
第四次作业
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……
Gitee文件夹链接:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业4/1.py
1.核心代码
为获取到不同板块的股票信息,首先对页面进行检查,观察到我们需要找到其板块对应的a标签并用selenium模拟鼠标动作对其进行点击以获取对应板块的股票数据。
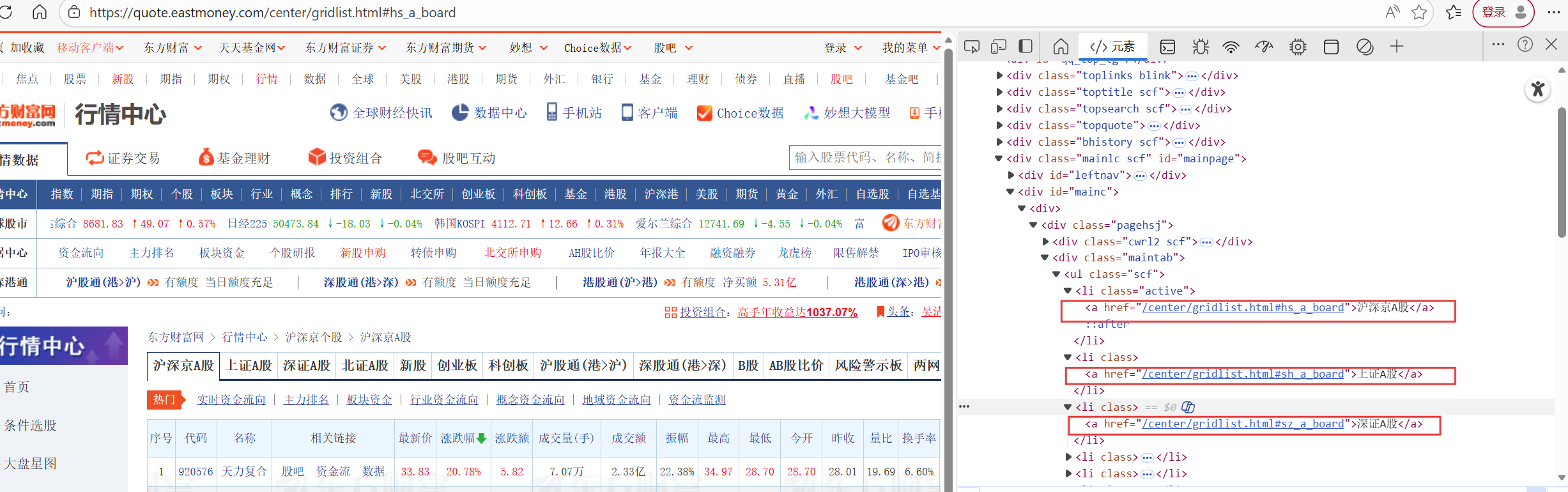
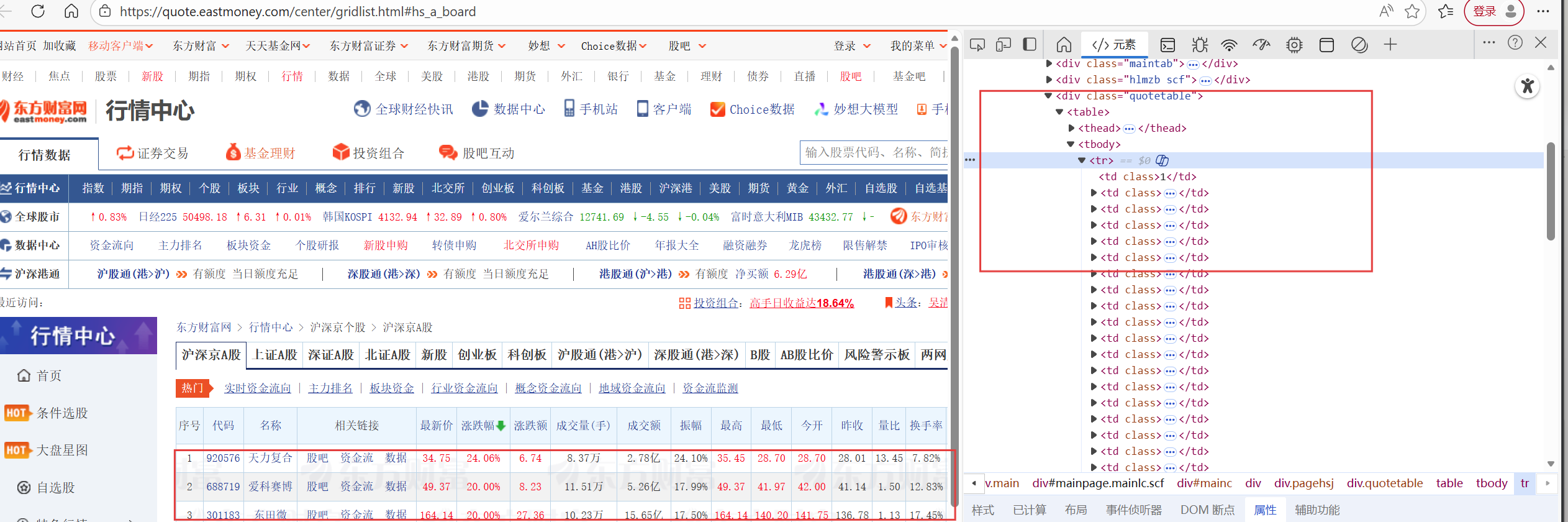
只要能找到不同板块的股票信息,接下来对其爬取就不难了,找到该板块下各个股票所在的tr标签的位置,在分别对tr标签里面的各个具有对应信息的td标签里的数据对应爬取即可,这里要注意的是第三个td中不是我们需要的数据。
首先初始化数据库
def initialize():
"""初始化数据库,创建股票数据表结构"""
con = sqlite3.connect("stocks.db")
cursor = con.cursor()
try:
# 尝试创建新表,包含13个股票数据字段
cursor.execute(
"create table stock (id varchar(16),code varchar(16),name varchar(16),price varchar(16),change_percent varchar(16),change_amount varchar(16),volume varchar(16),turnover varchar(16),amp varchar(16),m varchar(16),n varchar(16),today varchar(16),yesterday varchar(16))")
except:
# 如果表已存在,先删除再重新创建
cursor.execute("drop table if exists stock")
cursor.execute(
"create table stock (id varchar(16),code varchar(16),name varchar(16),price varchar(16),change_percent varchar(16),change_amount varchar(16),volume varchar(16),turnover varchar(16),amp varchar(16),m varchar(16),n varchar(16),today varchar(16),yesterday varchar(16))")
这是主要的爬虫函数,对对应的股票板块的股票信息进行爬取,同时我定义了一个全局的count变量用于实现爬取3个板块,爬取后将其存储到定义完的数据库中对应的数据表中
