
hadoop
1.采用hash散列算法读写文件 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2.计算向数据移动
3.Hadoop:Google 作者:Doug Cutting
OpenStack:NASA 云计算(集合基础设施、平台、软件)
4.PageRank:计算
5.HDFS:分布式计算文件
6.hdfs存储模型:
a.文件线性切割成块(Block):偏移量 offset(byte)
b.Block要分散存储在集群节点中
c.单一文件Block大小应一致,文件与文件可不一致
d.Block可以设置副本数,副本分散在不同节点中(副本不超过节点数量)
e.文件上传时可设置Block大小和副本数,已上传的Block副本数可以调整,大小不能变
f.只支持一次写入多次读取,同一时刻只有一个写入者
h.可以append追加数据
7.HDFS架构模型:
a.文件存储:元数据NameNode(存储上传的文件元数据,单节点)和数据本身DataNode保存文件Block数据:多节点 NameNode维护虚拟文件系统,真实存储数据,仍是os本身系统
b.DataNode与NameNode保持心跳,提交Block列表
c.HdfsClient与NameNode交互元数据
d.HdfsClient与DataNode交互Block数据
8.NameNode(NN):基于内存存储(不会和磁盘发生交换)
a.只存在内存中
b.持久化(快照到磁盘,运行时不用,重启时加载才会用)
NameNode保存metadata信息:
静态:文件owership和permissions
文件大小,时间
(Block列表:Block偏移量),不会持久化Block的位置信息
动态:位置信息 Block每个副本位置(由DataNode上报)
持久化:metadata在启动后会被加载,存储到磁盘文件名为"fsimage",只会加载静态数据
Block的位置信息不会保存到fsimage,
edits记录对metadata的操作日志
9.DataNode(DN):
本地磁盘目录以文件形式存储Block数据
同时存储Block的元数据(不同于NameNode,而为Block小文件的元数据,MD5)
启动DN是会向NN汇报block信息
通过向NN发送心跳保持与其联系(3秒),10分钟NN没收到DN的心跳,则认为lost,让其他节点重新备份该节点的Block
10.HDFS优点:
a.高容错性,数据自动保存多个副本,副本丢失后,自动恢复
b.适合批处理,移动计算而非数据,数据位置上报给计算框架(Block偏移量)
c.适合大数据量处理,GB、TB、设置PB级数据,支撑百万规模上的文件数量,支持10K+节点
d.可构建在廉价机器上,多副本提高可靠性,提供了容错和恢复机制
缺点:
a.数据访问延迟较大(相比单点io),吞吐率不高
b.小文件存取效率低,NameNode会占用大量内存,寻道时间会超过读取时间
c.不支持并发写入、文件随机修改,仅支持append
11.SecondaryNameNode(SNN):
a.不是NN的备份(但能完成备份),主要作为jvm中的一个进程,帮助NN合并edits log,减少NN启动时间
b.合并时间默认3600秒
12.Block的副本放置策略:
a.DN节点上,集群外提交时,随机挑选一台磁盘不太满,cpu不忙的节点存储
b.第二副本放置不同于第一个节点
c.第三副本放置与第二副本相同机架的节点
d.更多副本:随机节点(不同于第一副本节点)
13.拷贝文件到远端:scp ./jdk-7u67-linux-x64.rpm root@192.168.50.12:~/soft/
14.伪分布式搭建hadoop步骤:
1.配置jdk
2.配置ssh ssh loaclhost(自动创建本地ssh文件),对本机测试,会要求输入密码
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa 创建密钥
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥转移到文件authorized_keys,用于远端免密码认证
再ssh localhost就不用再要求输入密码
3.解压hadoop软件,将目录/root/hadoopEnv/hadoop-2.6.5配置/etc/profile环境文件中
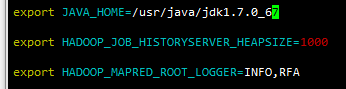
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/root/hadoopEnv/hadoop-2.6.5 (hadoop存放目录,后续给其他节点使用)
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后再. /etc/profile重新加载环境配置
hadoop+tab就可以补全
4.进入/root/hadoopEnv/hadoop-2.6.5/etc/hadoop
编辑vim hadoop-env.sh,
vim mapred-env.sh
vim yarn-env.sh 修改JAVA_HOME为绝对路径
5.查看节点情况
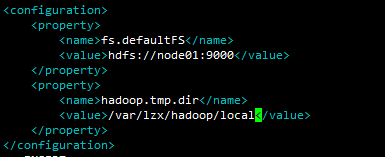
vi core-site.xml node01为本机节点,/var/lzx/hadoop/local为文件存储目录
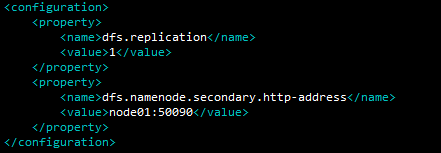
vi hdfs-site.xml dfs.replication分布式文件副本数,dfs.namenode.secondary.http-address配置Second NameNode
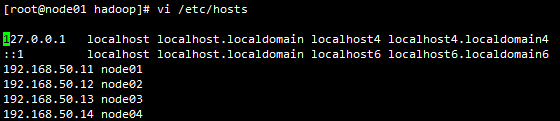
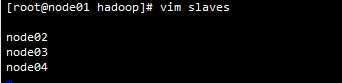
6.vi slaves指定nameNode, 配置node01
7.格式化namenode文件系统,产生fsimage和id


