多线程并发22进阶
书:java编程思想
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
java并发编程实战
EA(企业应用架构模式)
1.多线程设计模式:Future模式(netty)、Master-Worker模式(Storm)、生产者-消费者(mq)
2.线程安全:当多个线程访问一个类(对象或方法),此类始终能表现出正确的行为
多个线程多个锁:多个线程,每个线程都可拿到自己制定的锁,分别获得锁之后,执行synchronized方法体的内容
synchronized取得的锁都是对象锁,而不是把一段代码(方法)当做锁
当静态方法上加synchronized表示锁定.class类(类级别的锁,独占.class类)安全性更优
3.对象锁的同步和异步:
同步(共享):synchronized,如果没有共享,就没必要同步
:原子性(同步)
:可见性
异步:asynchronized 独立,相互之间不受到任何制约‘
分表:
分库:减缓数据库连接上限压力
4.脏读:读取到非正确修改后的数据
在对一个对象的方法加锁的时候,需要考虑业务的整体性,建议对(setV/getV)同时加锁synchronized,保证业务的原子性(侧面保证业务一致性)
,(牺牲部分性能,建议减小锁的粒度)
orcale:undo保证数据 强一致性
A:原子性
C:一致性
I:隔离性
D:持久性
5.锁重入:当一个线程得到了一个对象的锁后,再次请求此对象时时可以再次得到该对象的锁(加锁方法内部可再调用加锁的方法)
Lock:是一个接口,提供了无条件、可轮询、定时的、可中断的锁获取操作,所有加锁和解锁的方法都是显式的。
核心方法:lock() 获取锁,如果锁不可用,将禁用当前线程,并在获得锁之前,该线程一直出于休眠状态
ReentrantLock:互斥的同步器,具有扩展能力。吞吐量通常比synchronized好
Lock与synchronized比较:
1.Lock使用起来比较灵活,但是必须有释放锁的动作
2.Lock必须手动释放锁和开启锁,synchronized不需要
3.Lock只适用于代码块锁,而synchronized对象之间的互斥关系
常见锁参考:https://www.cnblogs.com/lxmyhappy/p/7380073.html
https://yq.aliyun.com/articles/34759
分段锁:系统提供一定数量的原始锁(借鉴concurrentHashMap的分段思想),根据传入对象的哈希值获取对应的锁并加锁;
注意:锁的对象的哈希值如果发生改变,有可能导致所无法成功释放
6.volatile:作用是使变量在多个线程间可见(具有可见性,不具备原子性(使用atomic)和同步性,可当做轻量级synchronized,性能要比synchronized强很多,
不会造成阻塞,netty中大量使用,volatile只针对于多个线程可见的变量操作,不能代替synchronized的同步功能);当变量改变时强制线程执行引擎去
主内存里读取在java中每个线程都会有一块工作内存,其存放着所有线程共享的主内存的变量值的拷贝。
当线程执行时,会在自己的工作内存中操作变量,为了存取一个共享的变量,一个线程通常先获取
锁定并清除它的内存工作区,把共享变量从共享内存区中正确地装入到其所在的工作内存中,当线程解锁时
保证该工作内存区中变量的值写回到共享内存中
static不能保证原子性,atomic类能保证自身是原子性,无法保证整个方法是原子性的
字符串加锁比较特殊,字符串内容改变了,则锁字符串将无效
synchronized:对象、ObjecA.class均可加锁
7.线程通信:线程是操作系统中的个体,通信提高cpu利用率和对线程任务在处理过程中的把控与监督
a.wait和notify必须配合synchronized使用
b.wait方法释放锁,notify方法不释放锁