def spider(url):
"""爬虫主函数,负责爬取指定URL的股票数据并递归爬取后续板块
Args:
url: 要爬取的网页URL
"""
global count
count += 1 # 板块计数器,用于控制爬取3个板块
# 访问目标网页
driver.get(url)
time.sleep(2) # 等待页面加载
# 定位股票数据表格中的所有行
stocks = driver.find_elements(by=By.XPATH, value="//div[@class='quotetable']/table/tbody/tr")
# 遍历每一行股票数据
for stock in stocks:
a = [] # 存储单只股票的相应字段数据
# 按顺序提取股票数据的各个字段(对应表格中的列位置)
a.append(stock.find_element(by=By.XPATH, value='./td[position()=1]').text) # 序号
a.append(stock.find_element(by=By.XPATH, value='./td[position()=2]').text) # 股票代码
a.append(stock.find_element(by=By.XPATH, value='./td[position()=3]').text) # 股票名称
a.append(stock.find_element(by=By.XPATH, value='./td[position()=5]').text) # 最新报价
a.append(stock.find_element(by=By.XPATH, value='./td[position()=6]').text) # 涨跌幅
a.append(stock.find_element(by=By.XPATH, value='./td[position()=7]').text) # 涨跌额
a.append(stock.find_element(by=By.XPATH, value='./td[position()=8]').text) # 成交量
a.append(stock.find_element(by=By.XPATH, value='./td[position()=9]').text) # 成交额
a.append(stock.find_element(by=By.XPATH, value='./td[position()=10]').text) # 振幅
a.append(stock.find_element(by=By.XPATH, value='./td[position()=11]').text) # 最高