8./var/lzx/hadoop/local/dfs 目录下启动start-dfs.sh
jps可以查看到NameNode等进程已启动
9.检查NameNode和DataNode的clusterID是否一致
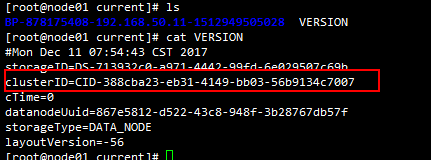
10.http://node01:50070/ 即可查看是否搭建完成
11.hdfs dfs -mkdir -p /user/root/ 根据用户增加一个home目录
hdfs dfs -put ./soft/hadoop-2.6.5.tar.gz /user/root/ 上传文件(默认128M)
12.stop-dfs.sh 停止hadoop环境
15.分布式Hadoop环境搭建,方案设计如下
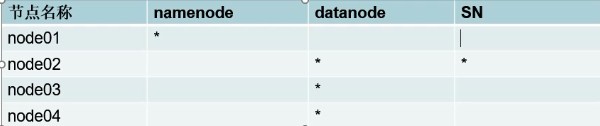
(环境放在/opt下比较方便,其他目录需要自己再修改一次)
1.安装剩余节点jdk环境 scp jdk-7u67-linux-x64.rpm node03:~
2.复制node01的profile文件到其他节点,scp /etc/profile node02:/etc/
3.分发node01的公钥,[root@node01 .ssh]# scp id_dsa.pub node02:`pwd`/node01.pub
4.ssh node02进行校验,ssh下一个连接时需先exit退出旧的会话
5.cd $HADOOP_HOME 直接进入Hadoop目录(重启时务必再加载/etc/profile,
否则进入etc目录无法看到hadoop目录) /root/hadoopEnv/hadoop-2.6.5/etc/hadoop
6.cp -r hadoop/ hadoop-local 拷贝生成分布式使用的版本
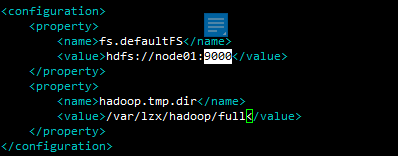
7.修改core-site.xml
修改hdfs-site.xml,由node02启动secondNameNode,设置两个副本
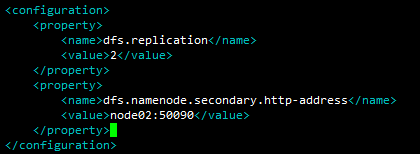
修改namenode配置
8.分发配置好的文件到2、3、4节点:
scp -r ./hadoop-2.6.5 node02:/root/hadoopEnv/
scp -r ./hadoop-2.6.5 node03:/root/hadoopEnv/
scp -r ./hadoop-2.6.5 node04:/root/hadoopEnv/
9.对2、3、4节点重新加载环境 . /etc/profile
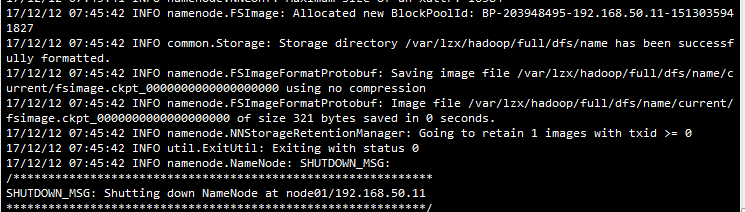
10.格式化新的文件系统:hdfs namenode -format,出现如下截图即为成功
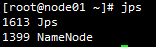
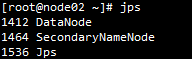
11.启动hadoop:start-dfs.sh,出现如下截图即为启动完成

12.启动完成后可看到角色分布
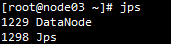
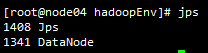
网页上查看:http://node01:50070/
var目录下也可查看角色:




13.在hdfs文件系统中创建目录进行调试:hdfs dfs -mkdir -p /user/root (相当于home目录)
创建文件会不会上传时被损坏:for i in `seq 100000`;do echo "hello hadoop $i" >> test.txt;done (1.9M)
hdfs dfs -D dfs.blocksize=1048576 -put ./test.txt /user/root =1048576
dfs.blocksize为hdfs文件系统属性 1048576为1M (/user/root可省略)
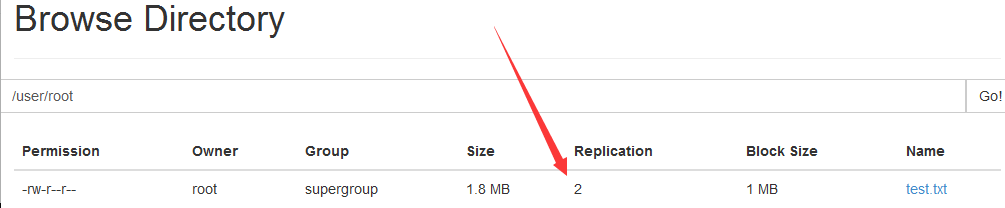
14.查看node04块的位置,块就是对文件的切割后原封不动保存

15.HA:同一功能,纵向多台集群,防止单点故障
Fedearation:多节点水平NN
posted on 2018-03-06 18:15 xiaojiayu0011 阅读(136) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号