随笔分类 - 深度学习&机器学习&机器学习 / 深度学习-pyTorch
摘要:# Inception块 当时有个疑问$1 * 1$、$3 * 3$、$5 * 5$、$Max pooling$、$Multiple 1 * 1$,到底用那个好呢?  由两个部分组成: • 卷积编码器:由两个卷积层组成; • 全连接层密集块:由三个全连接层组成。  × (n_w − k_w + 1)$。因此,卷积的输出形状取决于输入形状和卷积核的形状。 假如有一个$240 × 240$像素的图像,经过10层$5 × 5$
阅读全文
posted @ 2023-08-14 16:09
lipu123
摘要:# 二维卷积层计算 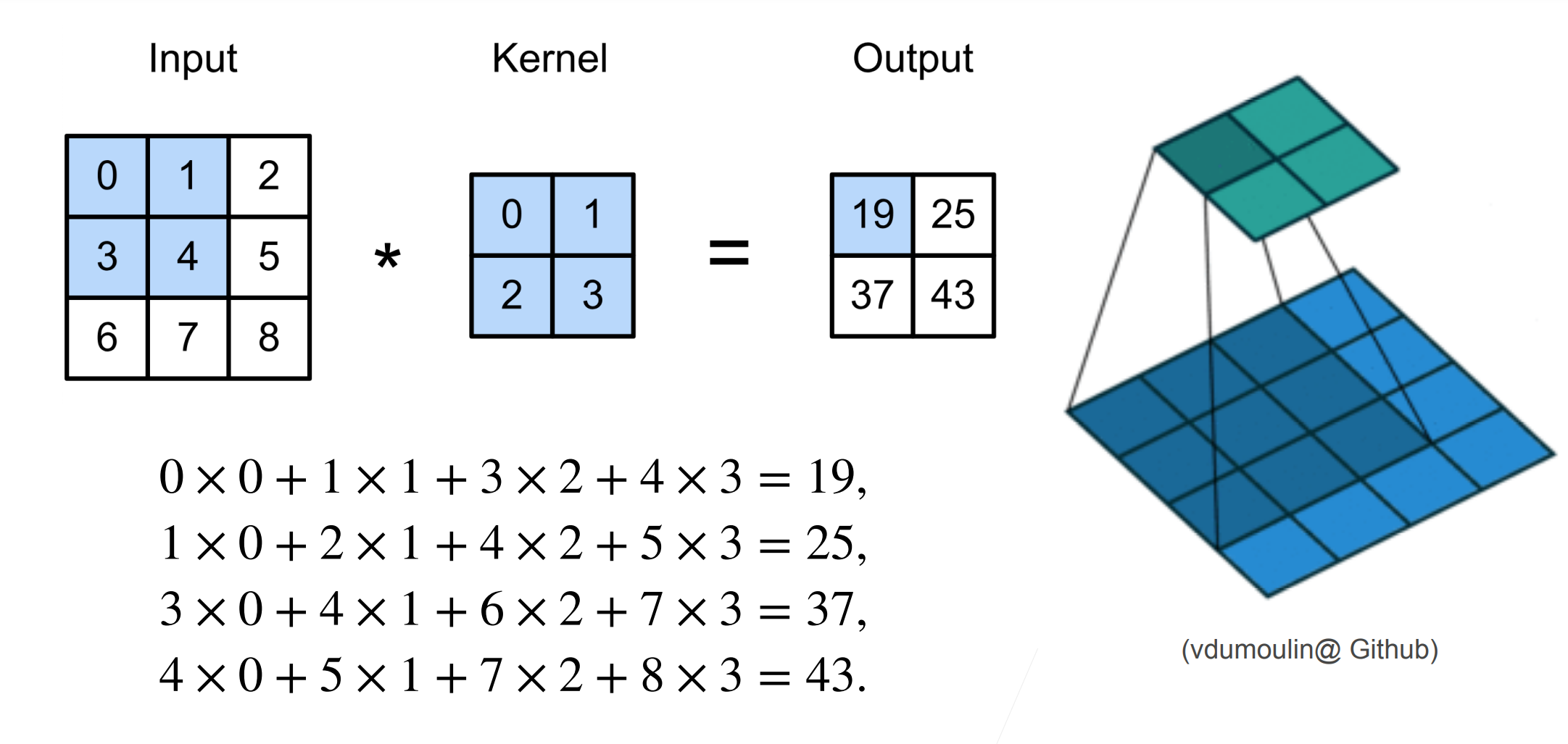 * 输入 X : $n_h * n_w$ * 卷积核 W : $k_h * k_w$
阅读全文
posted @ 2023-08-13 22:27
lipu123
摘要:要想时使用GPU,首先要先安装CUDA和GPU版的torch # 计算设备 我们可以指定用于存储和计算的设备,如CPU和GPU。默认情况下,张量是在内存中创建的,然后使⽤CPU计算它。在PyTorch中,CPU和GPU可以用torch.device('cpu') 和torch.device('cud
阅读全文
posted @ 2023-08-12 10:48
lipu123
摘要:# 加载和保存张量 对于单个张量,我们可以直接调用load和save函数分别读写它们。这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。 ``` import torch from torch import nn from torch.nn import functional a
阅读全文
posted @ 2023-08-12 09:39
lipu123
摘要:# 层和块 单个神经网络 (1)接受一些输入; (2)生成响应的标量输出; (3)具有一组相关参数(parameters),更新这些参数可以优化某目标函数。 然后,当考虑具有多个输出的网络时,我们利用矢量化算法来描述整层神经元。像单个神经元一样,层: (1)接受一组输入 (2)生成相应的输出 (3)
阅读全文
posted @ 2023-08-11 23:34
lipu123
摘要:安装: ``` pip install autogluon ``` # 官网实例 目的:预测一个人的收入是否超出5万美元 ``` from autogluon.tabular import TabularDataset, TabularPredictor ``` ## 数据读入 这里的这个Tabul
阅读全文
