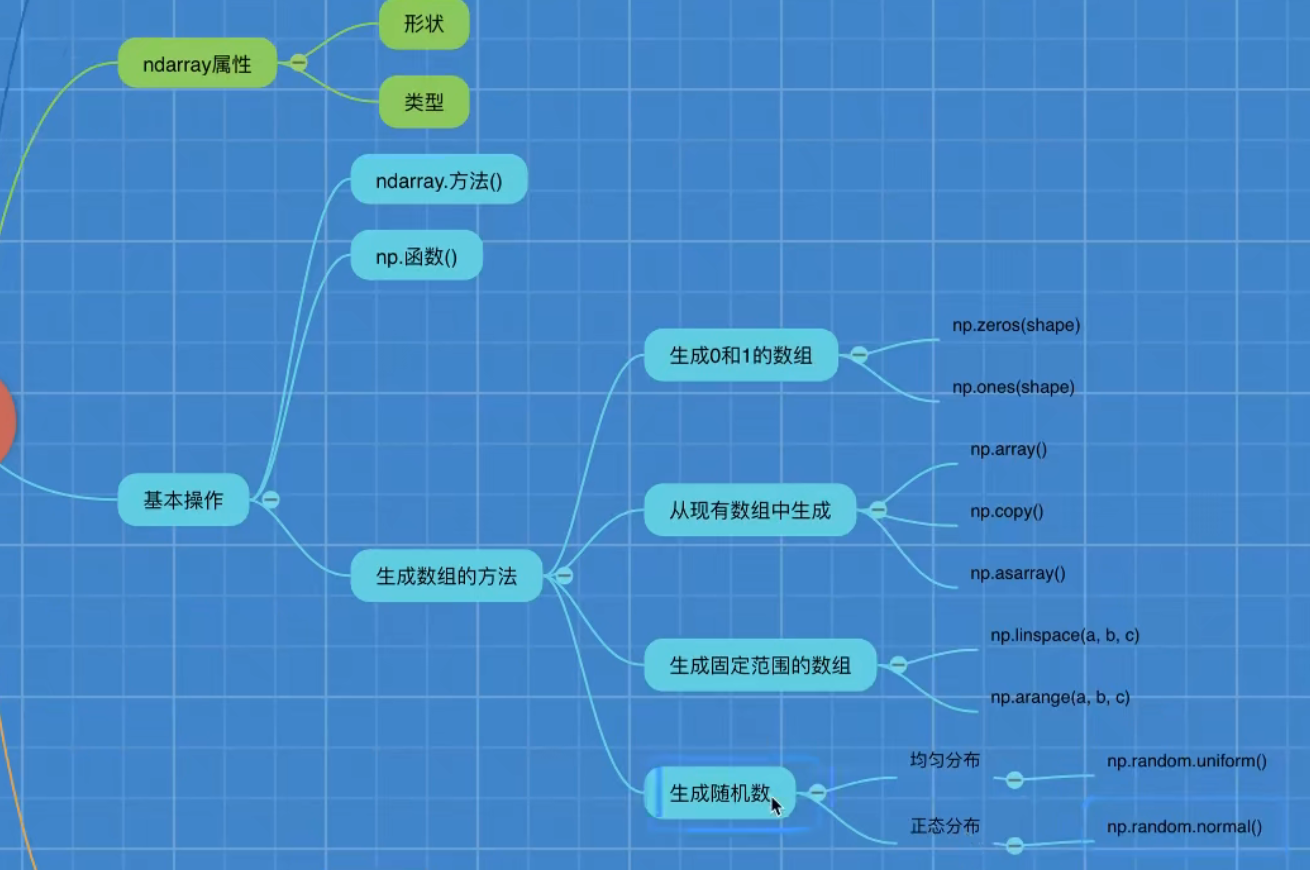
numpy库
1.介绍
Numpy (Numerical Python) 是一个开源的 Python 科学计算库,用于快速处理任意维度的数组。(n-任意 d-dimension 维度 array-数组)
Numpy 支持常见的数组和矩阵操作。对于同样的数值计算任务,使用 Numpy 比直接使用 Python 要简洁的多。
Numpy 使用 ndarray 对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
Numpy是一个数值计算库数据结构是ndarray
2.ndarray介绍
NumPy 提供了一个 N 维数组类型 ndarray,它描述了相同类型的"items"的集合
2.1 ndarray的属性
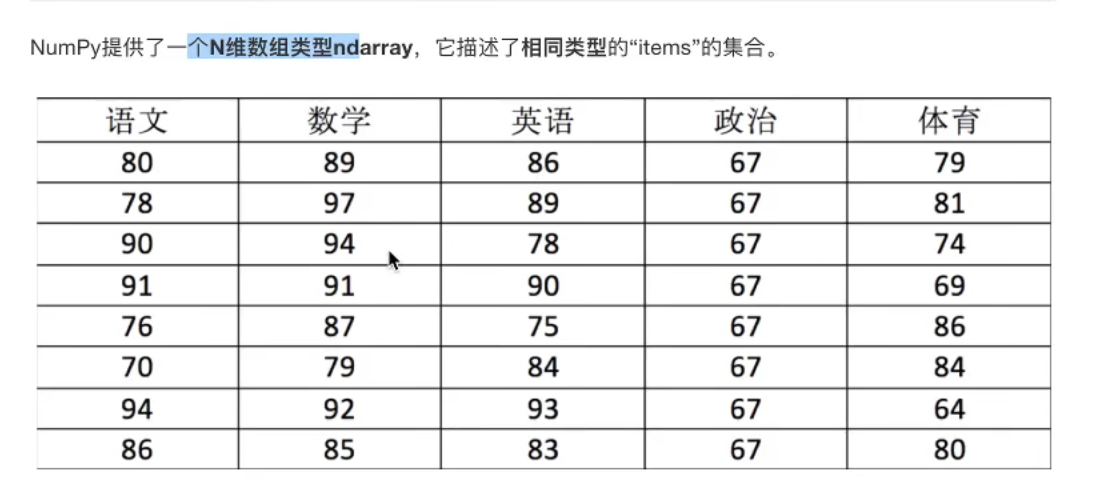
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
import numpy as np
score = np.array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
print(type(score))
print(score.shape)
print(score.dtype)
print(score.size)
<class 'numpy.ndarray'>
(8, 5) #维度
int32 #类型
40 #元素个数
2.2ndarray的形状
例如:
a = np.array([[1,2,3],[4,5,6]])
b = np.array([1,2,3,4])
c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
a #(2,3)
array([[1, 2, 3],
[4, 5, 6]])
b#(4,)
array([1, 2, 3, 4])
c(2,2,3)
array([[[1, 2, 3],
[4, 5, 6]],
[[1, 2, 3],
[4, 5, 6]]])