a.append(stock.find_element(by=By.XPATH, value='./td[position()=12]').text) # 最低
a.append(stock.find_element(by=By.XPATH, value='./td[position()=13]').text) # 今开
a.append(stock.find_element(by=By.XPATH, value='./td[position()=14]').text) # 昨收
# 保存股票数据到数据库
savestock(a)
# 递归爬取逻辑:依次爬取3个板块(沪深A股、上证A股、深证A股)
if count == 1:
# 爬取第二个板块:上证A股
href = driver.find_element(by=By.XPATH, value="//ul[@class='scf']/li[position()=2]/a").get_attribute('href')
nexturl = urllib.request.urljoin(url, href) # 构建完整URL
spider(nexturl) # 递归调用爬取下一个板块
if count == 2:
# 爬取第三个板块:深证A股
href = driver.find_element(by=By.XPATH, value="//ul[@class='scf']/li[position()=3]/a").get_attribute('href')
nexturl = urllib.request.urljoin(url, href) # 构建完整URL
spider(nexturl) # 递归调用爬取下一个板块
这是将单条股票数据保存到数据库的函数
def savestock(item):
"""将单条股票数据保存到数据库
Args:
item: 包含13个字段的股票数据列表
"""
con = sqlite3.connect("stocks.db")
cursor = con.cursor()
try:
# 插入股票数据到数据库表,字段顺序与列表索引对应
cursor.execute(
"insert into stock (id,code,name,price,change_percent,change_amount,volume,turnover,amp,n,m,today,yesterday) values(?,?,?,?,?,?,?,?,?,?,?,?,?)",
(item[0], item[1], item[2], item[3], item[4], item[5],
item[6], item[7], item[8], item[9], item[10], item[11], item[12]))
con.commit()
con.close()
except Exception as err:
