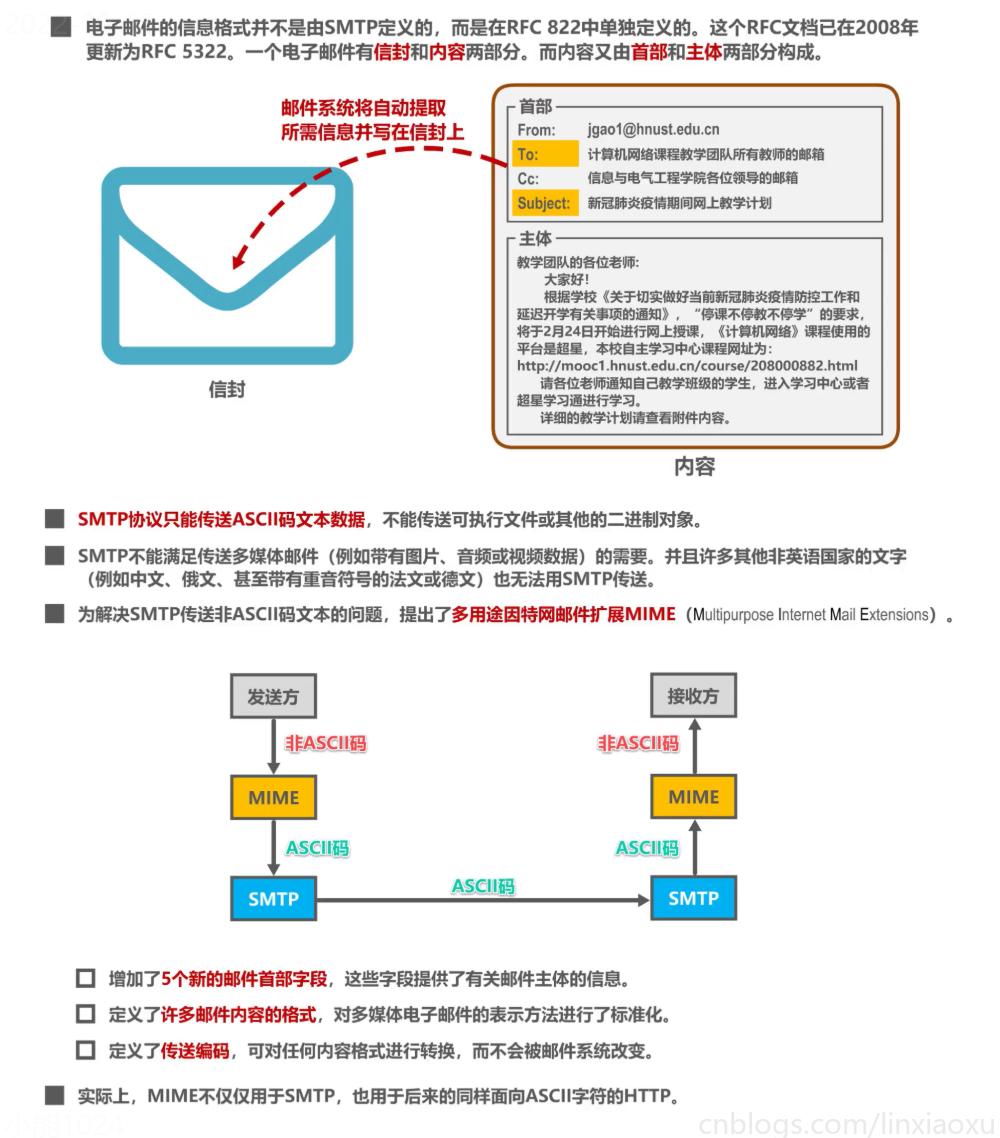
查漏补缺 ASCII、MIME、BASE64
 查漏补缺。ASCII、MIME、BASE64 一看就会。
查漏补缺。ASCII、MIME、BASE64 一看就会。
ASCII
美国信息交换标准代码 ( American Standard Code for Information Interchange, ASCII )
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1、2等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪个数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通讯而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了所谓的ASCII编码,统一规定了上述常用符号用哪个二进制数来表示。
美国标准信息交换代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。起始于50年代后期,在1967年定案。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,它已被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母。
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符。标准 ASCII 码也叫基础ASCII码,使用 7 位二进制数来表示所有的大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。其中:
0~31及127(共33个)是控制字符或通讯专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(振铃)等;通讯专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为 8、9、10 和 13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32sp是空格),其中48~57为0到9十个阿拉伯数字;
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。
-
奇校验规定:一个字节中八个二进制位数中1的个数必须是奇数,若非奇数,则在最高位b7添1;
- 原始码流+校验位 总共有奇数个1
-
偶校验规定:一个字节中八个二进制位数中1的个数必须是偶数,若非偶数,则在最高位b7添1。
- 原始码流+校验位 总共有偶数个1

MIME
**网络传输只能传输可打印字符(32127)。**在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些**不可见字符就有可能被处理错误**(控制字符,通讯专用字符,128255),这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
通用互联网邮件扩充MIME,增加了邮件的主体结构,定义了非ASCII码的编码传输规则,这就是Base64。
BASE64
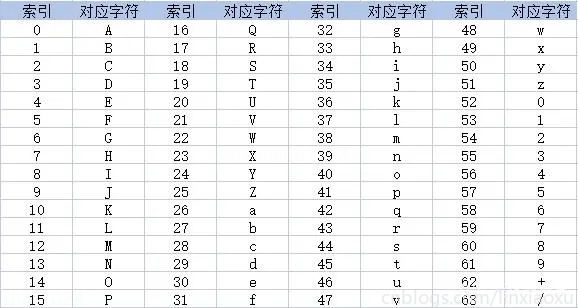
6bit(原8bit)一个字节,不足的位数用0补齐,两个0用一个=表示。
