

数据采集与融合作业2
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
Gitee文件夹链接
1.1代码
#导入相应库
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
#定义数据库类,并定义打开,关闭,插入,展示数据等方法
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key(wCity,wDate))")
except:
self.cursor.execute("drop table if exists weathers")
self.cursor.execute("create table weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), constraint pk_weather primary key(wCity, wDate))")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)",(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows=self.cursor.fetchall()
print("%-18s%-20s%-32s%-16s" %("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" %(row[0],row[1],row[2],row[3]))
#定义天气预报类
class WeatherForecast:
def __init__(self):
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"}
self.cityCode={"北京":"101010100","上海":"101020100","广州":"101280101","深圳":"101280601"}
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city+"code cannot be found")
return
url="https://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
i=0
req=urllib.request.Request(url,headers=self.headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")#找到7天天气预报所在的li标签
for li in lis:#对每一天天气提取需要的特征并将其插入数据库中
try:
i+=1
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
if i==1:#如果是第一天的话,那么其只有一个温度,没有最高温最低温
temp=li.select('p[class="tem"] i')[0].text
else:
temp=li.select('p[class="tem"] span')[0].text+'/'+li.select('p[class="tem"] i')[0].text
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self,citys):#运行爬取天气预报信息函数
self.db=WeatherDB()
self.db.openDB()
for city in citys:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws=WeatherForecast()
ws.process(["北京","上海","广州","深圳"])
print("completed")
1.2结果

数据库中的数据

1.3心得体会
此次实践加深了我对BeautifulSoup和sqlite3的相关方法的理解,也进一步提高了我爬虫的编程能力,为后续更难的任务打下基础
Gitee文件夹链接
https://gitee.com/linyuars/2025_crawl_project/blob/master/作业2/1.py
作业②
要求:用requests和json解析方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:
Gitee文件夹链接
2.1代码
#导入相关库
import json
import urllib.request
import re
import sqlite3
import requests
def drop():#如果stock数据库中原本存在stocks表则删去
try:
con=sqlite3.connect("stock.db")
cursor=con.cursor()
try:
cursor.execute("drop table stocks")
except:
pass
con.commit()
con.close()
except Exception as err:
print(err)
def saveDB(row):#如果没有stocks表就创建表,然后将股票数据插入该表中
if len(row)==0:
return
try:
con=sqlite3.connect("stock.db")
cursor=con.cursor()
try:
sql="create table stocks (rank int,code varchar(128) primary key,name varchar(128),price float,change_percent varchar(128),change_amount float,volume varchar(128),turnover varchar(128),other varchar(128))"
cursor.execute(sql)
except:
pass
if len(row)==9:
sql="insert into stocks (rank,code,name,price,change_percent,change_amount,volume,turnover,other) values(?,?,?,?,?,?,?,?,?)"
