

数据采集与融合技术综合实践报告
| 这个项目属于哪个课程 | 2025综合设计——多源异构数据采集与融合应用综合实践 |
|---|---|
| 组名、项目简介 | 组名:汪汪功立大队 项目需求:随着个性化旅游需求的爆发式增长,传统碎片化的信息获取与行程管理方式已无法满足用户对效率与深度的双重追求。同时,旅行结束后的数据资产(如足迹、消费、情感记忆)往往散落在不同平台,缺乏系统的沉淀与分析。 项目目标:构建一个集智能规划、实时地图联动、全生命周期旅行记录与多维数据洞察于一体的 Web 应用平台。 项目开展技术路线: 数据采集层:高德地图API实时地理数据获取 + 旅游信息采集 + AI清洗去重 数据存储层:SQLite/PostgreSQL关系型数据库 + Redis缓存机制 + 结构化行程数据建模 后端逻辑层:Python FastAPI异步框架 + 阿里云Qwen大模型Agent + Pydantic数据验证 算法层:高德地图多模式路线规划API + 旅行人格DNA量化算法 + 经济学模型分析 前端交互层:React 18数据流UI + 高德地图交互式组件 + 生态流光可视化仪表盘 |
| 团队成员学号 | 102302132(组长),102302133,102302134,102302135,102302137,102302145,102302107 |
| 这个项目目标 | 本项目旨在打造一款全生命周期的智能旅行助手,实现以下目标: 1. 智能规划:利用 LLM 实现“一句话生成可执行路书”。 2. 地图联动:实现对话与地图的实时双向交互,所见即所得。 3. 资产沉淀:提供完善的旅行记录功能,覆盖从计划到完成的全过程。 4. 深度分析:通过可视化数据看板,为用户提供上帝视角的旅行行为分析报告。 |
在本次智能旅行规划系统的开发中,我承担了系统架构设计与核心功能实现的双重角色。我主导设计了以大模型为智能中枢、地图服务为空间支撑、RAG系统为知识增强的三层融合架构,实现了以下核心功能:
1.大模型智能中枢:通过llm_engine.py构建了具备多轮对话和工具调用能力的AI决策引擎
2.地图服务封装:在MapService类中完整封装了高德地图API的多项核心功能
3.RAG知识增强:搭建了从文本处理到向量检索的完整知识增强系统
一、大模型应用架构分析
1.1 llm_engine.py:智能中枢与规划生成引擎
这是系统的智能中枢,实现了大模型的核心应用逻辑。其主要功能包括:第一,通过 call_qwen_with_tools函数集成通义千问大模型,具备多轮对话能力,并创新性地实现了“函数调用”机制,通过预定义的 TOOLS_SCHEMA让大模型能够智能判断并调度外部工具(如地图搜索、知识查询)。第二,通过 generate_full_plan函数,专门用于处理复杂的旅行规划生成任务,它使用更强大的 qwen-max模型,并构建专业的系统提示词,将用户的多维度需求转化为结构完整、格式规范的Markdown旅行攻略文档。
import dashscope
from http import HTTPStatus
# 大模型调用核心函数
async def call_qwen_with_tools(messages, api_config={}):
"""调用通义千问模型,支持工具调用"""
if api_config and api_config.get("dashscope_key"):
dashscope.api_key = api_config["dashscope_key"]
# 工具定义
TOOLS_SCHEMA = [
{
"type": "function",
"function": {
"name": "search_poi",
"description": "搜索特定地点、景点或位置",
# ... 参数定义
}
},
# ... 其他工具
]
# 调用大模型
response = dashscope.Generation.call(
model='qwen-turbo', # 使用 turbo 模型降低成本
messages=messages,
tools=TOOLS_SCHEMA,
result_format='message',
)
# 处理工具调用和响应
if response.status_code == HTTPStatus.OK:
output = response.output.choices[0].message
# ... 工具执行和二次调用逻辑
async def generate_full_plan(origin, destination, days, people, preferences, budget, transport, pace, who_with, tags, api_config):
"""生成全面的旅行计划文档"""
dashscope.api_key = "sk-6c96e1a36e9a4f00ad691535210d7e0e"
# 构建系统提示
system_prompt = f"""你是一位金牌旅游规划师。请根据以下详细信息生成旅游攻略..."""