CountDownLatch:当需要等到某一条件,发送信号量用(有延迟) //等待某个事件的发生
await(类似wait)和countDown(类似notify)也能实现通信
CyclicBarrier:等待所有的线程一起完成后再执行某个动作,即一组线程中只要一个未完成,则已完成的调用await等待其他线程执行完
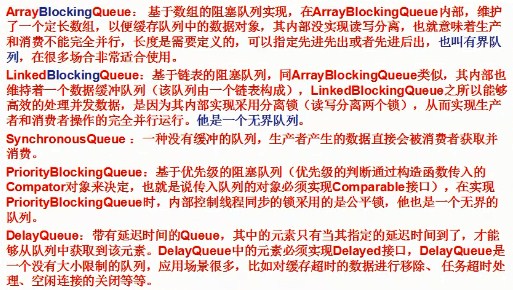
8.BlockingQueue(阻塞队列):支持阻塞机制的队列,阻塞的放入和得到数据 生产者和消费者模型用到
put:把对象加到队列,如果BlockQueue没有空间,则调用此方法的线程会被阻塞,
直到BlockingQueue里面有空间再继续
take:取走BlockingQueue里排在首位的对象,如为空,进入阻塞等待状态,直到有新的
数据被加入。
9.ThreadLocal:当前线程局部变量(与其他线程隔离),在高并发情况下,可减少锁竞争
10.多线程下的单例,随类初始化性能好:静态内部类
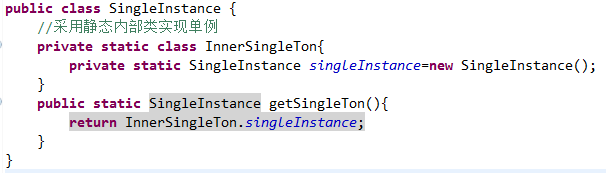
11.同步类容器(Vector、HashTable由Collections.synchronized*方法进行加锁,jdk1.5之前):串行化执行性能差、线程安全,但在某些场景下
可能需要加锁来处理复合操作(迭代等)
最常见异常:ConcurrentModificationException原因是当容器迭代的过程中,被并发的修改了内容,由于早期迭代器未考虑并发的问题
java.util.concurrent包完全建立在CAS之上的,没有CAS就没有并发包。并发包借助了CAS无锁算法实现了区别于synchronized同步锁的乐观锁。
因为对于CAS算法来说,就是在不加锁的前提下而假设没有冲突去完成某个操作,如果因为冲突而导致操作失败,那么就进行重试,直到成功为止。
CAS有三个操作数:真实的内存值V、预期的内存值A、要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为新值B,否则什么都不做。
缺点:虽然CAS有效的解决了原子操作的问题,但是其仍然有三个劣势:
1、ABA问题:因为CAS需要在操作前检查下值有没有发生变化,如果没有则更新。但是如果一个值开始的时候是A,变成了B,又变成了A,
那么使用CAS进行检查的时候会发现它的值没有发生变化,但是事实却不是如此。
ABA问题的解决思路是使用版本号,如A-B-A变成1A-2B-3A
2、循环时间长开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
3、只能保证一个共享变量的原子操作:对一个共享变成可以使用CAS进行原子操作,但是多个共享变量的原子操作就无法使用CAS,这个时候只能使用锁。
12.并发类容器(jdk1.5之后):ConcurrentHashMap代替HashTable
ConcurrentMap:
ConcurrentHashMap:内部使用段(Segment)来表示不同的部分(相当于小的HashTable),只要多个修改操作发生在不同的段上,就可以并发进行,
把一个整体分成了16个段,即最大支持16个线程的并发修改操作(多线程场景时减少锁的粒度,从而降低锁竞争的一种方案),并且代码中多使用
volatile关键字,目的是第一时间获取修改的内容,性能好
map.putIfAbsent()//如果key存在,就不执行put操作(cm的新增方法)
ConcurrentSkipListMap(支持并发排序)
13.CopyOnWrite:写时复制的容器,通俗理解:往一个容器添加元素,不直接添加,而是先将当前容器进行Copy,复制出一个新的容器,添加完元素之后,再将原容器的引用指向新的容器(读多写少操作时使用) 能否按小段进行copy?