try:
rank=row[0]
code=row[1]
name=row[2]
price=row[3]
change_percent=row[4]
change_amount=row[5]
volume=row[6]
turnover=row[7]
other=row[8]
cursor.execute(sql,(rank,code,name,price,change_percent,change_amount,volume,turnover,other))
except Exception as err:
print(err)
con.commit()
con.close()
except Exception as err:
print(err)
def showDB():#展示数据库中的数据
try:
con=sqlite3.connect("stock.db")
cursor=con.cursor()
try:
cursor.execute("select * from stocks")
rows=cursor.fetchall()
print("%-16s%-16s%-15s%-16s%-16s%-16s%-16s%-16s%-16s" %("排名","代码","名称","最新价","涨跌幅","涨跌额","成交量","成交额","涨幅"))
for row in rows:
print("%-16s%-16s%-18s%-18s%-18s%-18s%-18s%-18s%-18s" %(row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8]))
except:
pass
con.commit()
con.close()
except Exception as err:
print(err)
url='https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37103071409561710594_1762478212220&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn=1&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1762478212229'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'}
response = requests.get(url,headers = headers)
response.encoding = "utf-8"
data = response.text#爬取股票数据
print(f"{'排名':<2} {'代码':<2} {'名称':<6} {'最新价':<4} {'涨跌幅':<3} {'涨跌额':<4} {'成交量':>6} {'成交额':>4} {'涨幅':<4}")
drop()
for i in range(20):#将20个股票的信息依次提取打印出来并存到数据库中
stock=[]
rank=i+1
code=(data['data']['diff'][i]['f12'])
name=(data['data']['diff'][i]['f14'])
price=(data['data']['diff'][i]['f2']/100)
change_percent=(data['data']['diff'][i]['f3']/100)
change_amount=data['data']['diff'][i]['f4']/100
volume=round(data['data']['diff'][i]['f5']/10000,2)
turnover=round(data['data']['diff'][i]['f6']/100000000,2)
other=data['data']['diff'][i]['f7']/100
stock.append(rank)
stock.append(code)
stock.append(name)
stock.append(price)
stock.append(str(change_percent)+'%')
stock.append(change_amount)
stock.append(str(volume)+'万')
stock.append(str(turnover)+'亿')
stock.append(str(other)+'%')
saveDB(stock)
print(f"{rank:<2} {code:>6} {name:<6} {price:<6.2f} {change_percent:>3}% {change_amount:>6.2f} {volume:>8}万 {turnover:>6.1f}亿 {other:>4.1f}%")
showDB()
2.2结果

数据库中的数据

2.3心得体会
通过本次实践,我掌握了进入F12调试模式进行抓包的技巧,也学会了提取json格式数据的信息,丰富了我爬取数据的方法,也巩固了简单爬取网页数据并存储到数据库的能力,实践能力得到进一步提升。
Gitee文件夹链接
https://gitee.com/linyuars/2025_crawl_project/blob/master/作业2/2.py
作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
输出信息:
Gitee文件夹链接
| 排名 | 学校 | 省市 | 类型 | 得分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
GIF

3.1代码
#导入相应的库
import urllib.request
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'}
url='https://www.shanghairanking.cn/_nuxt/static/1761118404/rankings/bcur/2021/payload.js'
req=urllib.request.Request(url,headers=headers)
