四月分享
前端导出:转换为blob导出
后端导出
一.基本知识
1.OLE2和OOXML
OLE2 和 OOXML 本质上都是一种文件格式规范或标准,平时看到的 excel 中,有字体、公式、颜色、图片等等,看起来非常复杂,但是在文件结构上都遵循着固定的格式。
OLE2 文件一般包括 xls、doc、ppt 等,是二进制格式的文件。
OOXML文件一般包括 xlsx、docx、pptx 等。该类文件以指定格式的 xml 为基础并以 zip 格式压缩,
利用解压工具解压一个 xlsx 文件,可以看到以下文件结构,我们会重点关注 sharedStrings.xml 和 sheet1.xml 的内容,因为使用 SAX API 时必须用到:
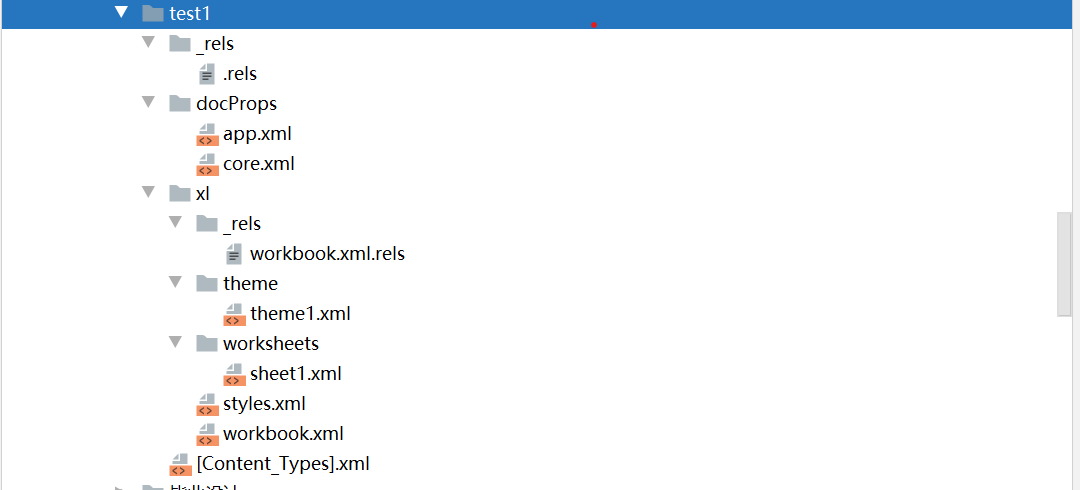
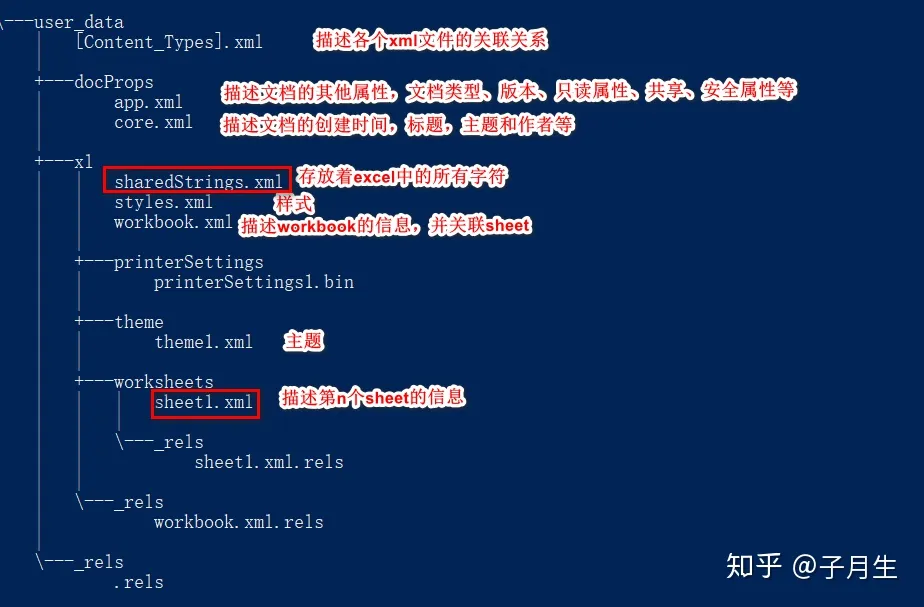
xlx,xlsx区别:
| XLS | XLSX |
|---|---|
| 只能打开xls格式,无法直接打开xlsx格式 | 可以直接打开xls、xlsx格式 |
| 只有65536行、256列 | 可以有1048576行、16384列 |
| 占用空间大 | 占用空间小,运算速度也会快一点 |
2.Java解析XML
Java库中提供了两种XML解析器:
- 像文档对象模型(Document Object Model,DOM)解析器这的树型解析器(tree parse),它们将读入的XML文档转换成树结构。
DOM是基于属性结构的XML解析方式,会将整个XML文档读入内存并构建一个DOM树,基于这棵树型结构对各个节点进行操作。XML文档中每个成分都是一个节点,整个文档是一个文档节点,每个XML标签对应一个元素节点,包含在XML标签中的文本是文本节点,每一个XML属性是一个属性节点,注释属于注释节点。
DOM树所提供的随机访问方式很灵活方便,可以任意地控制整个XML文档中的内容,但是DOM分析器把整个XML文件转化为DOM树放到了内存中,即在处理过程中整个文档都表示在内存中。当文档比较大或者结构比较复杂时,对内存需求比较高
SAX(simple API for XML)是一种XML解析的替代方法。相比于DOM,SAX是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。而且相比于DOM,SAX可以在解析文档的任意时刻停止解析。
3.1SAX解析器在解析XML输入数据的各个组成部分时会报告事件,但不会以任何方式存储文档,而是由事件处理器建立相应的数据结构。实际上DOM解析器是在SAX解析器的基础上构建的,它在接收到解析器事件时构建DOM树。
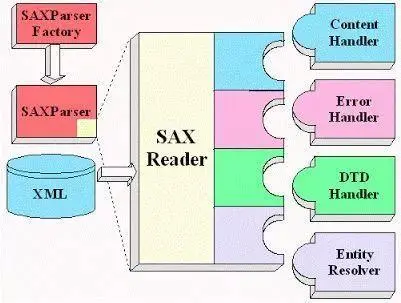
在使用SAX解析器时,需要一个处理器来为各种解析器事件定义事件动作。DefaultHandler接口定义了若干个在解析文档时解析器会调用的回调方法。下面是最重要的几个方法:
- startElement和endElement在每当遇到起始或终止标签时调用。
- characters在每当遇到字符数据时调用。
- startDocument和endDocument分别在文档开始和结束时各调用一次。
例如,在解析以下片段时:
<person> <name type="string">test1</name> <age>99</age> </person>
解析器会产生以下回调:
1)startElement,元素名:person
2)startElement,元素名:name ,属性:type="string"
3)characters,内容:test1
4)endElement,元素名:name
5)startElement,元素名:age
6)characters,内容:99
7)endElement,元素名:age
8)endElement,元素名:person
处理器必须覆盖这些方法,让它们执行在解析文件时我们想让它们执行的动作。
3.2.SAX解析XML的demo
3.2.1.准备xml
<?xml version="1.0" encoding="UTF-8" ?> <persons> <person> <name>test1</name> <age>99</age> </person> <person> <name>test2</name> <age>100</age> </person> </persons>
3.2.2.解析代码
- 获取解析工厂
- 从解析工厂获取解析器
- 得到解读器
- 设置内容处理器
- 读取xml的文档内容
`package com.alibaba.easyexcel.test.demo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.IOException;
/**
-
SAX方式解析xml文件