response = dashscope.Generation.call(
model='qwen-max', # 使用 max 模型获得更好效果
messages=messages,
result_format='message',
)
1.2 real_ai.py:大模型API网关服务
这实现了一个独立、专注的大模型API网关微服务。其核心功能是提供 call_dashscope_api函数,专门负责与阿里云DashScope API的后端通信细节。它封装了HTTP请求的构建、认证头部的添加、生成参数(如 temperature、top_p)的设置、超时控制以及响应解析等底层复杂性,为系统其他部分提供一个简单、可靠、专注于完成文本生成任务的工具函数,确保了核心AI服务的稳定性和可用性。
def call_dashscope_api(message: str, api_key: str, history: List[Message] = None) -> str:
"""调用阿里云DashScope API"""
data = {
"model": "qwen-turbo",
"input": {"messages": messages},
"parameters": {
"temperature": 0.8,
"top_p": 0.8,
"max_tokens": 2000
}
}
response = requests.post(
"https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation",
headers={"Authorization": f"Bearer {api_key}"},
json=data,
timeout=30
)
1.3实现的有关功能运作如下:
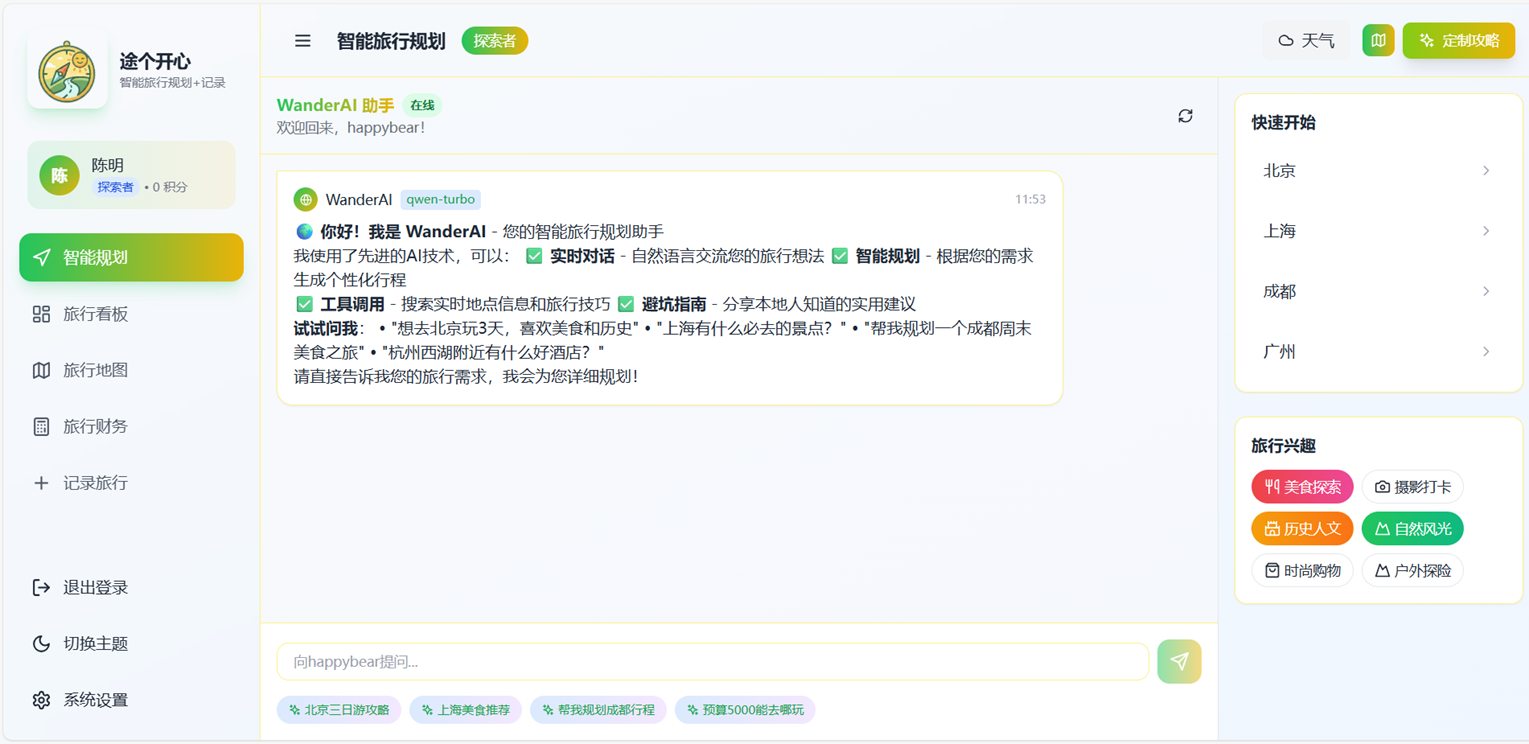
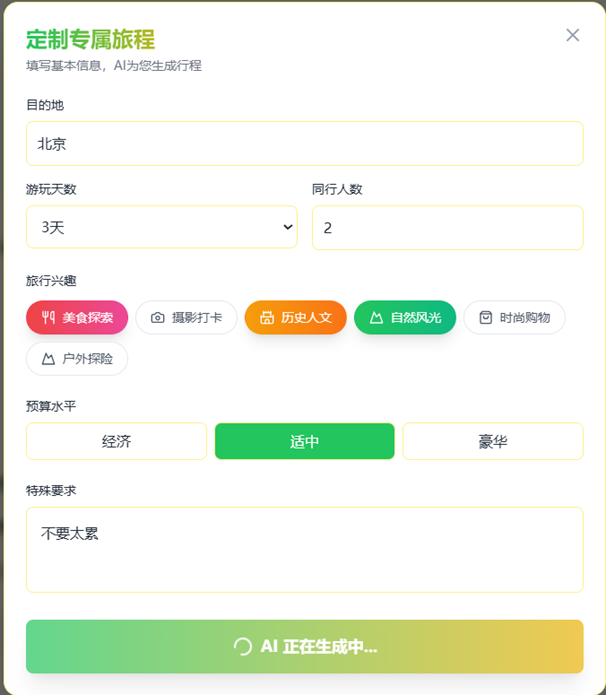

二、地图服务集成实现
2.1 main.py中MapService类:地理空间服务核心
这是系统的地理空间服务核心,完整封装了高德地图API的功能。它通过 MapService类提供了一整套地理位置服务:geocode方法实现地址到坐标的解析;search_places方法提供关键词地点搜索;calculate_route方法支持包括驾车、步行、公交、火车乃至飞机在内的多模式路线规划;get_weather方法则提供目的地天气查询。这些方法为整个系统提供了准确、实时的空间数据支撑。
class MapService:
def __init__(self):
self.AMAP_WEB_KEY = "2f7e7f522142f058bd513ad4b102fecc"
self.BASE_URL = "https://restapi.amap.com/v3"
def geocode(self, address: str):
"""地址转坐标 + 获取城市编码"""
url = f"{self.BASE_URL}/geocode/geo"
params = {"key": self.AMAP_WEB_KEY, "address": address}
res = requests.get(url, params=params).json()
def search_places(self, keyword: str, city: str = "全国"):
"""搜索地点"""
url = f"{self.BASE_URL}/place/text"
params = {
"key": self.AMAP_WEB_KEY, "keywords": keyword, "city": city,
