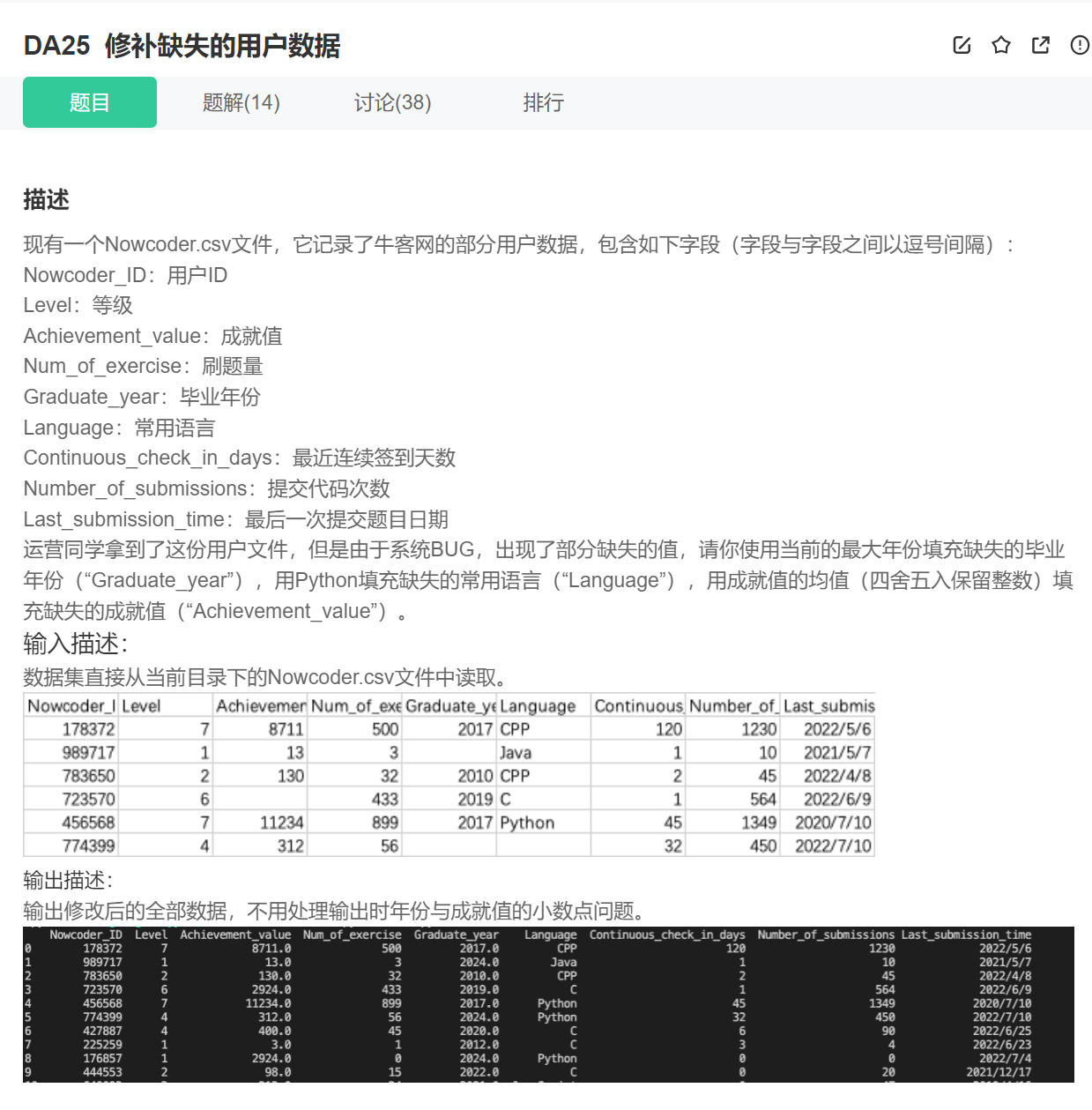
import pandas as pd
data = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
values = {
"Graduate_year": data["Graduate_year"].max(),
"Language": "python",
"Achievement_value": data["Achievement_value"].mean(),
}
# data_null_value = data.fillna(
# value={
# "Graduate_year": data["Graduate_year"].max(),
# "Language": "python",
# "Achievement_value": data["Achievement_value"].mean(),
# },
# inplace=False,
# )
data_null_value = data.fillna(
value=values,
inplace=False,
)
print(data_null_value)
重复数据

import pandas as pd
data=pd.read_csv('Nowcoder.csv')
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 1000)
pd.set_option('display.max_rows', None)
print(data.duplicated())
print(data.drop_dupilcated())
统一最后刷题日期的格式

pd.to_datetime(
arg,#int, float, str, datetime, list, tuple, 1-d array, Series DataFrame/dict-like
errors='raise',# {'ignore', 'raise', 'coerce'}, default 'raise'
dayfirst=False,
yearfirst=False,
utc=None,
format=None,#格式,比如 "%d/%m/%Y"
exact=True,
unit=None,#单位str, default 'ns',可以是(D,s,ms,us,ns)
infer_datetime_format=False,
origin='unix',#指定从什么时间开始,默认为19700101
cache=True,
)
最主要用的就是
pd.to_datetime(arg,format=("%Y-%m-%d"))
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",", dtype=object) # 要设置sep,dtype
Nowcoder["Last_submission_time"] = pd.to_datetime(
Nowcoder["Last_submission_time"], format=("%Y-%m-%d")
) # python索引列一定要带表格索引(包括赋值)
# pandas有专门的的日期格式化函数
print(Nowcoder.loc[:, ["Nowcoder_ID", "Level", "Last_submission_time"]])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号