*/
public class SaxTest {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// SAX解析
// 1.获取解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.从解析工厂获取解析器
SAXParser parse = factory.newSAXParser();
// 3.得到解读器
XMLReader reader=parse.getXMLReader();
// 4.设置内容处理器
reader.setContentHandler(new PHandler());
// 5.读取xml的文档内容
reader.parse("D:\study\aboutWork\easyexcel\easyexcel\easyexcel-test\src\test\java\com\alibaba\easyexcel\test\demo\person.xml");}
}
class PHandler extends DefaultHandler {
/**
* @author lastwhisper
* @desc 文档解析开始时调用,该方法只会调用一次
* @param
* @return void
*/
@Override
public void startDocument() throws SAXException {
System.out.println("----解析文档开始----");
}
/**
* @desc 每当遇到起始标签时调用
* @param uri xml文档的命名空间
* @param localName 标签的名字
* @param qName 带命名空间的标签的名字
* @param attributes 标签的属性集
* @return void
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("标签<"+qName + ">解析开始");
}
/**
* @desc 解析标签内的内容的时候调用
* @param ch 当前读取到的TextNode(文本节点)的字节数组
* @param start 字节开始的位置,为0则读取全部
* @param length 当前TextNode的长度
* @return void
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String contents = new String(ch, start, length).trim();
if (contents.length() > 0) {
System.out.println("内容为-->" + contents);
} else {
System.out.println("内容为-->" + "空");
}
}
/**
* @desc 每当遇到结束标签时调用
* @param uri xml文档的命名空间
* @param localName 标签的名字
* @param qName 带命名空间的标签的名字
* @return void
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("标签</"+qName + ">解析结束");
}
/**
* @desc 文档解析结束后调用,该方法只会调用一次
* @param
* @return void
*/
@Override
public void endDocument() throws SAXException {
System.out.println("----解析文档结束----");
}
}
运行结果:   3.2.3.xml转换为pojopackage com.alibaba.easyexcel.test.demo;
import com.alibaba.easyexcel.test.Person;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
*
- @desc 将xml数据解析到pojo中
*/
public class SaxTest {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// SAX解析
// 1.获取解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.从解析工厂获取解析器
SAXParser parse = factory.newSAXParser();
// 3.得到解读器
XMLReader reader = parse.getXMLReader();
// 4.设置内容处理器
PersonHandler personHandler = new PersonHandler();