分析一下这个:
array([[1, 2, 3],
[4, 5, 6]]),这个说明一共有二维,第一维就是去掉一个中括号,之后是两个二维的([1, 2, 3],[4,5,6])然后第二位就是4,5,6有三个,所以是(2,3)
array([[[1, 2, 3],
[4, 5, 6]],
[[1, 2, 3],
[4, 5, 6]]])
这个一共有三维(可以看一下这个一个有多少个括号)
去掉最外面的括号之后有两个[[1, 2, 3],[4, 5, 6]],[[1, 2, 3],[4, 5, 6]]
然后取其中一个之后再去掉一个[],之后是两个[1, 2, 3],[4, 5, 6]
然后再取一个去掉[],之后是1,2,3三个
所以这个的形状为(2,2,3)

创建数组的时候指定类型
np.array([1.1, 2.2, 3.3], dtype="float32")np.array([1.1, 2.2, 3.3], dtype="float32")
3.生成数组的方法
3.1生成01数组
生成全0
np.zeros(shape=(3,4))
指定类型:np.zeros(shape=(3,4),dtype="flaot32")
生成全1
np.ones(shape(3,4))
指定类型:np.ones(shape=(3,4),dtype=np.int32)
3.2从现有的数组中生成
np.array()
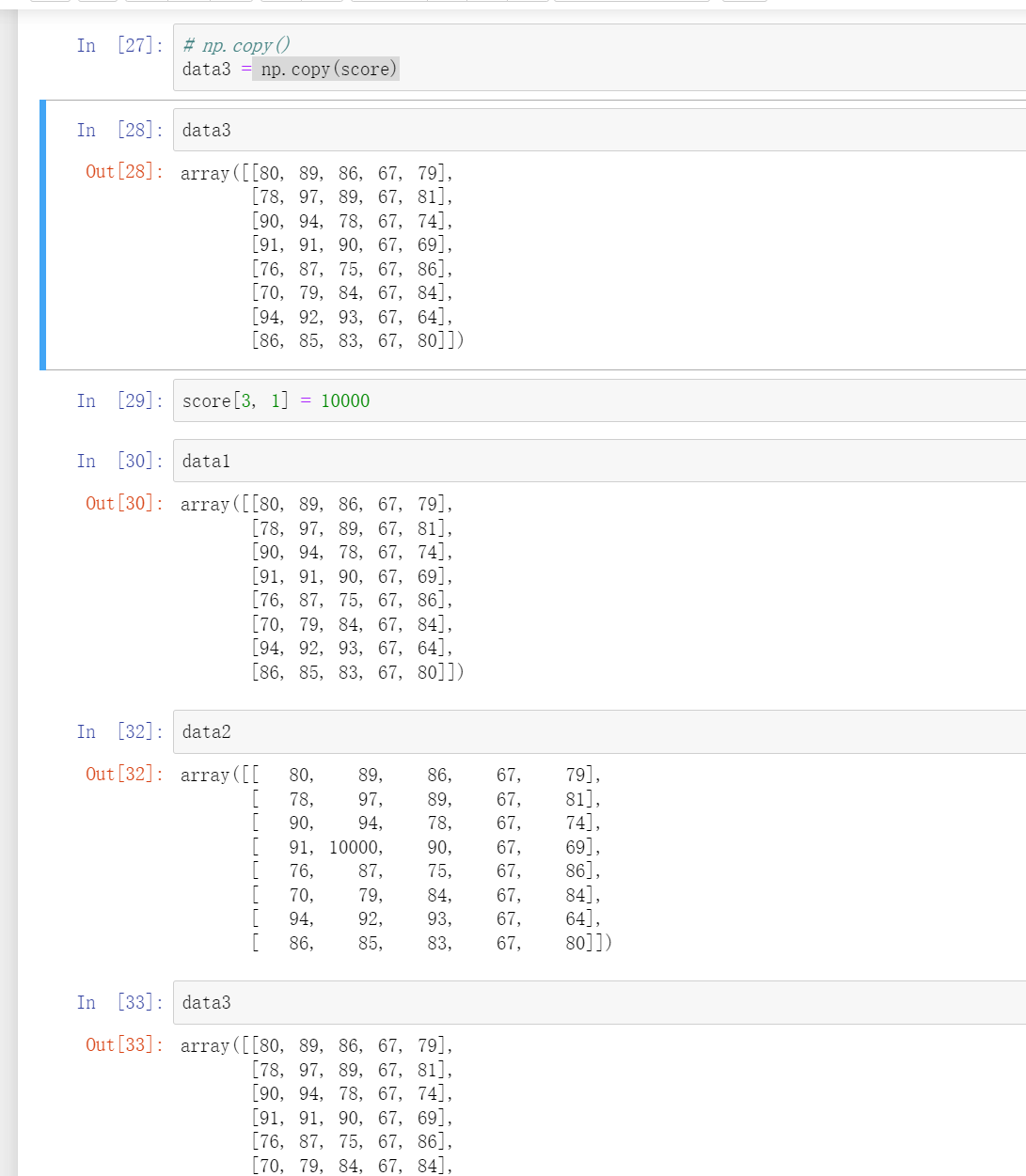
np.copy() #深拷贝
np.asarray() #浅拷贝
深拷贝就是原数组变了之后这个深拷贝的也会变

3.3生成固定范围的数组
1.np.linspace
np.linspace (start, stop, num, endpoint, retstep, dtype)
start序列的起始值stop序列的终止值,
如果endpoint为true,该值包含于序列中
num 要生成的等间隔样例数量,默认为50
endpoint序列中是否包含stop值,默认为ture
retstep如果为true,返回样例,以及连续数字之间的步长
dtype输出ndarray的数据类型
np.linspace(0,10,5)