print(err)
在爬取并存储完数据以后将其写入csv文件进行展示
def write():
"""将数据库中的课股票数据导出到CSV文件"""
con = sqlite3.connect("stocks.db")
cursor = con.cursor()
cursor.execute("select * from stock")
rows = cursor.fetchall()
# CSV文件表头,与数据库字段顺序一致
data=[['id','code','name','price','change_percent','change_amount','volume','turnover','amp','n','m','today','yesterday']]
with open('stocks.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
for row in rows:
data.append(list(row))
writer.writerows(data)
con.commit()
con.close()
2.运行结果
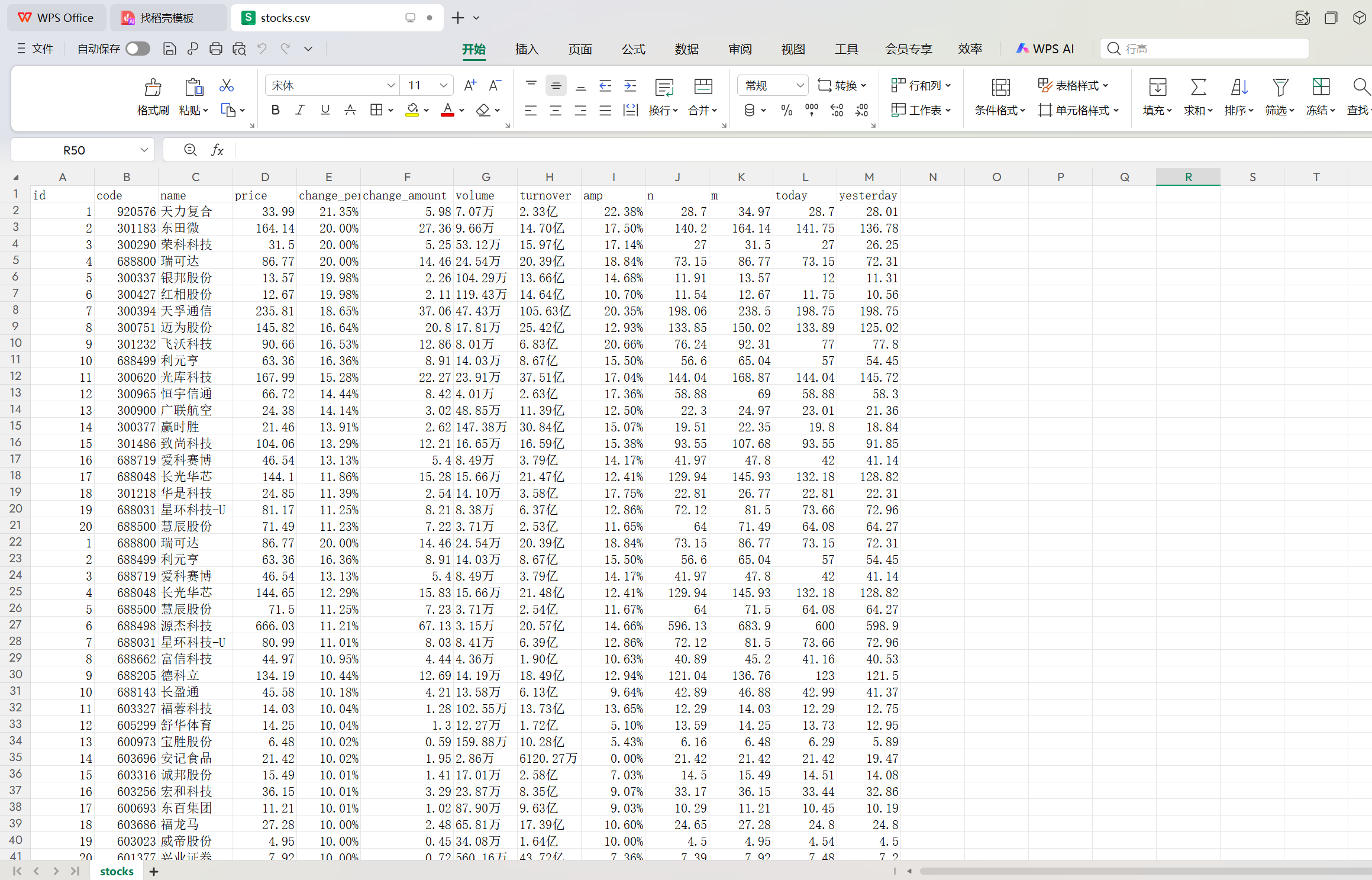
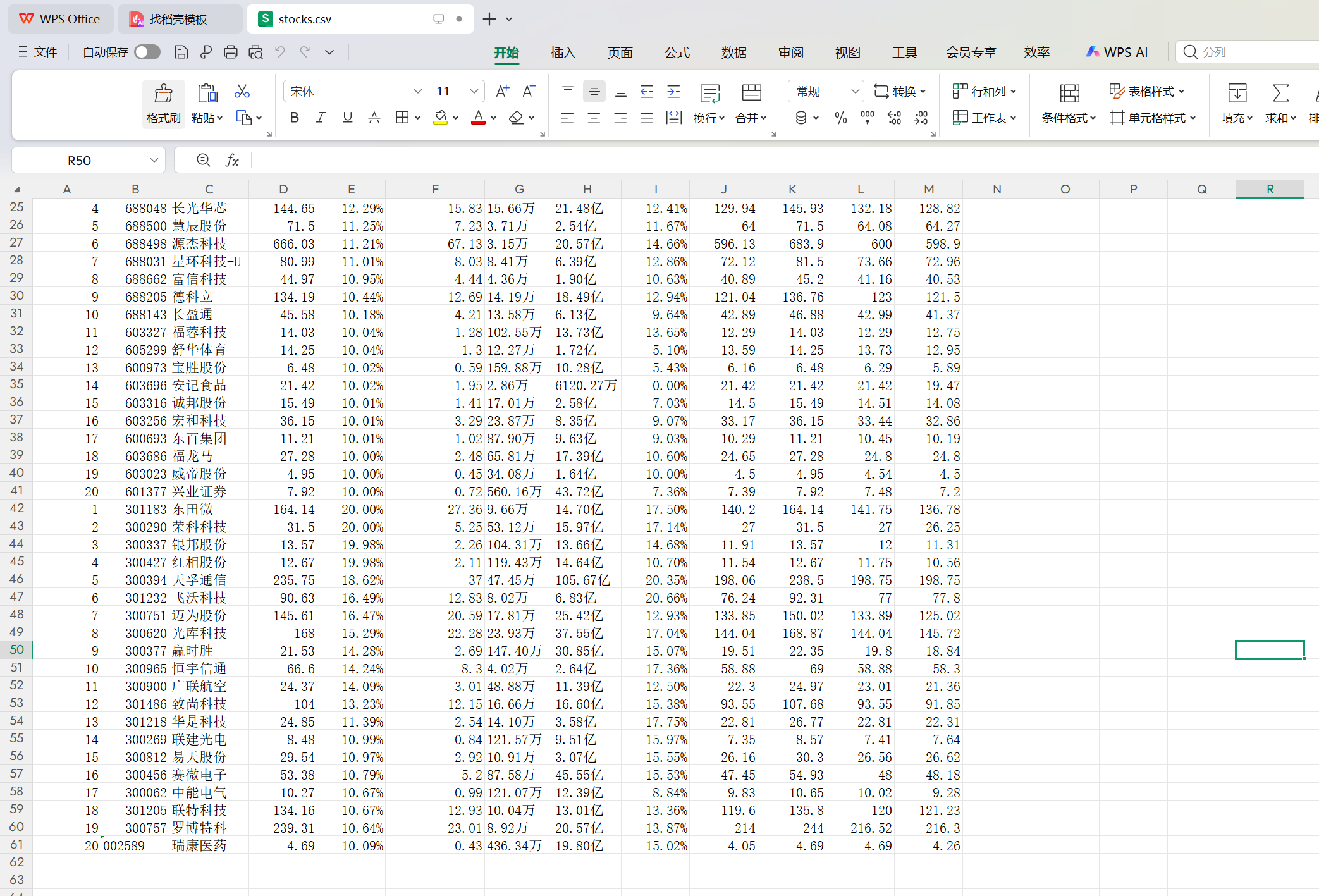
3.心得体会
在本次实验中,通过使用 Selenium 爬取东方财富网的股票数据,我深刻掌握了Selenium在动态网页数据抓取中的部分应用(可以通过模拟浏览器行为和设备动作点击元素标签的方法来爬取更多的信息,不在拘泥于爬取静态的网页源码了),极大地丰富了个人的爬虫方法。整个过程也让我体会到,稳定的爬虫程序不仅依赖于精准的元素定位,更需要对网络延迟、页面结构变动等异常情况具备充分的容错能力。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接:https://gitee.com/linyuars/2025_crawl_project/blob/master/作业4/2.py
1.核心代码
观察网页结构,发现我们首先要找到登录所在的标签并进行点击弹出登录的弹窗
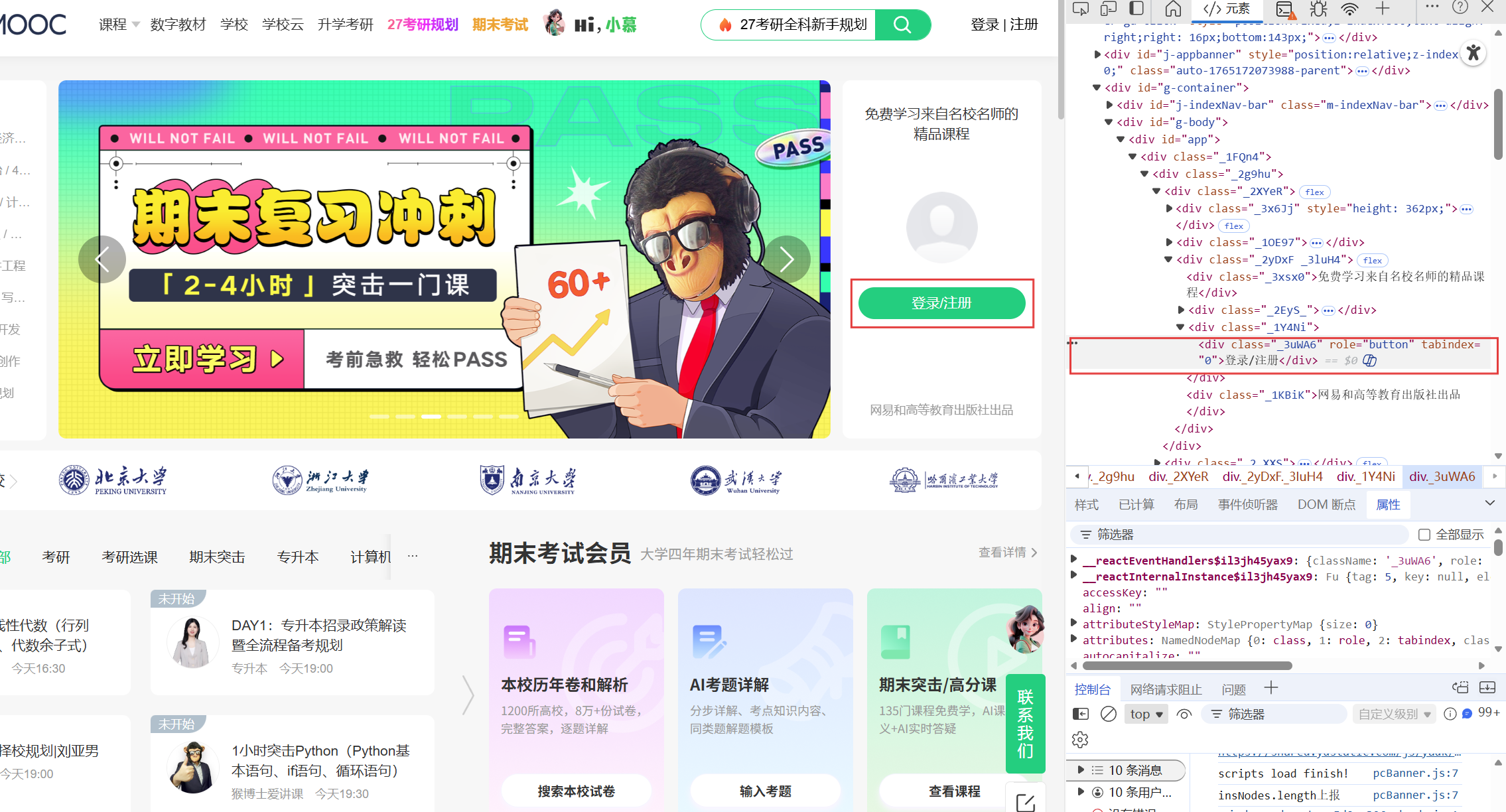
然后我们要分别找到手机号和密码对应输入的input标签进行输入,然后找到登录按钮所对应的标签并点击完成登录。
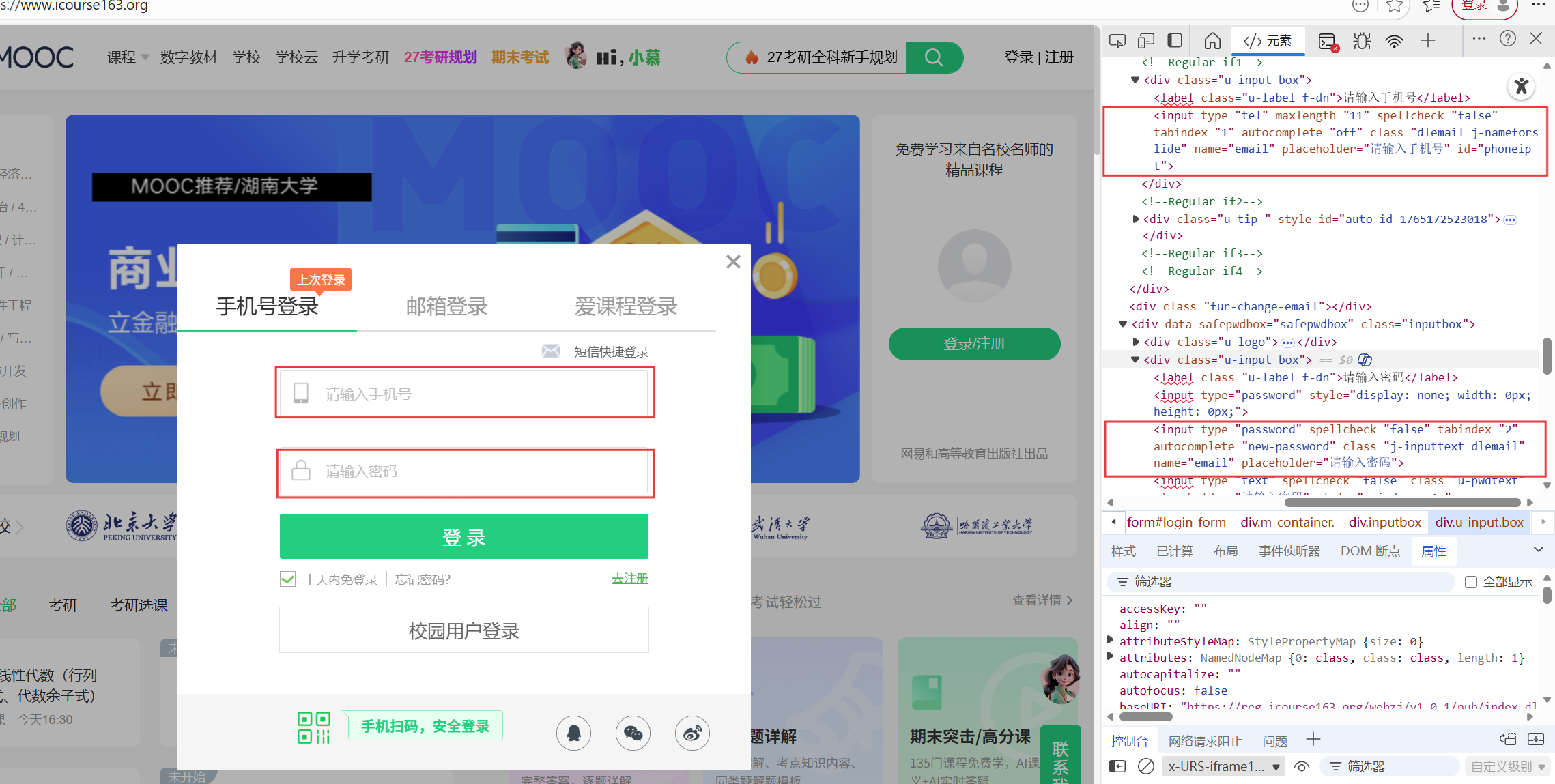
这里要注意的是我们应该先把窗体切换到iframe处(这里我是使用EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, 'iframe')完成该操作的),才能进行输入账号密码,否则是无法进行输入的!
