决策树
- 通常决策树主要有三种实现,分别是ID3算法,CART算法和C4.5算法。
- 随机森林的重点在于单个决策树是如何建造的
CART
- Classification And Regression Tree,即分类回归树算法,简称CART算法,它是决策树的一种实现.
- CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。在CART算法中主要分为两个步骤:
- 原理
![]()
熵
- 信息论中,熵是接受的每条消息中包含的信息的平均值。又被称为信息熵、信源熵、平均自信息量。可以被理解为不确定性的度量,熵越大,信源的分布越随机
- 熵是描述一个系统的无序程度的变量;同样的表述还有,熵是系统混乱度的度量,一切自发的不可逆过程都是从有序到无序的变化过程,向熵增的方向进行
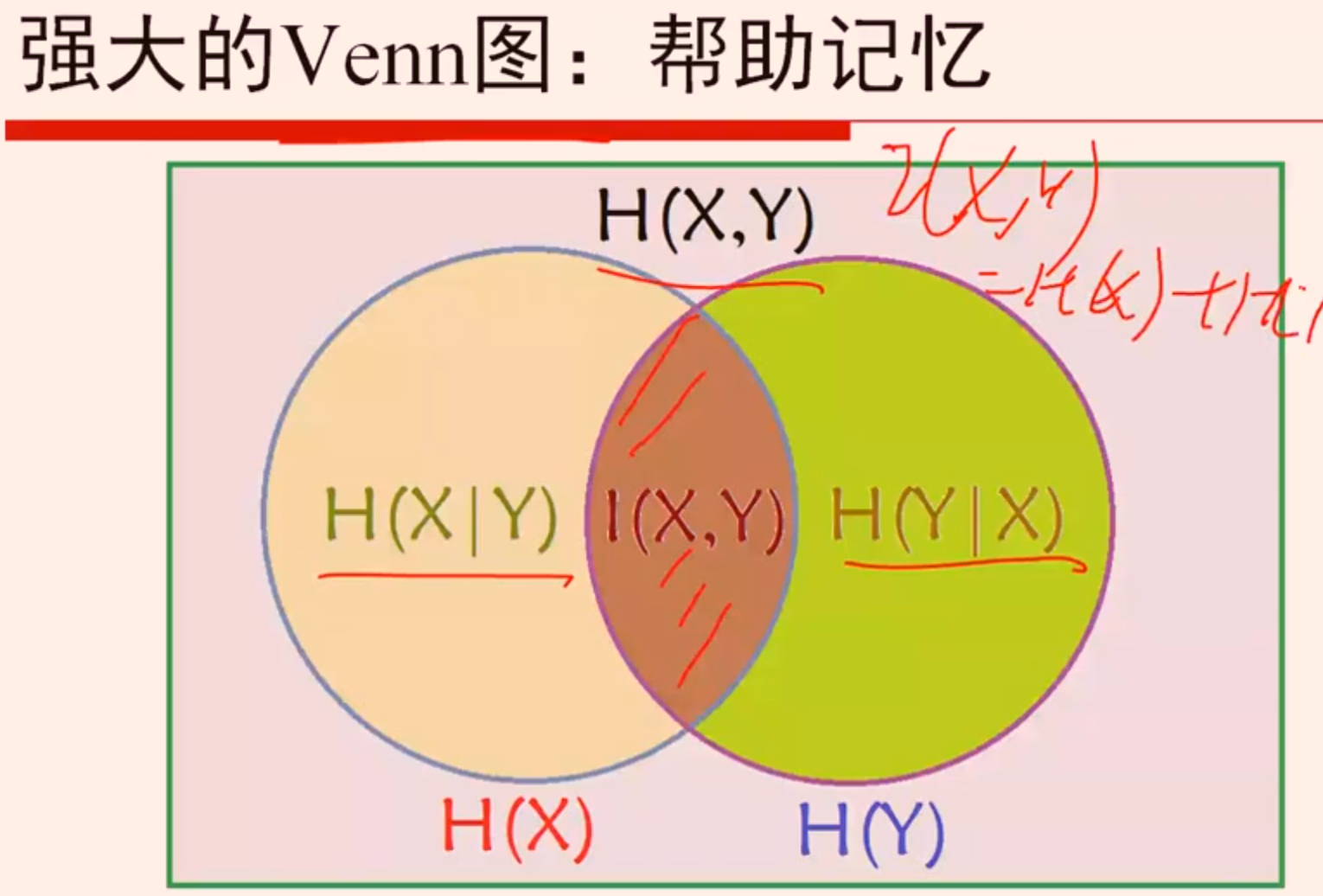
信息熵
![]()
![]()