返回结果
array([ 0. , 2.5, 5. , 7.5, 10. ])
2.np.arange()
np.arange()
arange(a,b,c) [a,b) c为步长
注意这个右区间是开的
3.4生成随机数组
np.random模块
3.4.1均匀分布(每一组的可能性相等)
np.random.uniform(low=0.0,high=1.0,size=None)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low:采样下界,float类型,默认值为0;high:采样上界,float类型,默认值为1;
size:输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k),则输出mnk个样本,缺省时输出1个值。
返回值: ndarray类型,其形状和参数size中描述—致。size=(2,3)生成一个2维2*3的数列
例如:
data1=np.random.uniform(low=-1,high=1,size=10)
data1
array([-0.32389251, 0.25663163, 0.18592025, 0.83991882, 0.94209985,
-0.41592839, 0.30407462, 0.30773603, 0.07309516, -0.00111122])
np.random.randint(low, high=None, size=None, dtype='/')
从一个均匀分布中随机采样,生成一个整数或N维整数数组,取数范围︰若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。
np.random.randint(low=1, high=100,size=10)
array([47, 95, 22, 4, 39, 44, 59, 25, 42, 63])
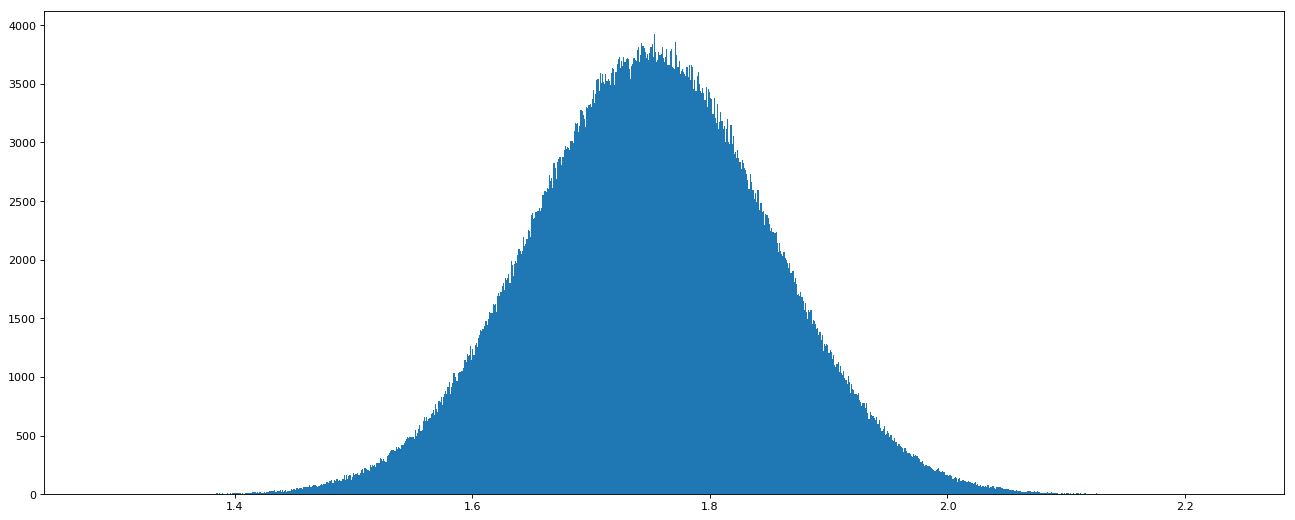
3.4.2正态分布

这个是常用的:
np.random.normal(loc=0.0, scale=1.0,size=None)