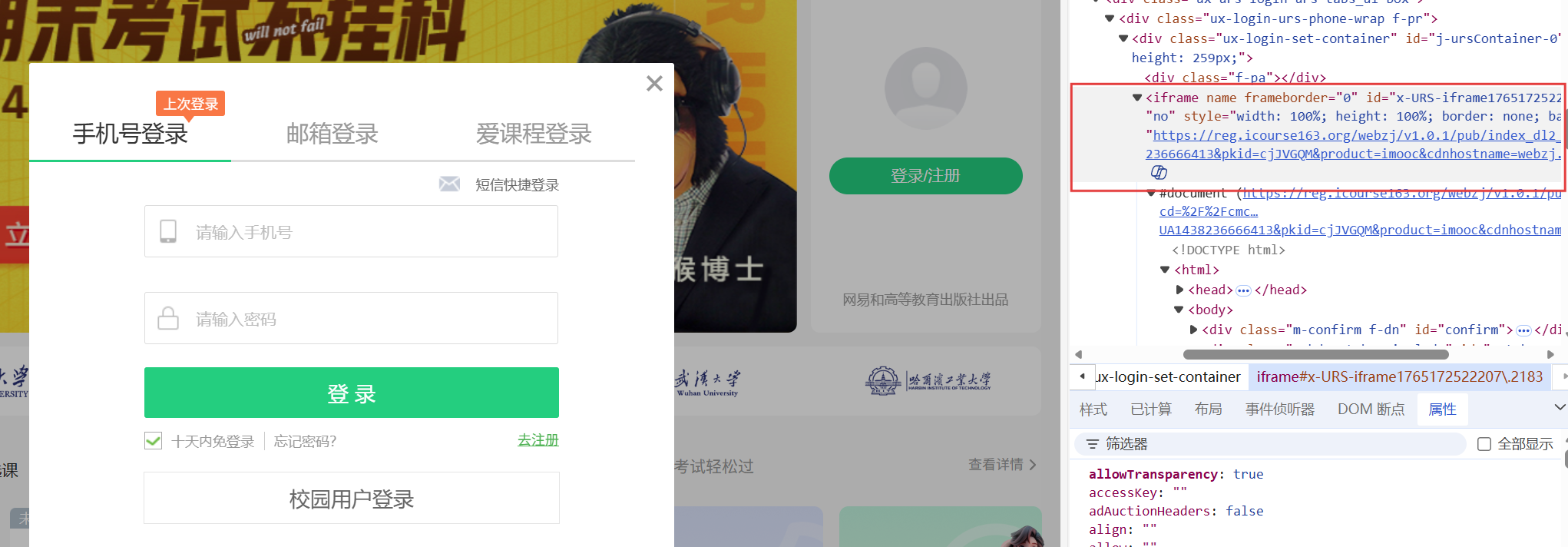
注意使用完还要切回原本的窗体(driver.switch_to.window(driver.window_handles[-1])以便进行接下来的操作
以下是完整的登录函数
def login(url):
"""登录中国大学MOOC网站"""
driver.get(url)
time.sleep(5)
# 点击登录/注册按钮
login_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//div[@class="_3uWA6" and text()="登录/注册"]'))
)
login_button.click()
# 切换到登录iframe
WebDriverWait(driver, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, 'iframe'))
)
# 输入手机号
phone_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'phoneipt'))
)
phone_input.send_keys("手机号")
time.sleep(2)
# 输入密码
driver.find_element(by=By.XPATH, value="//input[@autocomplete='new-password']").send_keys("密码")
time.sleep(2)
# 点击登录按钮
driver.find_element(by=By.XPATH, value="//a[@id='submitBtn']").click()
driver.switch_to.window(driver.window_handles[-1])
# 点击"我的课程"进入课程页面
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//div[@class="_3uWA6" and text()="我的课程"]'))
).click()
driver.switch_to.window(driver.window_handles[-1])
登录成功以后找到我的课程所在的标签,并完成元素的点击操作进入新的界面
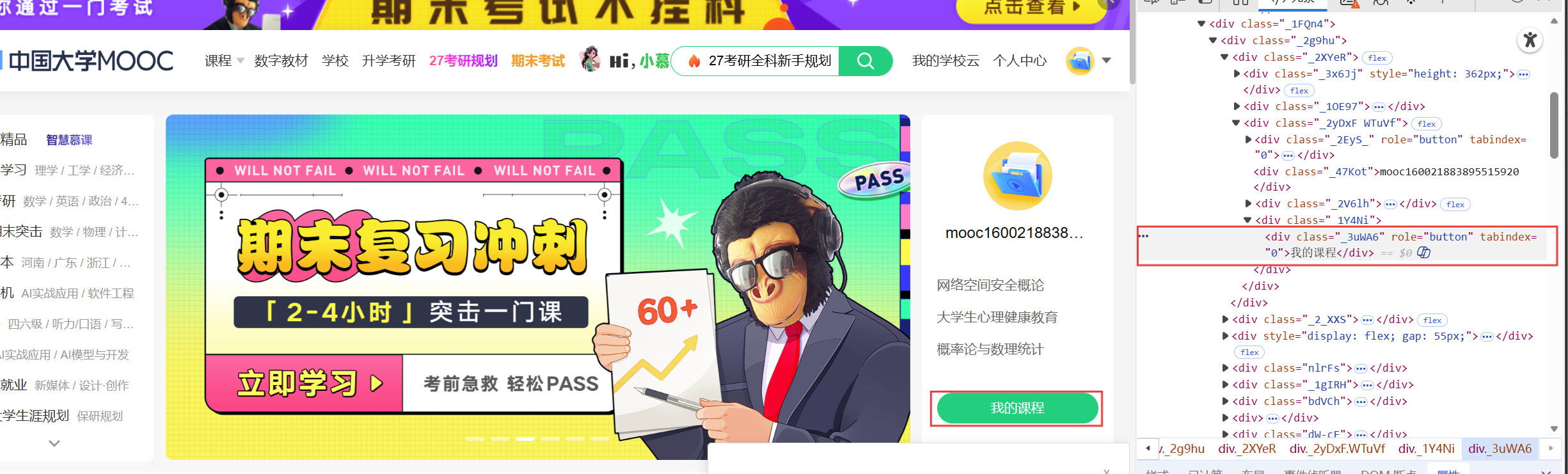
接着为了爬取课程的详细信息,我们要找到课程介绍的链接并点击,观察页面的结构后不难发现将鼠标悬停在class属性值为"menu-btn"的div元素下即可弹出跳转到课程介绍的链接(如果不悬停的话直接找该a标签是无法找到的
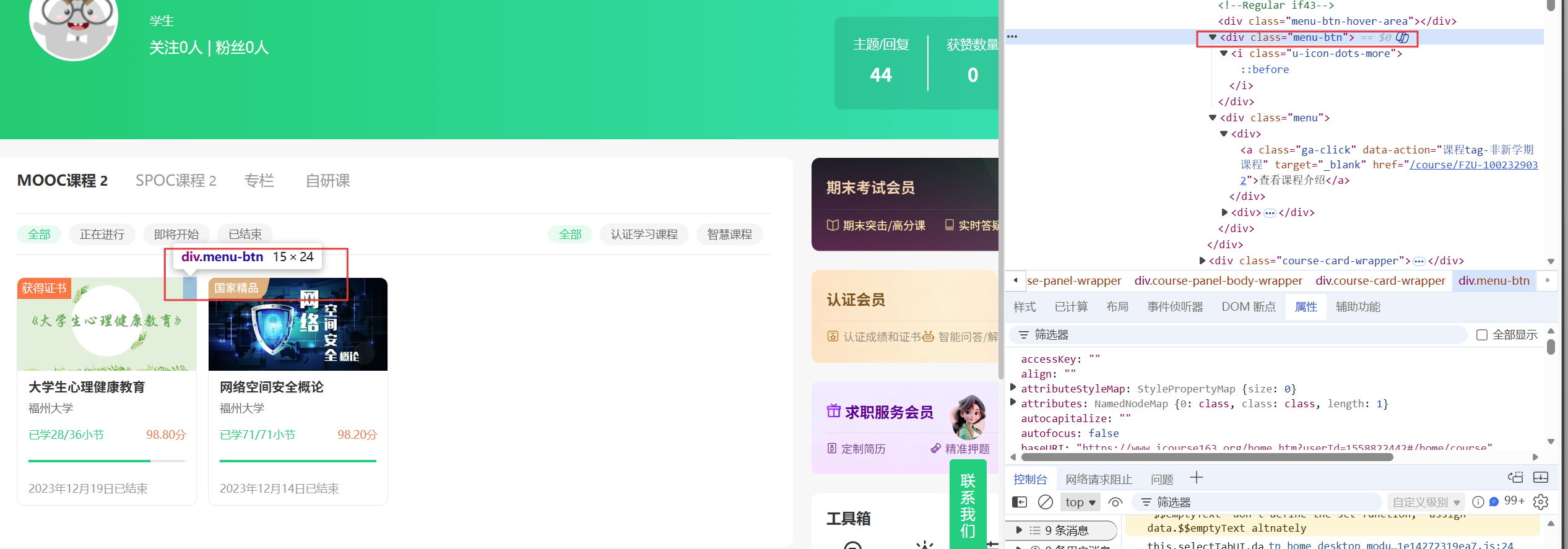
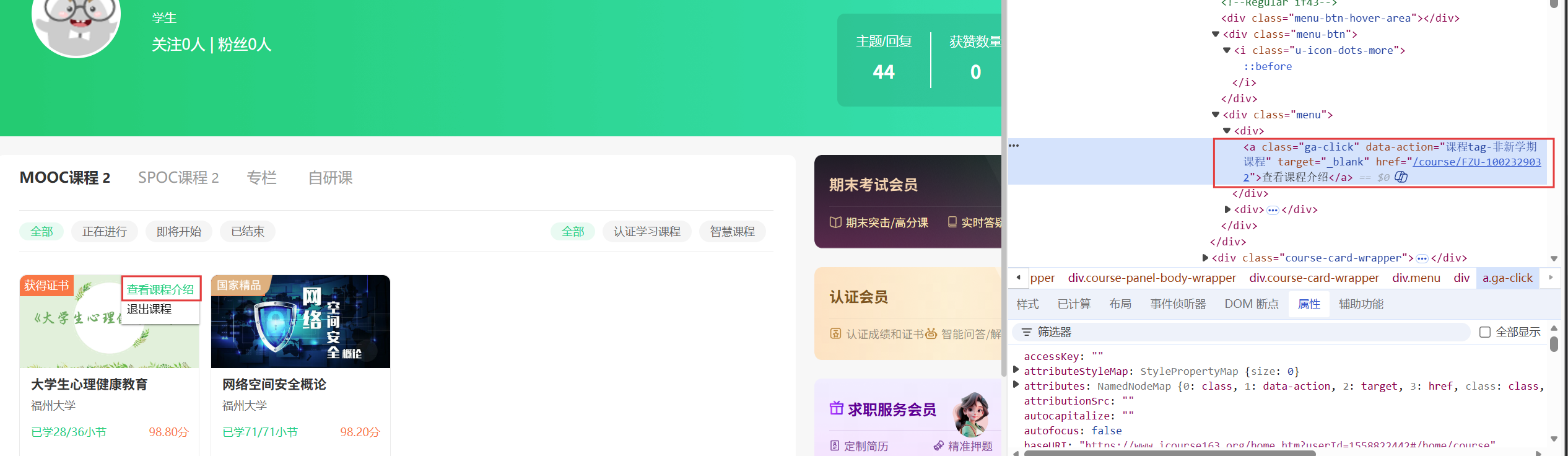
然后点击该元素进入课程详细介绍的界面(里面有我们要的课程的所有信息),然后就对应找到包含该信息的元素的所在位置然后进行提取信息即可
