
MapReduce
1.MapReduce: MapTask & ReduceTask 默认大小1G ![]()
![]()
![]()
![]()
![]()
![]()
![]()
原语/语义:相同的key为一组,调用一次reduce方法,在reduce方法内迭代这一组数据进行计算
注意key的设计,reduce的合理使用
MapTask: key可重复(非hashMap),一个分区对应一个reduceTask,分区数决定并行数
ReduceTask:取相同key的值,
2.Shuffer<洗牌>:
文件采用归并算法对小文件块进行合并,使其内、外部有序
reduce对一组分区的数据进行归并(数据只能在分区内归并)
3.MapperReduce:离线计算
jobTracker类似NameNode对任务进行管理
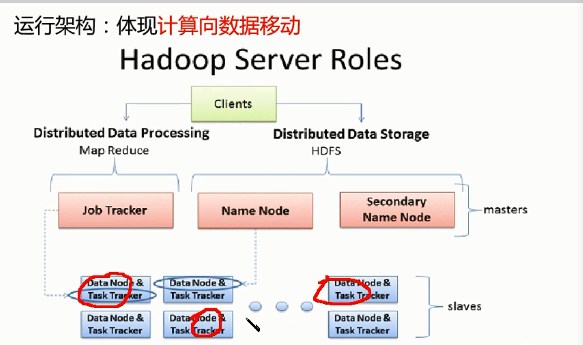
4.MRv1角色:
JobTracker:
核心、主、单点
调度所有的作业
监控整个集群的资源负载
TaskTracker:与DataNode一比1
从,自身节点资源管理
和JobTracker心跳交互,汇报资源,获取Task
Client:
作业为单位,规划作业的计算分布
提交作业资源(包含jar包)都HDFS
最终提交作业到JobTracker
弊端:
JobTracker:负载过重,单点故障
资源与计算强耦合,其他计算框架需要重复实现资源管理
不同框架对资源不能全局管理
5.对MR资源解耦,产生Yarn(只对资源进行操作,计算仍为MR执行),NodeManager与DataNode 一比一
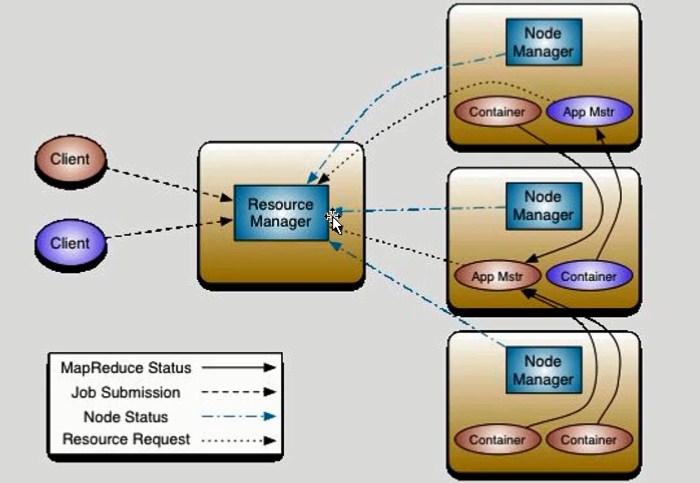
App Mstr(源自于Container)约等于JobTracker 监控Container Container约等于Jvm,会对资源大小进行限制
一切皆由Container产生
6.MRv2:On YARN
ResourceManager:
主、核心,集群节点资源管理
NodeMananger:
与RM汇报资源,管理Container生命周期,计算框架中角色都以Container标识
Container:存储节点NM,CPU,MEM,I/O大小,启动命令
默认NodeManager启动线程监控Container大小,超出申请资源额度,kill
支持Linux内核的Cgroup(linux3.x以上)
MR:
MR-ApplicationMaster-Container
作业为单位,避免单点故障,负载到不同的节点
创建Task需要和RM申请资源(Container)
Task交由Container管理
Client:RM-Client:请求资源创建AM
AM-Client:与AM交互
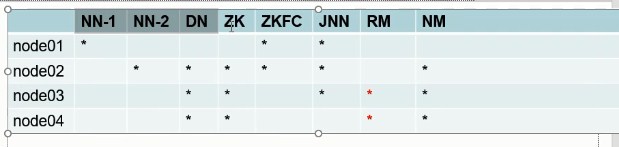
7.MR环境搭建方案:
1.配置mapred-site.xml
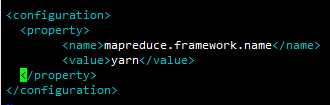
2.配置yarn-site.xml
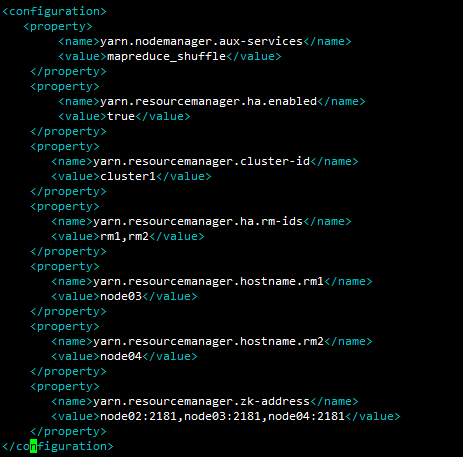
分发mapred-site.xml和yarn-site.xml到node02-04相同目录
scp mapred-site.xml yarn-site.xml node02:`pwd`
scp mapred-site.xml yarn-site.xml node03:`pwd`
scp mapred-site.xml yarn-site.xml node04:`pwd`
8.启动yarn,但只会启动node02-04的NodeManage,需要手动再启动node03和node04


posted on 2018-03-06 18:16 xiaojiayu0011 阅读(90) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号