loc: float
此概率分布的均值(对应着整个分布的中心centre)
scale: float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size: int or tuple of ints
输出的shape,默认为None,只输出一个值
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000)
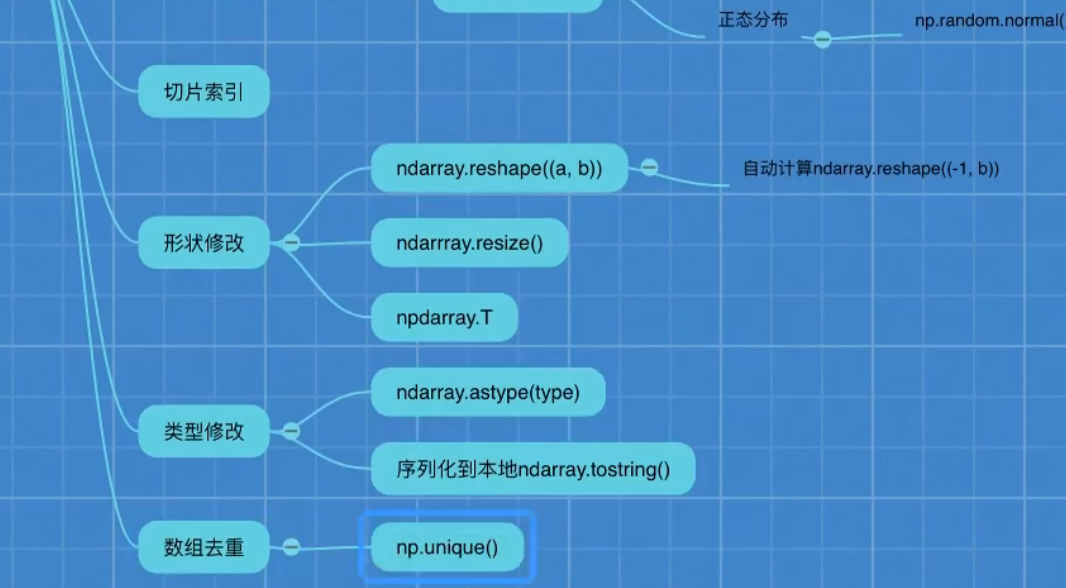
4.切片、索引和形状修改
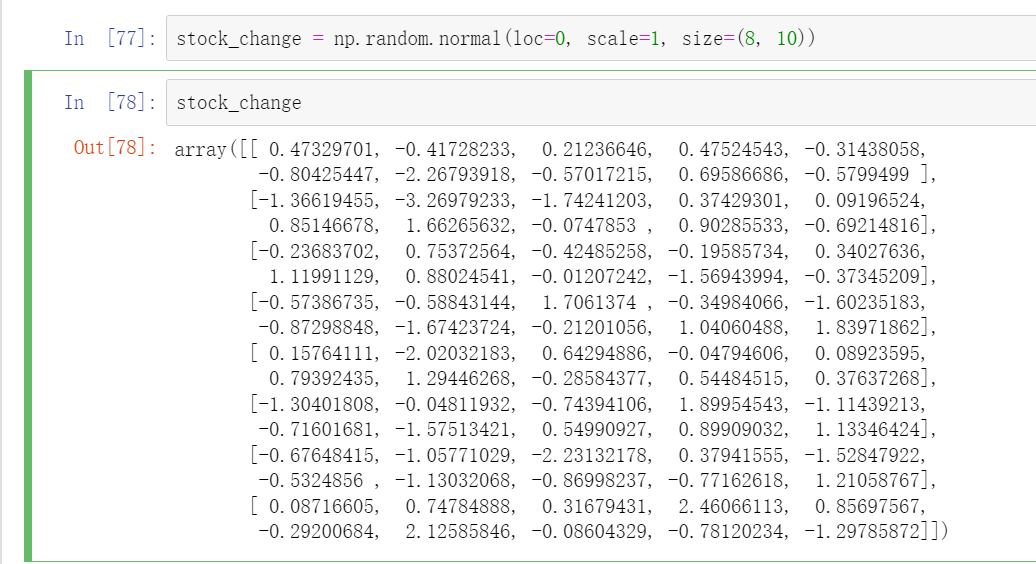
案例:随机生成8只股票2周的交易日涨幅数据
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
stock_change
array([[-1.57018774, -1.25970766, -2.3796732 , 1.14848963, -0.30345475,
1.20735246, -1.52672555, 0.13540022, 0.84785041, 0.61968931],
[ 0.61505944, -0.46245204, -0.94052479, 0.29319442, -0.25777012,
1.93851043, 1.61619433, 0.16969634, 1.59050888, 0.0138765 ],
[ 0.07429565, 0.56954703, 0.3926989 , 0.90978652, -0.61529256,
1.47658577, -2.01634565, 0.35092389, 1.3432413 , -0.28950357],
[ 0.79408811, -0.32485522, 0.19922215, 1.23239335, 1.19632515,
0.5691303 , -1.13906447, 0.3843912 , -0.38900849, 0.38448067],
[-1.12731803, 1.4888357 , -0.65074985, -1.03021949, 0.96198375,
