4.RDD创建
一、 RDD创建
1. 从本地文件系统中加载数据创建RDD
- sc:SparkContext的创建
- 从文件系统中加载数据创建RDD
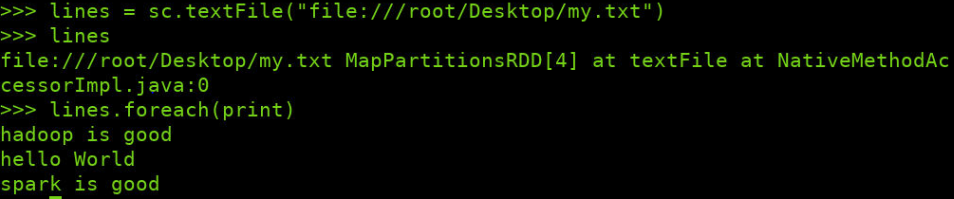
>> lines = sc.textFile("file://root/DesKtop/my.txt")
>> lines
>> lines.foreach(print)
2. 从HDFS加载数据创建RDD
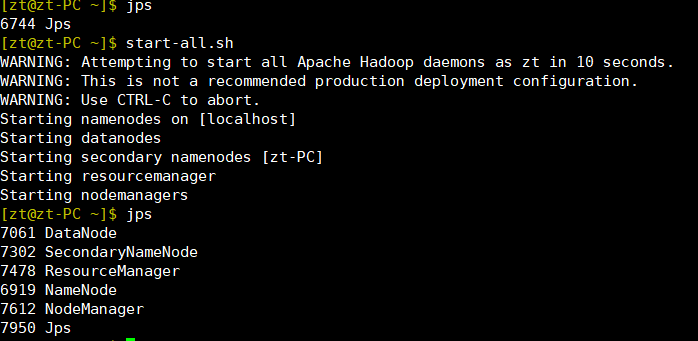
- 启动hdfs
start-all.sh
- 上传文件
hdfs dfs -put 要上传的文件路径 上传目的路径

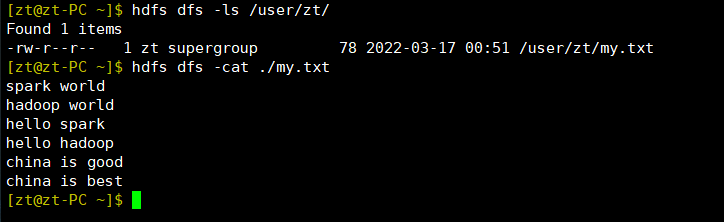
- 查看文件
hdfs dfs -ls /user/zt/ hdsf dfs cat ./my.txt
- 进入spark加载hdfs文件
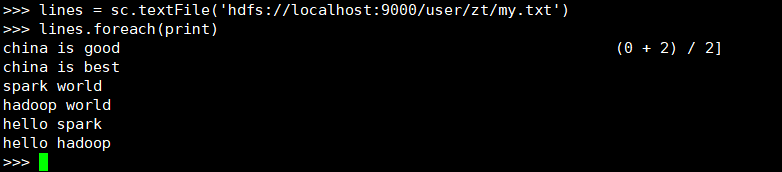
>> lines = sc.textFile('hdfs://localhost:9000/user/zt/my.txt')
>> lines.foreach(print)
- 停止hdfs
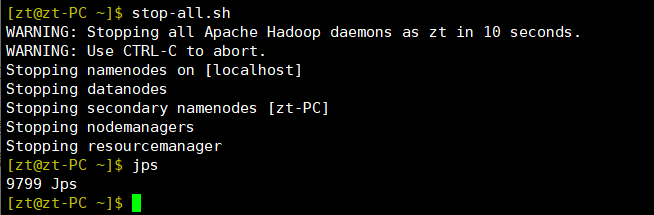
stop-all.sh
3. 通过并行集合(列表)创建RDD
- 输入列表、字符串、numpy生成数组
二、 RDD操作
转换操作
1. map(func)
含义:将每个元素传递到函数func中,并将结果返回为一个新的数据集
- lambda函数
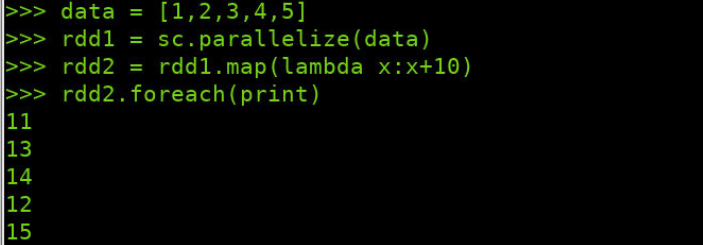
>>> data = [1,2,3,4,5] >>> rdd1 = sc.parallelize(data) >>> rdd2 = rdd1.map(lambda x:x+10) >>> rdd2.foreach(print)
- 显式定义函数