"offset": 20, "page": 1, "extensions": "all"
}
def calculate_route(self, origin_str: str, dest_str: str, mode: str = "driving"):
"""路线规划"""
# 支持多种交通方式:driving, walking, bicycling, bus, train, plane
if mode == "plane":
return self.calculate_plane_route(origin_loc, dest_loc)
elif mode == "walking":
url = f"{self.BASE_URL}/direction/walking"
# ... 其他交通方式
def get_weather(self, city_code: str):
"""获取天气信息"""
url_live = f"{self.BASE_URL}/weather/weatherInfo"
params_live = {"key": self.AMAP_WEB_KEY, "city": city_code, "extensions": "base"}
2.2 llm_engine.py中的地图工具集成:智能意图转换器
该部分代码实现了大模型与地图服务的无缝衔接。其功能是在大模型的工具调用框架内,作为具体执行器。当大模型决定调用 search_poi或 search_nearby工具时,这段代码负责接收指令,将高德地图API密钥注入请求参数,并调用相应的地图搜索函数,最终将搜索结果返回给大模型进行总结和回复。它扮演了“翻译官”和“调度员”的角色,将大模型的意图转化为具体的地图API调用。
# 在工具调用中集成地图API
if func_name == 'search_poi':
if amap_key:
function_args['api_key'] = amap_key
result = await search_poi(**function_args)
elif func_name == 'search_nearby':
if amap_key:
function_args['api_key'] = amap_key
result = await search_nearby(**function_args)
2.3 实现的有关功能运作如下:
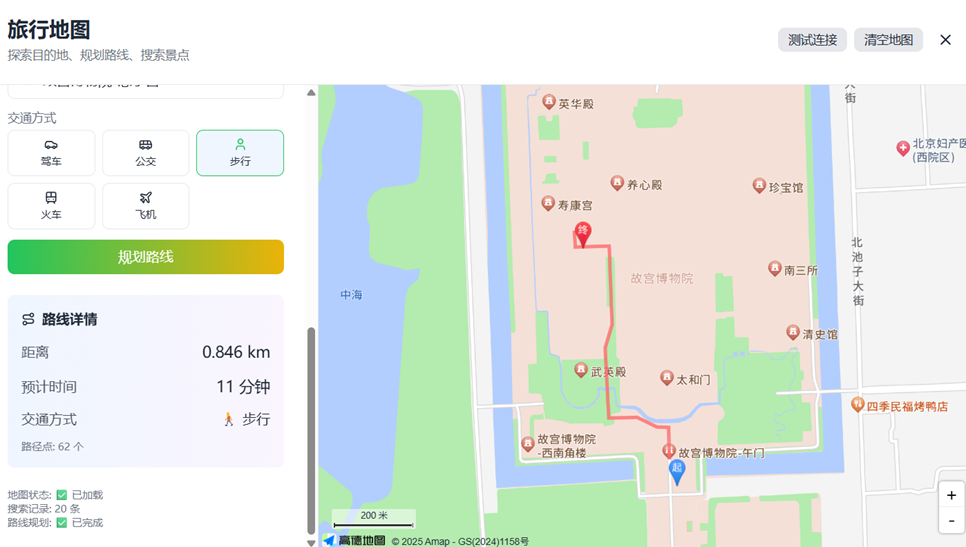
三、RAG知识增强系统设计
3.1 rag_engine.py:检索增强生成全流程实现
该文档独立构建了系统的检索增强生成(RAG)全流程。其核心功能分为三部分:第一,使用ChromaDB创建本地持久化的向量数据库,并定义 DashScopeEmbedding类利用嵌入模型将文本转换为向量。第二,通过 ingest_knowledge_base函数实现知识库的构建,能够读取文本文件、分割成块并导入向量数据库。第三,提供 search_knowledge函数,实现基于语义相似度的知识检索,能够根据用户查询从知识库中快速找到最相关的信息片段。
import chromadb
from chromadb import Documents, EmbeddingFunction, Embeddings
class DashScopeEmbedding(EmbeddingFunction):
def __call__(self, input: Documents) -> Embeddings:
"""使用DashScope的嵌入模型"""
resp = dashscope.TextEmbedding.call(
model="text-embedding-v1",
input=text
)