-0.93488657, -0.57725512, 0.86569825, -0.06399348, -0.58289178],
[ 0.14884572, -1.15397656, 0.1978762 , 0.70838332, -1.90472605,
1.0220865 , 0.23101243, -0.80568295, 2.13918437, -1.73500104],
[-0.27744519, 1.65703998, 1.40726915, 0.2631683 , -0.18302691,
0.56395719, -2.74668778, -0.04663681, -0.67760237, 0.87581514],
[ 0.17755502, -0.95923995, -0.19681983, -0.54050483, -1.88367949,
0.16945743, -0.04160143, -2.12832587, 0.17009967, -0.77175123]])
4.1切片操作
获取第一个股票的前3个交易日的涨跌幅数据
也就是从stock_change[0][0]到stock_change[0][2]
然后这个就是
stock_change[0, 0:3]
#这个代码就是第一维是0,然后第二维是[0,3)
array([-1.57018774, -1.25970766, -2.3796732 ])
4.2数组的索引
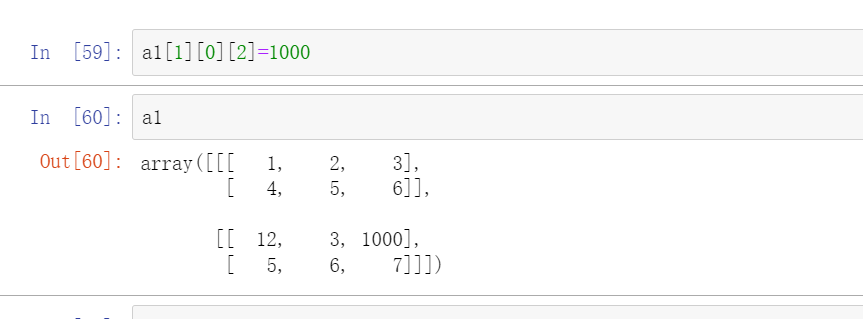
如果是查看的话直接:a[1][0][2]

修改的话直接赋值就行a[1][0][2]=10000
4.3形状的修改
需求:让刚才的股票行、日期列反过来,变成日期行,股票列
就是行,列反转
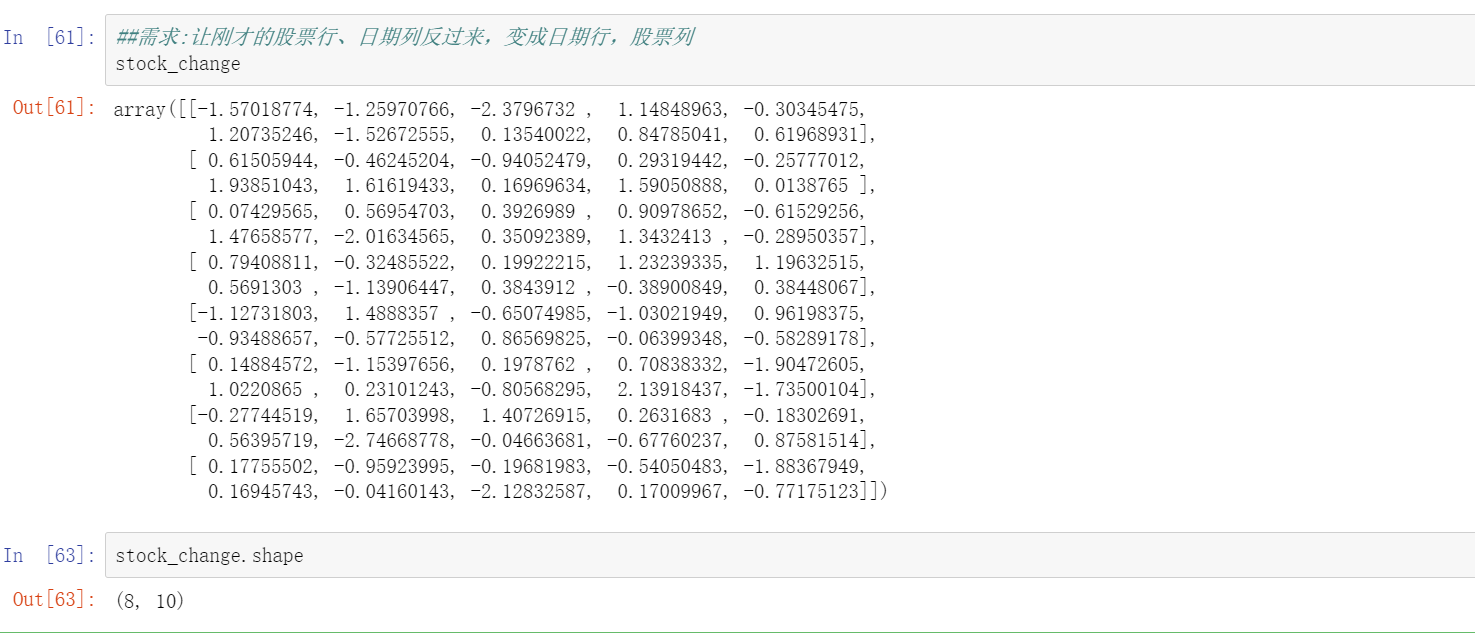
4.3.1 ndarray.reshape(shape)
原本是8行10列,现在要变成10行8列
stock_change.reshape((10,8))
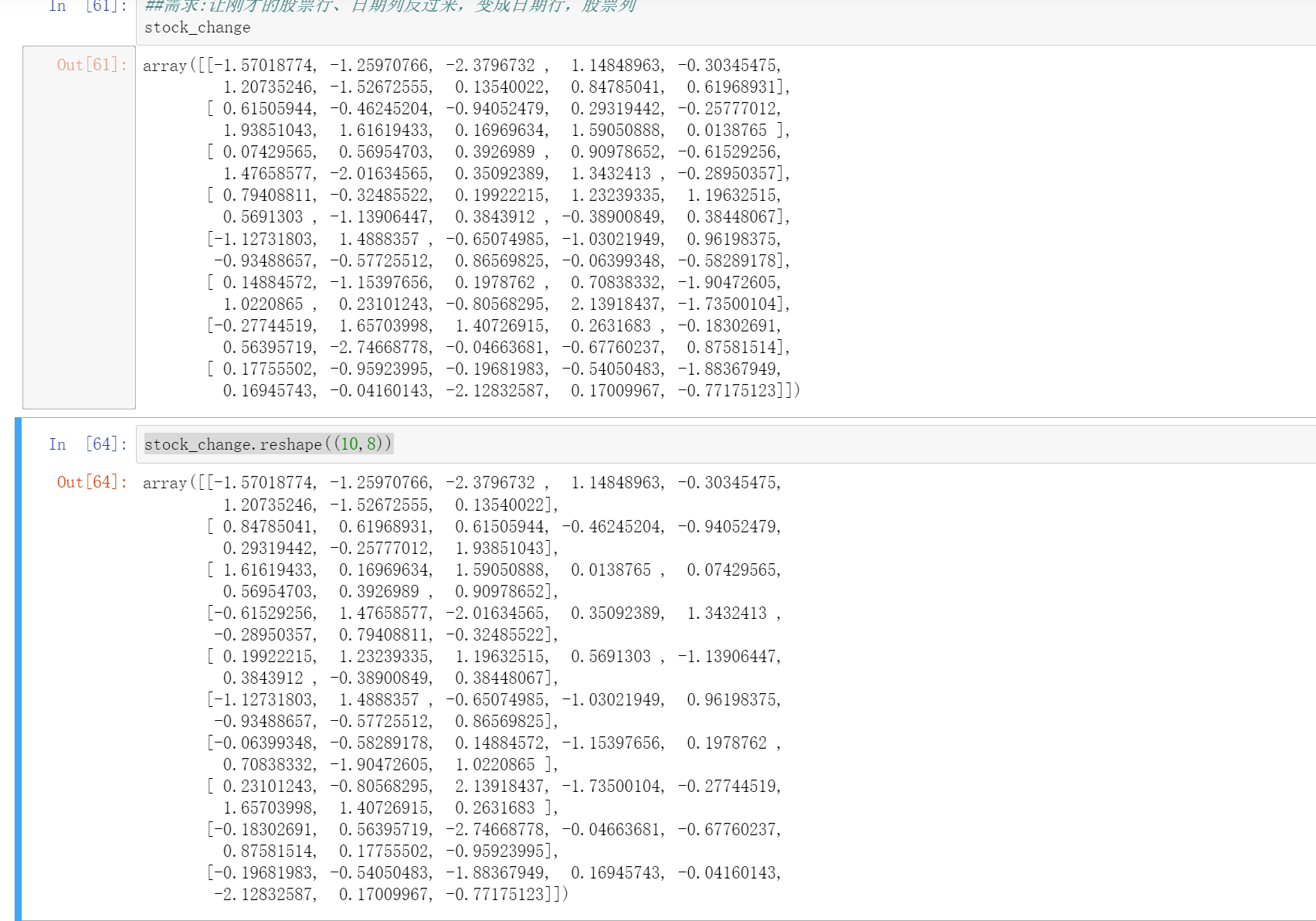