info=urllib.request.urlopen(req).read().decode('utf-8')
def drop():#如果原本存在schools表就删去
try:
con=sqlite3.connect("school.db")
cursor=con.cursor()
try:
cursor.execute("drop table schools")
except:
pass
con.commit()
con.close()
except Exception as err:
print(err)
def saveDB(row):#如果没有表就创建一个schools表,并将学校的相应信息存储到表中
if len(row)==0:
return
try:
con=sqlite3.connect("school.db")
cursor=con.cursor()
try:
sql="create table schools (rank varchar(128),name varchar(128),province varchar(128),category varchar(128),score varchar(128))"
cursor.execute(sql)
except:
pass
if len(row)==5:
sql="insert into schools (rank,name,province,category,score) values(?,?,?,?,?)"
try:
rank=row[0]
name=row[1]
province=row[2]
category=row[3]
score=row[4]
cursor.execute(sql,(rank,name,province,category,score))
except Exception as err:
print(err)
con.commit()
con.close()
except Exception as err:
print(err)
def showDB():#将school数据库的schools表中学校的信息显示出来
try:
con=sqlite3.connect("school.db")
cursor=con.cursor()
try:
cursor.execute("select * from schools")
rows=cursor.fetchall()
print("排名 学校 省市 类型 总分")
for row in rows:
print(f' {row[0]:<2} {row[1]:<5} {row[2]} {category[3]} {row[4]}')
except:
pass
con.commit()
con.close()
except Exception as err:
print(err)
start=re.search(r'univData:',info).end()
end=re.search(r',indList',info).start()
data=info[start:end]#提取出有用的信息段
var1='a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,_,$,aa,ab,ac,ad,ae,af,ag,ah,ai,aj,ak,al,am,an,ao,ap,aq,ar,as,at,au,av,aw,ax,ay,az,aA,aB,aC,aD,aE,aF,aG,aH,aI,aJ,aK,aL,aM,aN,aO,aP,aQ,aR,aS,aT,aU,aV,aW,aX,aY,aZ,a_,a$,ba,bb,bc,bd,be,bf,bg,bh,bi,bj,bk,bl,bm,bn,bo,bp,bq,br,bs,bt,bu,bv,bw,bx,by,bz,bA,bB,bC,bD,bE,bF,bG,bH,bI,bJ,bK,bL,bM,bN,bO,bP,bQ,bR,bS,bT,bU,bV,bW,bX,bY,bZ,b_,b$,ca,cb,cc,cd,ce,cf,cg,ch,ci,cj,ck,cl,cm,cn,co,cp,cq,cr,cs,ct,cu,cv,cw,cx,cy,cz,cA,cB,cC,cD,cE,cF,cG,cH,cI,cJ,cK,cL,cM,cN,cO,cP,cQ,cR,cS,cT,cU,cV,cW,cX,cY,cZ,c_,c$,da,db,dc,dd,de,df,dg,dh,di,dj,dk,dl,dm,dn,do0,dp,dq,dr,ds,dt,du,dv,dw,dx,dy,dz,dA,dB,dC,dD,dE,dF,dG,dH,dI,dJ,dK,dL,dM,dN,dO,dP,dQ,dR,dS,dT,dU,dV,dW,dX,dY,dZ,d_,d$,ea,eb,ec,ed,ee,ef,eg,eh,ei,ej,ek,el,em,en,eo,ep,eq,er,es,et,eu,ev,ew,ex,ey,ez,eA,eB,eC,eD,eE,eF,eG,eH,eI,eJ,eK,eL,eM,eN,eO,eP,eQ,eR,eS,eT,eU,eV,eW,eX,eY,eZ,e_,e$,fa,fb,fc,fd,fe,ff,fg,fh,fi,fj,fk,fl,fm,fn,fo,fp,fq,fr,fs,ft,fu,fv,fw,fx,fy,fz,fA,fB,fC,fD,fE,fF,fG,fH,fI,fJ,fK,fL,fM,fN,fO,fP,fQ,fR,fS,fT,fU,fV,fW,fX,fY,fZ,f_,f$,ga,gb,gc,gd,ge,gf,gg,gh,gi,gj,gk,gl,gm,gn,go,gp,gq,gr,gs,gt,gu,gv,gw,gx,gy,gz,gA,gB,gC,gD,gE,gF,gG,gH,gI,gJ,gK,gL,gM,gN,gO,gP,gQ,gR,gS,gT,gU,gV,gW,gX,gY,gZ,g_,g$,ha,hb,hc,hd,he,hf,hg,hh,hi,hj,hk,hl,hm,hn,ho,hp,hq,hr,hs,ht,hu,hv,hw,hx,hy,hz,hA,hB,hC,hD,hE,hF,hG,hH,hI,hJ,hK,hL,hM,hN,hO,hP,hQ,hR,hS,hT,hU,hV,hW,hX,hY,hZ,h_,h$,ia,ib,ic,id