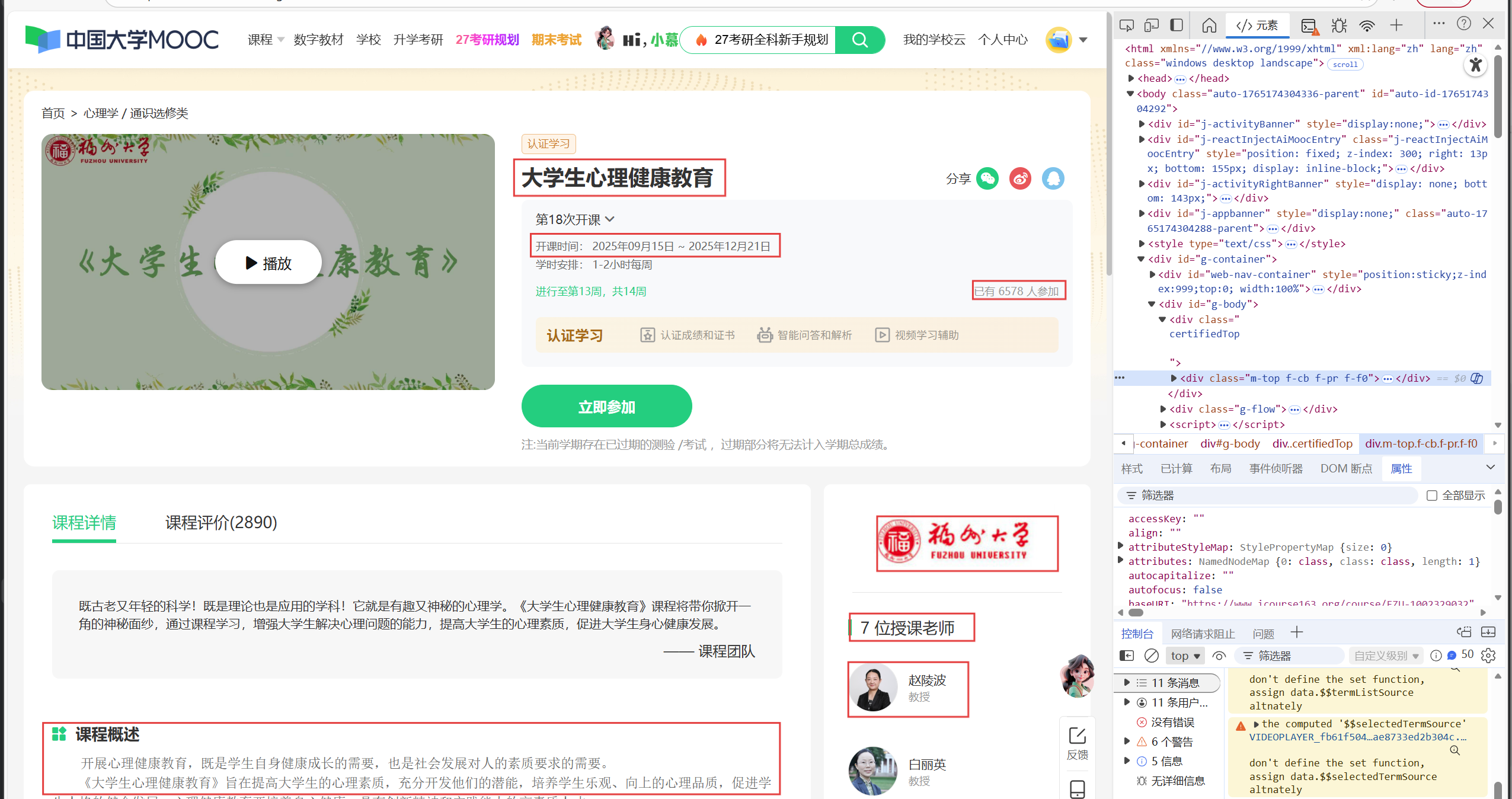
注意这里的教师团队的爬取还要实现一个和页面交互的一个动态爬取的过程,爬取教师团队的函数如下:
def get_team():
"""获取课程团队成员信息
返回:团队成员名称字符串,多个成员用逗号分隔
"""
team = ''
# 检查是否存在多标签页的课程团队展示
if driver.find_elements(By.XPATH, '//div[@class="um-list-slider_indicator_wrap f-pa"]/span'):
# 存在多标签页,逐个点击收集所有团队成员
x = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="um-list-slider_indicator_wrap f-pa"]/span'))
)
for i in range(len(x)):
if i != 0:
team += ',' # 添加分隔符
x[i].click() # 点击切换标签页
# 获取当前标签页的所有团队成员名称
elements = driver.find_elements(By.XPATH, '//h3[@class="f-fc3"]')
all_texts = [element.text for element in elements]
team += ','.join(all_texts) # 用逗号连接所有团队成员
else:
# 单标签页,直接获取所有团队成员
elements = driver.find_elements(By.XPATH, '//h3[@class="f-fc3"]')
all_texts = [element.text for element in elements]
team += ','.join(all_texts)
return team
打开并爬取mooc课程所有数据并存储到数据库的函数如下(spoc课程也是同理,只是有一个切换到spoc课程专栏的操作):
def spider():
"""主爬虫函数,爬取课程详细信息并保存到数据库
每门课程信息按顺序存储为列表:[课程号, 课程名称, 学校名称, 主讲教师, 团队成员, 参加人数, 课程进度, 课程简介]
"""
global count
actions = ActionChains(driver)
# 获取所有课程菜单按钮
buttons = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="menu-btn"]'))
)
l = len(buttons)
# 遍历每门课程
for i in range(l):
count += 1 # 课程编号自增
time.sleep(2)
a = [] # 初始化课程信息列表,用于存储当前课程的8个字段信息
# 鼠标悬停操作打开课程介绍
hover = driver.find_elements(By.XPATH, '//div[@class="menu-btn"]')[i]