reshape(shape)返回新的ndarry,原始数据没有改变,而且我们发现没有真正的逆转
4.3.2 ndarray.resize(shape)
原本是8行10列,现在要变成10行8列
stock_change.resize((10,8))
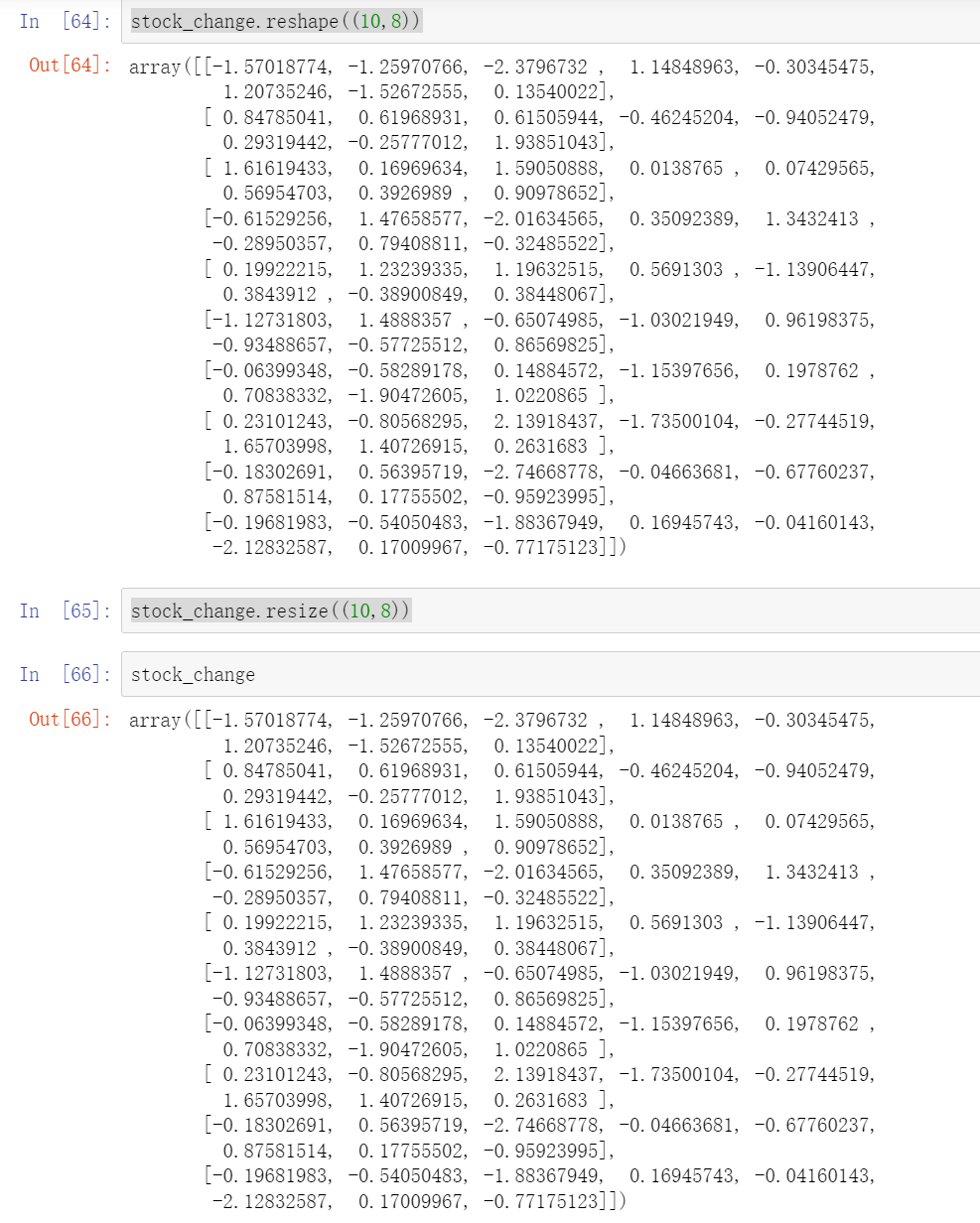
resize(shape)没有返回值,对原始数据进行改变,而且我们发现和上一个饭hi结果一样没有真正的逆转,就是这个对原始数据进行修改的
4.3.3 ndarray.T
原本是8行10列,现在要变成10行8列
stock_change.T
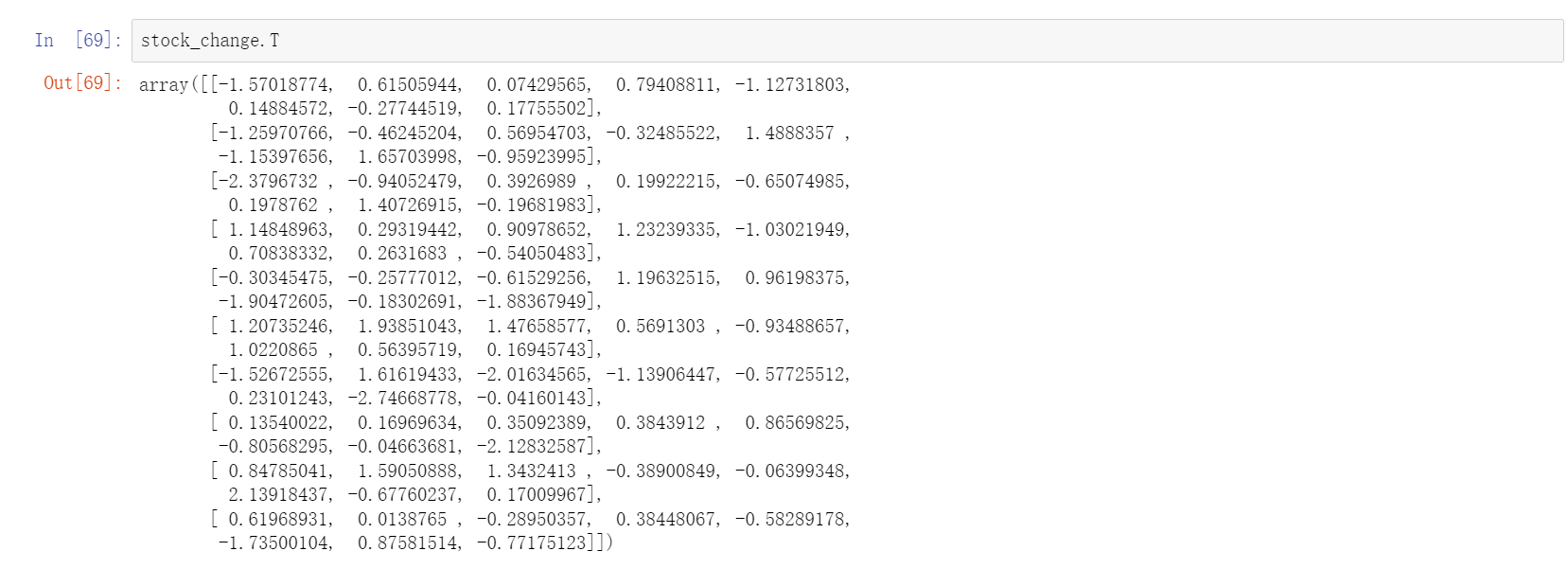
这个能实现真正意义上的逆转,行变列,列变行
4.4类型的修改
4.4.1 ndarray.astype(type)
stock_change.astype("int32")
array([[ 0, 1, 0, 2, 0, 0, -1, 0, 1, -1],
[-1, -1, 0, 1, -1, 0, 0, -1, 0, 0],
[ 0, 0, 1, 0, 1, 2, 0, 0, 0, 0],
[ 0, 0, -1, 0, 0, -1, 0, -1, 0, 0],
[ 0, -1, -2, -1, 0, 0, 0, 1, 1, 0],
[ 0, 1, 0, -2, -2, -1, 1, -2, 1, 1],
[-2, 0, 0, 0, 0, -1, 0, 0, 1, 0],
[ 0, 0, 0, 0, -1, -1, 0, 1, 1, 0]], dtype=int32)
4.4.2.ndarray.tostring()
ndarray序列化到本地
stock_change.tostring()
4.5数组的去重
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
之前可以用set,但是set只能用用于一维的,所以先变成一维的再去重
方法1:
set(temp.flatten())
#这个flatten是把二维数组变成一维的
#输出
{1, 2, 3, 4, 5, 6}
方法2.