采用64个基本的ASCII码字符对数据进行重新编码。
- 将需要编码的数据拆分成字节数组,以3个字节为一组,按顺序排列24位数据,再把这24位数据分成4组,即每组6位;
- 再在每组的的最高位前补两个0凑足一个字节,这样就把一个3字节为一组的数据重新编码成了4个字节;
- 当所要编码的数据的字节数不是3的整倍数,也就是说在分组时最后一组不够3个字节,这时在最后一组填充1到2个0字节,并在最后编码完成后在结尾添加1到2个=号。
为什么不直接传二进制
- 某些场合并不能传输或者储存二进制流。如果一个传输协议是基于ASCII文本的,那么它就不能传输二进制流,要将二进制流传输就得编码。常见的 http 协议的 url 就是纯文本的,不能直接放二进制流。
- 大多数现代语言的 String 类型,都不能直接储存二进制流,但可以储存BASE64编码的字符串。如果你希望用 String 类型操作一切数据,那就没法直接用二进制流。
- 就是某些协议会对二进制流中的特定字符进行特殊处理(比如ASCII的0~32编码的字符在某些传输介质中,是会被当作特殊含义处理的),这种时候就需要通过编码来避开这些特定字符了。(前面MIME的例子)
编码例子
- 第一种:待编码的二进制只有24位,此时刚好能分成4组,编码结果就是4个字符,没有=号,如you有24位二进制,结果就是eW91。
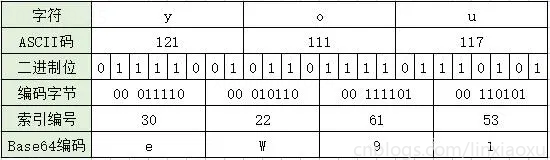
- 第二种:待编码的二进制只有16位,那么编码的结果就是3个字符跟上一个=号,如Ma:
Ma的二进制:01001101 01100001
分组结果:010011 010110 0001
根据RFC-4648的规范,对于这种情况,将在最后用0补齐6位,得到:010011 010110 000100
对应Base64的编码就是TWE,为了能在解码时能识别出最后有补齐的两个0,以便去掉,要跟上=作记号,所以Ma最终的Base64编码就是TWE=。 - 第三种:待编码的二进制只有8位,Base64编码结果应该是两个字符,跟上两个=号,如M:
M的二进制:01001101
分组结果:010011 01
根据RFC-4648的规范,对于这种情况,将在最后用0补齐6位,得到:010011 010000
对应Base64的编码就是TQ,为了能在解码时能识别出最后有补齐的4个0,以便去掉,要跟上两个=作记号,所以M最终的Base64编码就是TQ==
处理中文
Base64 仅可对 ASCII 字符进行编码,如果是中文字符等非ASCII码,就需要先将中文字符转换为ASCII字符后,再进行编码才行。
数据体积
Base64编码的数据体积通常比原数据的体积大三分之一。
应用
-
简单加密。(不确保安全性)
-
URL编码(改良的BASE64)。(具体编码方式由浏览器决定)
-
后端把数据库中文件数据返回前端前将数据转换为Base64编码后的字符串。
-
前端页面针对图片处理,Data URL。可以直接减少请求数,将其内嵌在img标签或者css样式中。
- data:[<mime type>][;base64],<data>
<img src="data:image/svg+xml;base64,MTE0NTE0.......">.buttonimg{ background: url(data:image/svg+xml;base64,MTE0NTE0......);}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号