posted @ 2023-08-11 16:14
lipu123
摘要:# 下载和缓存数据集 ``` import hashlib import os import tarfile import zipfile import requests ``` 下面的download函数用来下载数据集,将数据集缓存在本地目录(默认情况下为../data)中,并返回下载文件的名称。
阅读全文
posted @ 2023-08-10 16:57
lipu123
摘要:# 神经网络的梯度 考虑⼀个具有$t$层(注意这里的t表示的是层)、输入$x$和输出$y$的深层网络。每⼀层$t$由变换$f_t$定义,该变换的参数为权重$W^{(t)}$,其隐藏变量是$h^{(t)}$(令$h^{(0)} = x$)。我们的网络可以表示为: $$h^t=f_t(h^{t−1})\
阅读全文
posted @ 2023-08-10 10:01
lipu123
摘要:# 正则化: **正则化:凡是能够减少泛化误差,而不是减少训练误差的方法就是正则化方法,也就是说能够减少过拟合的方法。** 在训练参数化机器学习模型时,权重衰减(weight decay)是广泛使用的正则化的技术之一,它通常也被 称为L2正则化。 # 权重衰减 在神经网络中我们有参数w和b,w是权重
阅读全文
posted @ 2023-08-09 11:18
lipu123
摘要:# 训练误差和泛化误差 - **训练误差:模型在训练数据上的误差** - **泛化误差:模型在新数据上的误差** 例子:根据摸考成绩来预测未来考试分数 - 在过去的考试中表现很好(训练误差)不代表未来考试一定会好(泛化误差) - 学生A通过背书在摸考中拿到很好成绩 - 学生B知道答案后面的原因 类似
阅读全文
posted @ 2023-08-06 16:34
lipu123
摘要:# 感知机 早期1960年的感知机,每一根线就是一个权重。  给定输入x,权重w,和偏移b,感知机输出:
阅读全文
posted @ 2023-08-05 22:26
lipu123
摘要:# 分类问题 ## 什么是分类问题 回归 vs 分类 ·回归估计一个连续值 ·分类预测一个离散类别 例如:
阅读全文
posted @ 2023-08-05 11:06
lipu123
摘要:# 线性回归 - 一个简化模型 假设1:影响房价的关键因素是卧室个数,卫生间个数和居住面积,记为$x_1,x_2,x_3$ 假设2:成交价是关键因素的加权和$y=w_1*x1+w_2*x_2+w_3*x_3+b$ ## 线性模型 - 给定n维输入 $x=[x_1,x_2,....x_n]^T$ -
阅读全文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号