np.unique(temp)
#输出
array([1, 2, 3, 4, 5, 6])
5.ndarray的运算
5.1 逻辑运算
原始数据
5.1.1 操作符合某一条件的数据,
1.例如:逻辑判断,如果涨跌幅大于0.5就标记为True否则为False
如果按照常规需要for循环,现在只需要:
stock_change>0.5
array([[False, False, False, False, False, False, False, False, True,
False],
[False, False, False, False, False, True, True, False, True,
False],
[False, True, False, False, False, True, True, False, False,
False],
[False, False, True, False, False, False, False, False, True,
True],
[False, False, True, False, False, True, True, False, True,
False],
[False, False, False, True, False, False, False, True, True,
True],
[False, False, False, False, False, False, False, False, False,
True],
[False, True, False, True, True, False, True, False, False,
False]])
2.如果我们想弄出来全部的>0.5的数据的话,我们只需要 stock_change[stock_change>0.5]
stock_change[stock_change>0.5]
array([0.69586686, 0.85146678, 1.66265632, 0.90285533, 0.75372564,
1.11991129, 0.88024541, 1.7061374 , 1.04060488, 1.83971862,
0.64294886, 0.79392435, 1.29446268, 0.54484515, 1.89954543,
0.54990927, 0.89909032, 1.13346424, 1.21058767, 0.74784888,
2.46066113, 0.85697567, 2.12585846])
3.如果我们想把全部的>0.5的数据进行统一的操作的话 stock_change[stock_change>0.5]=1.1\
stock_change[stock_change>0.5]=1.1
stock_change
array([[ 0.47329701, -0.41728233, 0.21236646, 0.47524543, -0.31438058,
-0.80425447, -2.26793918, -0.57017215, 1.1 , -0.5799499 ],
[-1.36619455, -3.26979233, -1.74241203, 0.37429301, 0.09196524,
1.1 , 1.1 , -0.0747853 , 1.1 , -0.69214816],
[-0.23683702, 1.1 , -0.42485258, -0.19585734, 0.34027636,
1.1 , 1.1 , -0.01207242, -1.56943994, -0.37345209],
[-0.57386735, -0.58843144, 1.1 , -0.34984066, -1.60235183,
-0.87298848, -1.67423724, -0.21201056, 1.1 , 1.1 ],
[ 0.15764111, -2.02032183, 1.1 , -0.04794606, 0.08923595,
1.1 , 1.1 , -0.28584377, 1.1 , 0.37637268],
[-1.30401808, -0.04811932, -0.74394106, 1.1 , -1.11439213,
-0.71601681, -1.57513421, 1.1 , 1.1 , 1.1 ],
[-0.67648415, -1.05771029, -2.23132178, 0.37941555, -1.52847922,
-0.5324856 , -1.13032068, -0.86998237, -0.77162618, 1.1 ],
[ 0.08716605, 1.1 , 0.31679431, 1.1 , 1.1 ,
-0.29200684, 1.1 , -0.08604329, -0.78120234, -1.29785872]])
5.1.2通用判断函数
np.all(布尔值)
只要有一个False就返回False,只要全是True才返回True
np.any()
只要有一个True就返回True,全部都是False才返回False
1.判断stock_change[0:2, 0:5]是否全是上涨的(是否全大于1)
# 判断stock_change[0:2, 0:5]是否全是上涨的
stock_change[0:2, 0:5] > 0
#输出
array([[ True, False, True, True, False],
[False, False, False, True, True]])
np.all(stock_change[0:2, 0:5] > 0)
False
5.1.3 三元运算符
np.where(三元运算符)
np.where(布尔值,Ture的位置的值,False的位置的值)
这个布尔值就是指的判断条件
例如:判断前四个股票前四天的涨跌幅大于0的置为1,否则为0
temp=stock_change[:4,:4]
temp
array([[ 0.47329701, -0.41728233, 0.21236646, 0.47524543],
[-1.36619455, -3.26979233, -1.74241203, 0.37429301],
[-0.23683702, 1.1 , -0.42485258, -0.19585734],
[-0.57386735, -0.58843144, 1.1 , -0.34984066]])
np.where(temp > 0 , 1 , 0)
array([[1, 0, 1, 1],
[0, 0, 0, 1],
[0, 1, 0, 0],
[0, 0, 1, 0]])
复合逻辑需要结合np.logical_and和np.logical_or使用
例如:
判断前四个股票前四天的涨跌幅大于0.5并且小于1的,换为1,否则为0
判断前四个股票前四天的涨跌幅大于0.5或者小于-0.5的,换为1,否则为0
np.where(np.logical_and(temp > 0.5,temp < 1),1,0)
np.where(np.logical_or(temp > 0.5,temp < -0.5),1,0)
如果直接用(temp>0.5) and (temp<1)会报错

所以用这个复合逻辑可以
np.where(np.logical_and(temp > 0.5, temp < 1), 1, 0)
#输出