,ie,if0,ig,ih,ii,ij,ik,il,im,in0,io,ip,iq,ir,is,it,iu,iv,iw,ix,iy,iz,iA,iB,iC,iD,iE,iF,iG,iH,iI,iJ,iK,iL,iM,iN,iO,iP,iQ,iR,iS,iT,iU,iV,iW,iX,iY,iZ,i_,i$,ja,jb,jc,jd,je,jf,jg,jh,ji,jj,jk,jl,jm,jn,jo,jp,jq,jr,js,jt,ju,jv,jw,jx,jy,jz,jA,jB,jC,jD,jE,jF,jG,jH,jI,jJ,jK,jL,jM,jN,jO,jP,jQ,jR,jS,jT,jU,jV,jW,jX,jY,jZ,j_,j$,ka,kb,kc,kd,ke,kf,kg,kh,ki,kj,kk,kl,km,kn,ko,kp,kq,kr,ks,kt,ku,kv,kw,kx,ky,kz,kA,kB,kC,kD,kE,kF,kG,kH,kI,kJ,kK,kL,kM,kN,kO,kP,kQ,kR,kS,kT,kU,kV,kW,kX,kY,kZ,k_,k$,la,lb,lc,ld,le,lf,lg,lh,li,lj,lk,ll,lm,ln,lo,lp,lq,lr,ls,lt,lu,lv,lw,lx,ly,lz,lA,lB,lC,lD,lE,lF,lG,lH,lI,lJ,lK,lL,lM,lN,lO,lP,lQ,lR,lS,lT,lU,lV,lW,lX,lY,lZ,l_,l$,ma,mb,mc,md,me,mf,mg,mh,mi,mj,mk,ml,mm,mn,mo,mp,mq,mr,ms,mt,mu,mv,mw,mx,my,mz,mA,mB,mC,mD,mE,mF,mG,mH,mI,mJ,mK,mL,mM,mN,mO,mP,mQ,mR,mS,mT,mU,mV,mW,mX,mY,mZ,m_,m$,na,nb,nc,nd,ne,nf,ng,nh,ni,nj,nk,nl,nm,nn,no,np,nq,nr,ns,nt,nu,nv,nw,nx,ny,nz,nA,nB,nC,nD,nE,nF,nG,nH,nI,nJ,nK,nL,nM,nN,nO,nP,nQ,nR,nS,nT,nU,nV,nW,nX,nY,nZ,n_,n$,oa,ob,oc,od,oe,of,og,oh,oi,oj,ok,ol,om,on,oo,op,oq,or,os,ot,ou,ov,ow,ox,oy,oz,oA,oB,oC,oD,oE,oF,oG,oH,oI,oJ,oK,oL,oM,oN,oO,oP,oQ,oR,oS,oT,oU,oV,oW,oX,oY,oZ,o_,o$,pa,pb,pc,pd,pe,pf,pg,ph,pi,pj,pk,pl,pm,pn,po,pp,pq,pr,ps,pt,pu,pv,pw,px,py,pz,pA,pB,pC,pD,pE'.split(',')
var2=["",'false','null',0,"理工","综合",'true',"师范","双一流","211","江苏","985","农业","山东","河南","河北","北京","辽宁","陕西","四川","广东","湖北","湖南","浙江","安徽","江西",1,"黑龙江","吉林","上海",2,"福建","山西","云南","广西","贵州","甘肃","内蒙古","重庆","天津","新疆","467","496","2025,2024,2023,2022,2021,2020","林业","5.8","533","2023-01-05T00:00:00+08:00","23.1","7.3","海南","37.9","28.0","4.3","12.1","16.8","11.7","3.7","4.6","297","397","21.8","32.2","16.6","37.6","24.6","13.6","13.9","3.3","5.2","8.1","3.9","5.1","5.6","5.4","2.6","162",93.5,89.4,"宁夏","青海","西藏",7,"11.3","35.2","9.5","35.0","32.7","23.7","33.2","9.2","30.6","8.5","22.7","26.3","8.0","10.9","26.0","3.2","6.8","5.7","13.8","6.5","5.5","5.0","13.2","13.3","15.6","18.3","3.0","21.3","12.0","22.8","3.6","3.4","3.5","95","109","117","129","138","147","159","185","191","193","196","213","232","237","240","267","275","301","309","314","318","332","334","339","341","354","365","371","378","384","388","403","416","418","420","423","430","438","444","449","452","457","461","465","474","477","485","487","491","501","508","513","518","522","528",83.4,"538","555",2021,11,14,10,"12.8","42.9","18.8","36.6","4.8","40.0","37.7","11.9","45.2","31.8","10.4","40.3","11.2","30.9","37.8","16.1","19.7","11.1","23.8","29.1","0.2","24.0","27.3","24.9","39.5","20.5","23.4","9.0","4.1","25.6","12.9","6.4","18.0","24.2","7.4","29.7","26.5","22.6","29.9","28.6","10.1","16.2","19.4","19.5","18.6","27.4","17.1","16.0","27.6","7.9","28.7","19.3","29.5","38.2","8.9","3.8","15.7","13.5","1.7","16.9","33