1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
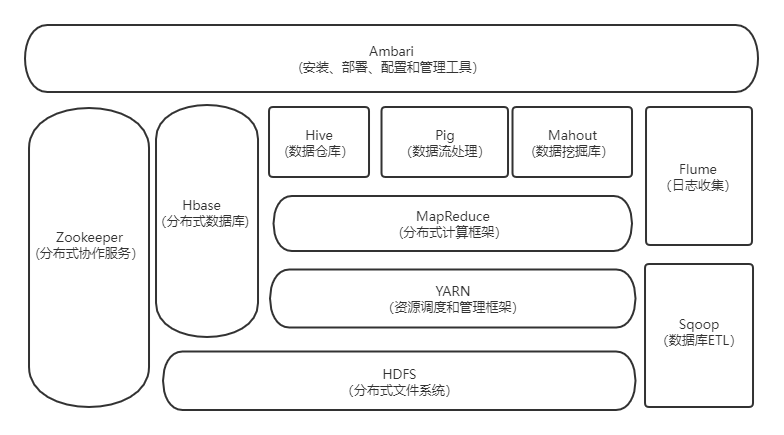
1.HDFS(分布式文件系统)
HDFS是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
2.YARN(资源调度和管理框架)
YARN 是负责集群资源调度管理的组件。
3.MapReduce(分布式计算框架)
MapReduce是分布式并行编程模型,用于大规模数据集的并行计算。
4.Hive(数据仓库)
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
5.Pig(数据流处理)
Pig是数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业
6.Mahout(数据挖掘库)
Mahout用于机器学习和数据分析。
7.Hbase(分布式列存数据库)
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
8.Zookeeper(分布式协作服务)
Zookeeper是协调服务。主要解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
9.Flume(日志收集工具)
Flume 是 一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
10.Sqoop(数据库ETL)
Sqoop主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
11.Ambari
Ambari是配置,监控和管理hadoop的平台。
2.对比Hadoop与Spark的优缺点。
Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载) 其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。 最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作。
3.如何实现Hadoop与Spark的统一部署?
Hadoop生态系统中一些组件实现的功能,是目前无法由Spark取代的。由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署

 浙公网安备 33010602011771号
浙公网安备 33010602011771号