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
np.where(np.logical_or(temp > 0.5, temp < -0.5), 11, 3)
#输出
array([[ 3, 3, 3, 3],
[11, 11, 11, 3],
[ 3, 11, 3, 3],
[11, 11, 11, 3]])
5.2 统计运算
主要是算最大值,最小值,平均值。。。。的

其中axis=0是每一列的最大值,axis=1是每一行的最大值
统计指标函数
min ,max ,mean ,median ,var ,std
直接np.函数名
ndarray.方法名
返回最大值,最小值的位置
例如:求最大值
temp
array([[ 0.47329701, -0.41728233, 0.21236646, 0.47524543],
[-1.36619455, -3.26979233, -1.74241203, 0.37429301],
[-0.23683702, 1.1 , -0.42485258, -0.19585734],
[-0.57386735, -0.58843144, 1.1 , -0.34984066]])
temp.max()
1.1
np.max(temp)
1.1
求每一行、列的最大值
temp.max(axis=0)
#这个返回的是每一列的最大值 axis=0 axis的值是维度影响的
array([0.47329701, 1.1 , 1.1 , 0.47524543])
np.max(temp,axis=1)
#返回的每一行的最大值 axis=1
array([0.47524543, 0.37429301, 1.1 , 1.1 ])
求每一行、列最大值所在的位置
np.argmax(temp,axis=)
np.argmax(temp,axis=1)
array([3, 3, 1, 2], dtype=int32)
返回的是第一行的第三个,第二行的第三个。。是最大值所在位置
5.3 数组间运算
5.3.1数组与数的运算
这个就是运算的时候数组里面的数全部都运算
arr = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr
array([[ 2, 4, 6, 4, 2, 8],
[10, 12, 2, 4, 6, 2]])
arr+10
array([[11, 12, 13, 12, 11, 14],
[15, 16, 11, 12, 13, 11]])
arr*2
array([[ 4, 8, 12, 8, 4, 16],
[20, 24, 4, 8, 12, 4]])
5.3.2 数组与数组的运算
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
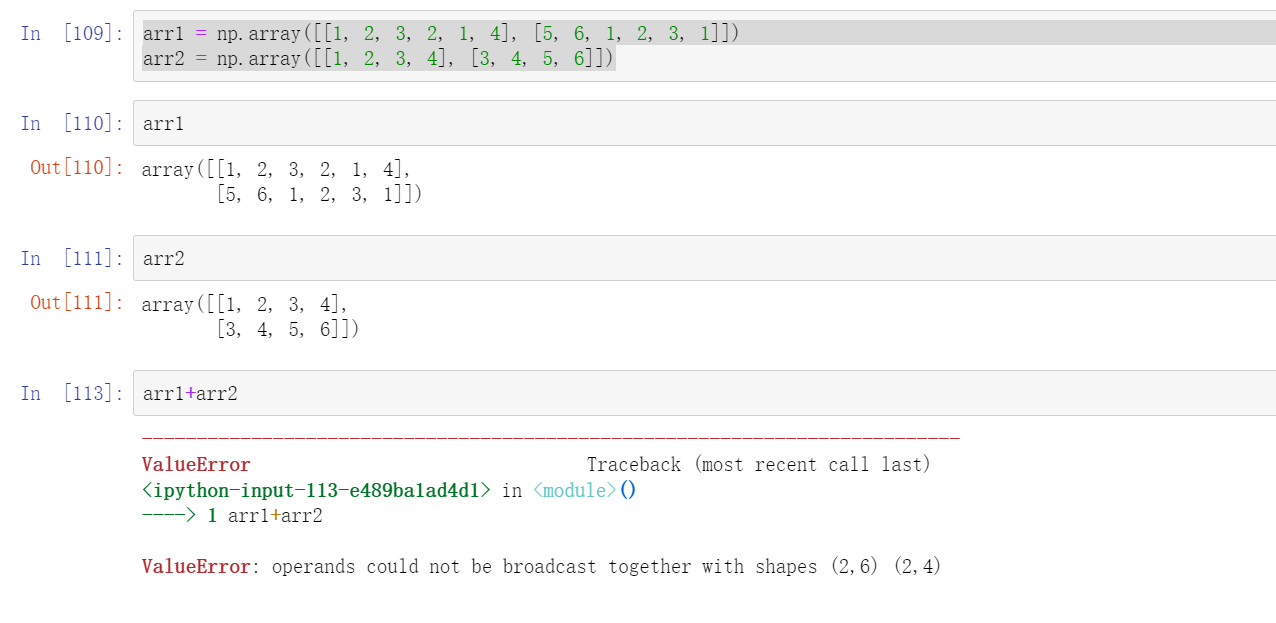
例如两个不同形状的数组进行加减的时候要满足广播机制
广播机制
执行 broadcast 的前提在于,两个ndarray 执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray (numpy库的核心数据结构)进行数学运算。
当操作两个数组时,numpy会逐个比较它们的shape(构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算。
·维度相等()
广播机制
执行 broadcast 的前提在于,两个ndarray 执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray (numpy库的核心数据结构)进行数学运算。
当操作两个数组时,numpy会逐个比较它们的shape(构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算。
·维度相等
·shape(其中相对应的一个地方为1)
下面这些是能进行运算的
其中第一个满足维度相等,第二个满足有一个地方为1,第三个也满足为1,第四个满足两个

下面这些不能匹配

例如这个:
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1], [3]])
arr1#(2,6)
arr2#(2,1)
对应位置是1所以可以运算
5.3.3 矩阵运算
矩阵metrix 二维数组
矩阵的存储:
(1)ndarray存储矩阵
就是二维数组
data = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
data
array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
(2) metrix 数据结构
matrix存储矩阵
data_mat = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
data_mat
matrix([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
5.3.3 矩阵乘法
(m,n)*(n,l)=(m,l)
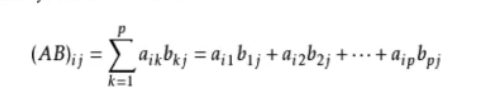
如果是array存储的矩阵:
可以用np.matul(arr1,arr2)
也可以用np.dot(arr1,arr2)
如果是array存储的话需要满足广播机制才能运算
如果用matrix存储的话:
可以直接arr1*arr2
六.合并和切割
6.1合并
合并API
numpy.hstack(tup) Stack arrays in sequence horizontally (column wise)..
numpy.vstack(tup) Stack arrays in sequence vertically (row wise).
numpy.concatenate((a1, a2,...), axis=O)
(1)np.hstack(a,b) 这个是横着拼接
例如:
a=np.array([[1],[2],[3]])
b=np.array([[2],[3],[4]])
np.hstack((a,b))
array([[1, 2],
[2, 3],
[3, 4]])

(1)np.vstack(a,b) 这个是横着拼接
例如:
a=np.array([1,2,3])
b=np.array([4,5,6])
np.vstack((a,b))
array([[1, 2, 3],
[4, 5, 6]])
a=np.array([[1],[2],[3]])
b=np.array([[2],[3],[4]])
np.vstack((a,b))
array([[1],
[2],
[3],
[2],
[3],
[4]])
np.concatenate()

6.2分割
numpy.split(ary,indices_or_sections,axis=0)
Split an array into multiple sub-arrays.
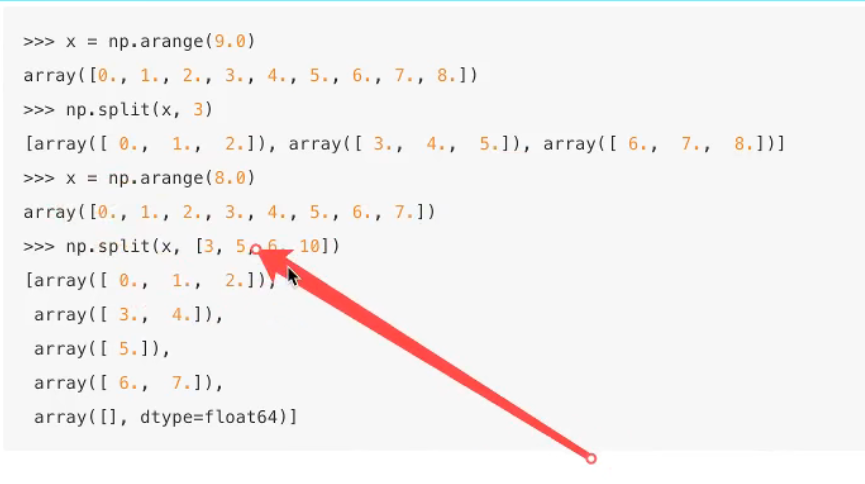
总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号