reader.setContentHandler(personHandler);
// 5.读取xml的文档内容
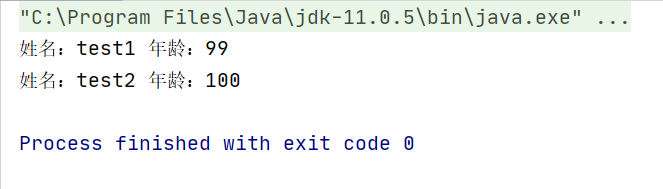
reader.parse("D:\study\aboutWork\easyexcel\easyexcel\easyexcel-test\src\test\java\com\alibaba\easyexcel\test\demo\person.xml");
List<Person> persons = personHandler.getPersons();
for (Person person : persons) {
System.out.println("姓名:" + person.getName() + " 年龄:" + person.getAge());
}
}
}
class PersonHandler extends DefaultHandler {
private List
private Person person;
private String tag; // 存储操作标签
/**
*
* @desc 文档解析开始时调用,该方法只会调用一次
* @param
* @return void
*/
@Override
public void startDocument() throws SAXException {
persons = new ArrayList<Person>();
}
/**
*
* @desc 标签(节点)解析开始时调用
* @param uri xml文档的命名空间
* @param localName 标签的名字
* @param qName 带命名空间的标签的名字
* @param attributes 标签的属性集
* @return void
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
tag = qName;
if ("person".equals(tag)) {
person = new Person();
}
}
/**
*
* @desc 解析标签的内容的时候调用
* @param ch 字符
* @param start 字符数组中的起始位置
* @param length 要从字符数组使用的字符数
* @return void
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String contents = new String(ch, start, length).trim();
if ("name".equals(tag)) {
person.setName(contents);
} else if ("age".equals(tag)) {
if (contents.length() > 0) {
person.setAge(Integer.valueOf(contents));
}
}
}
/**
*
* @desc 标签(节点)解析结束后调用
* @param uri xml文档的命名空间
* @param localName 标签的名字
* @param qName 带命名空间的标签的名字
* @return void
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("person".equals(qName)) {
persons.add(person);
}
tag = null; //tag丢弃了
}
/**
*
* @desc 文档解析结束后调用,该方法只会调用一次
* @param
* @return void
*/
@Override
public void endDocument() throws SAXException {
}
public List<Person> getPersons() {
return persons;
}
}
`
运行结果:
sax和dom的区别
二.Apache POI
1.Apache POI 是用Java编写的免费开源的跨平台的 Java API,
POI为“Poor Obfuscation Implementation”的首字母缩写,意为“简洁版的模糊实现”。Apache POI是基于 OOXML 标准(Office Open XML)和 OLE2 标准来读写各种格式文件,也就是说只要是遵循以上标准的文件,POI 都能够进行读写,而不仅仅只能操作我们熟知的办公程序文件。
2.处理组件:
HSSF - 提供读写Microsoft Excel XLS格式档案的功能。
XSSF - 提供读写Microsoft Excel OOXML XLSX格式档案的功能。
SXSSF - 处理超大的*xlsx 文件
HWPF - 提供读写Microsoft Word DOC97格式档案的功能。