# 创建向量数据库
chroma_client = chromadb.PersistentClient(path="./chroma_db")
collection = chroma_client.get_or_create_collection(
name="travel_knowledge",
embedding_function=SimpleEmbedding()
)
def search_knowledge(query: str, n_results: int = 3):
"""在知识库中进行语义搜索"""
results = collection.query(
query_texts=[query],
n_results=n_results
)
return results.get('documents', [[]])[0]
def ingest_knowledge_base(file_path: str):
"""导入知识库到向量数据库"""
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 分割文档
chunks = [c.strip() for c in text.split('\n\n') if c.strip()]
collection.upsert(
documents=chunks,
ids=[f"doc_{i}" for i in range(len(chunks))],
metadatas=[{"source": file_path} for _ in chunks]
)
3.2 llm_engine.py中的RAG集成:双模式知识应用策略
该部分代码负责将RAG能力融入系统工作流。其功能体现在两个层面:一是在生成旅行计划(generate_full_plan)时,主动调用RAG接口获取目的地的独家知识(如避坑指南),并将其作为上下文增强提示词,从而提升生成内容的质量和专业性。二是在大模型的工具列表(TOOLS_SCHEMA)中注册 search_knowledge_base工具,使得大模型在对话过程中能够根据用户问题,主动检索知识库来获取事实依据,确保回复的准确性。
# 在行程生成中集成RAG
rag_context = ""
try:
rag_docs = search_knowledge(f"{destination} 旅游 攻略 避坑")
if rag_docs:
rag_context = "\n\n**参考的独家知识库信息**:\n" + "\n".join([f"- {doc[:200]}..." for doc in rag_docs])
except Exception as e:
print(f"RAG 搜索失败: {e}")
# 在工具中集成RAG搜索
{
"type": "function",
"function": {
"name": "search_knowledge_base",
"description": "搜索独家旅行技巧、避坑指南、隐藏景点等",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "语义搜索查询"}
},
"required": ["query"]
}
}
}
四、心得体会
通过本次项目,我获得了大模型应用架构设计的完整实战经验。最大的收获是理解了如何将AI的"智能"转化为可落地的解决方案——不是单纯追求模型的复杂程度,而是精心设计工具调用机制和数据流转管道,让大模型能够按需调动地图服务的实时数据和知识库的专业内容,最终形成"智能决策-数据支撑-知识增强"的协同工作流。这让我深刻认识到,优秀的大模型应用架构,本质上是不同技术能力的有序编排。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号