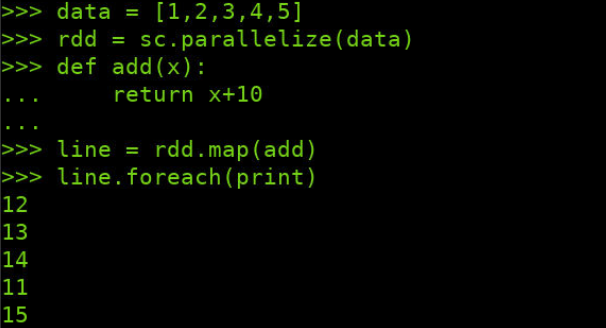
>>> data = [1,2,3,4,5] >>> rdd = sc.parallelize(data) >>> def add(x): ... return x+10 ... >>> line = rdd.map(add) >>> line.foreach(print)
2. filter(func)
含义:筛选出满足函数func的元素,并返回一个新的数据集
- lambda函数
>>> lines = sc.textFile('file:///root/Desktop/text.txt')
>>> linesWithSpark = lines.filter(lambda line: "spark" in line)
>>> linesWithSpark.foreach(print)

- 显式定义函数
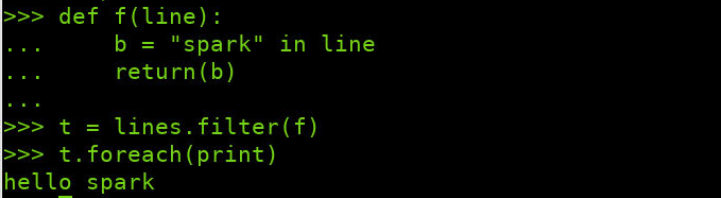
>>> def f(line): ... b = "spark" in line ... return(b) ... >>> t = lines.filter(f) >>> t.foreach(print)
行动操作
1.foreach(print)
foreach操作是直接调迭代rdd中每一条数据
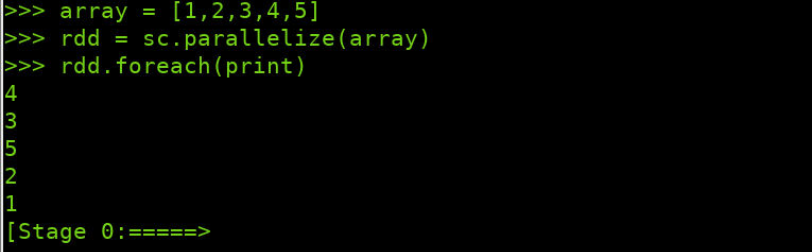
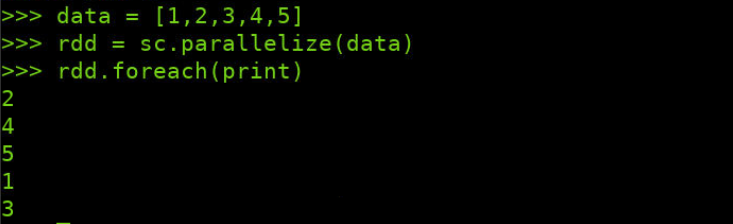
>>> data = [1,2,3,4,5] >>> rdd = sc.parallelize(data) >>> rdd.foreach(print)
2.collect()
collect操作在驱动程序中,以数组的形式返回数据集的所有元素
>>> data2 = [1,2,3,4,5] >>> rdd = sc.parallelize(data2) >>> rdd.collect()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号