button = driver.find_elements(By.XPATH, '//div[@class="menu"]')[i]
actions.move_to_element(hover).pause(1).move_to_element(
button.find_element(By.XPATH, './/a[@class="ga-click"]')).click().perform()
# 切换到新打开的课程详情页
driver.switch_to.window(driver.window_handles[-1])
time.sleep(2)
# 开始收集课程信息,按数据库字段顺序存储
a.append(count) # 字段1:课程号(自增ID)
keep('//span[@class="course-title f-ib f-vam"]', a) # 字段2:课程名称
# 字段3:学校名称(从图片alt属性获取)
x = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//img[@class="u-img"]'))
).get_attribute('alt')
a.append(x)
keep('//h3[@class="f-fc3"]', a) # 字段4:主讲教师
a.append(get_team()) # 字段5:团队成员(可能包含多个教师)
# 字段6:参加人数(使用正则表达式提取纯数字)
pattern1 = r'\d+'
text = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//span[@class="count"]'))
).text
a.append(re.findall(pattern1, text)[0])
keep('//div[@class="course-enroll-info_course-info_term-info_term-time"]/span[2]', a) # 字段7:课程进度
keep('//div[@class ="category-content j-cover-overflow"]', a) # 字段8:课程简介
# 将完整的课程信息列表保存到数据库
savelesson(a)
# 切回主窗口,准备处理下一门课程
driver.switch_to.window(driver.window_handles[0])
这里要注意的是打开一个新的窗口后要进行切换窗口的操作(driver.switch_to.window(driver.window_handles[-1]))
在爬取完这个课程的信息后要切换回主窗口,准备处理下一门课程
(driver.switch_to.window(driver.window_handles[0]))
上面所涉及到的keep函数和savelesson函数如下
def savelesson(item):
"""将单条课程数据保存到数据库
item列表顺序:[课程号, 课程名称, 学校名称, 主讲教师, 团队成员, 参加人数, 课程进度, 课程简介]