XWPF - 提供读写Microsoft Word DOC2003格式档案的功能。
HSLF - 提供读写Microsoft PowerPoint格式档案的功能。
HDGF - 提供读Microsoft Visio格式档案的功能。
HPBF - 提供读Microsoft Publisher格式档案的功能。
HSMF - 提供读Microsoft Outlook格式档案的功能。
3.POI对Excel中的对象的封装对应关系如下:
| Excel | POI XLS | POI XLSX(Excel 2007+) |
|---|---|---|
| Excel 文件 | HSSFWorkbook (xls) | XSSFWorkbook(xlsx) |
| Excel 工作表 | HSSFSheet | XSSFSheet |
| Excel 行 | HSSFRow | XSSFRow |
| Excel 单元格 | HSSFCell | XSSFCell |
| Excel 单元格样式 | HSSFCellStyle | HSSFCellStyle |
| Excel 颜色 | HSSFColor | XSSFColor |
| Excel 字体 | HSSFFont | XSSFFont |
4.POI 面向接口的设计非常巧妙,使用 ss.usermodel 包读写 xls 和 xlsx 时,可以使用同一套代码,即使这两种文件格式采用的是完全不同的标准。POI 提供了SXSSFWorkbook用于解决 xlsx 写大文件时容易出现的 OOM 问题。但是,还是存在以下不足(都只针对读场景):
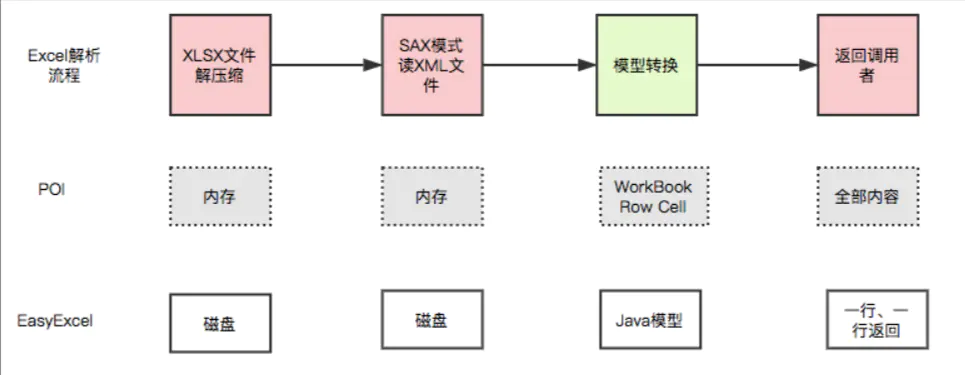
使用 ss.usermodel 包解析 excel 效率较低、内存占用较大,且容易出现 OOM。类似于 xml 中的 DOM,这种方式会在内存中构建整个文档的结构,在处理大文件时容易出现 OOM。然而,大部分场景我们并不需要随机地去访问 excel 中的节点。
POI 提供的 SAX 解析可以解决第一个问题,但是 API 太过复杂。为了解决第一个问题,POI 提供了基于事件驱动的 SAX 方式,这种方式内存占用小、效率高, 但是 API 太过繁琐,开发者必须在熟知文档规范的前提下才能使用,而且 xls 和 xlsx 使用的是完全不同的两套 API,实际项目中必须针对不同文件类型分别实现。这一点可以从本文的例子看出来。
针对以上问题,阿里的 easyexcel 对 POI 进行高级封装,提供了一套非常简便的 API,其中,读部分只封装了 SAX 部分 API,事实上,使用 easyexcel 读 excel 只会采用 SAX 方式,另外,easyexcel 重写了 POI 对 xlsx 的解析,能够原本一个3M的 excel 用 POI SAX 依然需要100M左右内存降低到几M,easyexcel 的内容本文也会涉及到。
三.EasyExcel
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
Java领域解析,生成Excel比较有名的框架有Apache poi,jxl等,但他们都存在一个严重的问题就是非常的耗内存,如果你的系统并发量不大的话可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的full gc.
EasyExcel是阿里巴巴开源的一个excel处理框架,以使用简单,节省内存著称,EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理(AnalysisEventListener)。
————————————————
版权声明:本文为CSDN博主「闲言博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42025798/article/details/122361631
作者:YuShiwen
链接:https://juejin.cn/post/7090716023636115470
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:最后的轻语_dd43
链接:https://www.jianshu.com/p/8df626ea70ed
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
————————————————
版权声明:本文为CSDN博主「风流 少年」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/vbirdbest/article/details/72870714

 浙公网安备 33010602011771号
浙公网安备 33010602011771号