好处:可对CopyOnWrite容器进行并发的读,而不需要加锁(读写分离的思想)
CopyOnwriteArrayList:
CopyOnWriteArraySet:
14.Queue:
ConcurrentLinkedQueue:高性能的队列代表
适用于高并发场景,通过无锁方式,实现了高并发状态下的高性能,基于链接节点的无界线程安全队列,队列中不允许null元素
add()和offer():加入元素在ConcurrentLinkedQueue中无区别
poll()和peek():取头元素节点,前者会删除元素,后者不会
size会遍历整个集合,速度慢,尽量避免,判断队列是否为空最好用isEmpty()
BlockingQueue:阻塞队列代表
add():将指定的元素插入到队列(如果可立即执行且不违反容量限制),成功是返回true,没有可用空间抛出IllegalStateException
offer():将指定的元素插入到队列(如果可立即执行且不违反容量限制),队列满时返回false,有容量限制的队列时,此方法优于add
put():将指定元素插入到队列,如有必要,则等待空间变得可用
poll:队列为空,返回null
remove:队列为空,抛出NoSuchElementException异常
take:队列为空,发生阻塞,等待有元素
13.多线程的设计模式,Future模式: 类似商品订单,Ajax请求,用户无需一直等待请求的结果
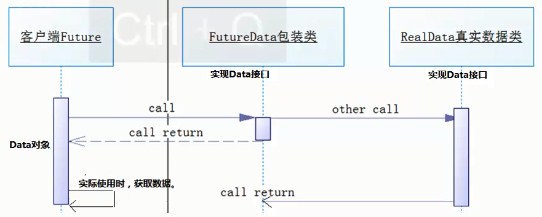
netty:FutureChannel采用此模式,readAndFlush()冲刷到缓冲区的过程是异步的;JDK的FutureTask
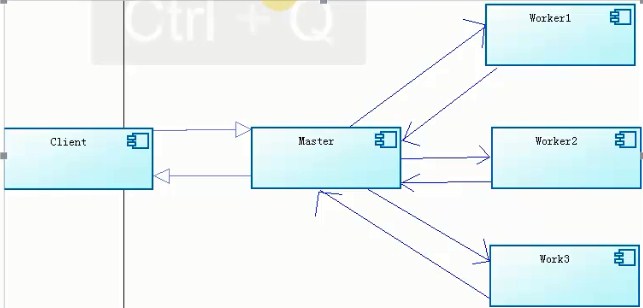
14.MasterWorker模式:并行计算模式,核心是系统由两类进程协作工作:Master进程和Worker进程,
Master负责接收和分配任务,Worker处理子任务。当各个Worker子进程处理完成后,会将结果返回
给Master,由Master做归纳和总结,好处是将一个大任务分解成若干个小任务,并行执行,从而提高
系统的吞吐量。分布式、大数据,hadoop的namenode和datanode
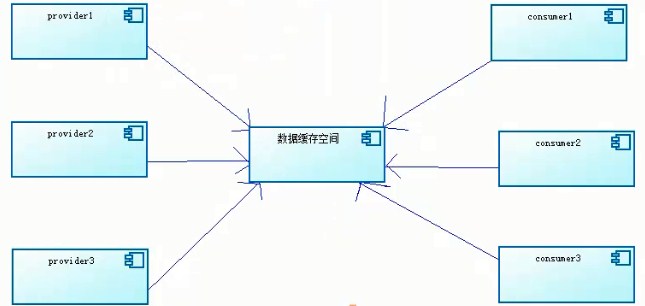
15.生产者和消费者:通常由两类线程(生产者和消费者线程),生产者负责提交用户请求,
消费者线程则负责处理生产者提交的任务,两者通过共享内存缓存区进行通信。MQ:底层多为netty
采用阻塞队列
16.jdk多任务执行框架:Executor
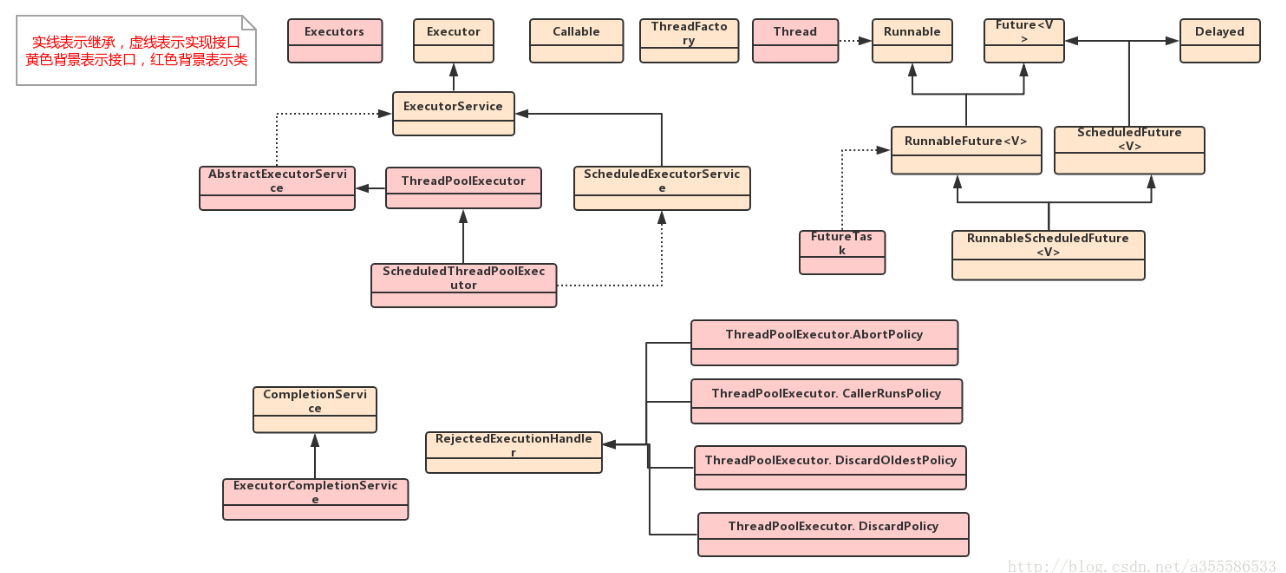
Executors是一个静态工厂,创建线程池方法(ThreadPoolExecutor实例化线程池):内部采用适配器模式?
newFixedThreadPool():返回固定数量的线程池,该方法的线程数始终不变,当有任务提交,如果线程池中空闲,则立即执行,