.4","132.7","15.2","8.7","20.3","5.3","0.3","4.0","17.4","2.7","160","161","164","165","166","167","168",130.6,105.5,2025,"学生、家长、高校管理人员、高教研究人员等","中国大学排名(主榜)",25,13,12,"全部","1","88.0",5,"2","36.1","25.9","3","34.3","4","35.5","21.6","39.2","5","10.8","4.9","30.4","6","46.2","7","0.8","42.1","8","32.1","22.9","31.3","9","43.0","25.7","10","34.5","10.0","26.2","46.5","11","47.0","33.5","35.8","25.8","12","46.7","13.7","31.4","33.3","13","34.8","42.3","13.4","29.4","14","30.7","15","42.6","26.7","16","12.5","17","12.4","44.5","44.8","18","10.3","15.8","19","32.3","19.2","20","21","28.8","9.6","22","45.0","23","30.8","16.7","16.3","24","25","32.4","26","9.4","27","33.7","18.5","21.9","28","30.2","31.0","16.4","29","34.4","41.2","2.9","30","38.4","6.6","31","4.4","17.0","32","26.4","33","6.1","34","38.8","17.7","35","36","38.1","11.5","14.9","37","14.3","18.9","38","13.0","39","27.8","33.8","3.1","40","41","28.9","42","28.5","38.0","34.0","1.5","43","15.1","44","31.2","120.0","14.4","45","149.8","7.5","46","47","38.6","48","49","25.2","50","19.8","51","5.9","6.7","52","4.2","53","1.6","54","55","20.0","56","39.8","18.1","57","35.6","58","10.5","14.1","59","8.2","60","140.8","12.6","61","62","17.6","63","64","1.1","65","20.9","66","67","68","2.1","69","123.9","27.1","70","25.5","37.4","71","72","73","74","75","76","27.9","7.0","77","78","79","80","81","82","83","84","1.4","85","86","87","88","89","90","91","92","93","109.0","94",235.7,"97","98","99","100","101","102","103","104","105","106","107","108",223.8,"111","112","113","114","115","116",215.5,"119","120","121","122","123","124","125","126","127","128",206.7,"131","132","133","134","135","136","137",201,"140","141","142","143","144","145","146",194.6,"149","150","151","152","153","154","155","156","157","158",183.3,"169","170","171","172","173","174","175","176","177","178","179","180","181","182","183","184",169.6,"187","188","189","190",168.1,167,"195",165.5,"198","199","200","201","202","203","204","205","206","207","208","209","210","212",160.5,"215","216","217","218","219","220","221","222","223","224","225","226","227","228","229","230","231",153.3,"234","235","236",150.8,"239",149.9,"242","243","244","245","246","247","248","249","250","251","252","253","254","255","256","257","258","259","260","261","262","263","264","265","266",139.7,"269","270","271","272","273","274",137,"277","278","279","280","281","282","283","284","285","286","287","288","289","290","291","292","293","294","295","296","300",130.2,"303","304","305","306","307","308",128.4,"311","312","313",125.9,"316","317",124.9,"320","321","Wuyi University","322","323","324","325","326","327","328","329","330","331",120.9,120.8,"Taizhou