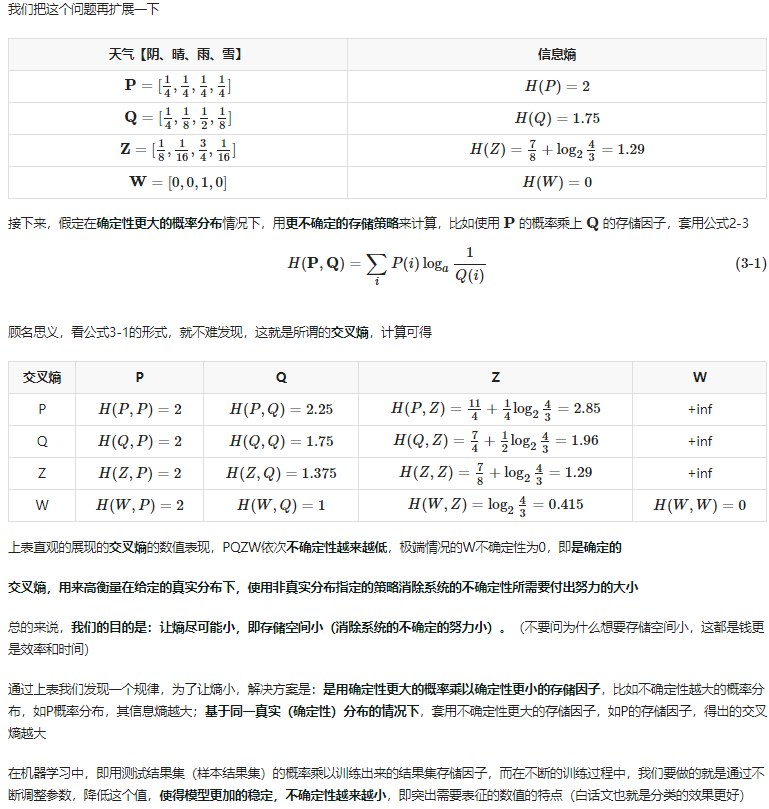
交叉熵和相对熵
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
决策树算法
三种决策树算法:ID3、C4.5、CART
![]()
决策树的评价
![]()
过拟合的解决方法:剪枝、随机森林
剪枝
![]()
![]()
Bootstraping
![]()
![]()
![]()
样本不均衡的常用处理方法
![]()
使用RF建立计算样本间相似度
![]()
![]()
孤立森林(Isolation Forest):常用于异常值检测
![]()
posted @
2020-07-09 23:25
败家小林
阅读(
302)
评论()
收藏
举报





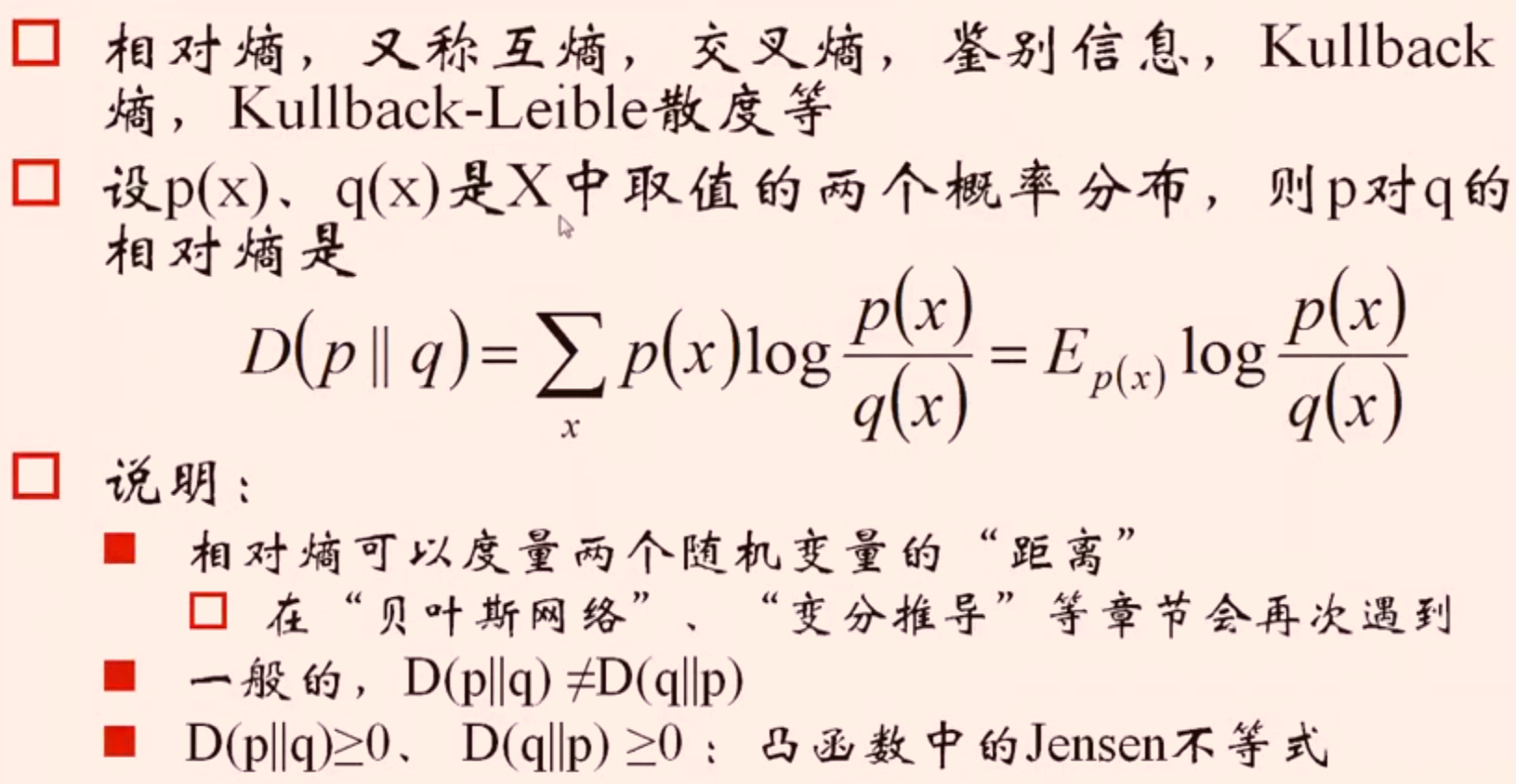

















 浙公网安备 33010602011771号
浙公网安备 33010602011771号