若没有则会被暂缓在一个任务队列中等待有空闲的线程再执行

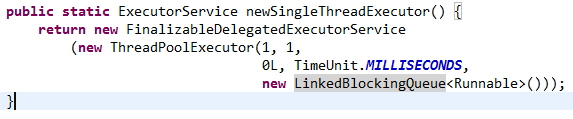
newSingleThreadExecutor ():创建一个线程的线程池,若空闲则执行,若没有空闲线程则暂缓在任务队列中
newCachedThreadPool():可根据实际情况调整线程个数的线程池,不限制最大线程数量,若有任务则创建线程,
若无任务则不创建线程。如果无任务则线程在60s后自动回收(默认)

newScheduledThreadPool():返回一个SchededExecutorService对象,但线程池可指定线程的数量。

ScheduledExecutorService和TimerTask对比:http://blog.csdn.net/guozebo/article/details/51090612
线程池的shotdown方法,jdk底层采用shutdown hock机制,友好地关闭线程
17.自定义线程池:当Executors工厂类无法满足业务需求,可自己创建自定义的线程池,使用有界队列和无界队列参数差异较大:
有界队列:有新任务执行,线程池实际线程数小于corePoolSize,则优先创建线程,
若大于corePoolSize,则将任务加入队列;若队列满了,则在总线程数不大于maxPoolSize的前提
下创建线程;若线程数大于maxPoolSize,则执行拒绝策略,或其他自定义方式。
无界队列:LinkedBlockingQueue,与有界队列比,除非系统资源耗尽,否则无界的任务队列不存在任务入队
失败的情况。当有新任务到来,系统线程数小于corePoolSize,则新建线程执行任务,当达到corePoolSize 后,则任务直接进入队列等待,不继续增加。若仍有新任务加入,
JDK拒绝策略:自定义拒绝策略实现RejectedExecutionHandler接口,重写rejectedExecution()
AbortPolicy:直接抛出异常阻止系统正常工作
CallerRunsPolicy:只要线程池未关闭,该策略直接在调用者线程中,运行当前丢弃的任务
DiscardOledestPolicy:丢弃最老的一个请求,尝试再次提交当前任务。
DiscardPolicy:丢弃无法处理的任务,不在做任何处理

20.disruptor:特别适用于对时间高度敏感的多线程应用,实现了有界队列的功能,对时间不敏感用ArrayBlockingQueue即可
原理:a.RingBuffer复用内存,减少分配新空间带来的时空损耗
b.单生产者对N消费者(不用锁)
c.BusySpin(疯狂死循环)是多核架构上最快的通讯方法,比经kernel走信号量都快
posted on 2018-03-06 18:17 xiaojiayu0011 阅读(345) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号