University","336","337","338",119.9,119.7,"343","344","345","346","347","348","349","350","351","352","353",115.4,"356","357","358","359","360","361","362","363","364",112.6,"367","368","369","370",111,"373","374","375","376","377",109.4,"380","381","382","383",107.6,"386","387",107.1,"390","391","392","393","394","395","396","400","401","402",104.7,"405","406","407","408","409","410","411","412","413","414","415",101.2,101.1,100.9,"422",100.3,"425","426","427","428","429",99,"432","433","434","435","436","437",97.6,"440","441","442","443",96.5,"446","447","448",95.8,"451",95.2,"454","455","456",94.8,"459","460",94.3,"463","464",93.6,"472","473",92.3,"476",91.7,"479","480","481","482","483","484",90.7,90.6,"489","490",90.2,"493","494","495",89.3,"503","504","505","506","507",87.4,"510","511","512",86.8,"515","516","517",86.2,"520","521",85.8,"524","525","526","527",84.6,"530","531","532","537",82.8,"540","541","542","543","544","545","546","547","548","549","550","551","552","553","554",78.1,"557","558","559","560","561","562","563","564","565","566","567","568","569","570","571","572","573","574","575","576","577","578","579","580","581","582",4,"2025-04-15T00:00:00+08:00","logo\u002Fannual\u002Fbcur\u002F2025.png","软科中国大学排名于2015年首次发布,多年来以专业、客观、透明的优势赢得了高等教育领域内外的广泛关注和认可,已经成为具有重要社会影响力和权威参考价值的中国大学排名领先品牌。软科中国大学排名以服务中国高等教育发展和进步为导向,采用数百项指标变量对中国大学进行全方位、分类别、监测式评价,向学生、家长和全社会提供及时、可靠、丰富的中国高校可比信息。",2024,2023,2022,15,2020,2019,2018,2017,2016,2015]
for i in range(len(var2)):
var2[i]=str(var2[i])
zipped=dict(zip(var1,var2))#根据该文本其中的映射构造相应的键值对
#找出文本中变量的值,如果其在构造的键值对的键中,将其用键值对中的值代替,还原其真实值
rank=re.findall(r'(?:ranking:)(.*?)(?:,)',data)
name=re.findall(r'(?:univNameCn:")(.*?)(?:",)',data)
province=re.findall(r'(?:province:)(.*?)(?:,)',data)
category=re.findall(r'(?:univCategory:)(.*?)(?:,)',data)
score=re.findall(r'(?:score:)(.*?)(?:,)',data)
for i in range(len(rank)):
if rank[i] in zipped.keys():
rank[i]=zipped.get(rank[i])
for i in range(len(province)):
if province[i] in zipped.keys():
province[i]=zipped.get(province[i])
for i in range(len(category)):
if category[i] in zipped.keys():
category[i]=zipped.get(category[i])
for i in range(len(score)):
if score[i] in zipped.keys():
score[i]=zipped.get(score[i])
print("排名 学校 省市 类型 总分")
drop()
for i in range(len(rank)):#打印出学校的信息并将其保存到数据库中
print(f' {rank[i]:<2} {name[i]:<5} {province[i]} {category[i]} {score[i]}')
saveDB([rank[i],name[i],province[i],category[i],score[i]])
showDB()#展示数据库中学校的信息
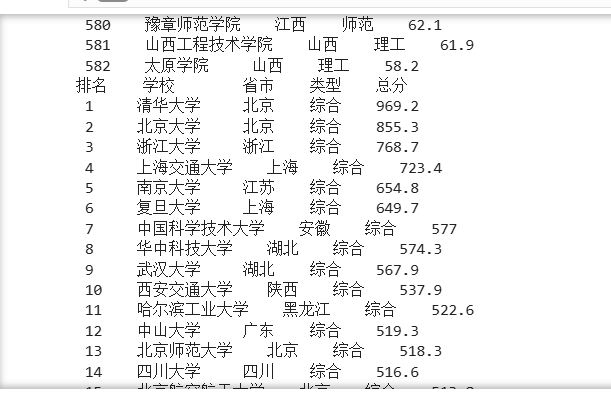
3.2结果
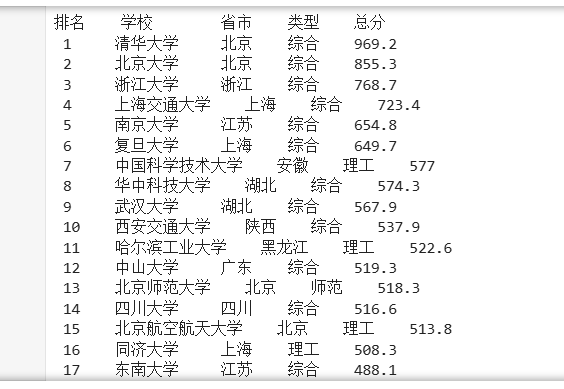
数据库中的数据
3.3心得体会
本次实践进一步丰富了我爬取数据的方法和技巧,加深了我对爬虫步骤的理解,提高了个人的编程实践能力和解决问题的思维逻辑,为后面更难的实践打下基础。
Gitee文件夹链接
https://gitee.com/linyuars/2025_crawl_project/blob/master/作业2/3.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号