"""
con = sqlite3.connect("lessons.db")
cursor = con.cursor()
try:
# 按字段顺序插入数据:Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief
cursor.execute(
"insert into lesson (Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values(?,?,?,?,?,?,?,?)",
(item[0], item[1], item[2], item[3], item[4], item[5], item[6], item[7]))
con.commit()
con.close()
except Exception as err:
print(err)
def keep(path, a):
"""根据XPath路径获取元素文本并添加到课程信息列表
path: XPath路径
a: 课程信息列表,按数据库字段顺序存储
"""
x = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, path))
).text
a.append(x)
这里初始化数据库和写入csv文件的函数和上一题的思路大致相同,不再列出
2.运行结果
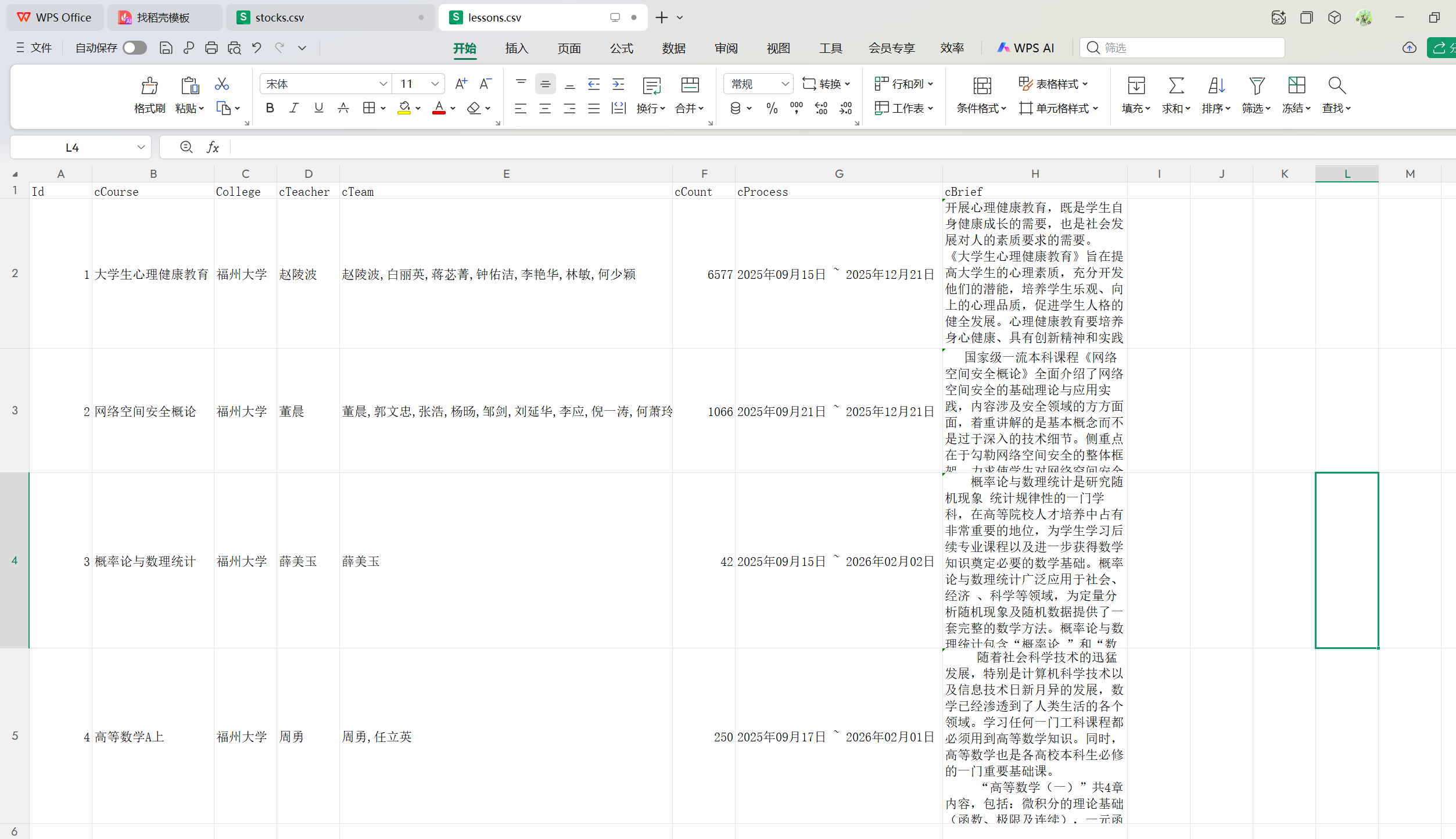
3.心得体会
通过本次中国大学MOOC平台数据采集实践,我系统掌握了Selenium在复杂Web应用中的高级应用能力。不仅熟练运用显式等待确保元素加载完备,更通过多窗口切换、iframe嵌套处理、悬停交互等关键技术,实现了对动态渲染内容的精准抓取。特别是在处理课程团队成员信息时,创新性地结合标签页切换与元素遍历,攻克了异步加载数据的采集难题。此次实践深化了对现代Web架构的理解,为后续大规模数据智能采集奠定了坚实技术基础。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
1.购买集群
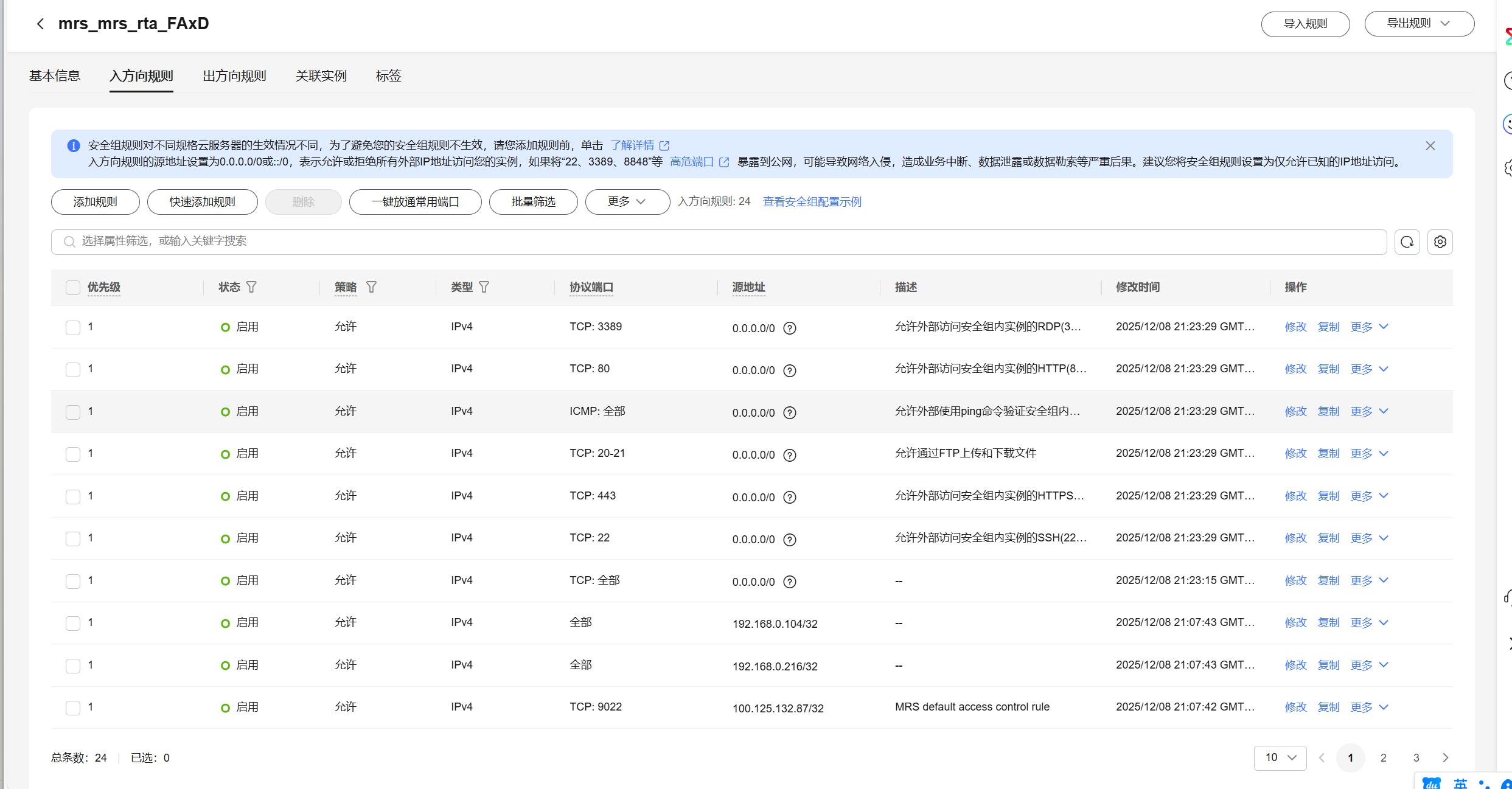
2.修改安全组规则
实时分析开发实战:
任务一:Python脚本生成测试数据
ssh远程连接并Python脚本生成测试数据

任务二:配置Kafka
1.安装Kafka客户端

2.在kafka中创建topic

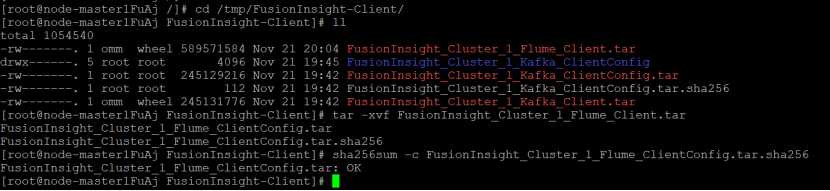
任务三: 安装Flume客户端


任务四:配置Flume采集数据
心得体会
通过这次Flume日志采集实验,我系统性地掌握了大数据生态核心技术的集成应用。不仅学会运用Python模拟复杂业务数据流,更深层次理解了分布式消息系统Kafka在高并发场景下的架构哲学,以及Flume在数据采集领域展现的工程美学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号